大规模科学数据体绘制技术综述*
2020-05-06王华维
王华维,何 柳,曹 轶,肖 丽, 2
(1. 北京应用物理与计算数学研究所 计算物理重点实验室, 北京 100088;2. 中物院高性能数值模拟软件中心, 北京 100088)
随着千万亿次计算机的出现以及数值模拟技术的不断进步,激光聚变、高温高压物理、大气与环境等众多应用领域需要使用成千上万个处理器核来实现高精密的三维数值模拟,以得到高科学置信度的模拟结果,促进相关领域科技水平的持续快速发展。当前,由于物理建模的精细化和并行规模的增加,数值模拟的计算规模达到了成千上万倍的增加,相应地,它们输出的数据规模也大幅增加:单时间步数据量可以达到十几字节甚至数十GB(十亿字节),一次完整模拟输出的时变数据总量将达TB(万亿字节)甚至是PB(千万亿字节)量级。例如,应用全波电磁场时域求解器(JEMS-FDTD)对L波段隐形战斗机整机瞬态电磁特性做数值模拟时,使用6000个处理器核进行了2万个时间步的模拟,网格规模为3400×2000×1060(约72亿个网格点),单时间步输出数据量为173 GB,共输出了200个时间步的结果,时变数据总量达到了34 TB。
高精密数值模拟输出的大规模数据集对领域专家分析物理问题提出了极大的挑战,主要困难存在于以下方面:
1)数据场中物理量变化剧烈,特征多样,而且在空间或时间上分布不均匀,难于精确刻画或准确定位;
2)数据量极大,并以复杂的拓扑组织分布式地存储于并行机多结点上,对处理和分析带来极大困难;
3)根据实际应用不同,数据集具有多种不同的复杂网格结构,例如直线网格、自适应结构(AMR)网格、变形结构网格或者非结构网格等。
如何有效、高效地把大规模复杂三维数据场中的物理特征以可视的方式展现出来,让领域专家能有效、深入地观察、理解和分析物理现象,从而得到科学发现或验证科学设想,是实际应用领域迫切需要解决的问题。
体绘制是实现三维数据场可视化的核心算法之一[1-4],它可以直接而有效地展示数据场内部的物理现象,具有非常强的表现力。该方法从视点向屏幕上的各个像素发出光线,光线穿过数据场时对数据场做重采样,然后根据光学模型计算采样点颜色效果并依视点顺序融合起来,即得屏幕上像素的颜色值,参见图 1。绘制质量和绘制效率是人们所关心的两个核心问题,即一方面要准确表现出数据场内部信息,另一方面还要满足交互可视分析的速度要求。随着科学计算技术的不断发展,模拟得到的物理现象越来越精细,理论上,不断加密采样点即可在体绘制中准确表现各个物理特征。然而,体绘制中采样计算与图像合成都是非常费时的,且两者的计算开销都与采样点总数成正比,因此,不断增加采样点势必引起巨大的计算开销,并导致绘制时间过长,甚至引起系统崩溃。

图1 光线投射原理图Fig.1 Principle diagram of ray casting algorithm
为了适应日益增长的数据量以及数据中日益复杂的物理特征,研究者们从多个方面对体绘制算法进行了深入研究,以不断提高绘制效率、增强绘制效果。
1 体绘制并行加速技术
1.1 并行绘制
