人工智能中面向人类的行为分析
2020-04-29石恒麟赵国英
石恒麟 赵国英
摘要:随着海量训练数据的获得、深度学习技术的进步和相关知识的积累,人工智能在近十年里取得了举世瞩目的进步。在接下来的几年里,人们将迫切地需要以人为中心的人工智能应用。该文希望通过对行为识别相关研究的介绍,让读者了解在开发面向理解人类的人工智能应用上所取得的进步。首先,从行为检测和行为识别两个子任务概述了行为分析,并讨论了该任务中的难点;其次,列举了可用于行为分析的数据模态以及当前被广泛使用的数据库;然后,介绍了当前用于行为识别研究的主要工具,如卷积神经网络和循环神经网络;最后,总结了近十年典型的行为识别方法,包括深度学习出现之前的传统方法和深度学习方法。
关键词:人工智能;机器学习;神经网络;行为分析;行为识别;行为检测
中图分类号:TP391.41
DOI:10.16152/j.cnki.xdxbzr.2020-03-003
Human centered action analysis in artificial intelligence
SHI HenglinZHAO Guoying1,2
Abstract: With the deluge of available data, the development of deep learning technology, and the accumulation of relevant knowledge, artificial intelligence has achieved outstanding progress. In the following years, people will eagerly require the application of human oriented artificial intelligence. This paper is to explain recent technology advances on developing human centered artificial intelligence applications by introducing human action analysis related research. Firstly, the action analysis is based on two sub-tasks: action detection and action recognition, and the research challenges of them is introduced. Moreover, the modalities used in action analysis research as well as currently popular datasets in this area is introduced. Furthermore, related deep learning tools for conducting action analysis research is introduced. Lastly, we illustrate some important action analysis methods in the recent decade, which includes some classical approaches and modern deep learning approaches.
Key words: artificial intelligence; machine learning; neural network; action analysis; action recognition; action detection
在近十年里,人工智能在工业和学术界都取得了爆炸性的发展,人工智能技术已经被广泛应用到人们生活中的各个角落,如公共安全监控、汽车驾驶辅助、个人智能助手等。当前人工智能相关研究主要集中在语音信号分析、自然语言处理和计算机视觉等领域,而人工智能在这些方面的进步主要可以归功于以下3个方面:海量训练数据的获得、深度学习和GPU计算技术的进步及相关知识的积累。
首先,数据对科学研究的重要性毋庸置疑,设计有效的算法离不开有效的数据对实验提供支持。我们正处在数据红利的时代,在近十年中,学术界和工业界都越来越感受到数据的重要性,再加上一系列众包(crowd-sourcing)工具为数据标注提供方便,各个研究领域的数据如雨后春笋般涌现,而且体量都愈发庞大,如语音识别领域的AudioSet[1],自然语言处理领域中多种人工标注的机器翻译数据,以及机器视觉里目标识别任务使用的ImageNet[2]。然而,现在的数据还仍然无法满足人们需求,随着相关研究的不断深入,人们研究的问题都越来越复杂,这使得人们对数据的需求也更加细化。所以,在接下来的十到二十年里,数据仍然是人工智能领域的核心问题之一。
