基于AGNES聚类的能耗均衡WSNs优化路由算法*
2020-05-04苟平章贾向东
苟平章,张 芬,毛 刚,贾向东
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
无线传感器网络WSNs(Wireless Sensor Networks)是由随机部署在监测区域内或附近具有通信能力、计算能力和数据处理能力的大量传感器节点组成,通过节点多跳传输数据与基站进行通信的自组织方式网络[1]。由于WSNs中节点一般通过电池供电,自身携带能量有限,并且电池不便更换,因此提高能量使用效率,降低网络能量消耗,延长网络生命周期成为WSNs研究的重要课题。
WSNs分簇路由协议中,最典型的是LEACH(Low Energy Adaptive Clustering Hierarchy)协议[2],该协议以随机选举簇头的方式将网络分成若干簇,按轮的形式周期性选举簇头,以达到网络中能耗均衡的目的。但是,该协议存在簇头个数随机,簇头有可能分布于稀疏节点位置或者网络边缘位置的问题,簇头与基站间采用直接单跳通信,会导致簇头能耗过高,加速网络死亡。LEACH-C协议[3]采用集中式控制,由基站决定簇头个数,采用模拟退火算法选举出最优簇头,但未考虑簇的分布位置问题。LEACH-GA(Genetic Algorithm based on LEACH)协议[4]基于遗传算法优化簇头选举,但数据传输阶段与LEACH协议相同。通过对LEACH、LEACH-C和LEACH-GA协议的性能对比分析[5]可知,LEACH-C和LEACH-GA协议相对于LEACH协议在能耗方面得到了提升。LEACH-improved路由算法[6]通过加入间距因子、剩余能量因子和节点密度因子来改进LEACH协议的簇头选举公式,使簇头的选举更加合理,但簇分布不均匀。KBECRA(Balanced Energy Consumption Routing Algorithm based on K-means)路由算法[7]采用K-means聚类算法使成簇更加合理,并且通过选举主、副簇头,节省了能耗,但是K-means算法随机选择聚类中心会导致局部最优的问题。KUCR(Uniform Clustering Routing based on K-means)路由算法[8]簇内根据节点剩余能量和距离选举簇头,但未考虑能量和距离对簇头选举的影响因子不同,导致簇头选举不合理的问题。UCPO(Uneven Clustering and Path Optimization)路由算法[9]根据最佳簇头个数划分区域,在数据传输阶段使用Dijkstra算法,降低了数据传输能耗,但在路径选择上未考虑中间节点的剩余能量和与基站的距离因素。