引入并行处理技术,发展并行体绘制算法,是提高绘制效率的一个有效途径[5-6]。各种体绘制算法可以通过并行机的多核加速能力来提升性能,包括光线投射法[7-8]、单元投影法[9]、错切-变形法[10]以及抛雪球法等[11]。由于体绘制的主要计算集中于采样计算和图像合成两个阶段,因而典型的并行模式按数据并行和图像并行分两步实现,而其中的I/O策略、数据组织以及负载平衡等是影响并行效率的重要因素。在分布式可视化软件VisIt[12]中,Childs等提出了一个基于合约的可视化流程[13],可根据绘制参数在合适的可视化阶段执行相应优化策略,例如I/O预筛选、数据规整化、负载平衡选择等,由此提高了绘制效率。混合并行格式是他们采用的另一种负载平衡优化办法[14]。后来,Moloney等提出了一个动态负载平衡策略,可预估各个像素的绘制开销从而平衡地分配计算任务[15]。尽管在并行体绘制中数据后排序方式被广泛采用,然而,Moloney等研究发现有几种并行体绘制算法在先排序方式下可以有更好的性能[16]。针对大规模并行机,Howison等提出了MPI+OpenMP混合并行绘制算法(参见图2),充分利用多核结点上的共享内存以减少内存消耗和数据通信量,绘制中并行规模可达21.6万核,对46 083的超大规模网格数据实现高分辨率图像的交互绘制帧率[17]。
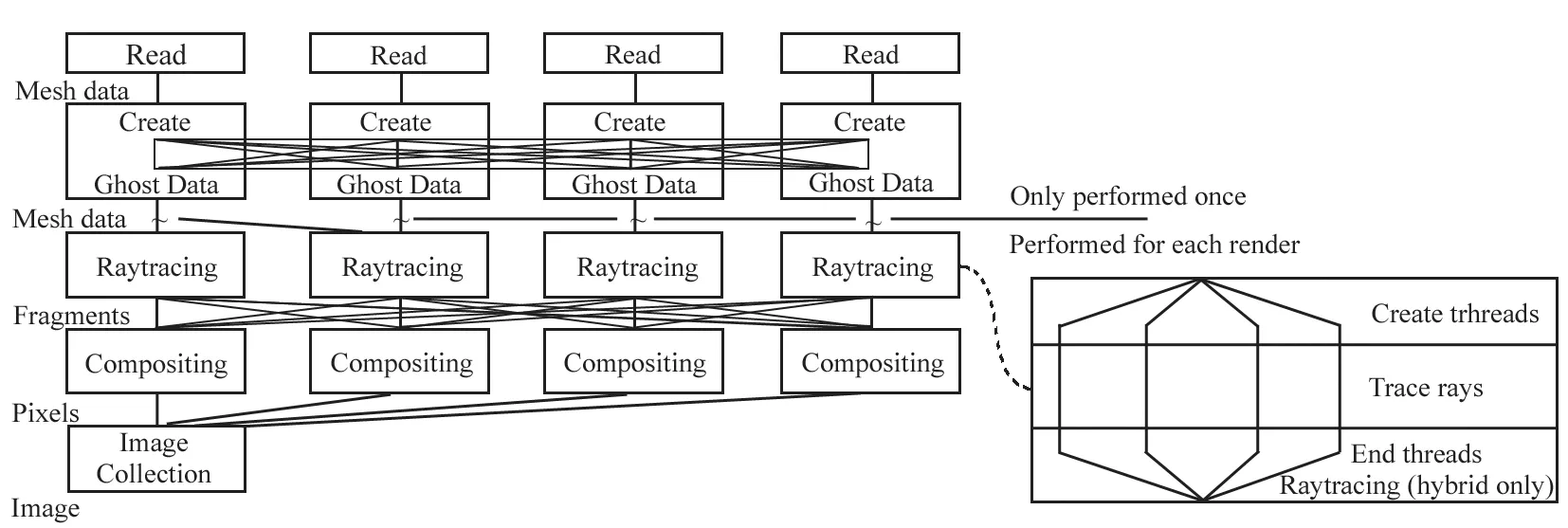
图2 MPI+OpenMP混合并行绘制算法[17]Fig.2 Hybrid parallel rendering MPI+OpenMP algorithm[17]
1.2 GPU硬件加速
利用GPU硬件加速功能,加快绘制流程中的采样和合成计算,是提高体绘制效率的另一个办法[18-23]。Engel等探讨了多纹理和相关纹理读技术,以实现基于纹理的预积分体绘制算法,可取得高质量的绘制效果[24]。Stegmaier等则发展了一种灵活的硬件绘制框架,可集成单程光线投射算法的多种不同形式[25]。利用图形硬件可编程能力,还可以加速估算采样间距[26]或确定采样点位置参数[27]这些较为复杂的计算,提升自适应采样策略下的体绘制性能。Singh和Narayanan提出了一种基于光线投射的隐式曲面绘制算法[28],其核心为自适应推进求根法,非常适合GPU的SIMD运算模式,因而该算法取得了较高的绘制效率。由于GPU纹理内存容量有限,不少工作也投向了纹理数据压缩及其随机访问技术,并探讨了适用于GPU的有效数据结构[29-30]。Fout和Ma提出了基于块的变换编码压缩方法[31],该方法在压缩时能保持感觉上重要的体特征因而不影响绘制质量,而且它的解压速度也很快。kD-Jump[32]是最近提出的一种无栈遍历技术,可有效操作隐式kD树,让遍历程序直接返回到下一个有效节点而无须额外的节点访问。另一方面,GPU也常常被装上可视化并行服务器,使得人们可以用并行机的海量存储能力以及多CPU耦合多GPU的双重加速能力来应对大规模数据集的高质量快速绘制。孔明明等[33]在用千兆以太网互联的可视化机群系统(含16个结点,配备NVIDIA 5950图形卡)上,采用基于三维纹理映射的硬件加速并行体绘制算法,实现了Visible Human数据集的可视化,其数据量约为3 GB,绘制速度达到2 s。Fogal等[34]在可视化机群上开展的并行可视化算法研究表明,他们已可使用128个计算结点耦合256颗GPU,完成单时刻千亿量级数据的体绘制,网格单元数量达到百亿。
1.3 光线追踪体绘制
