基于Spark的EIDA-BP算法对农作物产量的预测
2020-05-07唐立李六杏王启亮王睿方政
唐立,李六杏,王启亮 ,王睿,方政
(1.安徽经济管理学院 信息工程系,安徽 合肥,230031;2.安徽农业大学 信息管理学院,安徽 合肥,230031)
随着农业农村信息化推进,利用农业大数据对农作物产量进行预测是国内外学者研究的热点问题之一。在早年对农作物预测仅限于几个容易收集的参数,如播种面积、化肥施用量、农业从业人员及每公顷产量[1]。而当今现代化农业的建设促使了农业数据快速增长,对于以前难以采集的数据变得容易,如土壤成分监控数据、气象数据、现代化机械使用数据、遥感灌溉数据[2],而这些海量数据处理不当会影响农作物产量预测的精度。本文结合农业大数据的特点以及大数据技术的发展,拟采用Spark框架作为内存计算框架应对大量数据计算,同时运用EIDA优化BP神经网络算法对安徽亳州地区的小麦农产量进行预测,并以数据实验证明该算法的有效性。
1 影响农作物产量因素大数据计算框架设计
1.1 影响农作物产量因素概述
农作物产量受诸多因素影响,国内很多专家学者对此进行了很多研究,在相同的农作物品种和栽培技术前提下,如施丽娟等[3]指出化肥施用量、农药使用量、有效灌溉面积、农用塑料薄膜使用量以及农业机械总动力是农作物产量产生主要影响因素。郭梁等[4]指出气象因素也是影响农作物产量的因素之一,实验数据表明棉花作物受气象因素影响程度为13.22%,油类作业受气象影响程度为9.58%,粮食作物如小麦受气象影响程度为6.39%。因此,根据施丽娟等[3-4]的研究,初步筛选 8 种影响因素:有效灌溉面积(X1)、化肥施用量(X2)、农村用电量(X3)、农业机械总动力(X4)、第一产业从业人数(X5)、农作物播种面积(X6)、农作物单位面积产量(X7)、气象因素(X8)。
为了准确预测农作物产量,对影响农作物产量的因素数据进行计算,将农村生产过程中海量的数据信息归融为一组有意义的数值,该数值就是农作物产量因素,通过这些数值的变化可以精确预测农作产量的波动。本文结合EIDA算法优化BP神经网络,设计一个基于Spark框架的计算平台,通过海量农业数据预测农作物产量。
1.2 基于Spark系统框架设计
Spark是MapReduce分布计算的替代方案,是新一代大数据计算平台的代表。Spark的优势有:它通过并联执行多个Stage时,是通过内存进行数据运算的,无需访问磁盘;它具有弹性分布式数据集RDD和分布式运行架构,可以精确读取存储的数据,使用户自定义分区策略;Spark的事件驱动启动任务的方式也减少切换开销[5]。
由于影响农作物产量因素数据量巨大,类型繁多,对数据预处理造成极大挑战。为了快速地从海量的数据中高效提取有价值的预测数据,本文依靠Spark分析技术和分布处理能力,对农作物产量因素的大数据进行预处理,为本文后面提出的农作物预测的算法提供平台依托。其框架结构如图1所示。

图1 基于Spark的框架Fig.1 Spark based framework
基于Spark的框架有5层。
1)数据层是影响农作物产量因素数据的来源,收集科研数据,利用Python爬虫网站农业数据,收集农业传感数据和日志数据。
