融合注意力机制和BiLSTM+CRF的渔业标准命名实体识别
2020-05-06程名于红冯艳红任媛付博刘巨升杨鹤
程名,于红*,冯艳红,任媛,付博,刘巨升,杨鹤
(1.大连海洋大学 信息工程学院,辽宁 大连 116023;2.设施渔业教育部重点实验室,辽宁 大连 116023;3.辽宁省海洋信息技术重点实验室,辽宁 大连 116023)
命名实体识别是自然语言处理领域的一项基本任务,是语义分析、问答系统、机器翻译、知识图谱构建的基础[1]。渔业标准文本是渔业生产的指导性文件,渔业生产技术人员经常需要查阅、理解渔业标准内容,进而应用渔业标准指导生产,这就需要构建渔业标准内容服务系统以方便查阅渔业标准内容。人工构建渔业标准内容服务系统耗时耗力、成本高,难以保证数据一致性,因此,需要研究渔业标准文本语义分析技术以实现标准文本内容的自动理解和知识抽取,为渔业标准内容服务系统[2-3]的构建提供基础服务。渔业标准命名实体识别是进行渔业标准文本语义分析的基础,因此,对此进行研究具有重要的意义。
命名实体识别概念最早在MUC-6 Message Understanding Conference会议上被正式提出,目的是识别文本中具有特定意义的实体。国内外学者对此进行了大量研究,早期主要采用规则和词典方法,张跃等[4]结合了词典和规则方法对中文姓名进行了识别,取得了较好的效果;赵军等[5]结合统计方法和句法分析方法提出了基于例子的基本名词短语识别模型,较词典与规则方法取得了较高的召回率和精确率;方晓珊等[6]使用了词典与句法规则方法,通过学习新的规则来增强模型的泛化能力,取得了较好成绩;但是通过词典和规则的识别方法严重依赖词典的覆盖程度和领域知识。随着信息量指数级的增长,新词不断涌现,基于词典和规则的术语识别方法不再适应复杂的文本信息处理任务。为了克服基于词典和规则识别方法的不足,夏光辉等[7]提出了基于词典与条件随机场的混合模型基因命名实体识别算法,保证了准确率的同时优化了时间复杂度。冯艳红等[8]将渔业领域术语字符特征融合到条件随机场模型中,不再依赖词典与句法规则进行渔业领域命名实体识别。相对于词典和规则方法,统计学习方法的各项性能取得了较大提升,但是该方法较依赖领域专家设计的特征模板,在进行命名实体识别任务时缺乏泛化能力。
深度学习技术避免了统计学习依赖人工选择特征的问题,在自然语言处理、计算机视觉领域已成为研究热点[9-13]。毛存礼等[14]首次将深度学习方法应用在有色金属领域处理命名实体识别任务,实现了有色金属领域产品名、矿产名、地名、组织机构名的实体识别;Lyu等[15]采用双向LSTM进行生物医学命名实体的研究,并在JNLPBA 2004数据集上取得了73.79%的F值;Xu[16]等在临床医学命名实体识别研究中证明了BiLSTM在没有特征工程和更少的标注数据情况下效果优于CRF算法。孙娟娟等[17]利用LSTM+CRF模型实现了渔业领域命名实体识别,取得了较好效果。但是LSTM网络并没有考虑序列的前后顺序因素,且存在长序列语义丢失的问题。从目前的研究工作看,基于深度学习的术语识别在各个领域均取得了较好的效果。由于领域之间存在差异,且深度学习在长序列文本上存在语义丢失的现象,上述模型不能直接用于渔业标准术语识别,因此,需要针对渔业标准术语识别的特点,开展基于深度学习的渔业标准命名实体识别研究。
基于深度学习的命名实体识别算法基础是构建语料库,传统命名实体识别的语料库标注采用BIO标注法[18]针对人名、地名、机构名进行标注。由于渔业标准数据分析的特殊性,在命名实体识别任务中需要关注标准与标准之间的联系及标准内容的结构信息,这需要渔业标准命名实体识别任务关注标准文本中“渔业标准号”和“渔业标准指标”两类实体,传统的语料库不能满足渔业标准文本语料库的要求,不适用于渔业标准命名实体识别任务。同时BiLSTM+CRF模型存在长序列语义稀释的问题。本研究中,针对渔业标准文本的结构特点对标注方法进行研究,构建了融合注意力机制和BiLSTM+CRF的渔业标准命名实体识别方法,并基于BIO标注法提出E-BIO标注法,通过模型有效提取句子中的结构化信息,提升模型精度,旨在提升渔业标准命名实体识别的效果。
1 渔业标准命名实体识别模型
针对渔业标准命名实体识别中上下文向量权重不均、长序列前端语义稀释等问题,结合注意力机制提出了BiLSTM+Attention+CRF渔业标准命名实体模型,总体框架如图1所示。模型由Char Embedding层、BiLSTM编码器、Attention层和CRF解码器4部分组成。Char Embedding输入层将句子以字符为单位转换成低维、稠密的向量[17];BiLSTM编码器从输入层的向量中学习渔业标准命名实体的上下文特征h;Attention层通过注意力机制根据BiLSTM上下文特征向量动态也输出特征向量Ci;最终由CRF解码器将Attention层输出的特征向量转化成序列标签,得到渔业标准命名实体。
1.1 BiLSTM编码器