随着高性能计算机硬件体系结构越趋复杂,包括体绘制在内的可视化算法需要不断重构、优化才能适应包含多核/众核CPU的复杂硬件结构。应对该挑战,Wald等[35]设计了一种基于CPU光线追踪的科学可视化通用框架OSPRay,可以运行在不同SIMD宽度和多样化HPC计算资源上。该框架提供了一个与OpenGL同级别的抽象API,可集成到目前主流的可视化软件中,例如VTK、ParaView和VisIt等。图3显示了OSPRay的系统组件及其相互关系。
与现存的光线追踪框架Manta[36]和Embree[37]相比,OSPRay更加注重对于体数据的有效支持。该框架通过光线追踪技术实现体绘制,能充分利用当前最新的众核CPU环境。Wald等在工作站和TACC节点这两种具有代表性的平台上(其中工作站使用了Intel Xeon E5-2699 v3 CPUs 以及一块 NVIDIA Titan X 图形卡,TACC节点使用了两块 Intel Xeon E5-2680 v2 CPUs 和一块NVIDIA Tesla K40m 图形卡),对基于OSPRay和基于OpenGL的ParaView进行了性能对比。在仅仅使用CPU渲染时,OSPRay的性能大幅超过Mesa,而对于GPU渲染,OSPRay也取得了比OpenGL更优的性能表现。
在此基础上,Wu等提出了VisIt-OSPRay高性能可扩展的混合并行绘制系统[38],将OSPRay体绘制算法扩展为一种MPI加线程的混合并行模式,在一个计算结点上应用可高效使用众核处理器的CPU并行OSPRay[35],在结点间采用sort-last绘制流水线代替direct-send融合器完成图像融合,由此,在生成与经典光线投射体绘制相当的效果下,他们取得了30倍的绘制加速比,并且将体绘制算法并行扩展到了32 768个CPU核上。
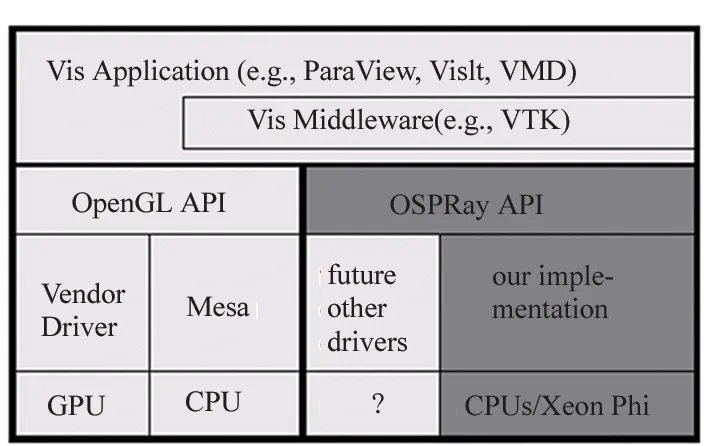
(a) OSPRay API在常见的可视化应用程序软件堆栈中的位置(a) OSPRay API in the context of the ubiquitous software stack found in visualization applications
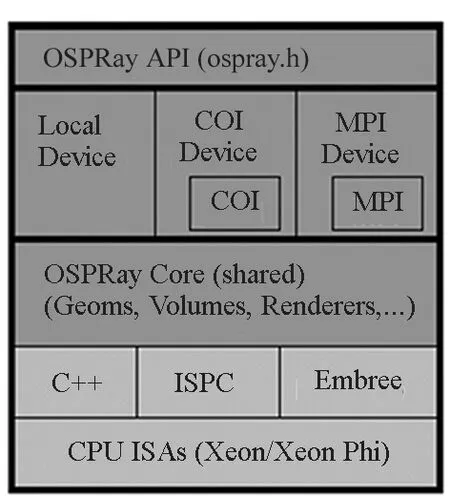
(b) 基于CPU实现的OSPRay组件结构图(b) OSPRay components that comprise our CPU-based implementation.图3 OSPRay的软件架构及其在可视化应用中的定位[35]Fig.3 Software architecture of OSPRay and its location in visual applications [35]
2 体绘制数据约简技术
2.1 自适应绘制
