基于anchor-free的交通场景目标检测技术*
2020-05-04葛明进孙作雷
葛明进,孙作雷,孔 薇
(上海海事大学信息工程学院,上海 201306)
1 引言
城市规模不断扩大,道路上的车辆日益增多,道路交通情况变得越来越复杂,使得智能交通系统[1,2]的发展越来越引人关注。交通场景下的目标检测技术是智能交通系统的关键所在,在车辆违法行为检测、停车缴费系统、规避交通事故等方面都发挥着极为重要的作用。
当前基于深度学习的目标检测算法主要可分为2大类。
一类是二阶段目标检测算法,此类算法在第1阶段通过区域建议网络RPN(Region Proposal Network)生成候选区域RP(Region Proposals),第2阶段在RP内完成图像特征提取,并利用提取到的特征对候选区域进行分类和定位。例如R-CNN(Region-based Convolutional Neural Network)[3]、Fast R-CNN(Fast Region-based Convolutional Neural Network)[4]、Faster R-CNN(Faster Region-based Convolutional Neural Network)[5]等。其中R-CNN算法首先利用选择性搜索SS(Selective Search)算法[6]获取图像的候选区域RP,然后使用卷积神经网络对所有RP进行特征提取,最后使用支持向量机SVM对RP进行分类和定位。Fast R-CNN针对R-CNN中存在的重复卷积计算问题进行了改进,首先将整幅图像输入到卷积神经网络中进行特征提取,然后通过感兴趣区域池化层(ROI POOLing)对获取到的RP进行尺寸处理。Fast R-CNN使用整幅图像作为卷积网络的输入,减少了大量的重复计算,降低了计算量,但其依旧采用SS算法提取候选区域,所以整个网络的训练还没有实现端到端处理。Faster R-CNN提出使用区域建议网络RPN的方法,将生成候选框的过程也加入到目标检测网络中来,整个目标检测网络实现了端到端的训练。Faster R-CNN还提出了anchor的概念,作为预测的候选框。后来候选区域生成阶段逐渐被基于anchor的区域建议网络所取代。
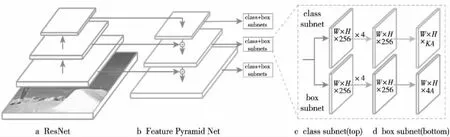
Figure 1 RetinaNet model图1 RetinaNet模型
另外一类是基于回归的目标检测算法,直接在网络中提取特征来预测目标类别和位置,将目标检测由分类问题转换为回归问题,检测速度相比于二阶段目标检测算法有了质的提升,但在精度方面却相差很多。其中DenseBox[7]采用的就是anchor-free的机制,在训练时通过剪裁、调整图像尺寸来适应多尺度的要求,因此DenseBox需要在图像金字塔上完成目标检测任务,重复的卷积计算使计算量增大。YOLO(You Only Look Once)[8]也是采用anchor-free的方法进行目标检测的典型,在网络训练的过程中,直接学习目标类别和位置,不以任何预定义的先验框作为参考。但是,由于在YOLO目标检测算法中,每个目标只由目标中心点所在的网格(Grid Cell)负责预测,召回率低。所以,后来的YOLOv2[9]、YOLOv3[10]和SSD(Single Shot multibox Detector)[11]都借鉴了Faster R-CNN中的anchor机制,利用密集采样的思想,通过大量预定义的anchor枚举目标可能的位置、尺寸和纵横比的方法来搜索对象,但网络的性能与泛化能力也受到了anchor自身设计的限制。首先,使用anchor作为先验框会引入额外的超参数;其次基于特定数据集设计的anchor尺寸不能通用于其它数据集;最后,每个位置都有大量的先验框,如此密集地采样会带来正负样本极度不均衡的问题。针对基于anchor的单阶目标检测网络存在的问题,本文在RetinaNet[12]网络的基础上提出一种基于anchor-free的交通场景下的目标检测模型,采用逐像素预测的方式进行目标检测,直接预测目标类别和边界框的位置。
