基于精英自适应遗传聚类算法的烟草物流配送优化研究
2020-04-27李存兵谢林君杨金欣
李存兵,谢林君,杨金欣
1. 浙江省烟草公司宁波市公司,浙江省宁波市高新区凌云路75 号 315000
2. 浙江工业大学,杭州市下城区潮王路18 号 310014
3. 浙江省烟草公司绍兴市公司,浙江省绍兴市人民东路485 号 312000
烟草物流配送中心选址以及服务区域规划是近年来物流系统建设的一个重点,并逐步向烟草行业要求的“集约化管理,规模化经营,专业化物流,标准化服务”方向发展[1]。传统的配送中心选址问题主要采用整数规划、重心法、线性规划、图上作业等方法,对目标函数要求较高,多约束条件处理困难。随着现代化物流的发展,启发式(Heuristics)和混合智能算法在选址问题上的应用优势越来越明显。该算法在搜索域中按一定规则搜索,搜索效率高且结果相对精确,能够更好地解决物流优化问题。刘鹏程等[2]构建了可动态适应多个分布式电源投切的开关函数,通过引入多种群遗传算法,提出了分布式电源配电网故障区段配送方法,有效提高了故障区段电源的配送效率;任晓智等[3]采用改进的聚类算法和遗传算法相结合,对烟草物流中转站、周期配送区域及线路进行了优化;Smieja 等[4]采用部分监督的高斯混合模型(C3L)进行聚类分析,通过控制最大初始分类之间的矛盾产生聚类,并结合专家知识和分布数据进行集群检测,提高了聚类在工程应用中的有效性;Abualigah 等[5]提出了3 种特征选择与特征权重方案,用于解决动态降维算法中的聚类问题,通过动态降低纬度以减少聚类因子,结合遗传算法、粒子群算法提升聚类速度和聚类性能。将上述算法应用于烟草物流配送则存在初始类核无法完全聚类或者聚类不均匀、算法收敛速度慢等问题。为此,采用配送物流量的距离、配送时间方差、服务区之间差异等指标,基于传统遗传算法构建了一种精英自适应遗传聚类算法,对配送服务区域分布和中转站数量进行优化,以期降低物流成本,提高配送效率。
1 配送问题与优化策略设计
1.1 配送优化问题
根据目前烟草物流配送体系特点及要求,需优化的问题包括:①确定服务区域聚类;②确定中转站,在聚类基础上以配送量的距离作为指标,使配送中心与中转站之间以及中转站与对应服务区域之间综合期望代价最小;③服务区域再优化,以中转站为中心,使服务区域之间配送时间波动最小化,且分布规模均匀。
1.2 配送服务区域与中转站优化
为确定服务区域聚类和中转站个数、位置,以配送距离、配送量、客户数、配送时间等为指标,建立目标函数。
(1)配送量的距离最小化目标:

(2)配送时间的方差最小化目标:

式(7)表示所有中转站对应服务区域的配送时间相对均衡,其中SjΔt表示中转站i 对应服务区域配送时间方差。
(3)不同服务区域(聚类)之间的差异最大化目标。区域划分问题的实质是聚类问题,采用聚类分析中的欧氏距离可以检验不同聚类之间的差异性:

式中:xik,yik,xjq,yjq分别表示聚类k,q中零售点i,j的坐标,k,q=1,2,3,…,m,m 取聚类k,q 中聚类点较少的数。
(4)综上,得到总目标函数:

式(9)是对式(1)、式(7)和式(8)的加权糅合,α,β,γ的大小可根据物流中心的商业目标做相应调整。若提高α值,需要建立紧凑型聚类;若提高β,γ值,需要关注聚类内部的平衡以及类与类之间的差异性。
2 改进的遗传聚类算法
遗传算法是借鉴生物自然选择和交叉变异遗传进化机制建立的一种全局优化搜索算法,具有优越的全局搜索能力,但局部搜索能力不佳,容易早熟。聚类分析是一种分类学与多元分析相结合的多元统计方法,将分类对象置于一个多维空间,依据相似性对样本自动分类,具有较强的局部搜索能力。常规的聚类算法有分割和层次两类,层次算法是指整个数据集分解成树状图子集,直到每个子集只包含一个数据对象,其构建方法有分裂和合并两种;分割算法是根据目标数据到聚类中心的距离进行迭代的算法。Barreto等[6]专门对选址和路径规划方法进行了比较分类,见图1。本文中提出的遗传聚类分析方法是将改进的遗传算法应用于聚类分析中,使分类过程既可用于局部范围搜索,也可在全局范围搜索分类,提高了聚类速度,且聚类结果可靠。
图1 聚类方法分类Fig.1 Classification of clustering methods
2.1 染色体编码/解码机制
本文中设计了一种基于聚类中心的三维实数编码方式。基于聚类中心的染色体编码就是将p 个聚类中心作为一串染色体的基因,三维编码实现了聚类中心对应零售点及位置坐标的映射,n维样本需要p个聚类中心,则染色体结构:

每条染色体的长度为3×p×n,其坐标和需求量向量依附于编号基因,这种编码方式包含的信息量较大,易于后续模型求解,也避免了二进制编码反复编、译码的问题。
2.2 种群初始化
种群初始化是随机产生一个初始种群的过程。在事先确定p 个中转站的基础上,首先利用一般聚类算法进行第一次分类,得到p 个初始聚类中心,根据编码方式构成染色体,作为遗传聚类的精英初始种群。由于聚类算法每次聚类得到的聚类中心存在差异性,重复此步骤若干次,直至构成初始种群规模。
2.3 适应度函数
聚类问题的实质是找到某种划分,使不同类之间存在较大差异性,同一类中的样本具有较高的相似性。根据拟求解的问题,适应度函数即为总目标函数:

2.4 选择算子
将精英主义选择与轮盘赌注方法相结合[7-8],计算父代染色体适应度,保留并复制适应度最高的染色体后进入下一代,对剩余染色体采用轮盘赌注方法选择,第i条染色体的选择概率:

在轮盘赌注方法中,轮盘转动N次(初始种群的数量),每转动一次产生一个被比较的个体。该个体的选择概率与一个随机产生的0~1之间的实数γ相比较,如果Pi-1<r<Pi,则选择Pi。
2.5 交叉算子
为扩大搜索区域,使染色体向着适应度高的方向发展,选用了部分映射交叉法[9-10],即在随机的两条染色体中选取片段确定映射关系,交换双亲中的子串,并利用映射关系使后代合法化,见图2。
2.6 变异算子
为满足配送时间波动最小目标,设计了基于配送时间方差最小化自适应变异算子,即假设选取的基因为xi,变异后的基因为x'i,两者之间的选择原则及关系:

式(13)表示选择聚类(服务区域)配送时间方差最大的基因(聚类中心)作为变异基因位。式(14)表示变异后的基因表达式,Δ(Tc,X)为变异步长,X 是变异选择范围,r 是服从(0,1)均匀分布的随机数,λ是系统参数。Tc是变异温度,在本文中定义为:


图2 映射交叉算法Fig.2 Mapping crossover algorithm
由式(16)可知,配送时间方差越大,表示变异步长越大,染色体产生的变异范围随之增大。本文中设计的基于配送时间的自适应变异算子,能够依据配送时间最大限度地产生新染色体,使之向着适应度高的方向发展,有效避免早熟现象。
2.7 算法流程
根据上述分析,得到精英自适应遗传聚类算法流程,见图3。

图3 算法流程图Fig.3 Algorithm flowchart
3 应用效果
3.1 应用现状
浙江省烟草公司下属某市公司现有1 个物流配送中心、1个分中心、3个中转站,承担全市26 000余零售户的卷烟配送任务。通过对成本、效率和服务等物流配送指标进行综合评价,发现目前配送体系存在物流成本过高、配送效率较低等问题。该公司拟建设新物流配送中心,撤销现有配送中心和分中心,对中转站及对应服务区域进行重新调整和划分,达到降低物流成本、提高配送效率的目的。
3.2 数据分析
3.2.1 空间聚合度分析
根据Barreto 等[6]的研究结论,从获得最优解的次数看,从下而上的二阶段方法性能最好;从求解的平均结果看,自下而上的一阶段方法和直接指派方法的效果最好。因此,利用文献[6]中的聚类算法对烟草配送问题进行求解,并将3种方法与本文中提出的精英自适应遗传聚类算法的空间聚合度进行对比,结果见图4。

图4 传统算法与精英自适应遗传聚类算法空间聚合度对比Fig.4 Comparison of spatial aggregation between traditional algorithm and self-adaptive elitist-based genetic clustering algorithm
图4a可见,从总体上看聚类效果可以接受,但存在两个问题:①每类的容量规模分布不平衡,特别是边远地区存在一些小类,影响配送车辆利用率;②少数类之间存在相互交叉重叠现象,对路径规划效率产生不利影响。图4b可见,最大的几个类每个都覆盖了很大一块区域,因此需要进行第二阶段调整,即对这块区域重新聚类。Barreto等使用的最大测试数是318 个零售点,而该地区有25 956 个零售点。因此,该方法在Barreto等的研究中应用效果较好,但在本文中的大规模区域仍存在一定困难。图4c 可见,从总体上看聚类效果可以接受,但最终类的效果无法与初始类核完全聚合,故不能找到稳定的求解结果。图4d可见,每个类的分布规模较均匀,空间聚合度也较高,可以对实际问题进行求解。
参数设置:种群数N=100,迭代次数T=100,交叉概率Pc=0.8,变异概率为自适应值,系统参数λ=1。利用Matlab进行计算,本文算法与K-mean聚类算法的计算结果见图5。可见,本文算法比K-mean 聚类算法收敛速度更快,收敛目标值也更优,表明本文算法具有可行性和实效性。