采用自适应采样方法,用较少的采样点来刻画数据内在物理变化,从而减少计算、内存和通信等多方面的开销,也是提高绘制效率的一个重要途径。常见的自适应采样方法包括空间跳跃[2]、分层次自适应采样[8,39]、细节导向的采样法[40]以及梯度场量值法等[41]。另外,Kraus等利用一个“启示器”程序来估算合适的采样间距,并据此在三个方向上实施自适应采样[26],可大量减少采样点。Suwelack等则从转换函数和数据集的谱分解中导出相配的采样准则,集成得到一个基于GPU加速的自适应光线投射体绘制算法[42]。Corcoran和Dingliana利用图像帧间一致性来快速生成二维的重要性图谱,由此指导进行自适应采样,在视点或转换函数改变时实现体绘制图像快速刷新[43]。然而,以上方法均难以在降低采样点的同时,准确把握住物理量取值的变化规律,针对这个问题,Marchesin和Verdière提出了一个自适应单元投影体绘制技术[27],在绘制中可以很好抓住物理量变化的单调区间,得到满意的绘制效果。大规模科学计算中的数据量远远超过了单机硬盘和内存的容量,此时,并行处理体绘制是不可或缺的,但在并行模式下进行自适应采样,其中的采样点数据组织、数据块空间关系、依视点有序性以及负载平衡等方面都将面临难题。虽然参考文献[8]的引文和文献[39]中的绘制算法是并行模式,但它们只是针对AMR网格的简单按层自适应,而在单层数据分块上仍是均匀采样格式。为了适应大规模科学数据,Wang等[44]改进了Marchesin和Verdière的自适应采样方法(参见图4,蓝色采样点将在跨单元判断中被舍弃,红色采样点被保留),并在分布式并行环境下实现了算法并行化,解决了算法中采样点管理与负载平衡等问题,相对于分布式环境下传统均匀采样方法取得了较大的性能提升。
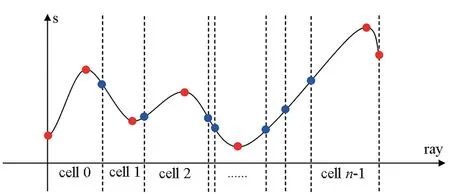
图4 改进的自适应采样方法[44]Fig.4 Improved adaptive sampling method[44]
2.2 多分辨率绘制
发展多分辨率绘制技术,在图像质量和绘制速度之间折中,从而在有限的资源预算下最快地得到绘制结果,也是处理大规模数据、优化绘制性能的一类方法。Han-Wei Shen研究组的Gao, Wang等提出了基于小波的多分辨率体绘制框架[45-46],参见图5,他们将数据转换为一种多分辨率小波树的结构,通过子树划分与预选节点重构优化了并行绘制中的负载平衡和数据通信。Knoll等则提出了一种多分辨率光束跟踪体绘制算法,可以在普通PC上绘制较大的体数据[47]。Suter等对体数据建立了一个基于张量逼近的多分辨率格式,并实现了三维数据场的多尺度特征可视化与多分辨率体绘制[48]。Sicat等提出了一种不同的多分辨率体数据表示格式——概率密度函数(probability density function, pdfs)稀疏体,即允许对大规模体数据做out-of-core计算,又可以实现GPU上的交互多分辨率体绘制[49]。基于多分辨率技术的进一步算法优化还包括基于图像质量评测的细节层次选择[50]、视点相关的数据裁减[51]、突出重点区域的混合分辨率绘制[52]、基于小波的数据压缩等[53]。
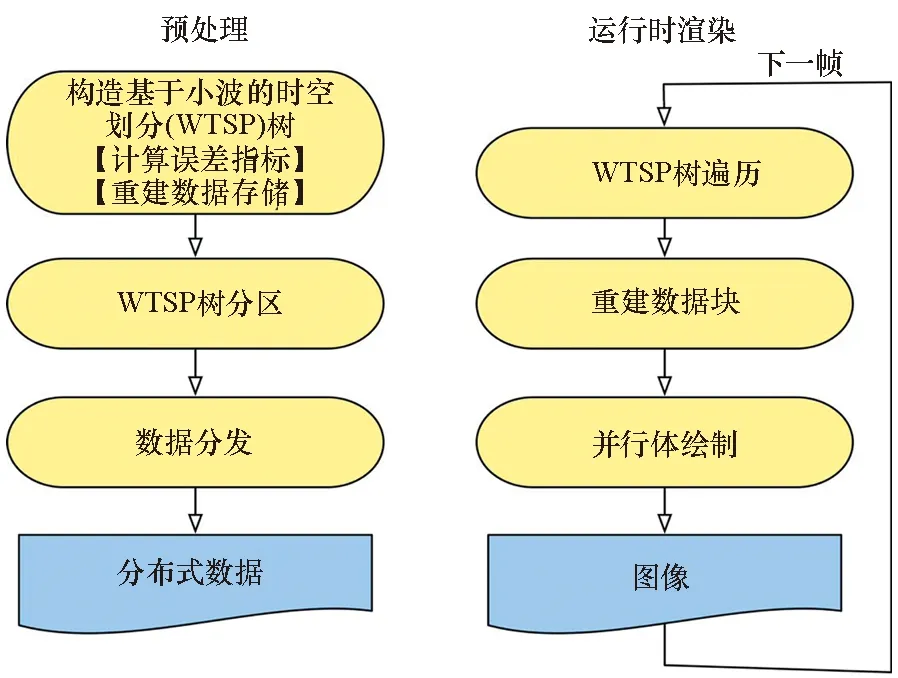
图5 大规模时变数据多分辨率体绘制的算法流程简图[46]Fig.5 Algorithmic flow chart of multi-resolution volume rendering for large-scale time-varying data[46]
2.3 PDF约简模型
