基于深度学习的个性化聊天机器人研究
2020-04-30王乾铭
王乾铭,李 吟
(江苏自动化研究所,江苏 连云港 222006)
0 引 言
在学术界,深度学习被广泛应用于各种研究领域,在工业界,深度学习掀起了一场巨大的革命,传统企业也加入了深度学习的浪潮,计算机视觉、模式识别和自然语言处理的变化超出了人们的想象。近年来,计算机视觉和模式识别取得了很大的进展。但由于人与人之间的差异、文化的差异以及人们对自然语言的理解,自然语言处理还存在着一些复杂的问题。自然语言处理领域一直面临着复杂的问题。NLP[1]起源于20世纪40年代。起先的工作运用了语言学理论并利用计算机对自然语言进行理解,从而对自然语言进行处理。在自然语言领域中,目前发展比较快的一些任务有机器翻译、机器理解和问答系统。
问答系统的一般业务流程是在用户输入一个问题后,系统需要根据问题找到最合适的答案。问答系统旨在自动找到任何问题的答案。传统的研究使用浅层概率对问题和答案进行分类,如果某个句子与其中一个问题非常匹配,这个句子就是那个答案。几十年来,机器学习(支持向量机、贝叶斯分类等)成为问答系统的实现方式。
传统的seq2seq模型中的输出结果往往是在输出之前选出出现概率最大的单词,也即极大似然估计。而训练语料中,作为结果输出的单词可能在训练语料中的出现概率就很大,比如“ok”、“yeah”、“I’m sorry”这类携带信息较少而出现比较频繁的词,这样就可能会导致极差的用户体验。一个吸引人的反应生成系统应该能够输出语法上的、连贯的、多样的、有趣的反应。因此文中使用Beam Search这种启发式搜索算法,它不同于传统的贪婪算法,可以输出概率最大的若干个句子,从而增加回复的多样性和趣味性。
对于传统的seq2seq模型的问答系统还存在一个普遍的不一致性问题。由于利用深度学习训练问答机器人时,都会使用大量的语料,而一般常见的问答语料,例如美国康奈尔大学搜集的电影对话语料“Cornell Movies-Dialogs Corpus”或者大型开放字幕库“Open Subtitles”以及Ubuntu社区问答语料“Ubuntu Corpus Dialogs”,都有着覆盖面广、开放式、有噪声的特点。如图1所示,利用这些语料直接训练的问题就是同样意思但不同表达的问句会得到不同答案。这就影响了问答机器人的效果以及使用功能。而文中利用不同语料多次训练的方式能够克服这个问题,从而得到良好的效果。

Q:who are you ?A:I am the bowler.Q:What’s your name ?A:Laure.Q:Where do you live now?A:I live in Los Angeles.Q:In which country do you live now?A:England, you?
1 相关工作
问答系统可以追溯到艾伦·图灵的图灵测试。用户输入问题,然后模型给出相应的准确答案。1980年至1991年,对知识库的问答系统进行了研究,但大部分知识库相对有限,没有太多的参考价值。在1991-1999年,行业内普遍使用统计建模和机器学习来构建问答系统。而问答系统被认为是最接近人工智能的产品。10年后,Siri的出现对问答系统来说具有跨时代的意义。如今,随着数据的快速发展,传统的搜索系统如谷歌和百度,它们的算法已经不能满足人们的要求。因此,他们试图选择问答系统作为一种新的方式来完成客户的需求。
对于问答系统,学术界的研究主要有三种类型:
(1)统计句子字数的方法[2]。根据问题统计频率的接近性,得到与问题相对接近的答案的频率。但是仅仅使用统计知识并不能很好地理解客户。比如知识检索图书馆系统。
(2)机器学习[3-4]。他们用概率和统计的方法构建了问答系统。就像SVM,k均值算法。这些机器学习算法利用数据样本的特征值,将这些特征组合成矩阵作为模型的输入。
(3)深度学习[5-7]。深度学习技术可以有效地减少数据集的创建和预处理时间。此外,它还可以减少人为因素造成的误差。最后,它显示了比以前更好的结果。特别是在大数据集中,深度学习比其他方法更有效。而且它不需要手动提取特性,所以实现起来很简单。深度学习算法在自然语言领域的第一个应用是CNN。在CNN的汇聚效应下,有效地减少了数据的浪费,准确地获得了相应的参数数据。
利用深度学习技术使自然语言处理领域的问答系统得到了飞速发展。使用RNN技术的聊天机器人模型可以不需要预定义一个知识库,它可以直接生成答案[8-12]。这种方法的思路来自于自然语言领域中的机器翻译技术。Ritter等[8]使用了大规模微博聊天数据集进行训练,并将问题当作翻译中的源语言,答案当作翻译后的目标语言,从而将机器翻译的技术运用到了问答上。Hinton等[9]提出了一种自动编码器,Cho等[10]设计了一种新的对RNN进行改进后的GRU网络。Shang等[11]在此基础上同样使用大量的微博对话数据集训练出了一个基于Sequence-to-Sequence框架的RNN网络。谷歌提出的神经会话模型[12],利用了4种不同的数据集对Seq2Seq模型进行训练。文中正是在这个模型的基础上进行改进。
2 模型构建
文中模型是在Seq2Seq架构的基础上进行改进的。Seq2Seq是一种典型的基于编解码器的体系结构。该架构最初出现在机器翻译领域,由Cho等人在2014年EMNLP会议[10]上提出。经过Liu等人的升华,出现了Seq2Seq[13-14]模型。Seq2Seq主要由编码器、解码器和状态向量组成。Seq2Seq的基本架构如图2所示。
编码器:编码器的作用是转换输入变长序列成定长状态向量,状态向量包含有关输入序列的信息。
状态向量:状态向量是由编码器的隐藏层向量决定的,它将输入序列的信息从编码器发送到解码器。
解码器:解码器通过对状态向量和前一时刻解码器的输出向量进行解码,从而能够生成可变长度的序列。
编码-解码器体系结构在一定程度上简化了数据集,将数据集转换为固定长度向量通过编码器表示,且向量作为数据集引入网络进行训练。该解码器对算法的输出进行解码,解码的思想是用概率论的方法输出不确定长度的答案。这样的体系结构提高了系统的效率和精度,使其特别适用于自然语言处理任务。

