基于支持向量机的城市道路降雨径流污染预测模型
2020-04-28田文翀
王 渲,田文翀
(同济大学 环境科学与工程学院,上海200092)
0 引言
城市降雨径流污染是指降雨径流水体对累积在城市路面、屋顶、绿地等不同下垫面的污染物质(如SS、原油、氮、磷、重金属、有机物质等)形成淋溶、冲刷作用,并将其裹挟的污染物通过排水系统直接排入受纳水体而造成的水体面源污染现象[1]。城市的发展极大地增加了建筑物和硬化道路的比例,改变了天然状态下雨水的产汇流规律,使得降雨时形成了更多地表径流。其结果会导致城市水体水质和生态系统受到破坏,产生包括富营养化、水环境恶化、水体黑臭等众多问题,影响城市水环境健康与水生态安全。
借助于降雨径流模型对径流污染进行预测,是控制城市降雨径流污染的主要途径之一。由于水质问题受多因素影响及其复杂性,许多生物、化学过程的反应机理尚未能通过模型进行描述。同时,水质机理模型在应用过程中通常需要大量的水文、水质参数,而这些参数既多又难于测量,这些都限制了确定性水质数学模型的适用性和准确性[2-3],机器学习直接从实测数据出发挖掘水质模型的内在规律为国内外学者提供了另一种研究思路。
在城市水质研究中:MJ Rodriguez[4]提出人工神经网络模型,从另一个角度研究了余氯在配水系统中的衰减,并与传统的一级模型进行了对比。模型是通过算法和使用一个时间延迟输入拓扑结构实现的,对两个供水系统进行的模拟表明在水温较低时一级模型显示了较好的效果,而在水温较高时模型则显示了较好的预测。杨航等[5]基于神经网络建立了复杂管网余氯水质预测模型,该方法避开复杂的管网水力计算,以实际测定参数进行训练和验证,具有较好精度。李芸[6]等针对当前非点源污染中雨水径流水质监测数据匮乏而难以评估其污染负荷的弊端,将BP神经网络模型引入评估雨水径流污染负荷问题。在湖泊水质研究中:徐红敏[7]通过建立支持向量机水质参数评价模型来预测太湖高锰酸盐月平均浓度取得了良好的效果。Recknagel[8]等系统地研究了ANN模型在水质预测中的应用,建立了三个淡水湖泊预测藻类暴发的ANN模型和一个河流预测藻类暴发的ANN模型,预测结果表明,模型可以预测不同环境条件下淡水水体中像藻类暴发这样复杂的和非线性的水环境现象。胡明星[9]等提出了基于多准则学习的模糊神经网络湖泊水质营养化评价模型。在河道水质研究中:HR.Maier[10]和GC.Dandy对澳大利亚南部Murray河上某段的水质参数矿化度进行了预测,取得了一定成效。王里奥[11]等利用因子分析法找出影响南渡河水质的主要污染指标,建立了基于BP神经网络的主要污染指标预测模型对近几年的主要污染因子进行了预测。HM Nagy等[12]建立了神经网络模型预测河流沉积负荷的浓度。但是,将机器学习方法应用于降雨径流水质污染的研究鲜有:田欢[6]基于BP神经网络构建了雨水径流污染物总量评估模型,并应用Schueler公式对评估结果进行验证。