基于粒子群优化算法的分簇路由协议[10]优化了分簇,但在数据传输时仍然采用单跳通信方式,增加了数据传输能耗。KAF(K-means And FAH)分簇算法[11]基于K-means和模糊综合评价方法,有效减少了能耗。IFCEER(Energy Efficient Routing based on Improved Firefly Clustering)路由算法[12]采用改进萤火虫聚类算法进行分簇,使分簇合理,但数据传输路径未优化。UCR(Unequal Cluster-based Routing)协议[13]采用竞争半径实现非均匀分簇,使用贪婪算法优化路由选择,但该算法只考虑当前节点到达基站的代价,忽略当前已花费的代价,所以找到的传输路径并非最优路径。基于能量约束的簇首多跳算法[14],在数据传输阶段采用Prim最小生成树算法,考虑节点剩余能量,使簇头之间形成一条多跳的最优路径,但未考虑距离对中间节点的影响。基于距离的二层中继节点选择阈值算法[15]实现了一种在二层网络中根据与基站最近距离选择中继节点的新技术,但仅考虑了距离因素。LECP-FC(Low Energy Cluster Protocol-Fuzzy Control)协议[16]通过考虑影响因子修改LEACH中簇头选举公式来降低网络能耗。文献[17]通过分析不同维数观测矩阵对Hybrid-CS发送数据影响,求出较优化的观测矩阵维数,从而降低网络能耗。文献[18]提出I_AOMDV(Improved Ad-hoc On-demand Multipath Distance Vector)协议,在路由发现阶段不再使用发生拥塞和低能量的节点,以均衡能耗,在路由维护阶段使用HELLO信息交换邻居节点的“剩余能量”和“队列长度”,从而使I_AOMDV协议更适应静态WSNs的数据传输。文献[19]提出一种聚类算法减少无线传感器网络的能耗,创建一种cluster-tree分簇路由结构的传感器网络,实现了均衡能耗、延长网络生命周期的目标。
综合以上研究,本文提出基于AGNES聚类的能耗均衡WSNs优化路由算法EBRAA(Energy-Balanced Routing Algorithm based on AGNES clustering)。在网络初始阶段,将最优簇头个数作为AGNES算法的终止条件,完成网络的均匀分簇;集中分簇后,在簇头选举阶段,采取簇内分布式选举簇头策略,各簇内根据节点剩余能量、与基站距离及两者的权重因子优化选举簇头;在数据传输阶段,采用优化后的Dijkstra算法,并加入能量阈值公式和距离阈值公式,以基站为源节点,将满足阈值公式的簇头节点放入节点集合后,计算基站到其他簇头节点的最短路径,优化了簇头间多跳传输数据的路径。EBRAA算法使簇的分布更加均匀,簇头选举更加合理,减少路径传输能耗,均衡网络能耗,达到延长网络生命周期的目标。