让数值模拟与可视化紧密结合、协同工作,基于概率分布函数(Probability Distribution Function, PDF)对计算结果在原位直接进行数据分析与约简处理,可以有效减少数据传输和I/O开销,满足大规模数值模拟数据及时或实时可视分析的需求[54]。Han-Wei Shen研究组的Wang等[55]用基于高斯混合模型的概率分布函数来原位约简数据,然后进行基于统计的高质量可视化,提出用空间高斯混合模型(Gaussian Mixture Model, GMM)对空间信息压缩存储,将之前基于分布的表示方法中没有包含的空间信息考虑进来。为了保证较小的存储开销,使用自适应方案来确定每个空间GMM所需的高斯分量数目。他们定性地将他们的表示与现有的分布表示进行了比较(见图6,测试数据为Isabel数据集,500×500×100网格点[55])。他们的方法能够计算任何位置的值的概率密度函数,它代表了可能的值及其出现概率,实验结果令人满意,在每个体素处具有较小的偏置和方差。
Wei等[56]对于多种场混合的数据集提出了两种有效的基于局部分布的特征搜索算法。一种是边缘特征搜索,该算法可以为用户提供对于每个数据场的特征描述进行视觉探索;另一种是联合特征搜索,用户能够探索基于局部区域的若干属性的联合特征。Dutta等[57]提出了一种局部各向同性驱动的分块随机数据汇总技术,该算法可以在原位(in-situ)工作,并且通过分块汇总来保留数据统计属性,从而实现有效的概率特征分析和可视化。Wang等[58]提出了一种基于图像和分布的大规模数据分析表示,它可以将传递函数的探索以及不确定性量化。他们通过科学家对图像做出的选择以及后处理机器所能承受的带宽与存储来生成代理(proxy)。只需要访问这些代理,就可以在后处理机器上执行分析和可视化。 Hazarika等[59]提出一种灵活的基于分布的不确定性建模策略,该策略基于统计健全的多变量技术——Copula。这项技术专门针对科学数据集不确定性建模的需要而定制,使用这种灵活的策略,他们提出了一种在标量以及矢量场里提取不确定性/概率特征的方法。
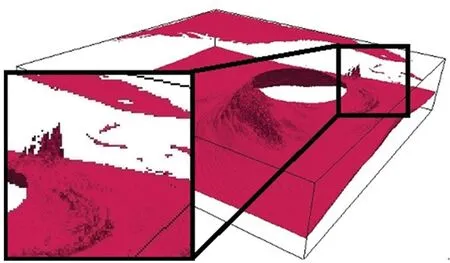
(a) 原始数据集渲染图(a) The field from the raw data

(b) 使用块直方图(b) Block histogram

(c) 使用带有插值的块直方图(c) Block histogram with interpolation

(d) 使用高斯混合模型块(d) Gaussian mixture model block
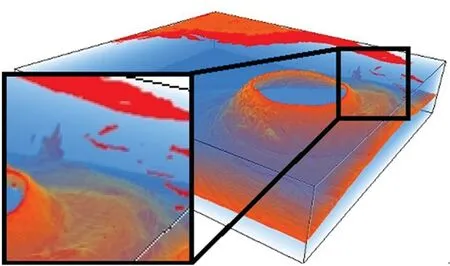
(e) 使用PDF约简模型(e) results obtained using the PDF reduction model图6 使用基于PDF 约简模型渲染出的效果图[55]Fig.6 Rendering effects using distribution-based representation[55]
3 体绘制效果增强技术
3.1 信息辅助可视化
