基于ACO-SVM的光谱分类算法研究
2020-04-30于晓阳莫家庆吕小毅唐军陈程陈晨
于晓阳 莫家庆 吕小毅 唐军 陈程 陈晨


摘 要:为了实现胡萝卜汁品牌的快速无损鉴别,文章以市售两种品牌的胡萝卜汁为研究对象,通过采集拉曼光谱,并结合支持向量机算法,建立了快速判断胡萝卜汁品牌的分类模型。两种品牌的胡萝卜汁光谱主要在1 007 cm-1,1 157 cm-1,1 516 cm-1这3个谱峰存在差异。先对拉曼光谱进行预处理,再选用蚁群优化算法进行特征选择,最后结合SVM构建分类模型。结果显示,相比SVM直接分类,模型ACO-SVM的最优分类准确率为96.67%,提高了2.5%;其分类时间为7.17 s,缩短了163.31 s。研究表明,基于拉曼光谱分析技术和模式识别算法构建的分类模型能够有效地鉴别胡萝卜汁品牌。
关键词:拉曼光谱;蚁群优化算法;胡萝卜汁;特征选择;支持向量机
假冒食品不仅损害了消费者的利益,而且也对正常的市场经济秩序造成了极大危害。目前市售胡萝卜汁品牌繁多,质量也参差不齐,市场上缺少一种能简单、快速、无损地鉴别胡萝卜汁品牌的方法,来打击假冒胡萝卜汁。为此,本研究将拉曼光谱分析技术同模式识别算法相结合,构造分类模型,鉴定胡萝卜汁品牌。
目前,应用在食品品种、品牌鉴别方面的光谱分析技术主要有荧光光谱分析技术、红外光谱分析技术、拉曼光谱分析技术。本研究采用拉曼光谱分析技术,原因如下:首先,作为胡萝卜汁样品中的一种主要成分,水在红外区有强烈的吸收能力,而其拉曼光谱信号在一般感兴趣的范围内则非常微弱。其次,胡萝卜汁样品中的类胡萝卜素能产生共振拉曼光谱而不能产生荧光。与红外光谱分析技术[1]相比,这种技术结合模式识别算法在众多的分类问题中都取得了更好的效果。国内外已有研究人员将拉曼光谱分析技术同模式识别算法结合对鱼片种类[2]、奶酪真伪[3]和葡萄酒产地[4]等的鉴别进行了研究,有效地实现了食品分类。在众多模式识别算法中,专门针对小样本学习问题提出的支持向量机(Support Vector Machine,SVM)[5-6]不仅非常适合处理非线性问题,而且具有良好的推广能力。
鉴于此,本研究结合拉曼光谱分析技术和SVM构造分类模型。为了在提高模型性能的同时避免出现过拟合现象,采用特征降维[7-8]简化分类模型是十分必要的。常见的主成分分析法(Principle Component Analysis,PCA)降维后的特征集失去了原有的物理意义和一些有用的类间区分信息,而特征选择通过选择与分类密切相关的特征来降低所需特征维数,弥补了PCA的不足。特征选择本质上是一个组合优化问题,相比其他优化方法,近年来迅速发展起来的智能优化算法具有通用性强、稳健、全局优化能力强等突出优点。因此,本研究选用极具代表性的智能优化特征选择算法—蚁群优化算法(Ant Colony Optimization,ACO)[9-10]对光谱数据进行降维。
本研究对打击假冒胡萝卜汁具有一定的借鉴意义,为其提供了技术支持。在一定程度上加强了品牌保护,有利于维护市场的公平竞争、促进市场的良性循环。
1 实验过程
1.1 实验材料和方法
