阵列处理器分布式Cache的局部优先访问结构设计*
2020-05-04刘有耀
刘有耀,张 园,山 蕊
(西安邮电大学电子工程学院,陕西 西安 710121)
1 引言
可重构阵列处理器具有设计复杂度低,编程灵活,高主频、高吞吐率等特性,是未来处理器发展的必然趋势[1 - 3]。随着半导体工业和集成电路产业的发展,可重构阵列处理器的集成度显著增加,支持应用的范围越来越广。以人工智能、超高清视频编解码、虚拟现实VR(Virtual Reality)、增强现实AR(Augmented Reality)等为代表的新兴应用发展迅速,可重构结构在实现新兴应用方面表现出较大的优势。然而,新型应用具有计算数据庞大、访存频率较高等特点[4],对可重构阵列处理器存储结构的并行访问特性提出了新的要求。如何在可重构阵列处理器上构建灵活、高效的存储体系是处理器性能提升的一个关键问题[5]。
许多学者针对存储结构进行了深入的研究,目前普遍采用的解决方法是在处理器中采用Cache缓解处理器处理速度与主存存储速度失配引起的“存储墙”问题[6,7]。文献[8]采用片上大容量共享Cache来进行访存,这种大容量的Cache结构不但使得整个系统的面积增加且访存的并行性不高。文献[9]采用多级Cache来进行访问,多级Cache因为一致性带来了较高的能耗,对于实时性数据处理较差,难以满足新兴应用对存储并行性访问的需求。为了增加数据的并行访问,文献[10]提出一种分布式Cache结构,在处理器PE(Processing Element)簇内根据多处理器特性采用片上分布式Cache结构来提高Cache容量,提高命中率,节省了能耗,提高了实时性。文献[11]提出的分布式Cache缓存结构,在大规模存储系统中提高了缓存吞吐量,节省了能耗。文献[12]提出了一个具有分布式框架和异构缓存方法的通用Cache系统,该系统应用于车辆互联网等大数据应用的实时高速数据传输。随着新兴应用对存储访问带宽、延迟性能需求的进一步提高,分布式Cache成为可重构处理器缓解“存储墙”问题一种行之有效的解决方案[13,14]。
可重构阵列处理器分布式存储结构中,常用的实现阵列间数据访问方法是在阵列处理器簇内PEG(Processing Element Group)设计簇内高效互连访问结构,满足簇内高效率、低延迟的访问需求,这种簇内访问结构是提升分布式存储访问性能的关键因素。文献[15]提出的簇内访问结构命名为行列交叉访问结构LR2SS(Line Row two-Stage Switch),该结构针对数据密集型访问存在较大的访问延迟且计算并行性较差。文献[16]提出的簇内全访问FS(Full-Switch)虽然访问延迟有所降低,但对于局部性访问明显的数据计算不能很好地处理。本文在可重构阵列处理器上基于分布式Cache结构,提出了一种簇内局部优先访问互连结构LPAS(Local Priority Access Switch)。该结构特点如下所示:
(1)基于可重构阵列处理器全局重用少、局部性访问明显的特征,将可重构阵列处理器的存储访问进行区域划分,分为本地区域LA(Local Area)和远程区域RA(Remote Area),其中远程区域的划分以本地区域为依托,根据访问距离长短又分为3个等级。以第1行PE为例,第1行Cache为本地区域,第2行Cache为远程区域1 RA1(Remote Area 1),第3行Cache为远程区域2 RA2(Remote Area 2),第4行Cache为远程区域3 RA3(Remote Area 3)。