其次,GPU计算技术使得利用海量数据训练大型神经网络模型成为可能。深度神经网络参数数量巨大,常常超过十万级别。训练这样一个庞大的模型,往往需要依赖大量的数据并使用较小的学习率进行迭代,这使得网络训练十分耗时。然而,GPU加速技术的出现大大加快了计算机运算速度,从而极大地缩短了模型的训练时间。这使得研究人员可以减少在工程实现上所花费的精力,更专注于研究问题本身。
最后,相关知识的积累不仅帮助了人工智能的研究,还促进了人工智能技术和应用的传播。在以前,训练深度神经网络存在诸多困难,如梯度消失和梯度爆炸、参数过多导致的过拟合,以及数据分布差异导致的难以收敛等。随着近些年的积累,研究人员提出了一系列深度学习模型的训练技巧,如Dropout[3]、批归一化[4]以及梯度剪裁等方法,降低了神经网络的训练难度,使得深度学习模型在各个应用领域大放异彩。另外,一系列软件库如CUDA,OpenCL的出现使得GPU加速技術可以被部署在家用显卡中,同时再加上各种深度学习软件框架的层出不穷,如Caffe[5],Tensorflow和Pytorch等工具简化了深度模型的实现,使得大量爱好者可以进行人工智能研究,大大帮助了人工智能应用的推广,促进了其蓬勃发展。
然而,伴随着人工智能技术的进步,人们也开始思考我们对人工智能的期待和需求是什么。本文认为,为了让人工智能更好地服务于人类,那么它的首要需求是“理解人类”:理解人的情感和行为。所以,我们认为以理解人类为中心的人工智能技术将是未来的研究方向。不同于语音信号分析和自然语言处理,他们的核心研究问题是理解人类,计算机视觉任务则更加宽泛。在当前的计算机视觉研究里,面向理解人类的研究主要集中在人脸分析和行为分析研究中。作为一个新兴起的研究热点,本文将对行为分析的相关研究进行介绍。
1 研究问题和难点
1.1 行为检测
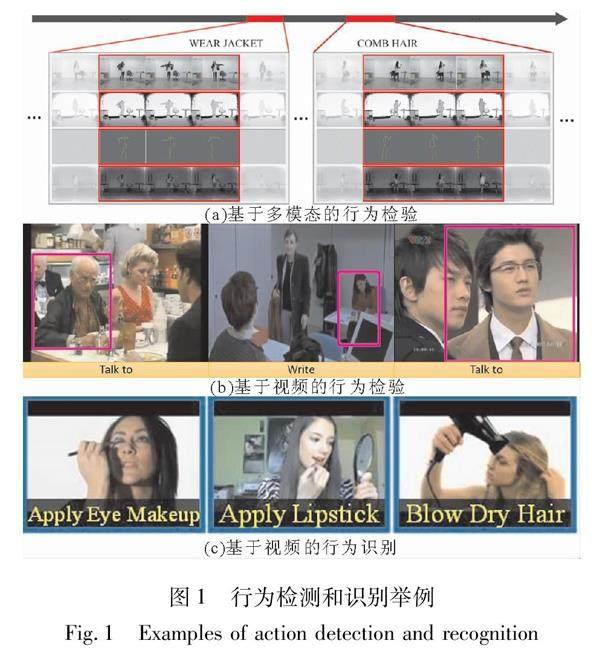
行为检测任务要求算法能够从时间序列中对行为示例的起始和結束时间进行定位。 行为检测所面对的场景往往比较复杂。 一般来说,在给定的时间序列中可能存在多个行为, 也可能不存在行为。 同时, 不同的行为可以在时间上重叠, 也可以在空间上重叠。 因此, 在现阶段研究中, 行为检测任务可以被分为两类, 一类是时间上的行为检测, 如图1(a)所示, 该样本采集于PKUMMD数据库[7]; 另一类则是最近新兴起的时间和空间上的行为检测。 算法不仅需要在时间上检测行为的起始和结束时间, 还要能够对行为的空间位置进行定位, 如图1(b)所示, 该样本采集于AVA数据库[8]。
1.2 行为识别
在行为检测的基础上,行为识别指的是对包含了一个完整人类行为或者动作的时间序列(如视频)进行识别分类,如图1(c)所示,该样本采集于UCF-101数据库[6]。通常情况下,假设检测出的一个时间序列包含且仅包含一个动作,时间序列的第一帧是动作的开始,最后一帧是动作的结束。在此基础上又衍生出多视角行为识别,在该任务下,对于任意一个行为示例都有录制于多个视角的行为数据(通常情况下不同视角的数据是同步的),该任务要求研究人员基于其中的一个或多个视角的数据进行行为识别。
1.3 问题难点
当前行为分析的主要难点在于如何有效地从动态变化的数据中学习到空间信息和时序信息。
1)空间信息学习:不同的机器视觉任务侧重于数据中的不同信息,如何从数据空间中提取有效的特征对于任务至关重要。空间信息学习的困难主要在以下几个方面:首先,行为分析任务对色彩信息不敏感,甚至色彩信息会对算法产生干扰,使得算法关注错误的区域。其次,行为分析数据往往具有动态的背景,在通常情况下,动作分析大多都以视频作为数据对象,然而大量的动作都发生在动态的场景中,例如体育运动动作,所以,这些样本中的背景都是在动态变化的,如何让方法关注发生动作的主体而不是变化的背景对于行为识别方法的效果至关重要。再次,行为分析样本中行为主体的位置并不是一成不变的,有效的行为识别方法要能一直捕捉到行为主体。最后是样本主体的多样性,行为主体在空间上的差异(如体态和体型)给行为分析任务增加了困难。
2)时序信息学习:在行为分析任务上,对时间序列进行建模、提取时序特征比空间特征提取更加重要。然而,时序特征的提取却要比空间特征提取更加困难。首先,时序特征的提取一般是包含了空间特征提取的,在进行时间序列建模之前,要先获取建模目标,所以,提取时序特征将会遇到和提取空间特征一样的困难。其次,行为时间序列的变化多样性阻碍了时序特征提取。举例来说,动作的执行并不是均匀的,即使是同一个人在执行不同的动作时,往往会有不同的变化速率和不同的完成度,因此,可以想象对不同主体的行为时间序列进行建模的难度。另外,行为数据中的信息冗余度高,相邻的帧提供的信息大部分是相同,而变化相对较少,然而这些变化的信息对行为分析任务至关重要,因此,如何构建一个有效的方法对关键信息进行提取是时序信息学习的关键任务。