2 系统模型
2.1 网络模型
网络模型假设如下:
假设1 实验区域范围为M×M,N个传感器节点随机分布在该区域内。
假设2 所有传感器节点具有相同的初始能量、处理能力和通信能力。
假设3 所有传感器节点有自己的ID,可以知道自身的剩余能量和位置,可对接收到的数据进行融合。
假设4 所有节点不可移动,随机分布后无人为干预。
假设5 链路对称,节点可以根据接收到的信号强度估算两者之间的距离,节点的发射功率和通信半径可以自行调控。
假设6 节点以固定速率监测环境,定期传输收集到的数据。
2.2 能耗模型
能耗模型采用和LEACH协议相同的1阶无线电通信能耗模型,该模型如图1所示。
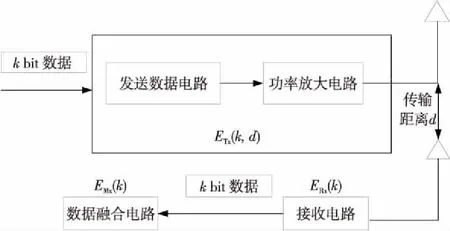
Figure 1 Energy consumption model图1 能耗模型
传感器节点发送kbit数据消耗的能量ETx(k,d)为:
ETx(k,d)=ETx-elec(k)+ETx-amp(k,d)=
(1)
其中,ETx-elec为发射电路消耗的能量,ETx-amp为发射功率放大器消耗的能量,k为发送数据的比特数,d为数据传输的距离,Eelec为发射电路处理1 bit数据所消耗的能量,εfs为自由空间信道模型下发送功率放大器向单位面积发射1 bit数据消耗的能量,εamp为多径衰落信道模型下发送功率放大器向单位面积发射1bit数据消耗的能量。通过式(1)计算出d0的临界值:
(2)
节点接收kbit数据需要消耗的能量ERx(k)为:
ERx(k)=k×Eelec
(3)
簇头对kbit数据进行融合需要消耗的能量EMx(k)为:
EMx(k)=k×Eda
(4)
其中,Eda为数据融合率。为了求出最优簇头个数,假定簇头向基站传输的能耗模型是多径衰落信道模型,簇内普通节点向簇头传输的能耗模型是自由空间信道模型,监测区域大小为M×M,分布节点总数为N,则根据式(1)~式(4)和文献[5],计算出最优簇头个数kopt的值,如式(5)所示:
(5)
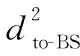
3 EBRAA算法
3.1 网络初始阶段
在网络初始阶段,EBRAA算法采用确定簇数的AGNES 算法对节点进行分簇。开始时将每个对象作为1个初始聚类簇,即将监测区域的N个节点看做N个簇,然后在算法运行的每一步中根据簇间相似度将这些簇一步步地合并直至达到设定簇数。