实验以市售两种品牌的胡萝卜汁为实验材料,研究胡萝卜汁品牌的鉴别方法。一种是神内胡萝卜汁,样品个数为40个;另一种是农夫果园,样品个数为50个。实验使用共聚焦显微拉曼光谱仪(LabRAM HR Evolution RAMAN SPECTROMETER,HORIBA Scientific Ltd.)在532 nm激光源下测其拉曼光谱。操作时,用毛细管吸取样品放在载物台上,先用10×镜找到物像,再用50×镜观察,采集100~4 000 cm-1范围内的拉曼光谱信号,数据采集的积分时间为5 s,积分次数为3次。本实验共采集了两种品牌的胡萝卜汁共计90个样品的拉曼光譜。需要注意的是,为了校正仪器以保证结果的准确性,光谱仪每次在使用前要测单晶硅片的拉曼光谱,使其峰位保持在(520.7±0.3)cm-1范围内。
1.2 光谱数据处理
因为拉曼光谱信号本身就比较弱,而且存在很多噪声,所以应对测得的拉曼光谱进行去噪处理,提高其信噪比。拉曼光谱中往往也包含较强的荧光背景(即基线)。其存在会影响后续的光谱归一化等操作,需提前将其去除。考虑到以上两点,首先,用FFT滤波器5点平滑法对各谱线进行去噪处理,可以去除大部分的噪声,使光谱曲线较为平滑,并完整保存了胡萝卜汁样品的拉曼特征峰。其次,用自适应迭代重加权惩罚最小二乘(adaptive iteratively reweighted Penalized Least Squares,airPLS)法[11]校正基线如图1—2所示。此方法能够完整保留胡萝卜汁样品原始拉曼光谱的特征峰,并且提高了峰的对比度和辨识度。最后,将经去噪和基线校正处理后的拉曼光谱数据归一化,进行特征选择。
2 光谱分析
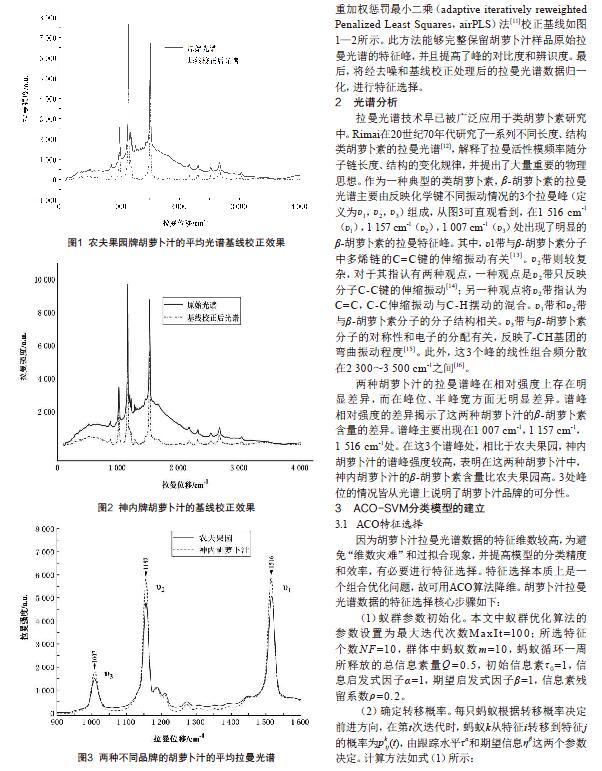
拉曼光谱技术早已被广泛应用于类胡萝卜素研究中。Rimai在20世纪70年代研究了一系列不同长度、结构类胡萝卜素的拉曼光谱[12],解释了拉曼活性模频率随分子链长度、结构的变化规律,并提出了大量重要的物理思想。作为一种典型的类胡萝卜素,β-胡萝卜素的拉曼光谱主要由反映化学键不同振动情况的3个拉曼峰(定义为υ1,υ2,υ3)组成,从图3可直观看到,在1 516 cm-1(υ1),1 157 cm-1(υ2),1 007 cm-1(υ3)处出现了明显的β-胡萝卜素的拉曼特征峰。其中,υ1带与β-胡萝卜素分子中多烯链的C=C键的伸缩振动有关[13]。υ2带则较复杂,对于其指认有两种观点,一种观点是υ2带只反映分子C-C键的伸缩振动[14];另一种观点将υ2带指认为C=C,C-C伸缩振动与C-H摆动的混合。υ1带和υ2带与β-胡萝卜素分子的分子结构相关。υ3带与β-胡萝卜素分子的对称性和电子的分配有关,反映了-CH基团的弯曲振动程度[15]。此外,这3个峰的线性组合频分散在2 300~3 500 cm-1之间[16]。
两种胡萝卜汁的拉曼谱峰在相对强度上存在明显差异,而在峰位、半峰宽方面无明显差异。谱峰相对强度的差异揭示了这两种胡萝卜汁的β-胡萝卜素含量的差异。谱峰主要出现在1 007 cm-1,1 157 cm-1,1 516 cm-1处。在这3个谱峰处,相比于农夫果园,神内胡萝卜汁的谱峰强度较高,表明在这两种胡萝卜汁中,神内胡萝卜汁的β-胡萝卜素含量比农夫果园高。3处峰位的情况皆从光谱上说明了胡萝卜汁品牌的可分性。