2 研究数据
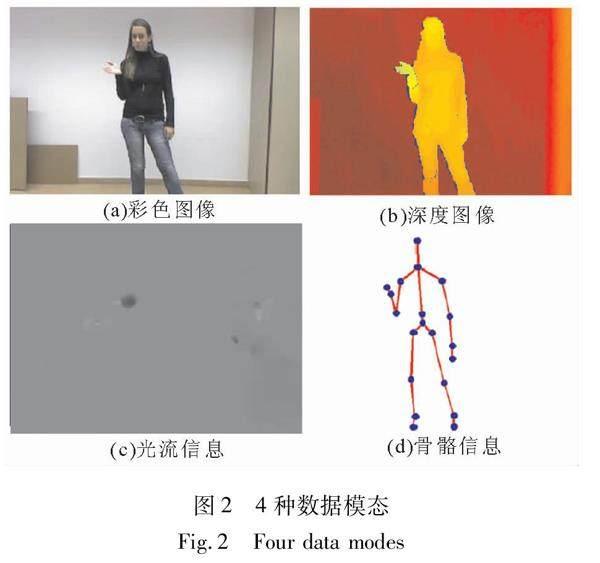
在人工智能任务里,构建智能系统与人工标注的数据是密不可分的。近年来我们所使用的主要数据模态分别是视频、光流、深度图像和骨骼坐标数据,其中,光流可以被认为是基于视频数据的衍生。而从数据的采集条件来看,当前数据主要有实验室条件下和in-the-wild条件下采集的两种(带有深度图像的数据库基本都是在实验室条件下采集的)。行为分析中被广泛应用的4种模态如图2所示。图2(a),(b),(d)3种模态实例来自Chalearn Looking At People(LAP)2014数据库[9],图2(c)来自于UCF-101数据库[6]。
2.1 图像/视频
在行为分析研究的发展中,视频一直是最被广泛使用的数据模态。相比于其他模态,视频数据的优势是采集成本低,需求设备简单,相关知识储备丰富等。深度图像和骨骼坐标的采集都需要实验室环境和特殊设备的支持,而视频采集则没有太多的要求。同时,互联网上也有丰富的来自于自然场景中的数据资源。所以,视频数据被认为是开展in-the-wild条件下行为分析最便利的数据模态。
2.2 光流
光流可以被认为是视频数据的一种衍生数据,因为光流可以基于视频数据计算获得。光流信息刻画的是图片上每一个像素点的变化趋势,这使得光流信息长于描述动态目标。因此,对于需要对目标的变化过程进行建模而不关心目标色彩信息的行为分析任务,光流信息具有先天的优势。在过去十年里,光流一直是行为分析任务的主要数据模态。然而,光流数据的缺点是它的计算复杂耗时,这制约了它在实际场景中的应用。当前提取光流的方法主要有两类,一类是传统方法,如Lucas-Kanade算法[10]和Brox算法[11];另一类是基于深度学习的方法,如FlowNet[12]和FlowNet2[13]。
2.3 深度图像
深度图像刻画的是场景内每一个像素点到深度摄像机的距离。通常情况下,深度摄像机要求目标到摄像机的距离在0.5 m到4.5 m之间。深度图像的优势是它专注于刻画与目标的距离,而不记录任何色彩信息,这使目标轮廓的刻画变得容易,与行为分析任务十分契合。另外,深度图像的采集条件比较简单且对光照条件不敏感。相比于光流信息,深度图像的优势是获取速度快。当前的深度摄像机成本并不高,一些商用手机上都已经配备了深度摄像头。然而,深度图像的一个明显缺点是采集的样本中噪音相对比较多。
2.4 骨骼坐标
骨骼坐标信息指的是人体的关节点在空间上的坐标,是这4类模态里最高层次的模态,因为它包含了人体结构的语义信息。骨骼信息的获取让我们在行为分析研究中能够“抛开现象看本质”。基于人体关键点,可以对骨骼信息进行建模,有效地提取空间特征,同时排除背景和体型等其他无关因素的干扰。早期的骨骼信息采集都是基于Mocap系统,成本高昂。随着基于深度图像的人体关键点实时检测技术的成熟[14],研究人员不再对骨骼信息望而却步。然而,骨骼数据也有两个显著的缺陷:一是当前算法的鲁棒性不足,检测出的关键点存在噪声;其次,类似方法在对手指等细节部位的检测结果并不理想。
2.5 相关数据库
在当前流行的行为分析数据库中,用于行为识别任务的有单模态的UCF-101[6],HMDB-51[15]和包含了视频、深度图像和骨骼的MSR Action 3D[16],NTU RGB+D[17]。用于行为检测任务的有大型的单模态视频数据库AVA[8]和Chardes[18]等,以及多模态的PKU-MMD[7]和ChaLearn LAP 2014[9]等。表1举例了一些具有代表性的数据集,除了以上提到的数据库,还包括一个多角度行为数据库UWA3D Multiview Activity II[19]。
3 当前研究工具
在近五年里,深度学习方法已经在行为分析研究占据了主导地位。基于深度学习的行为识别方法中所使用的基本模型包括多层感知机、卷积神经网络、循环神经网络和近些年刚兴起的图卷积网络。
3.1 多层感知机
多层感知机是最早出现的神经网络的类型,在如今的深度学习框架中也被称为全连接层,其典型的代表是自编码器(autoencoder)。简单来说,多层感知机实现的就是输入和网络权重的内积操作。目前,多层感知机几乎被用于所有的深度模型中,研究人员常将多层感知机置于深度模型中的深层用于高层特征提取。此外,常见的分类任务和循环神经网络的内部操作都需要依赖多层感知实现。
3.2 卷积神经网络