2)数据层的数据为原始数据,种类繁多,结构复杂,存储不易。进入吸取层,以便筛选出有用数据,对数据进行预处理。对于传统关系型数据存储在RDBMS中,并用Sqoop工具导入到HDFS。
3)经过ETL的数据预处理,对数据进行清洗、格式转换、计算、组合、抽样等处理。数据吸取完毕后进入存储层。对于非结构化和结构化数据、关系型数据与非关系型数据、离线数据与实时数据用一种存储方式显然不行,调用HBase、HDFS、RDBMS混合存储形式。
4)存储完毕进入平台层。Tachyon是位于Spark计算框架与HDFS之间的分布式文件系统,它能使DFS的文件直接分配到分布式内存文件系统中,文件在内存中共享,不需要落地磁盘,从而提高效率。首先接受任务后,驱动程序(Driver)向资源管理器申请资源,通过Spark Context.text Flie()函数从分布式文件系统HDFS中读取所需数据形成RDD。然后,在Spark的工作节点(Worker)上启动多个任务执行器(Executor),把Spark Context将程序代码和分配给每个处理机的任务广播给每个Executor。最后,将结果发送到Worker上,再返回给驱动程序(Driver)[6]。通过Spark平台处理提取可以用于后期预测计算的农作物产量因素数据。
5)在分析层实现EIDA优化BP神经网络算法。
2 EIDA优化BP神经网络
2.1 BP神经网络算法
BP神经网络算法是最常见的预测算法之一,目前对它的研究比较深,应用也比较广,它模仿人类神经结构和处理信息的方法。数据样本先由从输入层到隐藏层再到输出层正向传播训练,在其过程中得到误差e,如果误差e不符合期望值,则反向传播。采用梯度下降原则对网络的权值和阀值进行多次调整,使误差e尽可能地接近期望值[7]。
BP算法流程如下:
1)设定输入层节点个数为i(i=1,2…,n),隐藏层节点为j(j=1,2,…,l),输出层为k(k=1,2,…m),初始设定输入层到隐藏层的权重wij,隐藏层到输出层wjk,输出层到隐藏层的阀值aj,隐藏层到输出层的阀值bk。
2)计算隐藏层的输出式见式(1),其中g(x)为Sigmoid激励函数。
(1)
3)计算输出层的输出式为:
(2)
4)误差e计算公式见式(3),式中ΔYk为期望输出。
(3)
ek=ΔYk-Yk
(4)
5)判断相邻2个误差的差别是否小于期望值,若是则保存权重和阀值,否则,将进行权重和阀值的更新,见式(5)~(8),直到达到期望值或者指定的迭代次数为止。式中,η为学习效率。
(5)
wjk=wjk+ηHjek
(6)
(7)
bk=bk+ηek
(8)
由上面BP算法流程可以看出权重和阀值是本算法的关键。在实际运算过程中,初始选取的权重和阀值,将直接影响最后运算效率。由于BP算法受梯度下降学习法的影响,在更新最优权值时容易陷入局部极小值,在实际运算过程中容易陷入运算僵局,无法得出结果。因此,有必须对权重和阀值在全局上得到优化,即可以避免陷入局部极小值,也可以大大提高运算效率和精确度。
2.2 DA算法