(2)当PE访问簇内Cache时,LA优先级最高,RA优先级低于LA。RA 3个等级中:RA1优先级最高,RA2次之,RA3最低。
(3)该结构支持低流量无冲突访问模式下16个Cache的并行访问,写访问操作1个周期完成,读访问操作2个周期完成并发送读写反馈信息告知PE,提高了可重构处理器的访问并行性。
2 分布式Cache结构
一种具有局部访问优先、全局共享的“物理分布、逻辑统一”的通用的分布式Cache结构如图1所示,上层是1个由4×4个PE组成的阵列处理器簇,下层是由4×4个512×16 bit大小的高速缓存器(Cache)、轮询仲裁器(arb)以及网络适配器(NI)组成的存储结构。簇内访问结构在阵列处理器和Cache之间形成一个高速数据交互通路,该结构采用统一编址方式,使每个处理器可以通过地址的[7:4]并行性访问这些分布式Cache,实现簇内数据的高效访问,提高可重构阵列处理器的访问并行性。
从PE角度看,该分布式Cache结构中每个PE可以直接访问片上所有区域Cache,是片上共享Cache结构;物理实现上,采用4×4个独立的Cache块,通过簇内存储结构实现LA区域优先访问,RA区域次之的优先策略,同时利用多个Cache块的并行存储技术,实现簇内4×4个PE的并行访问。当PE访问Cache时,簇内访问结构接受来自PE的请求,根据地址判断是对LA区域Cache进行访问还是RA区域Cache进行访问,当PE访问LA区域Cache时,优先级最高,当PE访问RA区域Cache时,需通过簇内访问结构仲裁出正确的响应顺序完成对RA区域Cache的操作。一旦命中簇内Cache,立即将数据返回给请求PE,若不命中,则需要通过轮询仲裁器仲裁出一路信号通过虚通道路由器VCR0901与外存进行通信。

Figure 1 Intra-cluster distributed Cache architecture图1 簇内分布式Cache结构
本文设计的簇内访问结构LPAS用于处理全局重用少、局部性明显的视频图像多媒体数据时,通过在簇内配置数据访问指令ST把PE最先访问或经常访问的数据放在LA的Cache中或较近距离RA的Cache中,把PE最后访问的数据或不常访问的数据放在离PE较远位置RA的Cache中,这样对于经常访问的数据可以节省访问较远路径所耗费的时间,同时,减少资源的消耗,提高访存速度,提升并行访问带宽。同时,该设计硬件开销小,并行访问性高,可大大提高可重构阵列处理器的访存带宽;在应对大数据时代人工智能、计算机视觉等新兴应用所要求的高实时性、高并行性以及灵活性时表现出了较好的优势。
3 簇内访问结构(LPAS)
3.1 LPAS硬件结构
局部优先访问电路结构分为3部分,分别为仲裁选择模块Arb_select、仲裁模块Cache_arbiter和总线模块Bus,如图2所示。
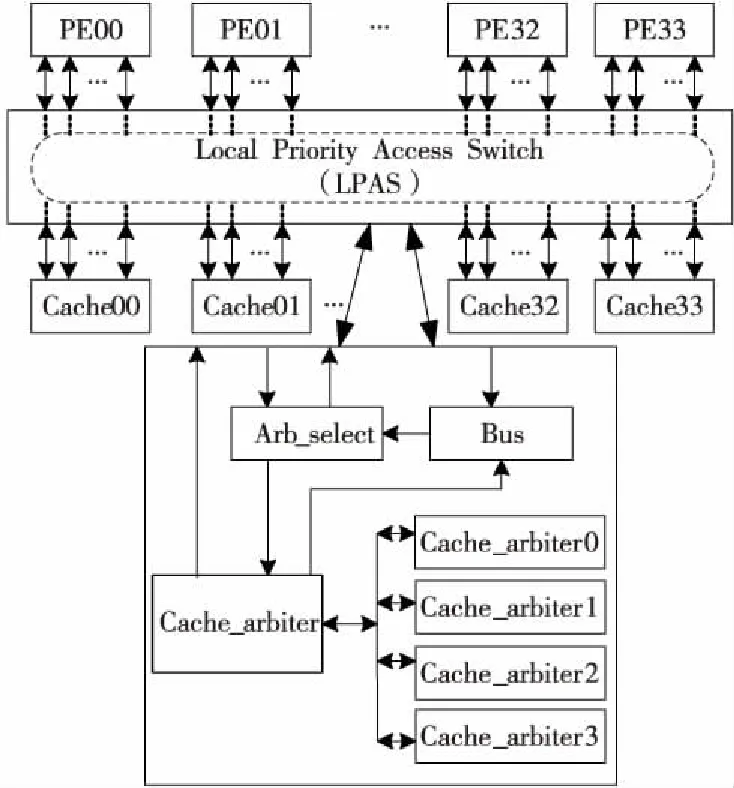
Figure 2 Intra-cluster local priority switch architecture图2 簇内局部优先访问结构
3.1.1 仲裁选择模块Arb_select
仲裁选择模块主要完成2个功能:(1)用来接收PE发出的读写请求,根据地址判断请求的目的Cache位置,选择目的Cache所在的仲裁模块;(2)根据Bus模块的反馈信号判断当前请求是否完成,同时将反馈信息送回给请求的PE。若反馈信号为低,代表当前操作未处理,下1拍PE不能发送新的数据请求,此时将访存信息暂存在电路中,等待正确的响应顺序;若反馈信号为高,代表当前访问完成,下1拍PE可以重新发送1组数据请求。