卷积神经网络是机器视觉任务中最为流行的深度学习工具之一,已经被广泛应用于物体识别、目标检测和行为分析等任务中。目前常用的卷积神经网络有常被用于语音信号处理的一维卷积模型、用于图片分析的二维卷积模型和用于视频分析的三维卷积模型。以二维神经网络为例,它使用一组滤波器对输入数据以滑窗的方式进行滤波,整个过程正如将输入数据和滤波器权重做卷积操作,故得名卷积神经网络。卷积神经网络的实现特点使得它只能处理规则的网格结构的数据,这一点天然与机器视觉契合。再加上每一个滤波器使用的参数较少,通常在每层可以使用数百个滤波器对图像进行滤波,这使得它已经成为机器视觉任务中主要的空间特征提取手段。图3描述了二维卷积网络的运算过程。
3.3 图卷积网络
图卷积网络[20]是近年来新兴起的一种卷积网络的变种。前文已经讨论过常规的卷积神经网络要求输入数据必须具有网格状结构。然而,在现实应用场景中并不是所有的数据都具有网状结构,如知识图谱中常见的关系数据和行为分析中的骨骼数据。为了利用卷积神经网络的能力并将其扩展到其他领域的应用中,研究人员提出了图卷积模型。目前,图卷积网络已经被应用在基于骨骼数据的行为识别任务中[21]。
3.4 循环神经网络
以上提到的3种模型的局限是它们并不适合单独被用于时间序列分析。即使要进行时间序列分析,也需要强行统一输入数据的维度,比如将不同帧数的视频采样成相同帧数,因此,人们需要一种动态的时序建模工具。基于这种需求,循环神经网络出现了。首先,以时刻t为例,循环神经网络通过隐藏层对之前从1到t-1时刻的数据中学习到的内容进行记忆;其次,在产生第t时刻的输出时,将第t时刻的输入和t-1时刻的隐藏层作为输入(也有实现将t-1时刻的输出作为输入)。这样,循环神经网络的输出是基于当前时刻的数据和从历史数据中学习到的信息来计算的。在对每一时刻的数据进行处理时,循环神经网络的参数是共享的,可以自适应各种长度的时间序列。另外,循环神经网络还有多种输出方式适合不同类型的任务,如图4所示。
1)长短时记忆模型:目前,研究人员已经开发出了多种循环神经网络的变种,其中最流行的是长短时记忆模型(long short-term memory, LSTM)[22],如图5所示,其中,i,f,o代表3个门控制器,分别是输入门、遗忘门和输出门。该模型將当前数据和上一时刻的输出作为输入,同时引入多个门控制器和内部隐变量来处理并存储从前面数据学习的信息。该方法对于基于时间序列的行为分析十分有效。
2)双向长短时记忆模型(bidirectional LSTM):双向长短时记忆模型是长短时记忆模型的一种衍生[23]。通过两组长短时记忆模型,一组顺序地对输入数据进行处理,另一组则倒叙地对数据进行处理,然后将两组输入进行融合,实现双向长短时记忆模型。我们可以由先发生的事情预测后发生的事情,也可以从后发生事情推理之前发生的事情,类似地,时间序列内不同时刻的样本间的关系也是如此。所以,这种双向模型被认为具有更强的时序建模能力。
3)卷积长短时记忆模型(convolutional LSTM):在常规的长短时记忆模型等循环神经网络里,内部的门控制器等模块都是由多层感知机通过内积操作实现的,所以它无法直接地处理二维数据。假如要将该模型引入基于视频的行为分析任务中,通常需要先将二维数据转化为一维数据,再输入循环神经网络中。然而,这种做法的危害是会损害数据中的结构信息,就像将一张图片转换成为一个一维向量会损失该图片的空间信息。因此,需要设计一种可以不损坏输入空间信息的循环神经网络。基于这种需求,将常规长短时记忆模型中的多层感知机都用卷积模型替换,提出了卷积长短时记忆模型[24]。该模型的输入和输出都是二维图像,为行为分析任务提供了新的有力工具。
4 行为分析相关方法
4.1 传统行为分析方法
在深度学习方法兴起之前,基于视频的行为识别方法主要是密集轨迹法(dense trajectory, DT)[25]和后来改进的密集轨迹法(improved dense trajectory, iDT)[26]。密集轨迹法基于光流,对视频中的像素点进行追踪并采样,从而捕捉目标的一系列重要的像素点在视频中的运动轨迹,最终获得目标的运动信息。iDT对DT进行了改进,在行为识别任务中,相机的位置并不是一直静止不动的。移动的相机会使与目标行为无关的像素点产生运动的轨迹,如背景等,而这些轨迹对于行为识别并没有贡献。因此,iDT通过估计相机的移动,能够更有效地对目标行为的像素轨迹进行采集,可以显著提高行为识别效果。
对于传统的骨骼行为特征,Yang和Tian提出了一种有效并易于计算的轻量骨骼行为特征EigenJoint[27]。该特征能够同时捕捉数据中的空间和时序特征:在空间上,计算不同关键点之间的差,从而获得大量的表示空间信息的向量;在时间上,计算相邻两帧任意两点之间的差作为时序特征。对于另一个典型的骨骼特征,Vemulapalli等将刚体运动理论引入行为分析,提出了基于李群的骨骼行为特征[28]。该特征将人体任意两个骨骼间的平移和旋转信息用一个特殊欧几里得群(special Euclidean group)SE3表示,因此,在每一帧中,所有骨骼间的旋转和平移信息可以被嵌入在数个SE3组成的积空间中,并且被表示为该空间中的一个点。