本文考虑到降雨径流污染的非线性、多影响因素特点,通过对文献中获得的不同地域的大量实测数据进行挖掘,建立支持向量机(SVM)的城市降雨径流预测模型,对场次降雨平均浓度EMC及初期冲刷指数FF30进行预测。研究方法及预测结果能够为降雨径流污染的有效控制提供参考及数据支撑。
1 理论基础
1.1 场次降雨径流污染平均浓度(EMC)
城市降雨径流污染物浓度规律可由瞬时浓度及平均浓度EMC共同表征。其中,瞬时浓度反映污染物浓度的动态变化情况,是进一步获得场次降雨污染物浓度的极大值、极小值、平均值及其变化规律的重要指标,同时也为初期冲刷效应的判别和的计算提供基础数据,需要通过连续测量获得。
然而,由于降雨特征的随机性,路面沉积物的非均质性以及雨期污染源排放污染物的随机性,在场次降雨径流过程中污染物瞬时浓度在较大范围内变化。因此,USEPA结合NURP计划研究成果,建议以参数EMC(Event Mean Concentration)来表征径流污染强度,因为从暴雨径流对受纳水体的影响方面来看,水体对排入的地表径流的污染响应速度相对径流过程中污染物瞬时浓度变化而言要慢得多。此后,国内外研究均釆用该指标表征场次径流污染物的浓度。EMC可由式(1)计算:
(1)
式中:
M(T)——场次降雨累积污染物总量,mg;
V(T)——场次降雨累积径流总量,L;
Ct——瞬时径流污染浓度,mg/L;
Qt——瞬时径流量,L/min;
T——降雨径流事件总时间,min。
1.2 初期冲刷指数
初期冲刷效应是指在初期降雨径流过程中污染物浓度明显高于后期径流冲刷的污染物浓度[13]。由于初期冲刷效应受到城市污染物累积过程、降雨径流过程以及两者相互作用影响,在不同汇水区域,或者同一汇水区域的不同场次降雨的初期冲刷程度均不相同。降雨特征、汇水区域特征等是影响初期冲刷效应程度的主要因素。由于不同地区的气候、降雨特征等存在差异,影响道路径流污染物的因素也不相同,因此需要根据当地特点具体分析。
通常采用无量纲累积分析M(V)曲线图评价初期冲刷效应存在与否[14]。降雨径流过程中的累积污染负荷比例M与累积径流量比例V计算方法如式(2)和式(3)所示。
(2)
(3)
式中:
M(t)——t时刻累积污染物总量,mg;
Fig. 5 shows that the zinc sulfide films deposited at 100 and 200 W have the same critical angle αc= 0.28°. From Eq.(8) we can directly calculate the density electronic N(Z+
M(T)——场次降雨累积污染物总量,mg;
V(T)——场次降雨累积径流总量,L;
尤其对男孩子来讲,他们是不能同时处理多个信息的,否则就会大脑直接NG,即使你说了再多的话,他们的大脑也不会做任何信息加工,这时沟通无异于对牛弹琴。如果你发火了,说出更多的气话,他们就会闭紧嘴巴,不做任何反应。所以,第一,我们不能同时给男孩布置很多项任务;第二,我们不能用很快的语速和男孩说很多话。