DA是MIRJALILI等[8]提出的一种新型群智能寻优算法,它是通过模拟蜻蜓群体飞行导航、捕猎和躲避天敌等行为对全局和局部同时进行搜寻,寻找最佳捕猎行为的算法寻优过程。蜻蜓群体的运动可以分以下5种行为。
1)分离行为,指单个蜻蜓与相邻蜻蜓之间的分离情况,其行为表达式为
(9)
式中:Si是蜻蜓i与相邻蜻蜓的分离度;X为当前蜻蜓所在的位置;Xj为相邻蜻蜓j的位置;N为相邻蜻蜓的数目。
2)对齐行为,表示单个蜻蜓与相邻蜻蜓的速度匹配,其行为表达式为
(10)
式中:Ai是蜻蜓i与相邻蜻蜓的对齐度;Vj为相邻蜻蜓的速度。
3)内聚行为,表示单个蜻蜓与相邻蜻蜓的集体聚拢,其行为表达式为
(11)
式中:Ci是蜻蜓i的内聚度。
4)觅食行为,指单个蜻蜓寻找食物,其行为表达式为
Fi=X+-X
(12)
式中:Fi表示蜻蜓i的觅食能力;X+为食物所在位置。
5)避敌行为,表示单个蜻蜓躲避外敌行为,其行为表达式为
Ei=X-+X
(13)
式中:Ei表示蜻蜓i的避敌能力;X-表示敌人所在的位置。
DA算法就是在更新蜻蜓位置的算法,有2种情况发生。
第1种,当蜻蜓有近邻时,蜻蜓可以通过以上5种行为方式来寻找飞行方向ΔX和空中位置X,并对方向和位置更迭变化,最终寻找最佳的结果。t+1是t的下一代,其位置和方向迭代更新的表达式:
Xt+1=Xt+ΔXt+1
(14)
ΔXt+1=(sSi+aAi+cCi+fFi+eEi)+ΔwΔXt
(15)
式中:s为分离权重;a为对齐权重;c为内聚权重;f为觅食因子;e为天敌因子;Δw为惯性权重。
第2种,蜻蜓无近邻,利用Lévy()函数更新蜻蜓位置,从而找到群体。Lévy()函数表达式如下:
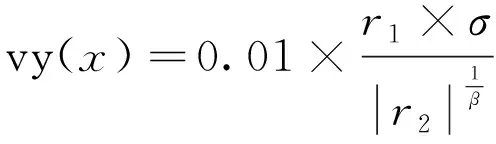
(16)
(17)
式中:τ(x)=(x-1)!;β=0.5的常量;r1,r2为0到1之间的随机数。蜻蜓位置更新数学表达式如下:
Xt+1=Xt+Lévy(d)ΔXt
(18)
式中:d为维度。
从以上可以看出DA算法具有较好的全局搜索能力,可以帮助BP神经网络算法将权重与阀值得到全局优化。但是它依然有缺点,因为蜻蜓个体之间没有过多的信息交流,每代的寻优没有充分利用上代的优秀个体,影响算法的收敛,容易出现过早收敛。
2.3 EIDA算法
为了避免DA算法收敛情况,采用多精英位置组合策略实现个体增强的DA算法,称为EIDA算法。采取的策略是选择新位置矩阵时,选中前3个最优秀个体,利用混沌映射随机性进行混沌线性组合。由于混沌的非周期性和遍历性,使得优化的线性组合能在已知最优秀个体附近进行局部寻找,这样就能充分利用上代优秀个体,极大地提高全局搜索的能力,避免过早收敛。
在解空间中N个蜻蜓在第t次迭代的位置矩阵为Xt=(Xt1,Xt2,…XtN),而其对应的适应值矩阵Qt=(Qt1,Qt2,…,QtN)每次进行迭代时,都会对应地构造增广位置矩阵XSt,QSt,并对增广矩阵建立QSt→XSt的排序映射,当排序结束后,把XSt中N个体构成新的位置矩阵XNt。
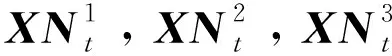
(19)
式中:rt为基于Cubic混沌映射的优化算子。