2个簇间的相似度(也称为簇间距离)有多种不同的计算方法。其中,单链度量(最小距离)是计算2个不同簇之间任意2点的最短距离;完全链度量(最大距离)是计算2个不同簇之间任意2点之间的最长距离;组平均度量(平均距离)是计算2个簇之间任意2点的平均距离。因为单链度量和完全链度量代表了簇间相似度的2个极端,所以本文采用组平均度量davg作为相似度计算方法。相似度计算方法如图2所示,图2a为单链度量,图2b为完全链度量,图2c为组平均度量。
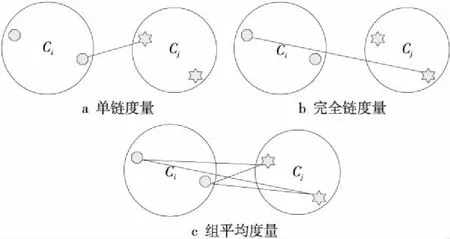
Figure 2 Similarity calculation method图2 相似度计算方法
采用图2c的度量方法分簇过程为,找出距离最近的2个聚类簇Ci和Cj进行合并,合并过程一直迭代进行,直到对象个数满足簇数目kopt,则完成分簇。簇数目为kopt的AGNES 算法具体步骤如下所示:
输入:包含N个节点的数据集,初始节点之间的距离度量dini,终止条件的簇个数为根据式(5)计算出的kopt。
Step 1 将每个节点当成1个初始聚类簇Cj,j=1,2,…,N。
Step 2 计算任意2个簇的平均距离davg,即Ci、Cj中所有节点的平均距离,求出节点之间距离的相似矩阵。计算公式如式(6)所示:
(6)
其中,Ci、Cj为2个簇;|Ci|、|Cj|为2个簇中节点个数;p为Ci簇中节点;q为Cj簇中节点。根据式(6)计算出所有聚类簇的平均距离davg后得到节点之间距离的相似矩阵。
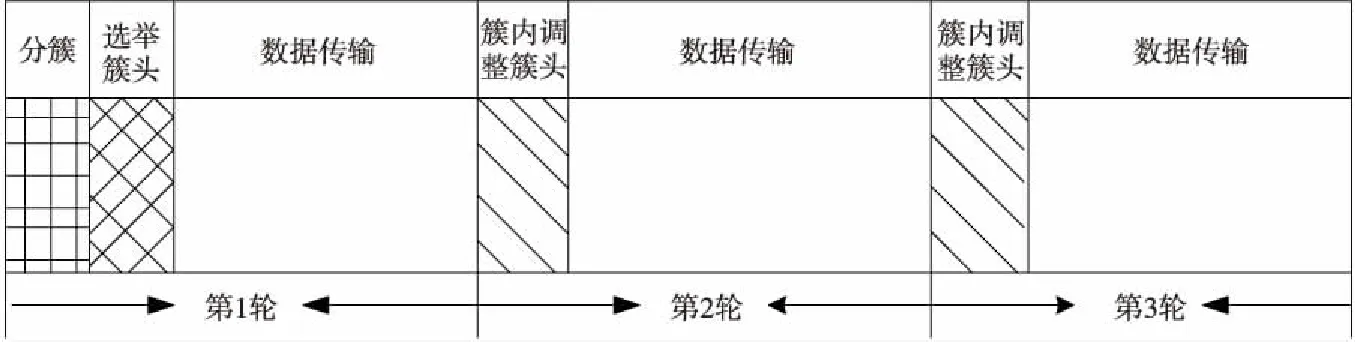
Figure 4 Protocol run rounds图4 协议运行轮次
Step 3 使用相似矩阵查找平均距离最小的2个簇(即最相似的2个簇)Ci和Cj,合并2个簇为1个簇,即Cij=Ci∪Cj,生成新的簇集合Cij,将聚类簇Cj重编号为Cj-1,簇的个数通过合并更新,通过式(6)重新计算新创建的簇Cij到其他所有簇Cr(r≠i∨r≠j)的距离,从而更新簇间距离的相似矩阵。
Step 4 重复Step 2和Step 3,直到簇的个数满足最优簇头个数kopt,表示完成均匀分簇,网络初始阶段结束。
3.2 分布式簇头选举阶段
在选举簇头阶段,分簇后产生的kopt个簇在簇内进行分布式簇头选举,因为节点位置固定且无人为干预,所以每一轮结束后,簇内普通节点将自己剩余能量信息告知簇头节点,簇头计算每个节点的竞争值W,计算公式如式(7)所示:
(7)
其中,Eres为节点剩余能量,Dto-BS为节点到基站的距离,w1为簇内节点剩余能量的权重因子,w2为簇内节点到基站距离的权重因子。
所有节点距基站的平均距离Davg的计算如下所示:
(8)
其中,Di为簇内节点i与基站距离。
