基于优化决策树的智能故障诊断方法研究
2020-05-08郑日晖陈志豪
郑日晖,岑 健,陈志豪
(1. 广东技术师范大学, 广东 广州 510665;2. 广东水利电力职业技术学院, 广东 广州 510635)
随着工业的发展,故障诊断已经成为生产过程中不可或缺的重要环节。工业4.0时代的到来,推动人工智能在各行各业中得到广泛应用。智能故障诊断的其中一个研究领域,就是运用机器学习的方法,希望机器不但具有人类的思维,并且可以做出比人类更快、更准的诊断。然而机器学习的算法繁多且每种算法均带有影响模型性能的参数,在实际应用中不仅要适当地选用模型,并且要结合数据收集的情况对算法的参数进行寻优。如王丹妮等[1]采用粒子群算法对BP神经网络算法的初始权值和阈值进行优化;张文雅等[2]采用网格搜索法对支持向量机的惩罚系数和核函数参数进行寻优;李刚等[3]采用遗传算法对随机森林的参数进行优化。粒子群算法更适用于对实数进行寻优,对于整数的寻优精度不高;网络搜索法对于多参数寻优往往开销大、耗时长;遗传算法编程比较复杂、收敛速度慢。
决策树算法具备容易实现、便于理解等优点[4],并且其参数较少,方便寻优。本文通过控制决策树叶子节点最小样本数来控制决策树的生长,寻找合适的参数进行建模并将其用于智能故障诊断。
1 决策树算法
决策树是用于实现数据分类或回归预测的算法。决策树的运算过程是将实测数据样本从根节点输入,在每个父节点中进行分裂选择子节点,从根节点开始通过唯一的一条路径一直到叶节点,实现最终的分类。
早期的决策树分类器采用CLS算法,该算法的主要思想是在每个节点处从当前剩下的候选属性中随机选取。由于每个属性对最终类别的影响程度不同,因此该方法存在一定的盲目性,缺乏科学有效的规则来选取分裂属性,拟合效果难以保证。所以决策树建树过程需要解决的关键问题是每个节点分裂属性的选择。为了解决选取最优分裂属性的问题,J.Ross Quinlan根据信息理论提出了ID3决策树算法[5]。在信息理论中,用信息熵H(x)(单位为bit,以下省略)来度量一个随机变量x的不确定度,有

其中,pi为随机变量x出现的概率。
选取某个属性A作为分裂属性时,由于产生了条件约束,减少了不确定性,故而产生了信息增益。显而易见,信息增益越大,不确定度减少幅度越大,所以ID3算法核心思想是通过计算当前节点的最大信息增益来选取最优分裂属性。
设样本D的类别种数为k,在没有任何属性约束的情况下,样本D的信息熵为

设属性A中有n个分支,a为第j个分支类别属性序号,则A属性条件约束下的信息熵为
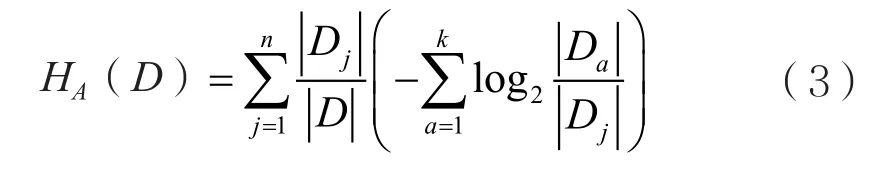
信息增益的计算公式为:
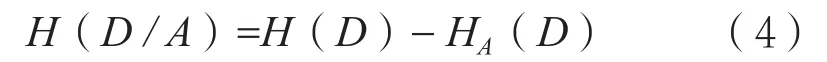
相对CLS算法而言,ID3算法确定了选择分裂属性的方向,使决策树生长集约化、合理化。但由于信息增益会偏好取值较多的属性,导致分类器出现局部最优解。针对ID3算法的不足,Quinlan于1993年提出了C4.5决策树算法[6]。C4.5算法是在ID3算法的基础上进行改进优化,引入一个参数HC(D)对信息增益进行惩罚,惩罚参数计算如下:
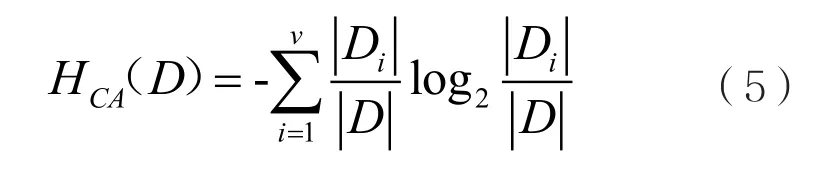
其中v为属性A的取值个数,此时将衡量分裂属性优劣顺序的指标