借助于信息熵[60],抽取出包含感兴趣特征或重要信息的数据部分并在绘制中赋以特别的表现力,是应对时变海量数据可视分析的重要手段。利用互信息测度,Viola等提出了一个重要性驱动的自动聚焦方法[61],以便于观察体数据中的不同特征。Wang等[62]则利用条件熵构造重要性曲线,以刻画局部数据的时间特性,然后通过聚类来分析各个重要性曲线的不同时间趋势特征,从而得到了一个展示、理解时变数据所蕴含动态时间特征的有效方法,参见图7。绘制时变数据的时候,人们还可以利用Shannon熵来找出最佳的静态或动态视点位置[63]。Feixas等则把Shannon熵和KL距离[64]联合起来,发展出高效的视点选择和效果加强算法[65]。Wang和Ma分析了在大规模数据可视分析中信息与知识驱动求解方法的重要性,并总结了相关的几个研究方向[66]。

图7 绘制中只突出一个重要性曲线聚类对应的数据特征而忽略其他[62]Fig.7 Only the data features corresponding to the clustering of curves of importance are highlighted, while the others are ignored in rendering[62]
3.2 预积分绘制
在相邻采样点之间插补中间信息并计算光强积分,可减少合成误差,提高绘制质量;另一方面,预先计算光强积分,供实时绘制中直接取用,可提高绘制效率。在预积分体绘制中,常用的插补函数包括一次[24]和二次多项式[67]。Guetat等在预积分中很好地集成了光照模型,减少了绘制误差[68]。Lum等给出了预计算积分的快速算法[69],而Kye等则简化了预积分表[70]。
3.3 转换函数设计
转换函数直接关系到体绘制的输出效果,是体绘制的本质参数之一,因而深受重视。研究者们设计出了大量的转换函数,用以突出表现数据中蕴含的各种时空特征。这些转换函数主要分为两类:数据型和图像型[71],数据型转换函数包括基于特征尺度[72]、空间遮挡频谱[73]、密度聚类[74]以及可见性[75]的转换函数等,而Wu和Qu[76]提出以编辑图像来指导转换函数生成,这样得到的是图像型转换函数。Guo等提出了一种“所见即所得”的可视化方法,可直接在体绘制图像上简单勾画,即实现对转换函数的相应修改,并由此设计了多种绘制效果编辑工具[77]。最近,Zheng等建立了反映深度有序感觉的能量函数,并通过优化能量函数来调节透明度和光照参数,从而提升体绘制中深度有序效果,更好展现数据场内部结构[78]。
3.4 光照效应
引入、改善光照效果可提升绘制质量,主要办法包括:在预积分体绘制中集成光照模型,这需要线性[69]或非线性[68]插值梯度方向;调节物质界面上的光照参数以增强界面表现效果[79];在绘制中加入光衰减效应[80]或全局光照效果[81]等,图8为使用全局光照渲染出具有128×128×64网格点的发动机工业CT扫描结果。其中图8(a)为对照,使用了基于局部光照的光线投射算法,图8(b)和(c)都使用了全局光照。其中图8(b)为使用材质A得到的全局光照图,该材料吸收绿光和蓝光子的速度更快,并沿光的方向逐渐变红,图8(c)为使用另一种材质B得到的全局光照图,该材质在高密度区域显示为饱和红色,周围区域由于渗色而饱和度较低。Kniss等[82]提出了一个基于小部件的界面,用于直观地指定高维不透明度/颜色转换函数,并描述如何在图形硬件中有效地实现这些高维转换函数。他们还通过在屏幕外渲染缓冲区中累积衰减光来描述阴影的渲染,使用标量梯度幅度避免均匀材料的阴影。