3.1.2 仲裁模块Cache_arbiter
仲裁模块设计了4种仲裁机制。第N行Cache仲裁机制为Cache_arbiterN(N=0,1,2,3)。每种仲裁机制工作过程如下:根据仲裁选择模块传来的16位使能请求进行冲突仲裁(16位使能请求分别代表PE00~PE33的访问请求),有冲突访问时,根据LA优先,RA次之的访问顺序仲裁出1路信号与Cache进行交互。无冲突访问时,根据目的Cache的地址直接进行数据交互。
以第1行Cache仲裁Cache_arbiter0为例,仲裁过程如下:当第1行Cache00收到同区域PE阻塞通信时(PE00,PE01,PE02,PE03),Cache_arbiter0经过轮询仲裁机制随机仲裁出1路信号与Cache00交互。当有不同区域PE(PE00,PE10,PE20,PE30)同时访问Cache00时,Cache00经过Cache_arbiter0仲裁先对LA的PE00响应,然后处理较近距离的PE10,接着是PE20,最后是最远距离的PE30。
3.1.3 总线模块Bus
总线模块主要将16个PE的请求信号和Cache_arbiter仲裁出的1路信号一起作为反馈信息送回到Arb_select模块,Arb_select模块根据反馈信息来判断读写访问操作要不要继续保持。
3.2 LPAS的访问机制
可重构阵列处理器分布式Cache的簇内局部优先访问结构旨在完成簇内 PE和分布式Cache的连接,实现簇内PE和Cache的数据访问,提高可重构阵列处理器簇内数据的访问并行性。
Write access
1 input:data_wr_en,data_waddr,data_wdata
2 ifwr_ack=0
3 then Store request singal
4 Judgedata_waddr[7∶4]
5 Select cache_arbiterN
6 ifdata_num>0
7 then Do arbitration
8 output:wr_req_pe_num
9wr_cache_en
10wr_cache_data
11wr_cache_addr
12 ifwr_ack=1
13 then Release storage signal
14 next 1
该结构写操作如下所示:
(1)当PE发出写请求时,Arb_select模块先判断写反馈信息wr_ack,若wr_ack为低,Arb_select将访存信息寄存到电路中,等待正确的顺序进行响应。
(2)Arb_select通过写地址信息data_waddr[7∶4]判断目的Cache位置,选择目的Cache对应的仲裁Cache_arbiterN(N=0,1,2,3)。
(3)Cache_arbiterN通过16位读热码data_num(16位读热码分别代表PE00~PE33访问请求,1代表有访问请求)进行访问仲裁,依据其局部优先的访问特性仲裁出1路信号与目的Cache进行交互。
(4)Cache_arbiterN根据请求的PE号经Bus模块发送写反馈信息给请求的PE。
(5)PE收到写反馈信息后,Arb_select在下1拍将寄存的信息释放,至此1个完整的写操作完成。可重构阵列处理器中16个PE可同时对16个Cache进行以上写操作。PE的读操作与写操作类似,这里只给出了写操作。
4 综合分析与算法实现
4.1 综合分析