4.2 基于卷积神经网络
作为初期深度学习在行为识别任务上的尝试,三维卷积[29]获得了大量学者的关注。该方法开创了三维卷积网络对基于视频的行为识别的先河。然而,作为初期的尝试,该方法却并未使用较为深层的网络。在此基础上,Tran等人结合了三维卷积模型和深度网络架构提出了C3D模型用于行为识别[30]。该模型将VGG模型[31]中的二维卷积层和二维池化层分别用三维卷积层和三维池化层替换,率先将深度模型引入行为分析任务,并且取得了很好的效果提升。后来,Du Tran等人又对C3D架构进行改进,将VGG架构替换为ResNet-18[32],从而降低了网络训练的难度。虽然C3D的出现极大地提高了行为识别的准确率,但是它的缺点也显而易见:模型过于庞大、参数太多、不易在大型数据库上进行训练。
为了提高网络的效率,研究者提出了伪3D卷积模型(pseudo-3D, P3D)[33],该模型通过一个二维卷积和一个一维卷积来模拟三维卷积模型,从而降低了网络每层的参数数量,使得网络可以使用更多的层数和更大的批训练大小。实验证明,该模型能用少于C3D的参数训练出高达119层的超深度网络。另外,Carreira和Zisserman提出了inception 3D(i3D)模型[18],一种宽度网络模块,使用多个尺度的卷积模块用于特征提取,实验表明,该模型对于视频行为特征的提取十分有效。
以上介绍了基于视频的深度学习行为识别方法。除此之外,由于光流信息在传统行为识别的成功,研究人员同样将其引入了深度模型中。Simonyan等人首先提出了基于视频和光流的双流网络(two-stream network)[34]。双流模型使用了双路vgg-16网络,一路是以单帧的彩色图片作为输入,另一路以多张光流组成的多通道光流组作为输入,两路网络独立地进行行为分类,最终的分类结果在决策端进行融合。Feichtenhofer等讨论了更多的融合方式[35],不同于前面所讲的决策端融合,该文则专注于在特征端进行融合。除了特征端的空间融合之外,本文还讨论了时间融合,采用的方法主要是三维池化和三维卷积。以上两种双流模型的每个流都是独立处理的,为了达到更好的训练效果,在此基础上,提出了新一代的交互式双流网络——时空乘子网络 [36]。该模型采用了残差神经网络的架构为基础,让RGB流和光流在不同的层间进行交互,从而使两路子网络的学习相互辅助相互制约,以达到更好的训练效果。
虽然光流网络已经达到了很好的效果,但局限是需要预先计算光流。光流计算十分耗时,这使得双流模型难以在实际应用中使用,或者在实际应用中难以获得理想的帧率。Zhang等人提出了使用运动向量(motion vector)替代双流网络中的光流数据,并且获得相当于双流网络的效果[37]。相比于光流数据,运动向量十分容易计算,这使得基于彩色和运动向量的双流网络可以达到上百帧的超高识别速率。另外,最近有学者新提出了一种仅仅基于视频信息的快慢网络[38],快慢网络建议使用双流网络分别处理不同帧率的的视频信息。一路快速网络通过处理高帧率的视频信息获得动作的时序特征,另一路慢速网络处理低帧率的视频信息以获得空间信息。实验证明该模型可以有效提取视频中的时序特征。
卷积网络的局限性是不同输出之间的上下文关系较弱,限制了其在行为检测中的应用。为了在行为检测中使用卷积神经网络,往往需要辅以一个时序模型,比如,Wu等人将卷积神经网络和隐马尔可夫模型相结合进行行为检测[39]。在该模型中,首先,由卷积网络进行帧级别的行为识别,然后,隐马尔可夫模型在所有帧的识别结果的基础上进行行为检测。但是,该模型的缺點是它并不是一个端到端模型,因为它的卷积网络和隐马尔可夫模型无法同时训练。Xu等人在区域卷积网络(regional convolutional neural network, RCNN)的基础上提出了端到端的行为检测模型R-C3D[40],该模型首先在输入视频的时间维度上产生多个可能的“行为存在区域(action proposal)”,然后,网络分别对每一个区域进行特征提取并识别行为。相比于基于隐马尔可夫模型的“先识别后检测”,R-C3D则是一种“先检测后识别”的模式。
4.3 基于循环神经网络