通过比较Dto-BS和Davg的大小来确定w1和w2的值。经过实验验证,当Dto-BS>Davg时,w1=4/5,w2=1/5,此时节点剩余能量因素对簇头选举影响较大;当Dto-BS≤Davg时,w1=2/5,w2=3/5,此时节点与基站距离因素对簇头选举影响较大。加入权重因子可以增加离基站较远的节点成为簇头节点的概率,减少离基站较近的节点过早死亡的现象,均衡整个网络的能耗。
将簇头节点的竞争值Wch与簇内其他普通节点的竞争值Wi相比较,Wch和Wi的值按照式(7)计算,如果Wch Figure 3 Distributed cluster head contention图3 分布式簇头竞争 由于分布式簇头选举不同于LEACH协议中每轮都需要更换簇头节点,所以更加节省能量,使能量效率提高。协议运行轮次如图4所示。 数据传输阶段使用改进的Dijkstra算法,考虑节点剩余能量和与基站距离因素,计算出最短路径后,簇头间采用多跳路由对数据进行转发。 Dijkstra算法将网络作为1个带权图G=(V,E),BS和簇头节点为图中的顶点集合,顶点之间距离为权值。将BS作为源节点,创建node_id和T2个节点集合,开始时,node_id节点集合只包含BS源节点,其他簇头节点ID存放在T节点集合中;将距离BS最近的T节点集合中的节点ID,即权值最小的节点加入node_id节点集合,其他节点ID继续存在T集合中;迭代求权值最小节点的ID,并将其放入node_id节点集合中;最终求得源节点BS到带权图G中其他簇头节点的最小权值之和的路径,得到多跳最小能耗路由。 在改进的Dijkstra算法中,设置1个能量阈值Elim,计算公式如式(9)所示: (9) 其中,Ei是节点i的剩余能量,w3是调整因子。随着轮数的增加,网络平均能量降低,适当减小调整因子w3,使Elim得到调整,防止路由多跳中间节点数量过少导致跳距过大的问题。Dijkstra在选择下一跳中间簇头节点时,考虑中间节点s的剩余能量Eres和与基站的距离ds-BS,如式(10) 所示: Eres≥Elim∧ds-BS≥d0 (10) 改进的Dijkstra算法具体步骤如下所示: Step 1 初始化节点集合。设置2个节点集合T和node_id,节点集合node_id中存放已经找到最短路径的节点ID,节点集合T中存放当前还未找到最短路径的节点ID,即为kopt个节点数量,kopt为每轮选举的簇头总数; Step 2 开始时,节点集合node_id中只有1个节点,即基站BS作为源点v0。