称为信息增益率。
CART算法[7]是早在1984年由Brei-man等人提出的另一种经典算法,其核心思想是基于Gini系数对分裂属性进行选取。样本集合D的Gini系数为

其中pi代表类别第i个类别被选中的概率。如果集合D被划分成两个子集D1和D2,则此次划分的Gini系数为

ID3算法只适用于处理属性为有限离散值的情况,对属性为连续实数的情况无能为力,虽然C4.5可以对属性为连续实数的情况进行处理,但其计算过程相对复杂;由于CART算法不仅适合处理属性为连续实数的情况,并且其计算过程简单,所以本文的决策树模型均采用CART算法。
2 调参优化
2.1 调参优化思路
决策树算法虽然易于实现且运算速度快,但在建树过程中如果任其生长而不加以控制,将可能造成训练过拟合,不仅增加运算开销和时耗,同时使得模型的泛化能力变差。控制决策树生长一般采用剪枝的方法,而剪枝有预剪枝和后剪枝之分。预剪枝是在决策树生长过程中同时采用一些指标来决定节点是否不再分裂并用叶子节点代替;后剪枝是在决策树充分生长后采用一些指标来决定是否剪去子树而用叶子节点代替。预剪枝的风险是可能导致决策树欠拟合;后剪枝一般不会导致欠拟合,但是由于后剪枝是在决策树充分生长之后进行的,所以其运算开销远大于预剪枝。
本文优化决策树的思路是采用预剪枝的方法,在决策树节点上设定一个阈值,将该阈值定义为叶子节点最小样本数。当决策树的节点中所含的样本数少于该阈值时则停止分裂,并将该节点设定为叶子节点,从而控制决策树的生长深度。由于决策树节点中的样本数为自然数且变化范围不大,所以采取可行域内遍历寻优的方法寻找合适的叶子节点最小样本数。
值得一提的是,决策树的生长深度并不与叶子节点最小样本数一一对应,叶子节点最小样本数在一定的变化区间内,决策树将保持相同的深度及相应的分类准确度。因此,本文调参寻优的思路是为参数寻找一个合理的区间使得模型最佳。
2.2 评价函数的构建
对模型参数进行优化的过程中,需要定义一个优化的目标。对于决策树而言,优化的目标不仅是希望提高分类准确率p,同时也希望模型不要因为过于复杂而增加运算开销、影响实时性。考虑到决策树算法的节点数N与决策树的深度是指数关系,反过来决策树的深度与节点数N为对数关系,因此采用log2N来表征决策树的复杂程度,也就是说,N越大模型越复杂,N越小模型越简单。综合以上分析,优化的目标是希望p越大、log2N越小则效果更理想,所以定义f=p/log2N为评价函数,将其作为优化目标,将叶子节点最小样本数k作为优化对象,则优化的过程就是寻找合适的k的取值范围使得f=p/log2N越大越好。需要说明的是,本文采用五折交叉验证对分类准确率p进行计算。
2.3 调参优化流程