(20)
使用混沌优化的线性组合能不仅可以提高解的精确度,而且还能提高算法后期的收敛速度。
2.4 EIDA优化BP神经网络算法实现
运用EIDA全局优化能力,对BP神经网络算法进行优化,具体步骤如下。
步骤1 初始化以下参数:蜻蜓算法种群规模N;最大迭代次数M;空间维度d;惯性权重Δw;领域半径为r,蜻蜓5种行为权值s,a,c,f,e,BP神经网络的权值w、阀值φ等。
步骤2 将BP网络的权值w、阀值φ进行排序,组成行向量(w,φ),使之成为蜻蜓算法的位置X,根据权值、阀值的取值范围生成初始化位置X,同时也随机生成初始化飞行方向ΔX。
步骤3 计算个体蜻蜓的适应度。当迭代次数t>1时,建立上一代迭代的蜻蜓位置与当前蜻蜓位置的排序映射,通过蜻蜓个体适应度值,求得上代和本代得优秀蜻蜓个体,并记录当前最优个体位置X,这里X也就是BP 神经网络的权值w、阀值φ。
步骤4 利用欧氏距离公式算出当前最优解为食物位置X+和当前最差解为敌人位置X-,并对5种行为权值s,a,c,f,e和惯性权重w进行更新。运用公式(9)~(13)重新调整S,A,C,F,E的值。
步骤5 判断领域半径内是否有其他蜻蜓,如有利用公式(14)、(15)更新位置向量X和方向向量ΔX;若没有其他蜻蜓,则利用公式(18)更新位置向量X。
步骤6 利用公式(19)和(20)对蜻蜓位置进行混沌优化的线性组合。
步骤7 是否满足最大迭代数,若是,则停止运算;若不是,则当前的迭代次数加1并跳转步骤3。
3 实验设计与结果分析
3.1 实验设计
本次实验数据来自安徽统计局官方网站历年统计年鉴,在2012—2017年之间安徽省亳州市各地区的小麦种植数据。亳州作为安徽小麦主产区,自2012年成为全省首个小麦亩产千斤市以来,小麦种植管理配套齐全,农作物数据完备。实验分为2个部分:第一部分是在Spark和Hadoop这2个不同框架下对影响农作物产量因素数据做数据预处理,并用改进的DA-BP神经网络对小麦产量进行预测;第二部分是在Spark框架下对数据预处理,运用本文改进的DA-BP算法与PSO-BP和BP算法进行对比分析。
实验环境是以1台为Master节点,若干台为Slave节点,搭建Spark集群框架和Hadoop集群框架。所有节点机具有CUP i3 2.75 GHz 、内存4 G配置,使用linux操作系统。服务平台配置为ThinkServer RD650,处理器类型E5-2609v4,内存16 GB,硬盘1 T。
3.2 Spark和Hadoop不同框架下的实验对比分析
本实验是为了体现Spark和Hadoop不同框架下对数据处理能力,在同样的实验环境中先后架构Spark和Hadoop平台,对0.5 GB到200 GB的数据进行预处理。将不同平台下的数据处理效率进行对比,结果见图2。
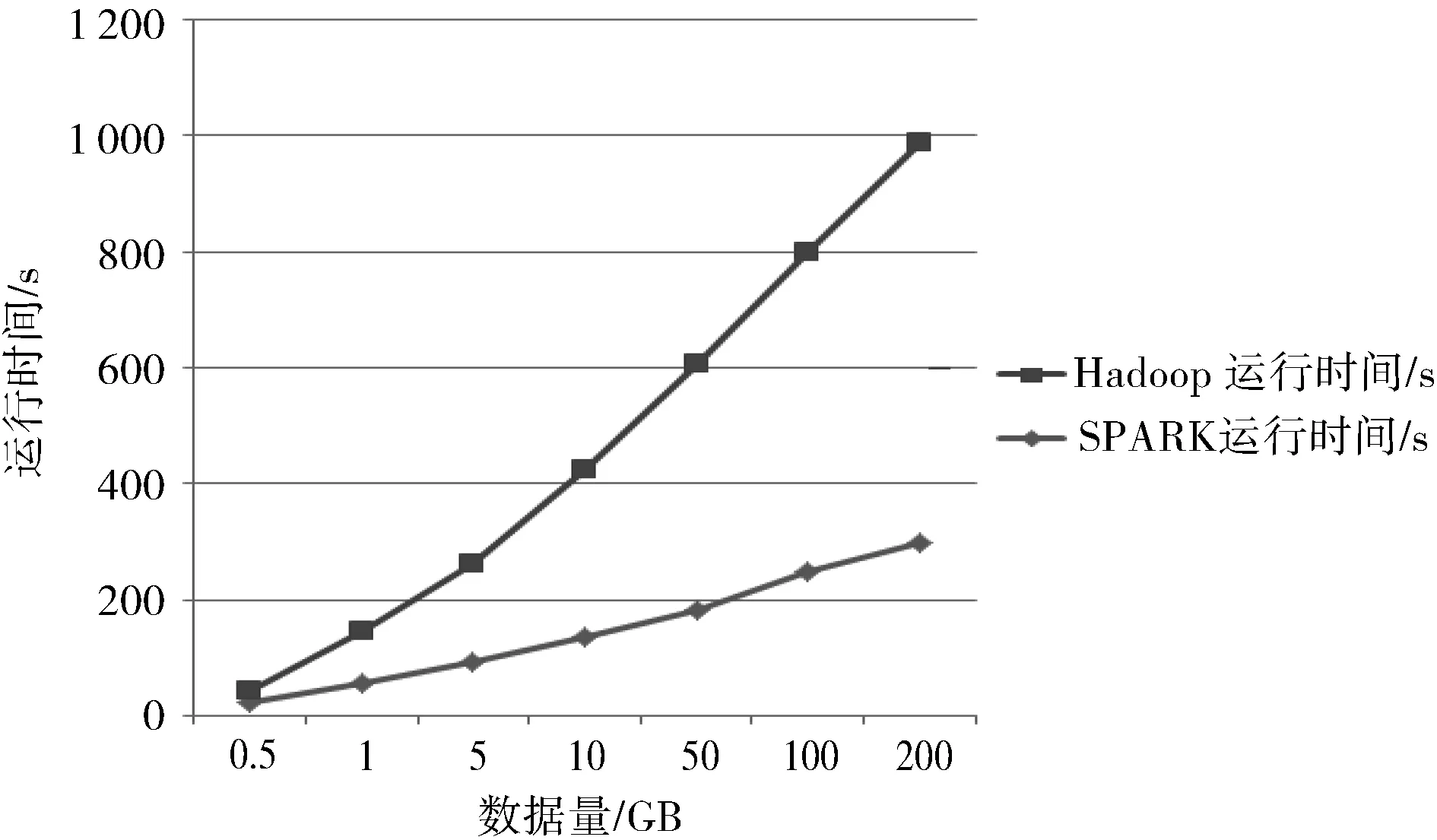
图2 Spark和Hadoop框架下不同数据量的运算时间Fig.2 Computing time of different data volumes under Spark and Hadoop frameworks