3 ACO-SVM分类模型的建立
3.1 ACO特征选择
因为胡萝卜汁拉曼光谱数据的特征维数较高,为避免“维数灾难”和过拟合现象,并提高模型的分类精度和效率,有必要进行特征选择。特征选择本质上是一个组合优化问题,故可用ACO算法降维。胡萝卜汁拉曼光谱数据的特征选择核心步骤如下:
(1)蚁群参数初始化。本文中蚁群优化算法的参数设置为最大迭代次数MaxIt=100;所选特征个数NF=10,群体中蚂蚁数m=10,蚂蚁循环一周所释放的总信息素量Q=0.5,初始信息素τ0=1,信息启发式因子α=1,期望启发式因子β=1,信息素残留系数ρ=0.2。
(2)确定转移概率。每只蚂蚁根据转移概率决定前进方向,在第t次迭代时,蚂蚁k从特征i转移到特征j的概率为pkij(t),由跟踪水平τα和期望信息ηβ这两个参数决定。计算方法如式(1)所示:
(1)
(3)信息素更新。当所有蚂蚁都死亡时,全部可行解中适应值最小的解即为此次迭代的最优解,并暂时将其作为全局最优解保存,蚂蚁按式(2)更新信息素并进行新一轮迭代,若得到的最优解比全局最优解更好,则用本次最优解替代;否则,全局最优解保持不变:
(2)
其中,Δτkij为信息素增量,Δτkij=Q*Fkij,Q为总信息素量,ρ为信息素轨迹的衰减系数,0<ρ<1。
3.2 支持向量机
3.2.1 线性可分情况与线性不可分情况
训练样本集分为线性可分与线性不可分两种情况。对于线性可分的样本,最优分类超平面的求解就是求(w, b)的最佳值。可以将该问题转化为式(3)所示的二次规划问题(Quadratic Programming,QP):
(3)
称式(3)所述问题为原始问题,可以应用拉格朗日乘子法构造拉格朗日函数再通过求解其对偶问题得到原始问题的最优解。构造拉格朗日函数后问题转化为:
(4)
其中,αi≥0, i=1, 2, ... , n代表样本xi对应的拉格朗日乘子。對于大多数情况,这些αi只有很少一部分不为零,不为零的αi所对应的样本xi就是支持向量。式(3)的等价优化问题为:
(5)
根据拉格朗日对偶性,式(3)所述问题即原始问题的对偶问题是:
(6)
为了求得对偶问题的解,需要先求得L(w, b, α)对w和b的极小再求对α的极大。
(1)求:对拉格朗日函数求导并令其导数为0,可以得到:
(7)
将式(7)代入L(w, b, α),得:
(8)
所以:
(9)
(2)求对α的极大等价于式(9)取负数后对α求极小,即:
(10)
这意味着求解原始最优化问题式(3)可以转换为求解对偶最优化问题(10)。不难发现,式(10)是不等式约束条件下的QP问题。解出式(10)的最优解α*后,求解式(7)得到最优分类超平面:
(11)
则分类的决策函数为
(12)
对于线性不可分的样本,构建其最优分类超平面时,需要放松上述不等式中的约束条件,使之能用于线性不可分样本的求解。在二次规划问题的约束条件中增加松弛变量ξi可解决线性不可分问题,即:
(13)
当出现分类错误时,ξi大于零,ξi可以用来度量一个样本点错分的误差,就是训练样本划分错误的上界。为了使分类间隔和分类错误有一个折中,在原目标函数中加入一个错误惩罚因子C,C的大小代表了对分类出错时的惩罚程度,则目标函数变为:
(14)