采用Verilog HDL硬件描述语言,在Questasim10.1d工具下进行功能仿真验证,选用Xilinx公司的ZYNQ系列芯片 XC7Z045 FFG900-2 FPGA进行综合,其中LPAS结构与文献[15]中LR2SS结构、文献[16] 中FS结构芯片综合资源使用情况对比如表1所示。

Table 1 FPGA chip resource usage table表1 FPGA资源使用表
分析测试结果表明,综合后的LPAS结构在无冲突情况下,支持16个PE的同时读/写操作,写操作1个周期完成,读操作2个周期完成,最高频率可达221 MHz,访问峰值带宽为7.6 GB/s。在无冲突情况下访问峰值带宽比LR2SS增加了0.95 GB/s,与FS在无冲突情况下的最高工作频率和访问峰值带宽相近,但比FS占用的硬件资源少。
4.2 图像处理算法的并行化映射
为验证簇内局部优先访问结构LPAS的可行性,将其应用于可重构视频阵列处理器,搭建验证平台,选取灰度共生矩阵GLCM(Gray-Level Co-occurrence Matrix)进行纹理图像特征提取的算法在此平台上的映射分析。
灰度共生矩阵反映图像灰度关于方向、相邻间隔、变化幅度的综合信息。一般在0°,45°,90°和135° 4个方向,从图像灰度为i的像素(x,y)出发,统计距离为δ、灰度为j的像素(x+Δx,y+Δy)同时出现的概率P(i,j,δ,θ)。本文所设计的LPAS局部优先访问结构对存入同行Cache的数据访问延迟最低,因此选取水平方向θ=0°,δ=3统计P(i,j,3,0°) 生成GLCM。
P(i,j,3,0°)=
{[(x,y),(x+Δx,y+Δy)]|f(x,y)=i,
f(x+Δx,y+Δy)=j;
x=0,1,…,Nx-1;
y=0,1,…,Ny-1;|Δx|=3,|Δy|=0}
(1)
其中,i,j=0,1,…,L-1;|Δx|和|Δy|分别表示像素(x,y)与像素(x+Δx,y+Δy)的水平距离和垂直距离的绝对值;x,y是图像中的像素坐标;Nx,Ny分别是图像的行列数。1幅图像的灰度级数一般为0~255,共256级。级数太多会导致计算的GLCM较大,求灰度共生矩阵之前,先将图像灰度级压缩为4级。用计算得到的4×4灰度共生矩阵提取纹理特征二阶矩(能量),二阶矩反映图像灰度分布均匀程度和纹理粗细度,是GLCM各元素的平方和,f大时,纹理粗,能量大,反之f越小,纹理越细,能量越少,如式(2)所示:
(2)

Figure 3 Image texture extraction map assignment图3 图像纹理提取映射分配
整个映射过程在1个簇内实现,如图3所示。阵列处理器仅有PE33可以与外部交互,将最终得到的二阶矩在PE33下用STM指令存到外存。具体映射过程如下:第1步:选取64×64的彩色图像在Matlab中转换为灰度图像,并用LDM和ST指令将像素值读入到16个PE的Cache中,每个Cache下存放64×4个像素值。第2步:簇内16个PE用LD指令并行从16个Cache中读取像素值。第3步:16个PE开始并行遍历像素值,并生成16个GLCM,编号为GLCM0~GLCM15,同时将生成的4×4的GLCM用ST指令存入每个Cache的最后16位地址中,低4位地址存放第1行,中间8位地址依次存放第2行,第3行,最后4位地址存放第4行。处理完成后,用ST指令将相应PE处理完成的握手信号存入PE33的Cache中。第4步:PE33用LD指令查看每个PE处理完成的握手信号,收到握手信号后,PE33将其他15个PE生成的灰度共生矩阵GLCM0~GLCM15用ADD指令和ST指令生成全局共生矩阵GLCM。第5步:PE33将生成的灰度共生矩阵用式(2)进行二阶矩计算,将二阶矩用STM指令存入外部存储中。