从图2可以看出:在Spark和Hadoop不同框架下,随着数据量增加,Spark平台下的数据处理用时明显要比Hadoop平台下的少。这是因为Spark是基于内存计算的,而Hadoop是基于磁盘计算的。在Spark平台中,计算所产生的中间值和结果写入内存数据集RDD中,减少了磁盘数据传输的开销,同时依靠RDD间的转换依赖关系,在很大程度上提高了数据容错性。所以,数据量越大,Spark平台下的数据处理能力越优于Hadoop平台的数据处理能力。
3.3 EIDA-BP算法与其他算法对比分析
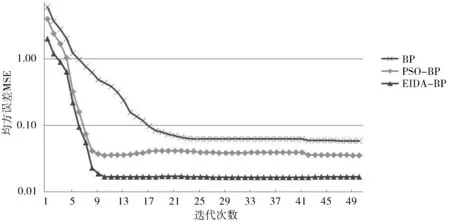
图3 三种算法均方误差(MSE)收敛比较Fig.3 Convergence comparison of mean square error(MSE)of the three algorithms
根据本文前面所述影响农作物产量的8个因素,可以确定输入层的神经元个数是8,而对小麦产量预测的输出层神经元为1。本实验将EIDA-BP算法与PSO-BP算法和BP算法进行比较。在EIDA-BP算法中,蜻蜓种群数量为20,最大迭代次数为60次,权值和阀值取值范围为[-1,1]。在PSO-BP算法中,步伐因子C1=C2=1.86,初始和最大惯性权值分别设定为Win=0.8,Wmax=0.4,最大速度Vmax=0.6。采用标准BP算法进行。在实验过程中,为了准确地反映3种算法的速度,将3种算法在运算过程中的均方误差(MSE)收敛走势进行比较,如图3所示。
从图3可以看出:EIDA-BP算法均方误差最小,最接近理论值;EIDA-BP算法和PSO-BP算法收敛速度比BP算法要快,这是因为BP在没有其他算法优化的时候,容易导致初始化权值和阀值不当,这将大大降低BP算法的速度。不管是PSO优化还是EIDA优化,它们的目的都是选出全局最优权值和阀值,在提高效率的同时也避免局部极小值发生。EIDA-BP算法比PSO-BP算法的均方误差还要小,是因为EIDA 的收敛精度和寻优能力都高于PSO-BP算法,且PSO-BP算法存在过早收敛的情况。
最后用3种算法对亳州各区小麦产量预测,预测的精确度和期间算出的MSE比较如表1所示。
表1 3种算法精确度和最佳MSE对比
Table 1 Comparison of accuracy and optimal MSE of the three algorithms

参数算法EIDA-BP算法PSO-BP算法BP算法最佳MSE0.01630.01890.0227精确度/%98.394.688.0
从表1可见:EIDA-BP算法的精确度明显高于其他算法,同时最佳MSE也是最小的,接近理论值。
4 结论
本文通过先Spark框架对影响农作物产量因素数据做数据预处理,再用EIDA-BP算法对2012—2017年安徽亳州小麦产量进行预测。在实验过程中发现Spark框架比Hadoop框架下数据处理速度快很多,EIDA-BP算法比PSO-BP算法和BP算法精确度更高。因此,采用基于Spark框架的EIDA-BP算法对农作物产量进行预测具有一定的意义,可以为农业信息化建设提供可靠支持。