为了更真实地渲染自然现象,已经有人通过使用更复杂的体积光照模型来做各种工作[83]。此外,在应用更逼真的可视化模型方面,Krueger[84]使用与数据集具有各种光照交互的粒子模拟将传输理论应用于体绘制。Rodgman和Chen[85]允许包括折射率的转换函数来模拟由于折射引起的光弯曲的影响。Noordmans等[86]模拟光的颜色变化,因为它与材料相互作用,并允许色彩不透明,而不是单个标量。Kniss等[80]使用图形硬件有效地生成高度逼真的渲染,模拟体积阴影,前向散射和色度衰减的影响。通过光照效应还可以作为说明张量场的手段。除了使用颜色和不透明度转换函数之外,Kindlmann和Weinstein[87]还描述了使用光照张量来指示各向异性的类型和方向的想法。
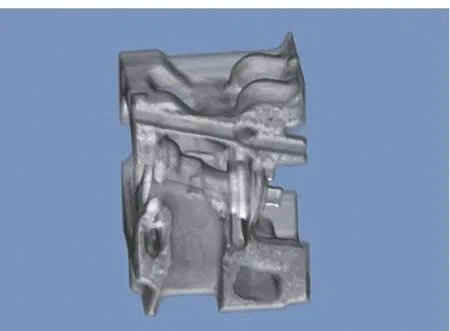
(a) 使用了局部光照的光线投射算法(a) Ray casting with local illumination

(b) 使用材质A得到的全局光照图(b) Ray casting with global illumination using material A

(c) 使用材质B得到的全局光照图(c) Ray casting with global illumination using material B图8 发动机工业CT扫描的全局光照渲染结果Fig.8 Global illumination of an industrial CT scan of an engine
3.5 边界增强技术
为了增强体绘制结构的显示效果,令绘制结果能够更有效地反映出体数据的结构特征,最有效的方式就是将体数据中物体的细节,比如边界、轮廓等突出绘制。增强边界显示效果的方法有很多,Lum等[79]提出了一种基于梯度采样的光照传递函数,用以突出显示物质之间的边界面,图9为一系列使用不同方法得到的马达CT数据的绘制结果。其中图9(a)没有使用光照效果,其内部结构几乎无法看到;图9(b)加上了光照效果,棕色区域变得清晰,但是在均质区域中,光线的不规则变化使我们很难看到物质的边界;图9(c)通过增加这些边界处的不透明度,边界表面变得清晰可见,但是很难观察出均匀区域处的厚度;图9(d)使用光照传递函数得到的结果图,既能看到清晰地物质边界,又能感受到均值区域的厚度。Tenginakai[88]提出了一种使用局部k阶中心矩及其相互关系定位物质边界处的显著等值面的方法。Roettger等[89]提出了通过将二维直方图中的空间连接区域归组进行物质边界分类。Huang等[90]加入了空间信息,将传递函数的定义域扩展到三维,利用设计的代价函数在三维空间中执行区域增长算法,准确地揭示了物质边界。Wang等[91]在二维特征空间内利用高斯混合模型和椭圆形的传递函数,提高了边界面的准确度和传递函数的设计效率。Caban等[92]提出了基于纹理特征的传递函数,为每一个体素计算多种纹理特征,在添加了纹理特征后,体素的结构可以得到有效的区分。Tzeng等[93]提出将采样点的空间信息作为自变量,利用神经网络设计了高维传递函数,更好地提取用户感兴趣的物质。

(a) 在棕色区域不使用光照效果(a) No lighting effects in brown areas