通过对渔业标准命名实体分析发现,渔业标准命名实体长度较长,构成渔业标准命名实体的字符与上下文存在较强的依赖关系,而基于循环神经网络的LSTM Long Short Term Memory网络可以在当前时刻保留上一时刻的信息,所以LSTM网络实现了渔业标准命名识别任务的长序列记忆功能,但是LSTM网络存在当前时刻后词权重大于前词权重的问题。
LSTM网络是循环神经网络的变体。循环神经网络是基于时序展开的神经网络,适用于对时序序列数据进行特征提取,可以使神经网络学习到上下文特征信息,LSTM的计算过程是由遗忘门(ft)、记忆门(it)、输出门(ot)和细胞状态(Ct)控制的,其中W是权重矩阵,b是偏置项,σ是激活函数。算法流程如下:
(1)计算遗忘门(ft)。选择遗忘的信息,输入为前一层细胞状态ht-1、当前输入向量为Xt,输出遗忘门为ft,通过遗忘门的计算可以选择遗忘过去没有用的信息,即
ft=σ(Wf×[ht-1,Xt]+bf)。
(1)
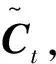
it=σ(Wi×[ht-1,Xt]+bi),
(2)
(3)

(4)
(4)计算输出门(ot)和当前隐层状态(ht)。输入为前一时刻的隐层状态ht-1、当前输入词Xt、当前时刻的细胞状态Ct,输出为输出门的值ot和当前隐层状态ht,即
ot=σ(Wo[ht-1,Xt]+bo),
(5)
ht=ot×tanhCt。
(6)
最终本试验中用与句子长度相同的隐层状态序列{h0,h1,…,hn-1}来表示输入的句子。
由于LSTM只能编码正向时序的信息,导致当前时刻的词语在LSTM网络下文权重大于上文权重的问题。BiLSTM网络将句子正向输入得到的序列和反向输入得到的序列拼接起来。正向序列即从句子的左边第一个词向后遍历,反向序列即从最后一个词向前遍历,并将两个序列拼接起来,得到BiLSTM的隐层向量。通过正、反双向的特征学习,每个时刻都能学习到合理的上下文特征,解决了在LSTM网络中当前时刻后词权重大于前词权重的问题,但是无法解决句子序列过长时导致序列前端语义稀释的问题。BiLSTM模型框架如图2所示。
1.2 注意力机制
注意力机制可以在有限的资源下快速、准确地处理信息。BiLSTM模型在渔业标准领域中应用存在长序列前端语义稀释、信息丢失的问题,导致BiLSTM网络输出的语义向量难以概括句子所有信息,得不到合理的向量表示。在深度学习中,注意力机制率先在计算机视觉领域中被广泛应用[19-20],Bahdanau等[21]使用Attention机制在机器翻译任务上并取得较大提升。在渔业标准命名实体识别模型中引入注意力机制,通过生成不断变化的语义向量使模型关注句子中关键部分,忽略对目标词影响力小的部分,有效地解决了BiLSTM网络生成固定的语义向量导致的长序列前端语义稀释的问题。
Attention层的输入有W、U、V权重矩阵,si-1表示解码器上一时刻隐层状态,eij表示注意力贡献矩阵,αij表示归一化的权重,cij为新的语义向量,分别由下式计算得出:
(7)
(8)
(9)
1.3 CRF解码器
传统的命名实体识别方法通过归一化处理将BiLSTM输出层计算得到每个时刻概率最高的序列,这种方法是将标签看成相互独立的个体,导致最终解码出的序列出现不合法标签的情况,如实体头被标注成I标签。为了得到全局最优解,避免标签的不合法性,同时使模型学习到E-BIO标注法引入的“渔业标准指标”与“渔业标准指标编号”之间的标签约束关系,将BiLSTM的隐层向量输入到CRF层,引入转移矩阵参数可以使最终的序列具有约束关系。
BiLSTM解码器输出的矩阵为P,设标签之间的转移矩阵为A,对于输入序列X,输出序列y的关系如公式(10)所示,
(10)
2 验证试验
2.1 渔业标准语料标注
2.1.1 渔业标准命名实体定义 渔业标准是指导渔业生产的规范性文件。渔业标准内容的分析需要关注标准与标准之间的引用关系和渔业标准指标的具体内容,渔业标准之间的引用关系是通过渔业标准号体现的,因此,定义了渔业标准命名实体识别任务是识别标准文本中“渔业标准号”和“渔业标准指标”两类命名实体。
(1)渔业标准号。渔业标准号是渔业标准的唯一标识,由“字母段”和“数字段”两部分构成。通常出现在渔业标准“规范性引用文件”和标准指标描述部分,如“GB 11607”、“GB/T 5099.44-2003”“NY 5288-2006”、“SC 2056”、“SC/T 3210-2001”等(图3)。
图3 渔业标准号实例
Fig.3 Examples of fishery standard number
(2)渔业标准指标。渔业标准定义渔业生产中需要规范化操作的项目名称,如“育苗设施”、“原料处理与装笼”、“冻品外观检验”、“鱼片”、“黑膜”等(图4)。
图4 渔业指标实例
Fig.4 Examples of fishery indicators