设置1个二维数组distance[i][j]表示节点i和节点j之间的距离,一维数组dist[i]表示从源节点v0到节点i的最短特殊路径长度; Step 3 在节点集合T中选举当前长度最短的1条路径(v0,…,vi),如果节点vi满足式(10),则将节点vi加入到节点集合node_id中,即node_id=node_id∪{vi},并修改源节点v0到T中各节点的最短特殊路径长度,即dist[i],此时并非全部节点的最短路径,继续下列步骤; Step 4 重复Step3,直到所有簇头节点都加入到节点集合node_id中,即|node_id|=kopt+1,此时,BS到网络中所有簇头节点的最短路径已经求出; Step 5 求出BS到簇内所有簇头节点最短路径后,簇头按照此最短路径多跳传输数据至BS。 改进的Dijkstra算法过程如图5所示。 Figure 5 Improved Dijkstra algorithm图5 改进的Dijkstra算法 图5中,A、B、C、D、E、F、G均为簇头节点。假设E、F和G节点到BS的距离d1、d2和d3均小于式(2)的d0,不满足式(10),所以E、F和G节点不需要参与Dijkstra算法,选择与BS直接通信。其余节点A、B、C、D与BS通过改进的Dijkstra算法计算出最短路径后,多跳地传输数据,假设A、B、C、D节点均满足式(10),其过程如表1所示。 Table 1 Shortest path iteration表1 最短路径迭代过程 由表1可得,BS到A节点最短路径为BS→A,BS到B节点最短路径为BS→D→B,BS到C节点最短路径为BS→D→B→C,BS到D节点最短路径为BS→D。 计算出最短路径后,各节点反向传送数据到BS,其路径分别为A→BS,B→D→BS,C→B→D→BS,D→BS,E→BS,F→BS,G→BS。 本文利用Matlab从簇头分布位置、节点的存活数、节点的死亡数和节点总能耗等方面,对基于LEACH协议的算法(简称LEACH算法)、KBECRA和EBRAA算法进行仿真比较,仿真参数设置如表2所示。 Table 2 Experiment parameters表2 实验参数 图6为分簇后簇头分布图。可以看出,LEACH算法的簇头个数随着轮数随机取值,且分布位置不均匀,会出现簇头集中分布和分布在网络边缘的情况;而EBRAA和KBECRA算法的簇头分布更加均匀,簇结构更合理,且簇头个数为设定的最佳簇头数kopt,使得簇头个数稳定。 Figure 6 Cluster head distribution map图6 簇头分布图 图7为网络运行中节点的存活数随着轮数的增加而变化的趋势图。从图7中可以看出,LEACH算法在300轮左右时存活节点数开始减少,在655轮左右时剩余50%存活节点,在1 047轮左右时存活节点为0;KBECRA算法在500轮左右时存活节点数开始减少,在824轮左右时剩余50%存活节点,在1 160轮左右时存活节点数为0;EBRAA算法在500轮左右时存活节点数开始减少,在885轮左右时剩余50%存活节点,在1 255轮左右时存活节点数为0。 