Ct——瞬时径流污染浓度,mg/L;
V(t)——t时刻累积径流量,L;
Qt——瞬时径流量,L/min;
Δt——连续测定时间间隔,min;
T——降雨径流事件总时间,min。
本研究中为了量化初期冲刷效应,并为后续预测模型的建立定义预测变量,引入了初期冲刷指数的概念,定义场次降雨累积径流量比例为30%时所对应的累积污染负荷比例为FF30,即M(V)曲线上V=0.3所对应的M的值。
1.3 支持向量机
支持向量机(SVM)由Vapnik及Cortes等人在1995年率先提出[15],通过寻求结构风险最小化来实现置信范围及经验风险最小化目标,这使其能够在样本量较少的情况下获得良好的统计规律,并在处理非线性及高维模式识别问题时具有特有的优势。
支持向量机算法由对线性可分数据集进行分类的最优超平面概念发展而来,简单地说,就是运用机器学习寻找对线性或非线性数据进行分类的最优分类面,而最优分类面的确定是由少数样本点决定,即支持向量(Support Vector,SV)。在运算时,与分类超平面无关的样本点被剔除,只保留作为支持向量的样本点,从而大幅提高运算效率(图1)。
目前多数地方高校现状是班级学生数量众多,师资队伍相对缺乏,所开设的课程门类较少,高校教师疲于应付科研、职称等各种压力,导致教学上所采用的教学方法与考核方式根本无法满足当代大学生的实际需求。而一些名校的MOOC课程资源与本地高校现设课程的课程目标、教学对象、课程难度等方面都难以匹配。高校教师希望通过各种实践去尝试更加灵活而又富有挑战性的教学模式,而不是周而复始地进行课程的重复性讲授与教学。
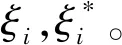
(4)
式中:
2.2.2 数据标准化
2.2.1 非数值影响因子
b——偏移量;
C——正常数,用于平衡f的平滑性和所被允许的超过ε的误差之和的作用。
2 基于支持向量机的城市道路降雨径流预测模型训练及验证
2.1 数据来源
机器统计学习需要一定规模的样本量。为了获得具有代表性、质量较高的足量样本集,本研究广泛检索研究城市降雨径流污染的国内外学位论文,从实验方法、研究区域、研究结论等多方面综合分析,获取满足SVM模型训练要求的样本数据。由于国内外对于城市降雨径流污染的实验研究多以道路作为研究对象,因此本研究预测模型亦针对道路径流建立。表1所示为本章预测模型研究数据来源。
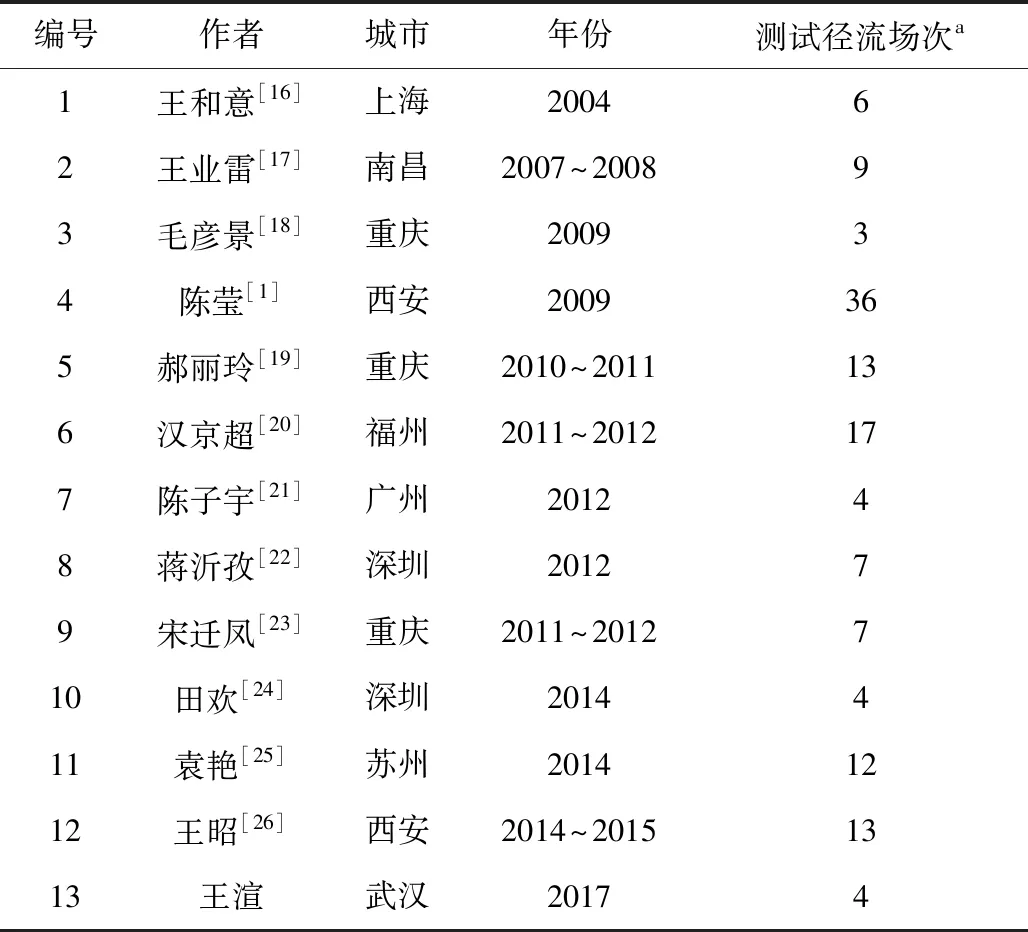
表1 道路径流污染模型数据来源
注:a.在同一场次降雨下对两处不同道路路面进行径流污染测试计作2次。
2.2 影响因子及决策变量
结合国内外对于降雨径流污染影响因素的研究成果,道路降雨径流污染主要受降雨特征、大气污染情况、交通流量及其他城市功能区等因素的影响。概括得出模型影响因子(输入值)见列表2。