综合2.1、2.2的分析,本文调参优化的方法是通过在设定区间内搜索理想的叶子节点最小样本数k的取值范围,使得同时兼顾分类准确率与模型复杂程度的评价函数f=p/log2N尽可能大,流程如图1所示。
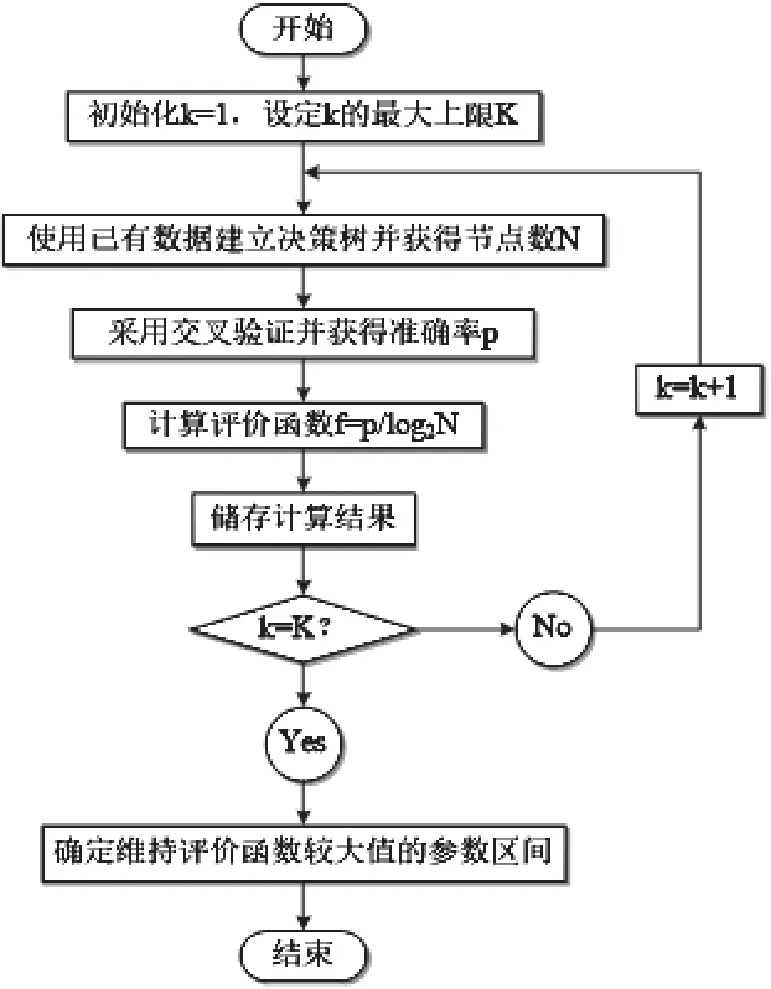
图1 调参优化流程
3 实例验证
3.1 实验准备
为了验证本文调参优化方法的有效性,采用某机械故障数据样本集进行实验,数据样本集共包含4类故障状态,每类故障状态均含有100个样本,每个样本均含有36个特征。基于优化决策树的智能故障诊断方法流程如图2所示:首先通过调参优化步骤获得最优参数的取值区间,然后在该区间内任选1个优秀参数k’并采用划分好的训练集建立优化后的决策树,最后采用测试集进行分类准确率的测试。
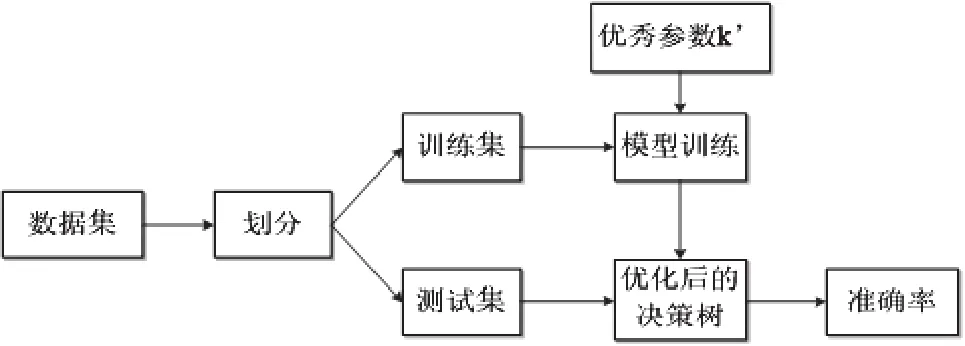
图2 基于优化决策树的智能故障诊断方法流程
3.2 调参优化分析
初始化叶子节点最小样本数为k=1,设定其最大值K=70,遍历k从1-70进行建模并考察相应的评价函数,实验结果如图3所示。
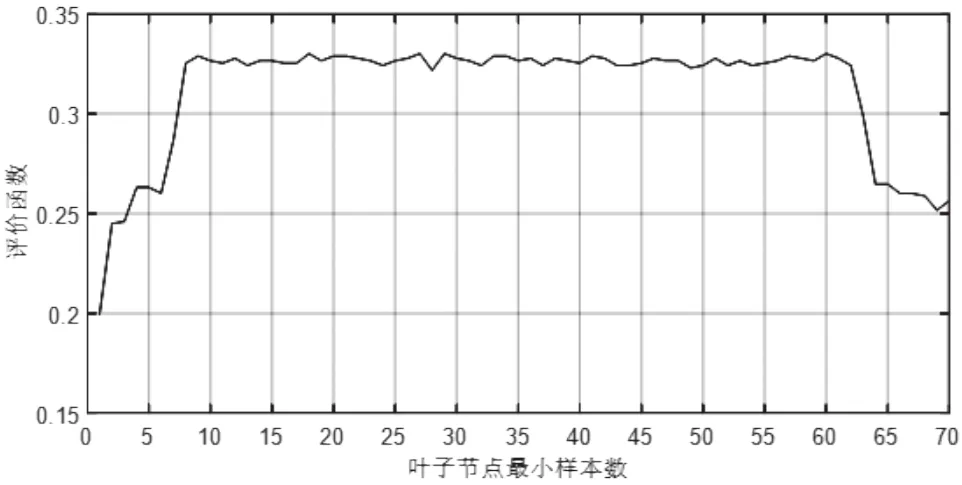
图3 调参优化实验结果
由图3可知,当叶子节点最小样本数k小于8时,由于从不受约束开始到逐步控制,评价函数从数值0.2呈现逐渐增大的趋势;当叶子节点最小样本数k大于62时,对决策树生长的限制过度,出现了欠拟合,分类准确明显下降,从而导致评价函数递减;当叶子节点最小样本数k落在区间[8,62]内时,评价函数较平稳地保持在高位数值0.33左右。由以上分析可得,当叶子节点最小样本数k在[8,62]内取值时,可以获得较理想的决策树模型。
3.3 模型测试分析
为了验证优化后模型的性能,将决策树最小样本数设置为40,采用数据集进行建模并测试,决策树算法模型如图4所示。
采用留出法,使用数据集建模并测试:将400个数据样本随机划分出300个作为训练集,留出100个样本进行测试,实验分类结果如图5所示。
由图5可见,优化后的决策树模型对于第一种故障的21个数据样本全部分类正确;第二种故障的23个数据样本中,有16个分类正确,有4个被错误识别为第三种故障,有3个被错误识别为第四种故障;第三种故障的30个数据样本全部分类正确;第四种故障的26个数据样本中,有25个分类正确,有1个被错误识别为第一种故障。统计四种故障情况的100个数据样本中,共有8个数据样本分类错误,分类准确率为92%。
如果不对决策树算法进行优化,决策树算法模型则如图6所示,实验分类结果如图7所示。
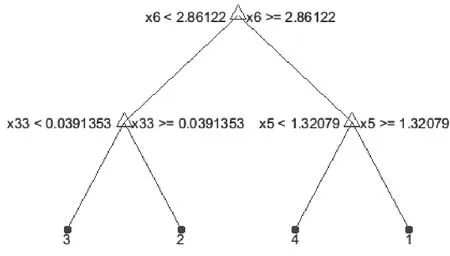
图4 优化的决策树算法模型
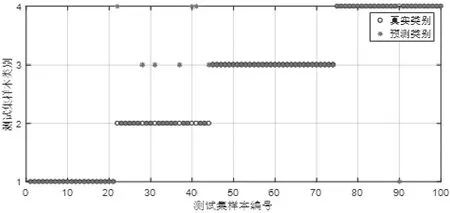
图5 优化的决策树算法分类结果