图2 Seq2Seq基本结构
文中使用LSTM(long short term memory)[15-17]结构作为Seq2Seq模型中提取句子信息的单元结构。LSTM是一种循环神经网络模型。循环神经网络利用前一个节点的反馈作为输入,利用递归思想迭代映射输入和参数,计算输出和损失,然后进行循环计算形成动态网络。
LSTM网络是RNN的一种变体,是一种更实用、更极端的变体。LSTM网络是一种能够在自循环下产生长时间连续流梯度的结构。LSTM对消失梯度和非自然梯度下降具有良好的适应性。

图3 LSTM Cell结构
首先,它选择单元格来代替门的描述。然后,每个细胞之间相互连接,而不是直接利用一般神经网络的隐藏单元。由图3可知,输入门的数据和输入数据要进行计算,遗忘门从状态量中修正向量,并且它也加入了自循环。在自循环的同时,状态返回向量到输入门、遗忘门和输出门。每个门都根据状态给出的值进行调整。最后输出门和状态影响输出。激活函数选择Sigmod函数。上述过程的公式如下:
forgetti=σ(bfi+∑jUfi,jxtj∑jWfi,jht-1j)
(1)
其中,t是当前的epoch值,xt是输入向量,ht是输出的最终结果,bf,Uf,Wf是偏置参数,输入权重矩阵和向量矩阵。遗忘门被用来表示循环权向量的状态量。它的权重随着状态有一定的更新。
自循环权矩阵的更新公式如下:
Selfloopti=fotgettiSelfloopt-1i+inputgtiσ(bgi+∑jUi,jxtj∑iWi,jht-1j)
(2)
输入门的更新公式如下:
inpotgti=σ(bgi+∑jUgi,jxtj∑jWgi,jht-1j)
(3)
同时需要给输出一些限制,最后选择了tanh函数作为激发函数:
hti=tanh(Sti)outgateti
(4)
outgateti=σ(boi+∑jUoi,jxtj∑jWoi,jht-1j)
(5)
总之,LSTM可以解决长依赖的问题,可以记住并学习更多的知识。而多层的LSTM结构往往比单层结构的效果更好,因此文中采用了4层的LSTM结构。
Seq2Seq模型中用一个固定长度的向量编码了所有输入序列的语义信息,限制了模型性能的提高,注意力机制(attention mechanism)则允许模型自动搜索源输入序列中与目标序列词汇相关的部分信息,注意力机制可以使得输出的结果能够关注不同的输入。在没有注意力机制之前,当输入序列的句子比较长,原始的Seq2Seq模型只用一个中间语义向量来表示所有的输入序列的语义,这就会导致丢失很多输入序列的细节信息。注意力机制的结构如下:
在编码器-解码器结构中,最后解码器的输出层根据输入序列X预测单词的概率是:
P(yi|y1,…,yi-1,x)=g(yi-1,si,ci)
(6)
其中,si是RNN在时刻i的隐层状态,si的计算公式为:
si=f(si-1,yi-1,cj)
(7)
对于输入序列的状态hi,此处引入不同的权重:
(8)
权重的计算公式是:
(9)
其中,ei,j是由输入序列的状态决定的,计算公式如下:
ei,j=VTtanh(W1hj+W2si-1)
(10)
文中的Seq2Seq模型是在传统的Seq2Seq模型的基础上进行了改进,采用4层的LSTM结构[18]并且增加了注意力机制,如图4所示。使用多层的LSTM结构能增加整体的参数量,这使得编码器能够更加精准地提取输入序列的语义信息。从图中看,其中最主要的改进就是在Seq2Seq模型的Decoder过程中每个输出都可以得到一个结合输入状态的权重。这样输出的单词会更准确,或者在含义上能够更符合问句。