Figure 7 Number of surviving nodes图7 存活节点数 图8为网络运行中死亡节点数随着轮数的增加而变化的趋势图。从图8中可以看出,LEACH算法第1个节点死亡发生在300轮左右,50%节点死亡发生在650轮左右,全部节点死亡发生在1 050轮左右;KBECRA算法第1个节点死亡发生在500轮左右,50%节点死亡发生在823轮左右,全部节点死亡发生在1 162轮左右;EBRAA算法第1个节点死亡发生在500轮左右,50%节点死亡发生在890轮左右,全部节点死亡发生在1 250轮左右。 Figure 8 Number of dead nodes图8 死亡节点数 图9为网络运行中节点总能耗随着轮数增加而变化的趋势图。从图9中可以看出,LEACH、KBECRA和EBRAA算法能耗为50%时分别发生在295轮,392轮和440轮左右,能耗为100%时分别发生在1 030轮,1 159轮和1 230轮左右。 Figure 9 Total energy consumption of nodes图9 节点总能耗 综上所述,EBRAA算法簇头分布更加合理,网络生命周期比LEACH和KBECRA算法的长。 本文在分析研究分簇路由算法LEACH和基于K-means聚类路由算法KBECRA基础上,针对其分簇不合理、簇头选举随机和单跳传输路由造成网络能耗不均的问题,提出一种基于AGNES聚类的能耗均衡WSNs优化路由算法(EBRAA)。通过确定簇数的AGNES聚类算法使簇的分布更加均匀,稳定了簇头个数,避免了簇头分布过于集中或者分布在网络边缘位置的情况。在簇内考虑能量和距离因素,以分布式方式选举和更换簇头,减少了每轮都需要选举簇头的能量消耗。采用改进后的Dijkstra算法产生簇头间多跳的最短传输路径,路径得到优化,最终提高了节点能量的利用率,均衡了网络能耗,延长了网络的生命周期。仿真结果表明,EBRAA算法相较于LEACH和基于K-means分簇路由算法KBECRA,延长了网络生命周期,提升了网络能量利用率。
3.3 数据传输阶段

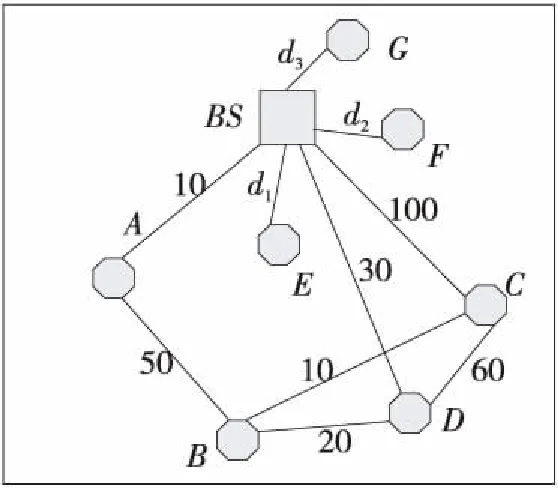
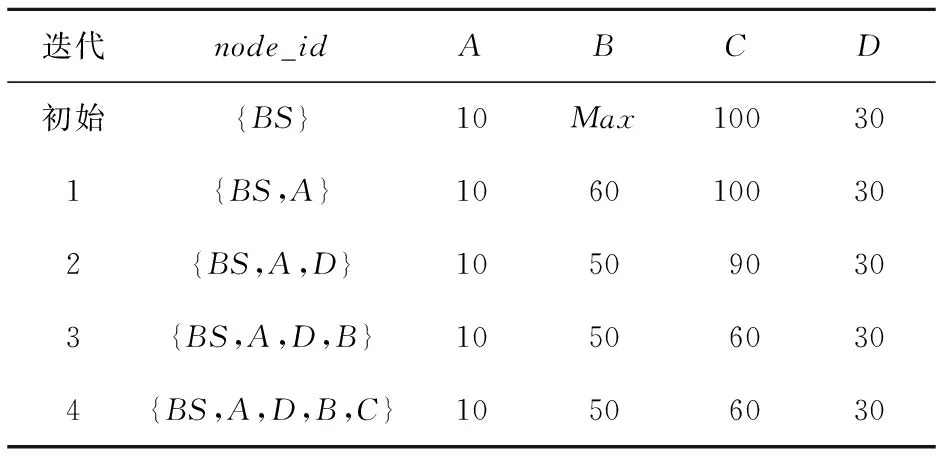
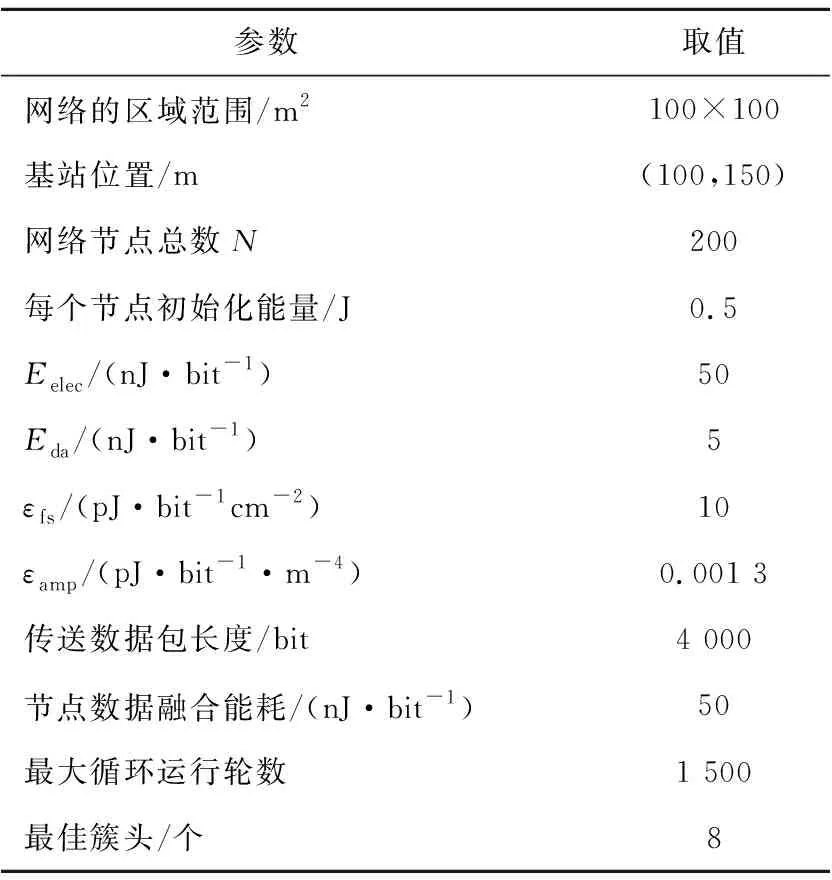
4 仿真及性能分析
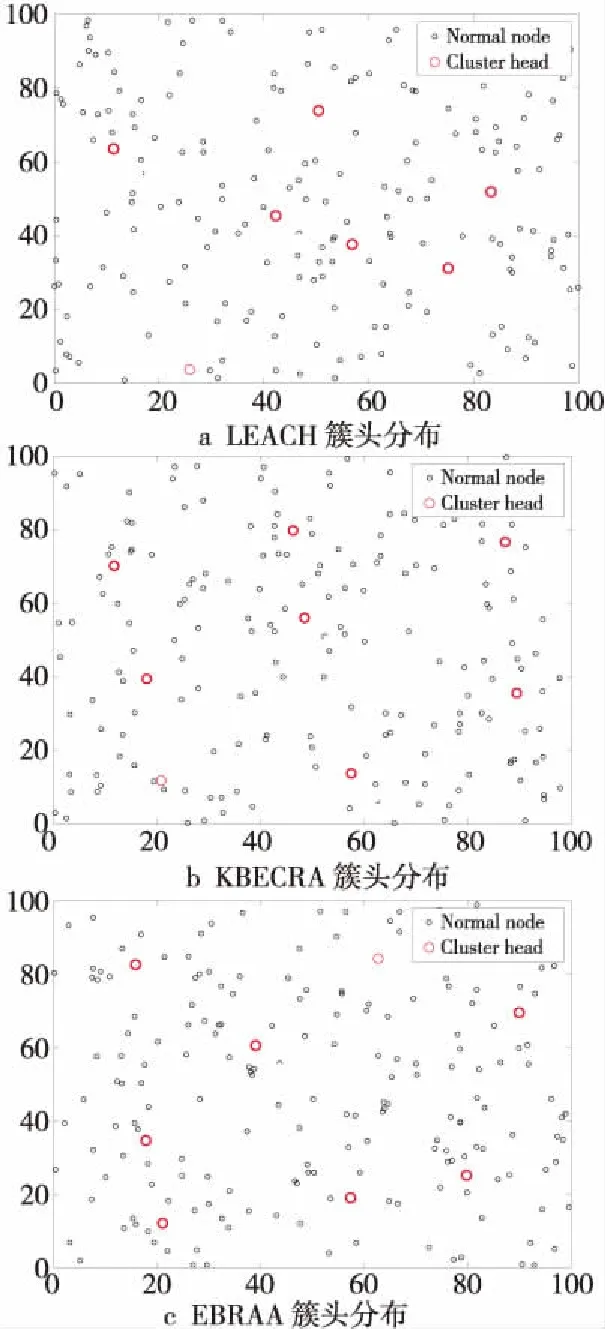



5 结束语