单独使用循环神经网络进行基于视频的行为分析并不容易,因为常规的循环神经网络并不适用于提取图像级别特征。因此,对于视频级别的行为分析任务,循环神经网络往往是结合卷积神经网络一起被使用的。Donahue等人提出了长效循环卷积网络(long-term recurrent convolutional network,LRCN)用于基于视频或图片的行为分析[41]。该方法可以被用于行为识别、图片标注和视频描述生成等多种任务。其中,用于行为识别的模型是基于“多对多”结构的循环神经网络。该模型首先将视频中的每一帧图片通过一个卷积神经网络进行特征提取;然后,将提取到的特征作为时间序列送入长短时记忆模型中;最后,通过对每一时刻的输出平均求和进行行为识别。Ng等将双流网络的思想与循环神经网络进行融合,该模型将视频中的图片和光流数据分别通过两个卷积神经网络提取特征[42];然后,再将双流的结果通过两个长短时记忆模型进行帧级别的行为识别;最后,模型在决策端融合每一时刻的输出进行行为识别。
相比于基于视频的行为识别,基于骨骼数据的行为分析方法一般不需要卷积神经网络进行特征提取。因此,循环神经网络对基于骨骼数据的行为分析任务具有天然的适应性,并得到了广泛的应用。Yu等人提出了一种基于层级架构的双向长短时记忆模型用于骨骼行为识别[43],该模型将人体结构分成多个部分,每一部分分别通过一个独立的双向长短时记网络,每个网络的结果统一被输入一个全局双向长短时记忆模型进行行为识别。
此外,循环神经网络在行为检测问题上也取得了令人瞩目地成果。Huang等人将语音分析中十分流行的连接主义时间分类(connectionist temporal classification, CTC)和长短时记忆模型相结合用于行为检测并取得成功[44]。Li等人利用长短时记忆模型提出了基于骨骼地在线行为检测模型[45]。该模型主要包含一个分类模块用于帧级别的行为识别,和一个回归模块用于学习行为的起始和结束时间,同时,该模型的训练是端到端的。
4.4 其他相关的的深度模型
除了前面介绍的流行的基于卷积神经网络和循环神经网络的行为分析方法,还有其他深度学习方法,比如,深度置信网络(deep belief network, DBN)曾被用于在无监督条件下的特征提取。Wu和Shao提出了使用基于深度置信网络的自编码器提取骨骼特征,最后提取的特征通过一个隐马尔可夫模型进行行为检测[46]。
此外,近年新兴起的图卷积模型也受到了行为分析科学家的关注。Yan等人将图卷积模型引入了行为识别任务,提出了基于时空图卷积网络的骨骼行为分析方法[21]。该方法开创了基于图卷积模型的行为分析的先河,为研究人员开展行为分析提供了更多的工具。
5 结 语
行为分析是人工智能领域中的关键任务。首先,本文对行为分析任务进行了定义,详细介绍了行为检测与行为识别;其次,本文总结了行为分析任务中主要使用的数据模态,并列举了一些被广泛使用的数据集;再次,基于近些年深度学习技术的火爆,简要介绍了当前流行的深度学习工具;最后,举例介绍了近些年流行的行为分析方法。
作为人类与机器交互的最前沿,行为分析任务的成果对下一代人工智能应用的开发至关重要,尤其是以人为中心的人工智能应用。智能医疗、智能看护和自动驾驶等技术都需要行为分析作为人与计算機沟通的媒介。深度学习技术的发展加速了行为分析的进步,将来学术界和工业界一定会产生效果更加优异的行为分析方法,帮助我们开发新一代的面向理解人类的人工智能应用。
参考文献:
[1]GEMMEKE J F, ELLIS D P, FREEDMAN D, et al. Audio set: An ontology and human-labeled dataset for audio events[C]∥2017 IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans:IEEE, 2017:776-780.
[2]DENG J, DONG W, SOCHER R, et al. Imagenet: A large-scale hierarchical image database[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami:IEEE, 2009:248-255.
[3]SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1):1929-1958.
[4]IOFFE S, SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[EB/OL].2015: arXiv:1502.03167[cs.LG]. https://arxiv.org/abs/1502.03167.
[5]JIA Y, SHELHAER E, DONABUE J, et al. Caffe: Convolutional architecture for fast feature embedding[C]∥Proceedings of the 22nd ACM International Conference on Multimedia. ACM, 2014:675-678.