图5 本文算法与K-mean聚类算法适应度曲线Fig.5 Convergence curves of the designed lgorithm and K-mean clustering algorithm
3.2.2 配送优化
将整个配送区域均分为40×40点阵,共1 600个候选点,相邻候选点东西间距4 km,南北间距3.6 km,给定中转站和配送中心数量,以最小总里程为目标,计算最佳选址方案。分别选取中转站个数p=0,1,2,3,运用本文中提出的算法进行聚类,效果见图6。

图6 不同数量中心转站的聚类效果Fig.6 Clustering effects for different amount transit stations
图6a 方案无中转站只有一个配送中心(红点所示)。由表1可见,配送总里程38 682.04 km,直送率达到100%。
图6b 方案有1 个中转站(红色三角形所示)和1个配送中心(红点所示)。由表2可见,中转站安排在区域A,配送总里程30 729 km,零售户直送率和按量直送率分别为70.9%和74.9%。

表1 无中转站方案配送效果数据(p=0)Tab.1 Delivery effect data with no transit station(p=0)

表2 有1个中转站配送方案效果数据(p=1)Tab.2 Delivery effect data with one transit station(p=1)
图6c 方案有2 个中转站(红色三角形所示)和1个配送中心(红点所示)。由表3可见,中转站分别安排在区域A 和区域B,配送总里程26 153 km,零售户直送率和按量直送率分别为51.8%和55.4%。
图6d 方案有3 个中转站(红色三角形所示)和1个配送中心(红点所示)。由表4可见,中转站分别安排在区域A、区域B 和区域C,配送总里程24 648 km。方案d 与优化前3 个中转站模式相比,零售户直送率由27.6%提高至35.0%,按量直送率由38.5%提高至41.4%,总里程由26 000 km 降低至24 648 km,所有中转站对应的服务区域分布也更加均衡。
集中配送可以降低配送成本,因此配送中心选址的最优位置应在配送最集中的区域。由图7可见,该地区卷烟销量集中区域与采用方案d规划的配送效果相符合。

表3 有2个中转站配送方案效果数据(p=2)Tab.3 Delivery effect data with two transit stations(p=2)

表4 有3个中转站配送方案效果数据(p=3)Tab.4 Delivery effect data with three transit stations(p=3)
以浙江省各市烟草物流成本、分拣、仓库储存等指标为对象进行对比,结果见图8。某市未优化前万支卷烟物流成本远高于全省平均水平,优化后略低于全省平均值;未优化前万支分拣、仓库费用明显高于全省平均水平,优化后显著降低,但各指标仍未达到全省最低值,原因在于该市年平均人工费用124 302 元/年,人工成本较高,且该市处于丘陵地带,拟建设的配送中心所处地理位置也造成物流配送成本较高。

图7 卷烟销量集中区域分布Fig.7 Distribution of major cigarette markets
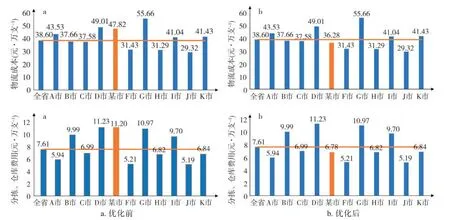
图8 优化前后物流成本对比Fig.8 Comparison of logistics costs before and after optimization
4 结论
针对配送中心选址以及服务区域规划问题,提出了配送物流量的距离最小化、配送时间的方差最小化、不同服务区域之间差异最大化的目标,通过加权糅合构建综合目标模型,并设计了精英自适应遗传聚类算法进行求解,提高了聚类收敛速度,避免了早熟现象,使聚类的区域分布更加均衡。以浙江省某市烟草物流配送中心为对象进行测试,结果表明:①利用本文算法实现了对应服务区域和中转站的确定以及聚类区域的优化,分别对中转站个数p=0,1,2,3 进行优化分析,其中3 个中转站模式优化后,零售户直送率提高7.4 百分点,按量直送率提高2.9 百分点,总里程减少1 352 km,所有中转站对应的服务区域分布较均衡;②优化后万支卷烟物流成本、分拣和仓库费用显著降低,低于浙江省平均水平;③该地区卷烟销量集中区域与采用本文算法规划的配送效果相符合。本文算法具有一定的可行性和实用性,有利于降低物流成本,提高物流配送效率。