类似地,线性不可分样本的最优分类超平面的求解几乎与线性可分时相同,不同的只是约束条件变为0≤αi≤C, i=1, 2, ... , n。
3.2.2 非线性情况及核函数
SVM对无法用线性方法划分的训练样本采用如下思想:在映射函数的作用下,将原空间的训练样本映射到一个高维特征空间,在该空间中样本线性可分,然后在该空间中构建一个最优分类超平面。
高维特征空间中分类函数的求解只需计算训练样本之间的内积,从而避免了复杂的高维计算;满足Mercer条件的核函数可代替内积运算,在不增加计算复杂度的前提下实现线性分类。
首先,选取适当的核函数和适当的参数C,构造最优化问题:
(15)
其次,利用现成的二次规划问题求解算法或者SMO算法求得最优解α*。
再次,选择α*的一个满足0<α*j (16) 最后,构造决策函数: (17) 式(17)中,采用不同的核函数构造出的SVM是不同的。支持向量机分类的重点在于核函数的构建与选择,合适的核函数可以巧妙解决高维空间维数灾难问题,降低高维空间中计算的复杂度。SVM常用的核函数有4种:线性核函数、多项式核函数、RBF核函数和Sigmoid核函数。
4 實验结果与分析
本文用ACO算法进行特征选择,并结合SVM建立胡萝卜汁品牌的分类模型,进行了对比仿真实验:实验将所选特征的个数设置为10,最大迭代次数设置为100,把分类误差率作为适应度函数的适应值,用分类器SVM(采用网格寻优法计算最优参数值)和十折交叉验证得到的适应值来评价特征选择算法的性能优劣。适应值越低说明该特征选择算法性能越好。ACO迭代次数与适应值的关系如图4所示,其最优结果为0.025,最优结果最早出现的代数为39。若为了在优化效果不大幅下降的前提下减少计算开销,将最大迭代次数设为50较为合适。
在使用ACO-SVM分类时,以分类准确率和分类时间作为评价分类模型的有效指标,为了使结果更接近其真实性能,采用网格寻优法和十折交叉验证。观察图5可以发现,在分类精度方面,分类模型ACO-SVM在采用RBF核函数时的分类精度最高,且无论采用哪种核函数,相比于直接使用SVM分类,其分类精度都有所提高,具体来说,在采用Linear,Polynomial,RBF,Sigmoid核函数时,分类准确率分别提高了1.67%,3.34%,2.5%,2.5%。由表1可直观看出,在分类效率方面,无论使用哪种核函数,模型ACO-SVM的分类效率都比直接分类时有显著提高,说明使用分类模型ACO-SVM进行胡萝卜汁品牌的分类是非常有效的。
5 结语
为了鉴定胡萝卜汁品牌,本文将拉曼光谱分析技术同模式识别算法相结合,建立了分类模型ACO-SVM,实现了对市售两种品牌的胡萝卜汁的有效分类。首先,对光谱进行去噪、基线校正和归一化处理;其次,进行特征选择;最后,用SVM进行分类。经特征选择,特征数由最初的2 710个缩减到10个,达到了去除冗余特征的目的,相比直接分类,ACO-SVM在提升分类精度的同时,大大提高了分类效率。研究表明,分类模型ACO-SVM能够有效地将两种品牌的胡萝卜汁分开,实现了胡萝卜汁品牌的快速鉴别,为打击假冒胡萝卜汁提供了技术支撑。
[参考文献]
[1]张海红,张淑娟,王凤花,等.应用可见-近红外光谱快速识别沙棘汁品牌[J].光学学报,2010(2):574-578.