2.1.2 渔业标准实体标注方法 通过对渔业标准文本的结构分析发现:渔业指标实体前通常会出现数字编号来对渔业指标实体进行分级和定义,而传统的BIO标注方法是针对需要识别的实体类别进行标注,如人名、地名、机构名等通用语料库。由于传统BIO标注方法无法引入文本结构信息,针对渔业标准文本的上述特点,提出E-BIO标注法,在构建渔业标准语料库时新增实体类“指标编号”,对出现在“渔业指标”前的数字编号进行标注。标注方式采用BIO标注,标签类别定义如表1所示。通过引入渔业标准文本结构信息,可以使渔业标准命名实体识别模型的CRF解码器阶段学习到各类命名实体标签之间的约束关系,更充分地提取“渔业标准指标”实体的特征。经对比试验证明,E-BIO标注方法在“渔业标准指标”实体识别的召回率上有明显的提升。

表1 标签类别定义
2.1.3 渔业标准语料库 收集和整理240篇现行的涵盖国标、省标、地标、行标等有关种质、育苗养殖、基础设施、水产品加工流通等渔业标准。渔业标准语料库总字数20万字符,共4607条句子,带标记字符占总体16.1%。渔业标准命名实体分布数据如表2所示。
2.2 试验环境及评价指标
本研究中的试验环境为Intel xeon E5-2630 v32.4 GHz处理器,6 GB内存,操作系统为Ubuntu 16.04 LTS 64 bit。字符向量采用300维的随机初始化向量,优化器选择Adam,学习率为0.001,Dropout为0.5。

表2 实体数据分布
试验结果的评价指标采用准确率(precision)、召回率(recall)、F1值(F-measure)[22],其中F1值为模型的综合评价指标。P、R、F1的计算公式为
(11)
(12)
(13)
2.3 试验设计与结果
为验证本研究中提出的E-BIO标注法和模型对渔业标准命名实体识别的效果,分别设置了两组对比试验。
(1)试验1。BiLSTM+CRF模型使用BIO标注方法和标注法的比较。表3分别给出了传统BIO标注法和E-BIO标注法对“渔业标准指标”的识别效果。从表3可见:E-BIO标注法较传统BIO标注法在“渔业标准指标”的召回率方面提升5.71%,这表明本研究中E-BIO标注法在渔业标准命名实体识别任务上有较好的效果。
表3 不同标注方法对渔业标准指标识别效果比较
Tab.3 Effect comparison of different marking methods on the identification of fishery standards %
(2)试验2。使用E-BIO标注法的语料对BiLSTM、BiLSTM+CRF、BiLSTM+Attention+CRF模型进行比较,其中,BiLSTM+Attention+CRF是融入注意力机制的渔业标准命名实体识别模型。3种模型对“渔业标准号”与“渔业标准指标”的识别效果见表4、表5。
从表4可见:在“渔业标准号”的识别任务上,BiLSTM模型识别效果较差,BiLSTM+Attention+CRF模型的表现明显优于BiLSTM模型与BiLSTM+CRF模型,准确率、召回率、F1值相对于BiLSTM+CRF模型分别提升了3.98%、0.87%、2.49%。
从表5可见:在“渔业标准指标”的识别任务上,BiLSTM模型识别效果较差,BiLSTM+Attention+CRF较BiLSTM+CRF模型召回率提升了4.59%,F1值提升了2.37%。
试验2结果说明融入注意力机制的命名实体识别模型能有效提升渔业标准命名实体识别效果。
表4 不同模型对渔业标准号识别效果比较
Tab.4 Comparison of the recognition effects of different models on fishery standard numbers %
表5 不同模型对渔业标准指标识别效果比较
Tab.5 Effect comparison of different models on identification of fishery standard indicators %

模型model准确率precision召回率recallF1值F1-measureBiLSTM76.5078.2977.61BiLSTM+CRF89.2680.3584.57BiLSTM+Attention+CRF89.0484.9486.94
3 结论
针对渔业标准命名实体识别的问题,提出了一种基于E-BIO标注法构建渔业标准文本语料库,可以使BiLSTM+CRF模型学习到渔业标准命名实体标签位置信息,提升了渔业标准命名实体识别的召回率;针对传统命名实体识别模型在渔业标准命名实体识别任务中长序列语义消失的问题,提出了融合注意力机制的BiLSTM+CRF模型,经试验证明了该模型的有效性。但是在渔业标准语料库中还存在其他有识别意义且样本数量较低的实体类别,如“渔业水产品”等,这类术语在语料中总字符占比约1%,属于样本不均衡问题。因此,下一步工作是解决语料中样本不均衡类实体的识别问题,以进一步提升渔业标准命名实体的识别效果。
致谢:感谢国家科技资源共享服务平台——国家海洋科学数据中心大连分中心(http://odc.dlou.edu.cn/)提供数据支撑!