[6]SOOMRO K, ZAMIR A R, SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[EB/OL].2012: arXiv:1212.0402[cs.CV]. https://arxiv.org/abs/1212.0402.
[7]LIU C, HU Y, LI Y, et al. Pku-mmd: A large scale benchmark for skeleton-based human action understanding[C]∥Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities. ACM, 2017:1-8.
[8]GU C, SUN C, ROSS D A, et al. Ava: A video dataset of spatiotemporally localized atomic visual actions[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE, 2018:6047-6056.
[9]ESCALERA S, BAR X, GONZALEZ J, et al. ChaLearn looking at people challenge 2014: Dataset and results[M]∥Computer Vision-ECCV 2014 Workshops.Cham:Springer International Publishing, 2014:459-473.
[10]LUCAS B, KANADE T. An iterative image registration technique with an application to stereo vision[C]∥Proceedings of Imaging Understanding Workshop,1981:121-130.
[11]BROX T, BRUHN A, PAPENBERG N, et al. High accuracy optical flow estimation based on a theory for warping[C]∥Computer Vision-ECCV 2004. Cham: Springer International Publishing, 2004:25-36.
[12]DOSOVITSKIY A, FISCHER P, ILG E, et al. Flownet: Learning optical flow with convolutional networks[C]∥Proceedings of the IEEE International Conference on Computer Vision. Santiago:IEEE, 2015:2758-2766.
[13]ILG E, MAYER N, SAIKIA T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE, 2017:2462-2470.
[14]SHOTTON J, FITZGIBBON A, COOK M, et al. Real-time human pose recognition in parts from single depth images[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Colorado Springs:IEEE, 2011:1297-1304.
[15]KUEHEN H, JHUANG H, GARROTE E, et al. Hmdb:A large video database for human motion recognition[C]∥Proceedings of the IEEE International Conference on Computer Vision.Barcelona:IEEE, 2011:2556-2563.
[16]LI W, ZHANG Z, LIU Z. Action recognition based on a bag of 3D points[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.San Francisco:IEEE, 2010:9-14.