预测模型的决策变量(输出量)应当能够综合反映场次降雨径流污染特征,包括径流污染程度及初期冲刷效应等特性,此外,由于COD是评价降雨径流污染程度及控制情况的重要指标,因此选取指标COD的场次降雨径流污染平均浓度EMC及初期冲刷指数FF30值作为评估模型的决策变量(输出量)。

表2 影响因子

续表
确定模型所需数据样本的输入量(影响因子)及输出量(决策变量)之后,通过从文献直接获取、检索及调研等方式,补齐所选取数据集的影响因子。由于SVM模型在预测新样本时不允许缺失值存在,因此对于无法补齐缺失信息的数据采取剔除处理。经过数据清洗得到的数据集样本量见表3。

表3 数据集样本量
w——n维权向量;
支持向量机(SVM)要求被处理的数据均为实数。表2中所示10项影响因子中,平均雨强、峰值雨强、降雨历时、雨前干期、大气降尘量、PM10、车流量等均为数值型变量,可直接进行标准化处理之后进入模型运算;而对于非数值属性雨型、路面材料及功能区,参考文献资料,作如下进一步转换。
(1)雨型:定义为类别型变量,并将其划分为峰值靠前、居中及靠后三类,分别对应编码{1,0,-1}。
平均偏差MBE反映模型预测值与实测值之间的平均误差,具有一定的参考意义。
(3)城市功能区:本研究按照数据集各研究区域人口密度、道路清扫频次及空气污染等要素进行赋权重值打分,要素权重见表4,分值范围均为0~100。打分标准为:人口密度越大、清扫频次越低、空气污染程度越差,则分值越高;其他项考虑不同实测点导致径流污染加重的相关因素。各项得分加权平均即得到“功能区”影响因素的数值。
如果患者“四部27点规律”查体后,不符合“两部2点或两部2点以上”,则不需要拍X光、CT、MRI。这样先行压痛点检查既可避免漏诊,又可免除拍X光、CT、MRI的检查,从而最大限度的避免医疗资源的浪费,这也是本诊断方法的特别优势。

表4 功能区评价要素权重
(xi,yi),i=1,2,…,n,x∈Rd——训练样本集;
表2所示影响因子及决策变量具有不同的量纲及量纲单位,其数值大小会使得模型运算时产生不同的权重影响,导致模型收敛速度降低、数据分析结果失真。在支持向量机模型中,径向基核函数RBF采用样本数据的欧式距离计算,能够避免数值较大的变量控制数值较小的变量,但是较大的数值差距会影响模型计算,降低模型收敛速度。因此,为了消除变量间的量纲影响,对数据进行Z-score标准化(Z-score Normalization)处理,使得不同变量之间具有可比性:
(5)
式中:
μ——样本均值,
为了在将来实验中更好的识别和研究第五主族原子(N、P、Sb、Bi)替位掺杂对砷烯几何结构和电子性质的影响,模拟计算了扫描隧道显微镜(STM)图像,如图5所示. 在1 V的正偏压条件下,其STM图像较容易识别,并与其晶体结构相对应. 从图5可见,4种不同的掺杂晶格的STM图像存在明显的差异,因此为实验时辨别砷烯材料中的这些杂质提供了参考.