(b) 加上光照效果(b) Add lighting effects

(c)增加边界处的不透明度(c) Increase the opacity at boundaries

(d) 使用光照传递函数的效果(d) Use the light transfer function图9 不同方法得到的马达CT数据的绘制结果[79]Fig.9 Images generated from a CT scan of an engine[79]
4 体绘制技术展望
对于TB量级时变数据场,虽然可用数万核的大规模混合并行实现交互体绘制[17],但这样庞大的计算资源在实际应用中是极难得到的。一方面,大规模并行机常常承担着繁重的科学计算任务,其计算资源是非常宝贵的,一般系统仅把其中10%的结点分配给可视化任务使用。另一方面,在目前的并行体绘制算法中,主要是应用均匀采样或分层均匀采样,而没有根据数据内在特性有效地设定采样点,因而浪费了计算与存储资源。一般而言,在数百至数千核并行规模下,为了清晰展现精细物理特征,未来人们还需进一步探讨高效率的体绘制算法,从软件和硬件两个角度加速算法,绘出最佳效果,取得最快速度。
应对TB量级以上时变科学数据,清晰快速展现数据中蕴含的精细物理特征,人们可从四个方面进一步探讨体绘制技术:
1)应用驱动的特征体绘制。针对具体应用中的复杂数据特征,研究特征分析与抽取技术,重点展现用户感兴趣特征,发展复杂特征的体绘制效果增强技术,提升特征结构的层次感与真实感。
2)基于特征的约简体绘制。深入挖掘数据内在特性,研究基于特征的数据约简技术。在大幅降低数据处理量的同时,准确把握数据场中精细物理特征,进一步发展相应的自适应体绘制算法,显著提升数据特征的绘制效率。
3)适应硬件的体绘制多级加速。适应高性能计算机复杂体系结构,发展结点间多进程数据并行处理、结点内多核耦合加速器多线程局部数据并行处理的混合并行绘制技术,对体绘制算法进行多级加速。
4)原位智能化体绘制。紧密耦合数值模拟应用与后处理可视化,发展原位处理与绘制技术,避免I/O瓶颈,在原位模式下研究自动特征分析技术与自动转换函数设计方法,发展智能化体绘制算法,避免交互瓶颈。
基于这四个方面的发展,未来有望显著提高体绘制的速度和效果,实现TB量级以上时变科学数据的交互绘制性能,满足应用领域对交互可视分析的急切需求。
5 结论
本文对于目前大规模科学数据体绘制研究中的两个关键问题——绘制效率和绘制效果的研究现状进行了总结。近几年,随着科学计算的发展以及HPC运算能力的提高,科学与工程模拟产生的数据量越来越大,传统的科学可视化方法越来越难以应对千万亿次计算数据的处理与分析。为了解决超大规模计算数据分析的性能瓶颈,研究者们提出了并行加速和数据约简等方法来提升绘制处理效率。同时,为了实现高逼真度的绘制效果,研究者们在特征抽取与效果增强等方面也取得了较好成果,更好的绘制效果可以带给领域专家更多的信息。应对未来更庞大的数据量、更复杂的物理特征,体绘制算法的效率和效果还需不断加强,这要求研究者们持续深入开展相关研究。展望未来,可能进一步开展的研究包括应用驱动的特征体绘制、基于特征的约简体绘制、适应硬件的体绘制多级加速以及原位智能化体绘制等。通过这些研究,未来力争显著提高体绘制的速度和效果,满足应用领域对TB~PB量级数据交互可视分析的急切需求。