2 基于 anchor-free的目标检测模型
2017年Facebook AI团队提出了RetinaNet目标检测器,RetinaNet是一个基于anchor的单阶目标检测网络,其网络结构图如图1所示,其中,W和H分别为特征图的宽和高,K为目标的类别数,A为anchor的数量。首先将深度残差网络ResNet[13]作为主干网络用来提取图像的特征;然后利用特征金字塔网络FPN(Feature Pyramid Networks)[14]对不同特征层提取到的图像信息进行融合;最后2个平行的子网络完成特定的任务,第1个子网络负责对特征金字塔某一层的输出特征图执行目标分类,第2个子网络负责目标位置回归。
本文采用与RetinaNet网络相同的主干网络,使用ResNet作为基础特征提取网络,利用FPN完成多尺度预测。不同的是本文采用anchor-free方法进行目标检测,在目标检测的过程中不以任何预定义的anchor作为目标分类和边界框回归的参考,而是将特征图上的每个像素作为1个样本,对特征图上的像素进行逐像素分类[15],并回归正样本区域内的像素距离真实框GT(Ground Truth)左上角和右下角的距离。此外,本文在边界框回归分支上添加中心性预测分支,中心性预测分支与边界框回归分支共享网络参数。其网络结构图如图2所示。其中分类子网络最后的输出是1个K(类别数)通道的类别敏感的语义特征图,回归子网络负责预测4个位置偏移量,中心性预测网络负责衡量正样本区域内的点距离真实框中心点的远近程度。

Figure 2 Object detection network based on anchor-free图2 基于anchor-free的目标检测网络
2.1 特征提取网络
基于深度学习的目标检测算法通常包含2个步骤,首先利用特征提取网络提取图像不同分辨率、不同层次的语义特征,然后利用提取到的特征进行分类和定位。常用的特征提取网络包括AlexNet[16]、VGG-Net[17]、GooLeNet[18]等,这些都属于直线型的卷积神经网络。对于这种类型的网络,通过增加网络的宽度和深度可以提高网络的性能,但网络的加深也会产生更多的误差。如果简单地增加网络深度,会产生梯度弥散或梯度爆炸的问题。
ResNet的设计巧妙地规避了直线型卷积神经网络的缺点,它的特点是容易优化,并且能够通过增加网络的深度来提高准确率。其内部的残差块使用了跨层连接(Shortcut Connection),缓解了在深度神经网络中增加深度带来的梯度消失问题,如图3所示。

Figure 3 Shortcut connection in ResNet图3 残差网络中的跨层链接
2.2 特征金字塔网络
由于低层的特征图具有目标位置准确但语义信息少的特点,而高层的特征图虽然具有更多的语义信息,但目标位置信息不准确。特征金字塔网络可以根据单尺度的输入图像构建网络内的特征金字塔,具体实现方式为自底向上的连接、自顶向下的连接以及横向连接的网络结构,将不同层的特征图融合到一起,获得更加丰富的信息,用来探测不同尺度的物体,其结构如图4所示。

Figure 4 Feature pyramid network图4 特征金字塔网络结构图
自底向上的过程代表卷积神经网络的前向传播,本文选用ResNet的C3、C4、C5层特征图,利用卷积核为3×3,步长为1的卷积操作对C5层特征图进行处理后得到FPN的P5层。自顶向下的连接是一个上采样的过程。横向连接的作用是把上采样的结果和卷积神经网络前向传播过程生成的特征图相加,即将卷积核为1×1,步长为1的卷积操作对C4层进行处理后的结果与P5层上采样结果相加,然后在此基础上使用卷积核为3×3,步长为1 的卷积运算进行处理,得到FPN的P4层。以此类推产生P3层。P6层是由P5层经过卷积核为3×3,步长为1卷积运算处理后得到的,同理可得P7层。FPN的结构可以从单尺度输入图像中构建多尺度的特征图,不同尺度的特征图可被用于不同尺寸的目标检测,本文中所有特征金字塔层级的通道数C皆为256。