[2]BO?IDAR R,RALF H,PETRA R,et al.The potential of raman spectroscopy for the classification of fish fillets[J].Food Analytical Methods,2016(5):1301-1306.
[3]KAMILA DE S,CALLEGARO L D S,STEPHANI R,et al.Analysis of spreadable cheese by Raman spectroscopy and chemometric tools[J].Food Chemistry,2016(3):441-446.
[4]MANDRILE L,ZEPPA G,GIOVANNOZZI A M,et al.Controlling protected designation of origin of wine by Raman spectroscopy[J].Food Chemistry,2016(5):260-267.
[5]杨倩,孙双林.基于粒子群优化算法的雷达辐射源识别[J].激光杂志,2018(2):118-121.
[6]CHEN S G,WU X J,ZHANG R F.A novel twin support vector machine for binary classification problems[J].Neural Processing Letters,2016(3):795-811.
[7]EGHBAL G M,KHADIJEH S S.On fuzzy feature selection in designing fuzzy classifiers for high-dimensional data[J].Evolving Systems,2016(4):255-265.
[8]胡洁.高维数据特征降维研究综述[J].计算机应用研究,2008(9):2601-2606.
[9]WANG G,HAICHENG E C,ZHANG Y X,et al.Multiple parameter control for ant colony optimization applied to feature selection problem[J].Neural Computing and Applications,2015(7):1693-1708.
[10]GONZ?LEZ P A,JUNG J J,CAMACHO D.ACO-based clustering for ego network analysis[J].Future Generation Computer Systems,2017(4):160-170.
[11]LIANG Y Z,CHEN S,ZHANG Z M.Baseline correction using adaptive iteratively reweighted penalized least squares[J].The Analyst,2010(5):1138-1146.
[12]RIMAI L,HEYDE M E,GILL D.Vibrational spectra of some carotenoids and related linear polyenes Raman spectroscopic study[J].Journal of the American Chemical Society,1973(14):4493-4501.
[13]MARTIN Q,MARC A,CELIN R,et al.β-carotene revisited by transient absorption and stimulated raman spectroscopy[J].ChemPhysChem,2015(18):3824-3835.
[14]里城祺,尚玉婕,孫琳,等.用高压拉曼光谱方法研究β-胡萝卜素相变[J].红外,2018(11):34-38.
[15]杨宇,翟晨,彭彦昆,等.基于拉曼光谱的胡萝卜中β-胡萝卜素的快速无损检测[J].食品安全质量检测学报,2016(10):4016-4020.
[16]吴楠楠,欧阳顺利,里佐威.高压对β-胡萝卜素分子结构及π-电子离域影响的拉曼光谱研究[J].光谱学与光谱分析,2013(9):2429-2432.
Research on spectrum classification algorithm based on ACO-SVM
Yu Xiaoyang1, Mo Jiaqing1*, Lyu Xiaoyi1, Tang Jun2, Chen Cheng1, Chen Chen1
(1.College of Information Science and Engineerin, Xinjiang University, Urumqi 830046, China;
2.Center for Physical and Chemical Analysis, Xinjiang University, Urumqi 830046, China)
Abstract:In order to achieve rapid and non-destructive identification of carrot juice brands, two types of commercially available carrot juice brands were used as research objects in this paper. A classification model for quickly determining carrot juice brands was established by collecting Raman spectra and using support vector machine algorithm. The carrot juice spectra of two brands are mainly different in the three peaks of 1 007 m-1, 1 157 cm-1, and 1 516 cm-1. Firstly, preprocessing the Raman spectra, then the ant colony optimization algorithm were used for feature selection, finally, the classification model was built with SVM. The results show that compared with direct classification by SVM, the optimal classification accuracy of the model ACO-SVM is 96.67%, which is an improvement of 2.5%; the classification time is 7.17 s, which is shortened by 163.31 s. Research shows that a classification model based on Raman spectroscopy and pattern recognition algorithms can effectively identify carrot juice brands.
Key words:Raman spectroscopy; ant colony optimization algorithm; carrot juice; feature selection; support vector machine