用SAS 9.2软件进行统计分析。定量数据的组间比较采用t检验或Wilcoxon秩和检验,并描述其例数、均值、标准差等。定性数据的组间比较采用χ2检验、Fisher精确概率法;若考虑到中心或其他因素的影响,采用CHMχ2检验。时序资料的组间比较采用Log‐rank检验。组间整体比较检验水准为0.05。
σ——样本标准差。
2.3 道路降雨径流污染SVM模型建立
2.3.1 核函数选择
直流输入电压udc=55 V时,对比其中一相相电压在空间矢量调制下滤波前后波形可知压空间矢量调制波形为马鞍形,相电压频率为50 Hz,波形图如图7所示。由于相电压的三次谐波在合成线电压时会相互抵消所以线电压波形为只存在50 Hz基波的正弦波,如图8所示。通过FFT分析,其主要成分只有50 Hz基波。线电压峰值为54 V,直流电压利用率为98.1%,与SPWM调制相比提高了15.3%,其值和理论分析值接近。可见,SVPWM调制下直流母线电压的利用率较高。
在支持向量机预测建模的过程中核函数尤为重要,直接关系到最后预测数据的准确性。本文通过多次实验确定以径向基函数RBF作为核函数,预测模型的性能最好。
2.3.2 模型参数选择
SVM确定采用径向基核函数后,参数的选择目标为寻找一组能使预测模型准确率最高的惩罚因子c和核参数g。其中,惩罚因子c决定了模型重视离群点引入的损失程度;而核参数g决定模型的泛化能力。本文支持向量机参数的选择采用网格搜索法,使用Python工具包gridgression提供的k折交叉验证法对径向基核函数的c、g参数进行寻优,搜索范围和搜索步长分别为[-10,10]及1。对于EMC和FF30模型寻得的最优参数见表5所示。
武成龙和鬼算盘打得异常激烈。回龙剑如银蛇飞舞,不断攻击着鬼算盘的全身,然而鬼算盘那二尺一寸长的、近尺宽的、怪异的、乌黑发亮的铁算盘好像一面盾牌一样有效扼制了长剑的攻势。长剑的轻灵飘逸与铁算盘的沉重而笨拙相映成趣,不时响起“叮!叮!叮!”轻脆悦耳的碰撞声,如果没有斗场中刺耳的剔肉刮骨声掺杂其间,会让人感到那不是一场生死搏杀,而是一场陶醉人心的表演。

表5 径向基核函数最优参数
2.4 模型校核及验证
2.4.1 校验参数
基于下述4类参数对SVM回归模型结果进行校验:
新工科背景下,利用网络教学平台进行混合模式教学,在很大程度上克服了传统教学存在的弊端,提高了学生的自主学习能力,体现了课程考核的多样化和公正性。只有将传统学习与网络化学习结合起来,使二者优势互补,才能获得最佳的学习效果。
(1)均方根误差(The root mean square error,RMSE):
④措施和计划予以制定。制定系列规章管理办法,营造宣传氛围。对媒体予以尊重,并合理利用,建立良好的媒体沟通机制。健全舆论危机应对措施,做到防患于未然。管理和教育需强化,医务人员的媒体介素需进一步提升。与时俱进,传统媒体和自媒体并重,加强媒体覆盖面。
式中:
YSVM——EMC及FF30的SVM模型预测值;
Y——数据集EMC及FF30实验值。
均方根误差RMSE反映模型预测值及实测值之间的标准偏差,其值越小表明模型预测精度越高。
式中:
(7)
(2)路面材料:将道路路面材料归纳为沥青及水泥混凝土两类,分别对应编码{1,0}。
(3)效率系数(Coefficient Efficiency,CE):
(8)
式中:
效率系数CE广泛应用于校验水文水力模型的模拟性能,反映模型预测值与实测值之间的方差与实测值均方差的比值,其值越接近于1表明模型预测精度越高。
(4)相关系数(Correlation coefficient,CC):
每年为政府提供一份区域非物质文化遗产保护和开发的研究报告。同时加强和地方文化、旅游、民族部门的联系,开展横向课题合作。与百色市及下属各县等合作建设系列非物质文化遗产研究基地,为区内外研究人员的田野调查和研究提供场所和方便,帮助各县区开展非物质文化遗产的申报和保护、研发等工作。
(9)
(2)平均偏差(The mean bias error,MBE):