2.3 目标分类与边界框回归
假设GT的坐标为G(x1,y1,x2,y2),其中(x1,y1)和(x2,y2)分别代表GT的左上角和右下角的坐标。首先基于步长(为2l)将GT映射至特征金字塔中对应的l层。映射到第l层的GT的坐标记为G′(x′1,y′1,x′2,y′2),G′和G中坐标的映射关系为:
x′1=x1/2l,y′1=y1/2l
(1)
x′2=x2/2l,y′2=y2/2l
(2)
c′x=x′1+(x′2-x′1)/2
(3)
c′y=y′1+(y′2-y′1)/2
(4)
其中(c′x,c′y)表示GT的中心点坐标。定义图像正样本区域为特征图上GT的中心部分区域,相当于GT按一定比例收缩后的区域,记作Rp,其边界框坐标为(x″1,y″1,x″2,y″2):
x″1=c′x-((x′2-x′1)δ1)/2
(5)
y″1=c′y-((y′2-y′1)δ1)/2
(6)
x″2=c′x+((x′2-x′1)δ1)/2
(7)
y″2=c′y+((y′2-y′1)δ1)/2
(8)
其中,δ1指正样本区域相对于GT的收缩系数,正样本区域内的每个像素被标记为1,作为网络训练时的正样本。如果某一点(i,j)落入正样本区域,那么该点将负责检测其对应的目标。再引入另一个收缩系数δ2来定义忽略区域,记为Ri,忽略区域即为GT在δ2收缩系数下覆盖的区域减去正样本区域后的部分,忽略区域不参与网络训练。剩下的区域即为负样本区域,记为Rn。实验中,δ1取 0.3,δ2取0.4。
2.3.1 目标分类
目标分类子网络是一个小型的全连接网络FCN(Fully Connected Network)[19],连接到特征金字塔的每一层。对特征金字塔某一层输出的特征图(H×W×256),使用4个3×3×256的卷积核进行处理,每一层卷积层之后都加入ReLU激活函数处理卷积层的输出,最后使用1个3×3×K的卷积核卷积并通过Sigmoid激活函数得到网络的最终输出。最后的输出为K通道的置信度热图,大小为H×W,其中K为类别数,每个通道都是1个二进制掩码,表示是否为某一类别以及类的可能性,并对最后输出的特征图进行逐像素分类。
2.3.2 边界框回归
与目标分类子网络平行,另一个小型的FCN用于边界框回归。同样是用4个3×3×256的卷积核对特征图进行处理,同样也在每一层卷积层之后加入ReLU激活函数处理卷积层的输出,不同的是最后使用的是1个3×3×4的卷积核卷积并使用Sigmoid激活函数得到网络最终的输出。每个位置(i,j)预测4个位置偏移量。这4个位置偏移量即为正样本区域内的每个像素与GT的相对偏移量(Δω1,Δh1,Δω2,Δh2),其中:
Δω1=(2l*i-x1)/W
(9)
Δh1=(2l*j-y1)/H
(10)
Δω2=(x2-2l*i)/W
(11)
Δh2=(y2-2l*h)/H
(12)
首先将特征图中的某一点(i,j)映射至输入图像,然后计算其与GT的左上角和右下角2点的偏移量,最后将结果归一化到[0,1]。在边界框回归阶段,只对正样本区域内的点进行回归,不关注负样本区域(Rn)和忽略区域(Ri)的点。分类分支与回归分支结构相同,但二者参数相互独立。
2.3.3 中心性预测
本文提出了一个中心性预测分支,与边界框回归共享网络参数,中心性表示正样本区域内的点(i,j)距离GT的中心点(c′x,c′y)的远近程度。中心性的计算公式如式(13)所示:
(13)
测试阶段目标检测标注的最终得分是由分类得分和中心性相乘之后的结果。因此,对于远离GT中心点的位置产生的预测框,中心性预测可以降低这些预测框的得分。如此便可以通过非极大值抑制NMS(Non Maximum Suppression)[20]过程将质量较差的预测框过滤掉,提高目标检测算法的性能。
2.4 损失函数