[17]SHAHROUDYA, LIU J, NG T T, et al. NTU RGB+D:A large scale dataset for 3d human activity analysis[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE, 2016:1010-1019.
[18]CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE, 2017:6299-6308.
[19]RAHMANI H, MAHMOOD A, HUYNH D, et al. Histogram of oriented principal components for cross-view action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(12): 2430-2443.
[20]KIPF T, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL].2016: arXiv:1609.02907[cs.LG]. https://arxiv.org/abs/1609.02907.
[21]YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[EB/OL].2018: arXiv:1801.07455[cs.CV]. https://arxiv.org/abs/1801.07455.
[22]HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8):1735-1780.
[23]GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005, 18(5/6):602-610.
[24]SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[EB/OL].2015: arXiv:1506.04214[cs.CV].https://arxiv.org/abs/1506.04214.
[25]WANG H, KLSER A, SCHMIDC, et al. Action recognition by dense trajectories[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Sydney:IEEE, 2011:3169-3176.
[26]WANG H, SCHMID C. Action recognition with improved trajectories [C]∥Proceedings of the IEEE International Conference on Computer Vision.Sydney:IEEE, 2013: 3551-3558.
[27]YANG X, TIAN Y L. Eigenjoints-based action recognition using naivebayes-nearest-neighbor[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence:IEEE, 2012:14-19.
[28]VEMULAPALLI R, ARRARE F, CHELLAPPA R. Human action recognition by representing 3D skeletons as points in a lie group[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE, 2014:588-595.
[29]JI S W, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1):221-231.
[30]TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]∥Proceedings of the IEEE International Conference on Computer Vision.Santiago:IEEE, 2015:4489-4497.
[31]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL].2014: arXiv:1409.1556[cs.CV].https://arxiv.org/abs/1409.1556.
[32]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE, 2016:770-778.
[33]QIU Z F, YAO T, MEI T. Learning spatio-temporal representation with pseudo-3D residual networks[C]∥Proceedings of the IEEE International Conference on Computer Vision.Venice:IEEE, 2017:5533-5541.
[34]SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[J].Advances in Neural Information Processing Systems. 2014:568-576.
[35]FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE, 2016:1933-1941.
[36]FEICHENHOFER C, PINZ A, WILDES R P. Spatiotemporal multiplier networks for video action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE, 2017:4768-4777.
[37]ZHANG B W, WANG L M, WANG Z, et al. Real-time action recognition with enhanced motion vector cnns[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE, 2016:2718-2726.
[38]FEICHTENHOFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]∥Proceedings of the IEEE International Conference on Computer Vision.Seoul:IEEE, 2019:6202-6211.
[39]WU D, PIGOU L, KINDERMANS P J, et al. Deep dynamic neural networks for multimodal gesture segmentation and recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(8):1583-1597.
[40]XU H J, DAS A, SAENKO K. R-C3D: Region convolutional 3D network for temporal activity detection[C]∥Proceedings of the IEEE International Conference on Computer Vision.Venice:IEEE, 2017:5783-5792.
[41]DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Boston:IEEE, 2015:2625-2634.
[42]NG JOEY H, HAUSKNECHT M, VIJAYANARASIMHAN S, et al. Beyond short snippets: Deep networks for video classification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Boston:IEEE, 2015: 4694-4702.
[43]DU Y, WANG W, WANG L. Hierarchical recurrent neural network for skeleton based action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Boston:IEEE, 2015: 1110-1118.
[44]HUANG D A, FEI-FEI L, NIEBLES J C. Connectionist temporal modeling for weakly supervised action labeling[M]∥Computer Vision-ECCV 2016.Cham:Springer International Publishing,2016:137-153.
[45]LI Y H, LAN C L, XING J L, et al. Online human action detection using joint classification-regression recurrent neural networks[M]∥Computer Vision-ECCV 2016.Cham:Springer International Publishing,2016:203-220.
[46]WU D, SHAO L. Leveraging hierarchical parametric networks for skeletal joints based action segmentation and recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE, 2014:724-731.
(編 辑 李 静)
收稿日期:2020-04-02
基金项目:国家自然科学基金资助项目(61772419);陕西省科技计划重点项目(2018ZDXM-GY-186)
作者简介:石恒麟,男,山东诸城人,从事基于机器视觉的微动作分析研究。
通信作者:赵国英,女,山东聊城人,教授,博士生导师,入选陕西省“百人计划”,从事计算机视觉、机器学习和情感智能等研究。