表示层用来完成地图数据和业务数据的展示以及人机交互的相关逻辑,接收用户的输入并将用户的意图转换为对业务层相关逻辑的调用。地图展示和地图操作通过调用ArcGIS API for JavaScript接口快速实现。
相关系数反映模型预测值与实测值之间的相关性,其值越接近于1,表明模型预测精度越高。
2.4.2 校验结果
使用libsvm工具包提供的Java接口分别对两组数据集进行训练,运用验证样本对模型进行验证。图2及图3所示分别为径流污染COD指标的EMC及FF30模型预测值与实测值对比,由图可知基于两组数据集训练得到的SVM模型均具有较好的预测能力。

表6 EMC-SVM模型校验参数

表7 FF30-SVM模型校验参数
表6及7所示分别为EMC及FF30支持向量机模型的校验参数,从对验证样本的预测结果看:EMC-SVM模型均方根误差(RMSE)、平均偏差(MBE)分别为57.928及-1.231,远小于数据集EMC均值(189.59 mg/L),其效率系数(CE)及相关系数(CC)分别达到0.815及0.933,表明该模型具有较高的预测精度;FF30-SVM模型均方根误差(RMSE)、平均偏差(MBE)分别为0.038及0.004,远小于数据集FF30均值(0.457),其效率系数(CE)及相关系数(CC)分别为0.866及0.932,表明FF30-SVM模型同样具有较高的预测精度。
3 结果及讨论
论文以前人文献中的实测数据作为样本,结合国内外研究成果及论文实验部分研究结论,选取合适的影响因子及决策变量作为模型输入量及输出量,基于支持向量机(SVM)构建了道路径流污染预测模型。主要结论如下:
(1)选取雨型、平均雨强、峰值雨强、降雨历时、雨前干期、大气降尘量、PM10、车流量、路面材料及城市功能区等10项影响因子作为模型输入量,分别选取径流污染指标COD的场次降雨EMC及FF30值作为模型输出量。对非数值属性雨型、路面材料按类别编码进行转换,对城市功能区采用按要素权重打分的转换方法。
(2)选用径向基函数(RBF)作为核函数,使用k折交叉验证法对模型参数进行寻优,对于EMC-SVM及FF30-SVM模型寻得的最优参数(c,g)分别为(64.0,0.001 953 125)、(2.0,0.062 5)。
在目前大部分的高职公共英语教学中,教师还是倾向于使用单一的教学方法,一本教材,一支粉笔,一堂课。同时,大部分公共课程进行大班授课,课堂活动组织困难,这就更加重了教师授课“满堂灌”的倾向。除此,公共英语的教学内容虽然与学生日常生活有联系,但是相当一部分内容对于学生而言已经过时或者很熟悉了,难以引起学生的兴趣。
(3)校验结果表明论文构建的EMC-SVM及FF30-SVM模型均具有较高的预测精度。EMC-SVM模型校验参数RMSE、MBE远小于数据集EMC均值,CE、CC达到0.815及0.933;FF30-SVM模型校验参数RMSE、MBE远小于数据集FF30均值,CE、CC分别为0.866及0.932。
此外,本文建立的预测模型以国内多个城市的道路降雨径流污染实测数据为样本,通过验证,该模型预测精度较高,因此可作下述应用:
(1)对于开展监测实验难度较大的城市道路,可以运用该模型进行降雨径流污染的预测和评估:通过道路特性参数及降雨特性参数的输入得到其在特定场次降雨下的EMC及FF30输出值。
(2)预测模型输出值EMC可作为降雨径流模型(如:SWMM)的输入参数,通过模型进一步计算出排水管网出口污染负荷。
(3)低影响开发(LID)作为城市降雨径流水质水量管理的重要途径,其方案设计应基于可靠的场地基础数据。降雨径流形成后,先经过LID单体设施的消纳及净化,再进入管网系统排出。因此路面径流污染预测值EMC及FF30可作为LID方案设计的基础数据。同时,模型输出值FF30反映初期冲刷效应的显著性,可为初雨截留装置的设计提供依据。
(4)通过累加特定道路一年内所有场次降雨的EMC预测值与径流量的乘积,得到道路年径流污染负荷评估值。