损失函数 Focal Loss提出的目的是解决分类问题中类别不均衡、分类难度差异较大的问题。在本文的目标检测算法中,由于正样本区域仅仅占据特征图的很小一部分,为了避免网络训练过程中产生严重的正负样本不均衡的问题,使用Focal Loss作为分类损失函数,其函数表达式为:
FL(pt)=-αt(1-pt)γlog(pt)
(14)
其中,αt用来调节正负样本在训练过程中的重要性。Focal Loss的目的是让所有的正负样本都参与到模型训练之中,通过αt调节正负样本损失值的比重来缓解正负样本不均衡的问题。γ为调制因子,用来降低容易分类的样本在模型中所占的比重。例如,1个样本被错误地分类,那么置信度pt一般不高,属于难分类的样本,此时1-pt的值趋向于1,对损失函数的值影响不大;若pt趋向于1,属于容易分类的样本,1-pt的值趋向于0,此时容易分类样本的权重被大大降低。
对于回归问题的损失函数,不同于基于先验框的目标检测算法,本文算法直接回归正样本区域内的点(i,j)与真实框的相对偏移量,损失函数的选择也要适应目标的尺度变化,本文采用IOU(Intersection Over Union) Loss[21],其数学表达式为:
(15)

中心性预测分支采用L2范数作为损失函数,其函数表达式为:
(16)
其中,i和j分别表示正样本区域内某点的横坐标与纵坐标,c′x和c′y分别表示真实框中心点的横坐标与纵坐标。
3 实验
3.1 数据准备
实验采用KITTI数据集中的2D目标检测数据。其中目标类别包含Car、Van、Truck、Tram、Pedestrian、Person_sitting、Cyclist、Misc和DontCare。本文的实验目的是对交通场景中的车辆、行人和骑行者进行识别,不关注车辆的类别和行人姿势的差异。因而为了适应实验的需求,将Van、Truck、Tram标记为Car,与Car类别合并,将Person_sitting标记为Pedestrian,与Pedestrian类别合并,忽略与交通场景无关的Misc类和DontCare类。由于转化后的KITTI数据集中,目标类Car所占比重过大,为了数据集中各类别间的平衡,本次实验通过关键词搜索“行人”“道路”和“车辆”从YFCC100M数据集中收集了1 000幅分辨率较高的图像进行标注,并将标注后的图像加入转化后的KITTI数据集中,从而更好地展示改进算法的效果。根据实验的需要将KITTI数据集(包含自行收集标注的数据集)转化成MSCOCO(MicroSoft Common Objects in COntext)数据集的格式,最终的实验数据集有3个目标类别,分别为Car、Cyclist和Pedestrian。数据集中总共有8 482幅图像,将数据集中的所有图像按照8∶1∶1的比例划分为训练集、验证集和测试集。其中训练图像6 786幅,验证图像和测试图像各848幅。
3.2 实验过程
实验在GPU型号为NIVID GeForce GTX 1080Ti(×2)的服务器上进行,操作系统为64位Ubuntu16.04,配置CUDA8.0, cuDNN6.0。基于以上配置使用深度学习框架PyTorch搭建运行环境。根据迁移学习的思想,本文实验使用在ImageNet上的预训练模型对本文模型进行初始化,利用PyTorch的分布式训练模式进行训练,Batchsize设置为8,迭代次数为90 000,使用随机梯度下降优化算法,初始学习率为0.001,权重衰减系数为0.000 1。
3.3 实验结果与分析
交并比IOU、平均准确率AP(Average Precision)、平均准确率均值mAP(mean Average Precision)等是目标检测算法中的重要概念。交并比是指预测框与真实框的交集和并集之比,AP是查准率Precision和查全率Recall的关系曲线与坐标轴之间所围的面积,查准率和查全率计算公式为:
(17)
(18)
其中,TP(True Positive)表示针对某一目标类,被正确分类的正样本的数目,FP(False Positive)表示被错误分类的负样本的数目,FN(False Negtive)表示被错误分类的正样本的数目。mAP即为各类目标的平均准确率的均值。本文采用在指定IOU阈值下的mAP作为实验结果的评价指标,实验可分为以下3个部分:
(1)算法中采用的各种改进方法的效果。
为了验证本文算法中所采用的各种措施对于改进目标检测模型准确度的效果,进行了3次实验,如表1所示。其中,实验1为在主干网络为ResNet-101-FPN的条件下采用逐像素分类的方式进行目标检测,检测模型具有目标分类和边界框回归2个子网络。实验2为在目标分类子网络上增加1个中心性预测分支,与目标分类子网络共享网络参数。与实验1对比可发现,在目标分类子网络上增加中心性预测分支后,mAP上升了1.2%。实验3为中心性预测分支与边界框回归子网络共享网络参数,由表1可知,对比没有中心性预测分支的实验1,mAP上升了1.7%,相比于实验2,mAP上升了0.5%。
(2)不同的目标检测算法在本文数据集上的检测效果对比。
利用本文数据集对Faster R-CNN、YOLOv3、SSD、RetinaNet和本文改进的目标检测算法的效果进行测试,结果如表2所示。

Table 2 Detection effects of different algorithms on the dataset in this paper表2 不同算法在本文数据集上的检测效果
本文改进的算法在检测准确度方面不仅高于单阶目标检测算法YOLOv3、SSD,而且mAP比二阶段目标检测算法Faster R-CNN的高2.7%。相比于RetinaNet模型,在同为单阶目标检测模型且主干网络完全相同的情况下,改进算法相较于RetinaNet目标检测算法,mAP提升了1.9%。由表2可知,在本文数据集中图像尺寸为1242×375的情况下,RetinaNet的推理时间为101 ms,改进算法的推理时间为108 ms,对比两者的推理时间可知,本文改进算法的推理速度稍逊于RetinaNet算法的,但仍能达到交通场景下目标检测实时性的要求。
(3)不同的目标检测算法在公开数据集MSCOCO上的检测效果对比。
为了进一步验证本文改进算法的效果,利用Faster R-CNN、YOLOv3、SSD、RetinaNet和本文改进算法在公开数据集MSCOCO上进行测试,测试结果如表3所示。改进算法在检测准确度方面优于其他算法,比Faster R-CNN的mAP高3.8%,比RetinaNet的mAP高1.6%。在推理时间方面,改进算法的推理时间远小于Faster R-CNN算法的推理时间,略大于RetinaNet算法的推理时间,满足交通场景下实时检测的要求。
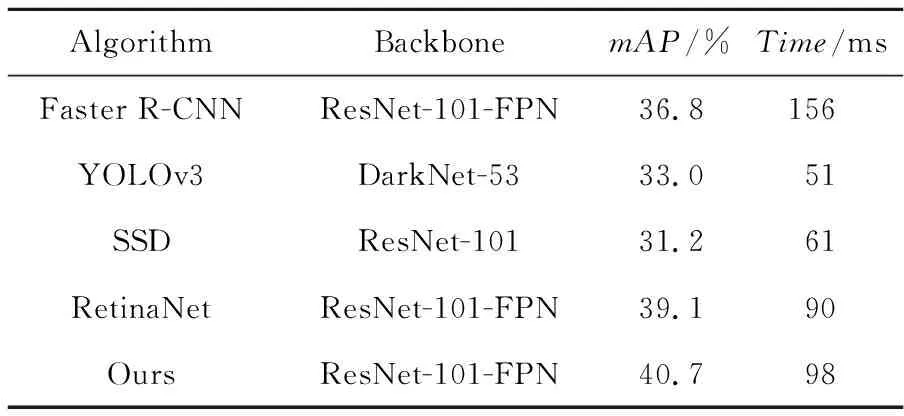
Table 3 Detection effects of different algorithms on MSCOCO dataset表3 不同算法在MSCOCO数据集上的检测效果
部分目标检测效果图如图5所示。由图5可知,在复杂的城市街景中,改进算法可以准确地识别出车辆、行人和骑行者,在车辆较多的情况下也能检测出遮挡不超过50%的目标,在道路宽敞、环境空旷的道路环境下,改进算法能够较好地识别出远方较小的车辆目标。

Figure 5 Some detection results图5 部分检测效果图
4 结束语
在RetinaNet目标检测算法的基础上,本文提出了一种基于anchor-free的单阶目标检测算法,利用逐像素预测的方法,直接预测目标类别和位置。相比于基于anchor的原RetinaNet目标检测算法,本文算法减少了与anchor有关的超参数的设计,也避免了由于anchor自身设计带来的网络泛化能力减弱等问题。同时,算法中提出的中心性预测分支,通过衡量距离GT中心位置的远近,降低偏离GT中心的位置所得预测框的得分,从而使得质量较低的预测框在非极大值抑制的过程中被过滤掉。通过在本文数据集以及公开数据集MSCOCO上的实验,表明本文改进的目标检测算法能够在交通场景中对车辆、行人和骑行者实现更好的识别。