图4 改进后的Seq2Seq模型的结构
传统的Seq2Seq模型在解码过程中采用的是Greedy Search,Greedy Search本质上是一种贪心算法,在解码过程中每一个单词的输出都选择了概率最大的值,然后将这个值作为下一个时刻的输入。最终得到的结果经常会出现重复的安全回复,因为在训练集中例如“I don’t know”等等出现的次数比较多。Beam Search算法则是在解码过程中首先输出概率最大的前K个单词,然后再将这K个单词分别作为输入计算它们下一时刻的输出,最终能得到K个结果。所以系统的回复就能够变得更多样化。
3 系统的设计与实现
3.1 数据集
文中使用的数据集是康奈尔大学搜集的电影对话语料“Cornell Movies-Dialogs Corpus”,该数据集共包含10 292对电影人物之间的220 579次会话交流,涉及617部电影中的9 035个角色,总共304 713条话语。所以将其中的200 579条数据用于训练,其他的20 000条数据用于测试。
文中采用的一个数据集就是生活大爆炸的台词对话语料。为了给问答机器人赋予一个角色,使其有一定的个性化,选取了Sheldon与其他人的对话,具体就是将原来的数据集进行过滤,最终只保留Sheldon回答其他人的对话,具体信息如图5所示。该数据集共包含了50 685条对话。其中45 685条数据用于训练,5 000条数据用于测试。

Penny: Well imagine how I’m feeling.Sheldon: Hungry? Tired? I’m sorry this really isn’t my strong suit.Leonard: You told her I lied, why would you tell her I lied?Sheldon: To help you.
3.2 数据处理与模型实现
文中的代码实验利用了谷歌的Tensorflow框架,第一步先分析两种数据集,通过对文件进行处理生成.pkl格式的数据集,然后根据Tensorflow框架中的Seq2Seq框架去定义网络的输入值。
(1)编码器的输入:第一个角色说的句子A,并且设定了句子A的最大长度为10个单词。
(2)解码器的输入:第二个角色回复的句子B,因为前后分别加上了go开始符和end结束符,最大长度为12。
(3)解码器的目标输入:解码器输入的目标输出,与解码器的输入一样但只有end标识符号,可以理解为解码器的输入在时序上的结果,比如说完这个词后的下个词的结果。
(4)解码器的权重输入:用来标记target中的非padding的位置,即实际句子的长度,因为不是所有的句子的长度都一样,在实际输入的过程中,各个句子的长度都会被用统一的标识符来填充(padding)至最大长度,weight用来标记实际词汇的位置,代表这个位置将会有梯度值回传。
最终计算Softmax Loss,Softmax Loss是一种交叉熵损失函数,它的具体形式是:
E(t,y)=-∑itilogyi
(11)
(12)
3.3 模型训练及结果分析
文中的训练及测试在一台GPU服务器上完成。GPU服务器的配置见表1。