最终在算法正确处理的情况下执行时间为0.24 ms。生成灰度共生矩阵GLCM0~GLCM15的过程中,16个PE并行访问本地Cache数据,此时冲突概率为0,存储访问带宽可以达到峰值7.6 GB/s。生成全局灰度共生矩阵GLCM和二阶矩的计算时只有PE33访问执行,冲突概率依旧为0,此时访问带宽为450 MB/s。最终该簇内局部优先访问结构LPAS可以为该算法提供的数据访存带宽为478.125 MB/s。
5 仿真性能统计与比较
5.1 仿真性能统计
为验证簇内局部优先访问结构LPAS的正确性和局部低时延特性,分别选取了有冲突和无冲突情况的读写访问在Questasim上进行仿真,对4×4分布式Cache中每1行Cache的RA区域和LA区域进行延迟统计。图4是无冲突访问的读写统计,行1表示第1行Cache的LA区域和RA区域的平均读写访问延迟,行2表示第2行Cache的LA区域和RA区域的平均读写访问延迟,行3表示第3行Cache的LA区域和RA区域的平均读写访问延迟,行4表示第4行Cache的LA区域和RA区域的平均读写访问延迟。由于读操作和写操作相似,图5只统计了冲突概率分别为25%,50%,75%和100%时簇内第1行Cache的LA区域和RA1区域、RA2区域和RA3区域的局部平均写访问延迟。
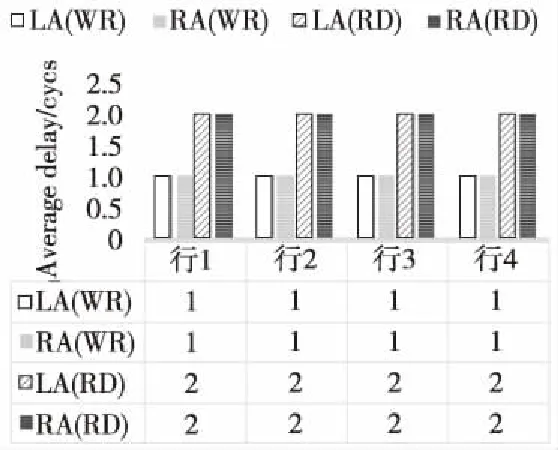
Figure 4 Access without conflict图4 无冲突访问

Figure 5 Access with conflict图5 冲突访问
从图4和图5可以看出,无冲突访问情况下:每1行Cache不管是LA还是RA平均写访问延迟均为1个周期,平均读访问延迟为2个周期。冲突访问情况下:(1)同样的冲突概率,每1行Cache的LA的平均写访问延迟最低,RA1次之,RA3的平均写访问延迟最大。(2)随着冲突概率的增加,LA的平均写访问延迟保持在2.5个周期,RA的平均写访问延迟呈上升趋势,其中RA3的平均写访问延迟上升最快。从以上分析结果可以看出,该互连结构具有明显的局部访问优势。
5.2 仿真性能比较
为了进一步分析比较LPAS的低时延特性,针对这种簇内LPAS互连设计,进行了多种测试用例仿真,并与 LR2SS和FS进行仿真性能对比。首先对8种简单的无冲突访问进行性能仿真统计。(1)同行的PEs访问同行的Caches,比如PE00访问Cache10,PE01访问Cache11,PE02访问Cache12,PE03访问Cache13;(2)同列的PEs访问同行的Caches;(3)同行的PEs访问同列的Caches;(4)同列的PEs访问同列的Caches;(5)局部的2×2 PEs阵列交叉访问;(6)一个局部 2×2 PEs阵列访问另一个局部2×2 PEs阵列中的Caches;(7)局部 2×2 PEs阵列分别访问4个局部 2×2 PEs阵列中的Caches;(8)局部 2×2 Caches阵列访问本地2×2 PEs阵列中的Caches。3种结构的读写访问延迟如图6所示。
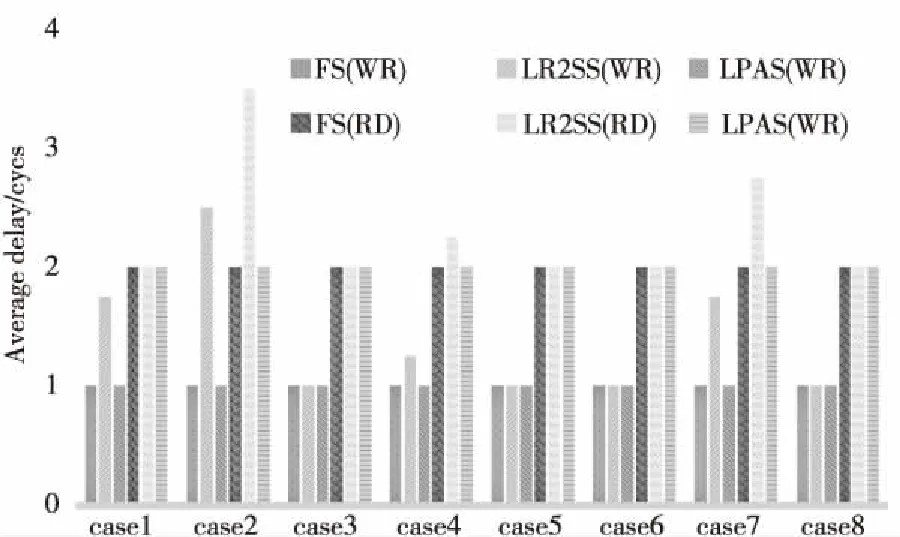