图6 没有优化的决策树算法模型
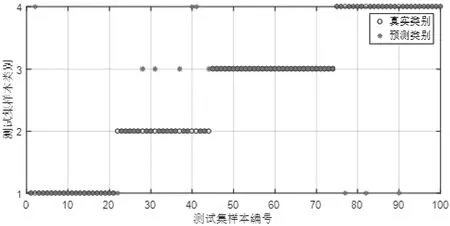
图7 没有优化的决策树算法实验结果
由图7可见,未经过优化的决策树模型对于第一种故障的21个数据样本中有20个分类正确,有1个被错误识别为第四种故障;第二种故障的23个数据样本中,有16个分类正确,有1个被错误识别为第一种故障,有4个被错误识别为第三种故障,有2个被错误识别为第四种故障;第三种故障的30个数据样本全部分类正确;第四种故障的26个数据样本中,有23个分类正确,有3个被错误识别为第一种故障。统计四种故障情况的100个数据样本中,共有11个数据样本分类错误,分类准确率为89%。
此外对比图4、6可知,没有进行优化的决策树模型共有5层、21个节点;优化后的决策树模型只有3层且仅有7个节点。

表1 优化前后的决策树模型对比
表1显示:优化后的决策树模型不仅提高了分类准确率,并且很大程度地减小了决策树模型的复杂程度。
4 小结
本文针对决策树性能受其参数影响问题,提出了一种基于优化决策树的智能故障诊断方法。
(1)分析了决策树节点最小样本数对决策树算法性能的影响,提出了以决策树节点最小样本数为优化对象的优化思路。(2)分析了影响决策树算法性能的因素,构建了同时兼顾分类准确率和模型复杂程度的模型性能评价函数。(3)设计了以决策树节点最小样本数为优化对象、以模型性能评价函数为优化目标的优化流程。(4)通过实验证明,未进行优化的决策树模型共有5层、21个节点,分类准确率为89% ;优化后的决策树模型只有3层且仅有7个节点,分类准确率为91%。这说明本文提出的优化方法应用于智能故障诊断中不仅可简化模型,还可提高模型分类准确率。