表1 GPU服务器配置
训练时采用基于Adam算法的随机梯度下降算法,学习率是0.002,每个batch包含256个问答对。另外利用了Dropout技术来避免出现可能的过拟合问题,Dropout的比率设为0.1。
模型的训练分为两个阶段。第一个阶段将两个数据集同时进行训练,一共训练90个Epoch,这一阶段的训练是为了使系统覆盖的知识面更广。第二阶段就是只用Sheldon数据集进行训练学习,一共训练30个Epoch。
文中最终训练了两个模型,一个是只利用了传统的Seq2Seq结构,一个利用了Seq2Seq结构加上注意力机制。
实验过程记录的损失函数曲线如图6所示。
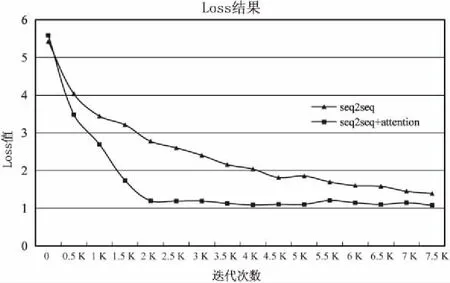
图6 两种模型的loss曲线对比
结果显示:增加了attention机制的模型loss值比原模型下降的快,这有助于模型能够快速收敛到稳定值,并且最终的loss值也比原模型要低。
为了更精确地测试两模型的区别,文中引入了两个自动评估指标:BLEUs[19]、Distinct-n。
BLEUs指标是从机器翻译中的评估指标引申过来的,它是通过判断回复句子和参考回复句子的词汇重叠度来表示回复的质量。
针对对话系统中万能回复的问题,通过计算生成回复中1元词和2元词的比例来衡量回复的多样性。具体来说,Distinct-1和Distinct-2分别是不同的unigrams和bigrams的数量除以生成的单词总数。
评估结果如表2所示。
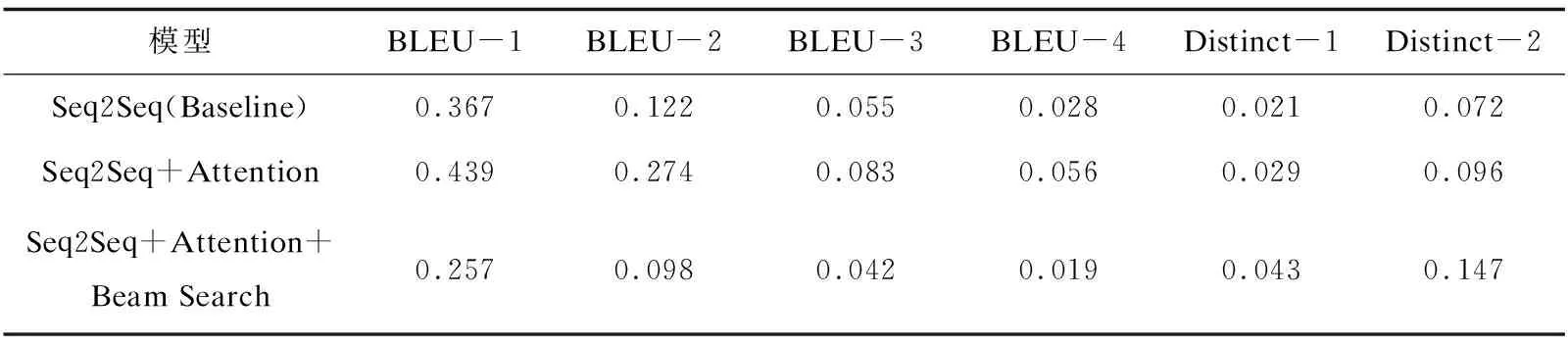
表2 三种评估指标结果
从实验结果可以看出:加入了注意力机制后,三个指标较原来的模型都有提高。当在测试时加入了Beam Search算法时,回复的多样性有了明显的提高。但是BLEU指标与原来的相比有所下降,原因是BLEU指标只专注于句子之间词汇的重复率,当增加了回复的多样性之后,回复的句子就会常有相同意思但不同的表达,这就会减小回复句子与目标句重复单词的概率,因此BLEU指标会有所下降。下面通过输入一些问句,将它与原有模型进行对比,去测试系统的一致性以及是否具有角色的个性。
表3是测试了若干组问句抽出的几个结果。

表3 两种模型测试问句结果

续表3
从结果可以看出,新模型的回复有了一定的一致性,相比于传统模型,回复质量有了一定的提高,回复的语句也比原来更流畅,效果更好。
4 结束语
通过对Seq2Seq模型进行了改进,针对一般问答机器人的一致性和多样性的问题进行改进,训练出了一个个性化的问答机器人,和原有模型相比提高了一定的回复质量,并且在BLEUs和Distinct-n指标上做了相应的测试,也都获得了不错的结果。对于未来的工作,准备将问答机器人和知识库相结合,使它在遇到不知道的问题时能够从本地知识库搜索,或者从网络上利用搜索引擎进行查找,从而进一步增强问答机器人的作用,提高其回复质量。