Figure 6 Read and write delay in simple cases图6 简单读写访问延迟统计
简单无冲突测试情况下,FS和LPAS具有相同的读写访问延迟,其中平均写访问延迟为1个周期,平均读访问延迟为2个周期。LR2SS的平均写访问延迟为1.4个周期,平均读访问延迟为2.31个周期。由此可得出,在无冲突或低冲突率情况下,FS和LPAS的平均访问延迟最小,LR2SS的平均访问延迟最大。
为了更加深入地分析3种簇内结构延迟情况,选取了4类复杂情况测试用例,对写访问情况进行测试比对,每种情况至少模拟15种测试case,情况I是不同行的PEs访问不同行的Caches,也称为行循环访问。测试结果表明3种结构的行循环平均写访问延迟相同,都为1个周期,这里省略了比对图。情况II是不同列的PEs访问不同列的Caches,也称为列循环访问,仿真统计结果见图7。情况III是基于一定的冲突概率不同行的PEs访问不同行的Caches,称为不同行访问不同行,仿真统计结果见图8。情况IV是基于一定的冲突概率不同列的PEs访问不同列的Caches,称为不同列访问不同列,仿真统计结果见图9。

Figure 7 Line loop access delay图7 列循环访问延迟
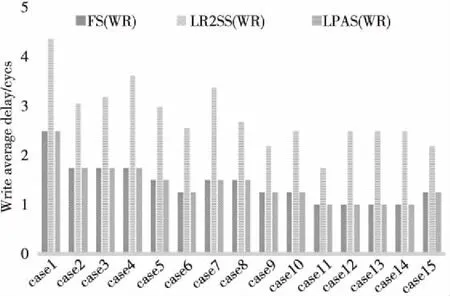
Figure 8 Different lines delay with different lines access图8 不同行访问不同行

Figure 9 Different rows delay with different rows access图9 不同列访问不同列
以上4种复杂情况测试中,无冲突情况下: LR2SS、FS和LPAS结构的行循环平均写访问延迟相同,均为1个周期;FS和LPAS的列循环平均写访问延迟均为1个周期,LR2SS的平均列循环写访问延迟最大,为2.3个周期;加入冲突后:不同行访问不同行的访问情况下,FS和LPAS的平均写访问延迟均为1.42个周期,LR2SS的平均写访问延迟最大,为2.8个周期;不同行访问不同列的访问情况下,LPAS的平均写访问延迟最低为1.41个周期,FS的平均写访问延迟为1.43个周期,LR2SS的平均写访问延迟最大,为2.61个周期。从以上各种模拟情况可得到:多数情况下FS和LPAS的平均写访问延迟基本相同,也是3种结构中平均写访问延迟最低的,在有冲突的不同列访问不同列的访问中,LPAS平均写访问优于FS结构。
6 结束语
针对可重构视频阵列处理器数据的访存问题,本文基于分布式Cache结构设计了一种簇内局部优先访问结构,该结构实现了簇内4×4个PE对4×4个Cache的并行访问,在没有冲突时对簇内Cache直接访问,有冲突时按照本地区域优先,远程次之的响应顺序完成访问。通过Xilinx公司的ZYNQ系列芯片 XC7Z045 FFG900-2 FPGA开发板进行验证,在无冲突情况下,该互连结构支持簇内16个PE的同时读/写访问,最高频率可达221 MHz,访存峰值带宽为7.6 GB/s。相比于文献[15]的LR2SS结构,有更低的访问延迟,相比于文献[16]的FS结构,在局部数据访问时有较好的响应特性,该LPAS结构相比于前2种结构占用的硬件资源最少,且在大多数情况下有较低的访问延迟。最后选取64×64的图像提取纹理特征的算法在此结构上映射实现,完成该算法耗费时间为0.24 ms,算法映射过程中的访问峰值带宽为7.6 GB/s,且LPAS结构可为该算法提供 478.125 MB/s的访存带宽。
