基于分布式的算法封装技术研究与应用
2020-04-26和志成
李 辉,和志成
(1.云南电网有限责任公司信息中心,云南 昆明 650011;2.玉溪供电局,云南 玉溪 653100)
0 引 言
随着大数据时代的到来,电力行业有关数据的存储总量已达一定规模。这些数据蕴含丰富的知识,若能从中挖掘有关模式,将有利于电力行业的发展。为建设快速灵活、简便易用、支持分布式以及可复用的企业算法中台,需要充分考虑算法封装方法及分布式架构的设计与实现,使其兼具实用性与易用性。本文提出了一种基于分布式的算法封装框架,该框架不仅能够支持分布式并行计算,而且融合了算法优化、参数择优以及数据采样等多种功能,能够满足电力行业数据分析方向的基本需要。
传统的算法封装框架有Weka、MADLib以及Mahout。Weka是一个用于数据挖掘的机器学习工具包,它的UI非常简单,但需要专业人员来选择合适的机器学习算法并调整有关参数,这降低了它的易用性。此外,Weka还是一个单节点式的,无法实现分布式计算,即无法满足并行化数据分析的需要。在数据库和分布式领域,Mahout的目标是建立一个可扩展的机器学习库,它是Hadoop技术栈的一部分。MADLib则为关系型数据库提供机器学习库。这些框架的共同点是没有自动的算法优化过程,然而这个过程对于非专业数据分析人员来说非常重要。
Google Predict是谷歌开发的Web服务,用于解决预测类问题,但它能支持最大训练数据量仅为250 MB,远远无法满足人们的需求。文献[1]提出了数据库应该原生支持预测模型的观点,并基于此观点展示了一个称为Longview的模型。近期,在针对新型分析任务的分布式实时计算领域有很多重要的发现,如Hyracks和AMPLab’s Spark均支持基于内存的迭代式计算,能够对机器学习算法起到很好的支撑作用。SystemML提供了一个类R语言的功能,并且提供了算法优化功能,最后将它编译到MapReduce中,该思想值得借鉴。但是,SystemML尝试支持机器学习专家来对分布式算法进行开发而忽略了对算法易用性的考虑。文献[2]表明很多机器学习算法都能够被简化为一个凸优化问题,文献[3]展示了一种在概率数据库中对算法进行优化的技术。
1 框架结构
如图1所示,框架主要结构由驱动器、执行器以及集群管理器所构成。驱动器是框架的核心,它位于集群的某个节点上,主要负责以下内容。一是维护会话,以保存应用程序的相关信息,二是和用户进行交互,管理输入输出,三是分析任务并将任务分发至执行器。执行器接收驱动器分配的任务并执行,然后将计算结果状态返回给驱动器。集群管理器负责计算资源的统一调度,将计算资源统一按某种策略分配给应用程序[4]。

图1 框架结构
2 框架原理
如图2所示,当用户将声明式机器学习任务作为请求输入后,框架将对其进行解析。解析后的请求会经历两个阶段。第一个阶段称为计划阶段,该阶段不对具体数据进行操作,而仅仅用于描述完成用户请求的通用流水线。该流水线涉及算法选择、特征工程、算法调参以及数据采样等功能。此外,框架内部会自动搜索优化空间来对此阶段进行优化。第二个阶段称为执行阶段,它是由计划阶段转化过来的。一个执行阶段主要包含一系列的可执行操作,如过滤或特征值缩放,这些操作和MapReduce所实现的功能类似[5]。与计划阶段不同的是,执行阶段使用具体参数对数据集进行测试。在测试过程中,主节点会将这些任务分配到从节点上执行。执行的过程有两种,所产生的结果也会不同。一种是对数据特征进行处理,如数据降维等,所产生的结果是数据的某种表现形式,可用于后续预测或数据综述;另一种是利用数据对模型进行训练,所产生的结果即是已经训练好的模型。同时,框架会总结模型的训练过程,以便于用户了解详细情况[6]。

图2 内部流程
当获取到第一次计算结果时,计算任务仍未结束,而是会通过额外的探索来提高模型性能。在每一次计算过程中,框架会将中间步骤存储起来,包括已训练的模型、处理过的特征值以及和模型相应的核心统计指标。根据指标比对,可能会修改计划以提高模型的最终效果[7]。
用户提交当前请求后,在提交下一个请求之前,框架不会闲置,而是会持续在后台搜索当前请求的更优解。若发现更优解,即质量更好的算法或参数,它会及时通知用户。
框架优势如下,一是通过让用户早期对初始模型进行评估试验,使其具备交互性特点,二是使得用户创建整个数据处理流水线变得更容易,三是降低了早停的风险,四是当用户输入新数据时,它能够立即使用新数据更新模型并提升模型性能,即实现在线学习,五是框架具有良好的可扩展性,能够容纳新型机器学习算法[8]。一旦有需求,开发者就能通过指定的协议将新的机器学习算法源源不断地添加到算法库中。协议明确了算法的类别(如聚类算法)、参数以及时间复杂度等。
3 算法优化过程
框架内部集成了算法优化的功能,主要体现在计划阶段。算法优化需要用到优化器,优化器通过参数调整和数据采样多种策略组合优化已有的计划阶段,然后进行评估。为了满足时间约束条件,优化器将基于统计模型,利用启发式算法及最新的模型选择工具来估计流水线的执行时间和算法综合表现[9]。优化器能够根据已有数据的表征形式来估计模型的运行时间。针对每一个模型,优化器会估计它的效果,选出一个最佳候选。
图3显示了一个具体的优化过程。在该过程中,优化器对数据进行特征标准化并采样,接下来优化器采用10折交叉验证进行检验。在每次实验中,将其中一份数据用于验证[10]。评价指标则采用通用标签基线准则、误分类率以及近邻数。需要注意的是,最终的模型仍然是用全量数据集生成的。此外,优化器能够建立多维索引结构并提前完成距离矩阵的计算工作,以便对算法进行加速。
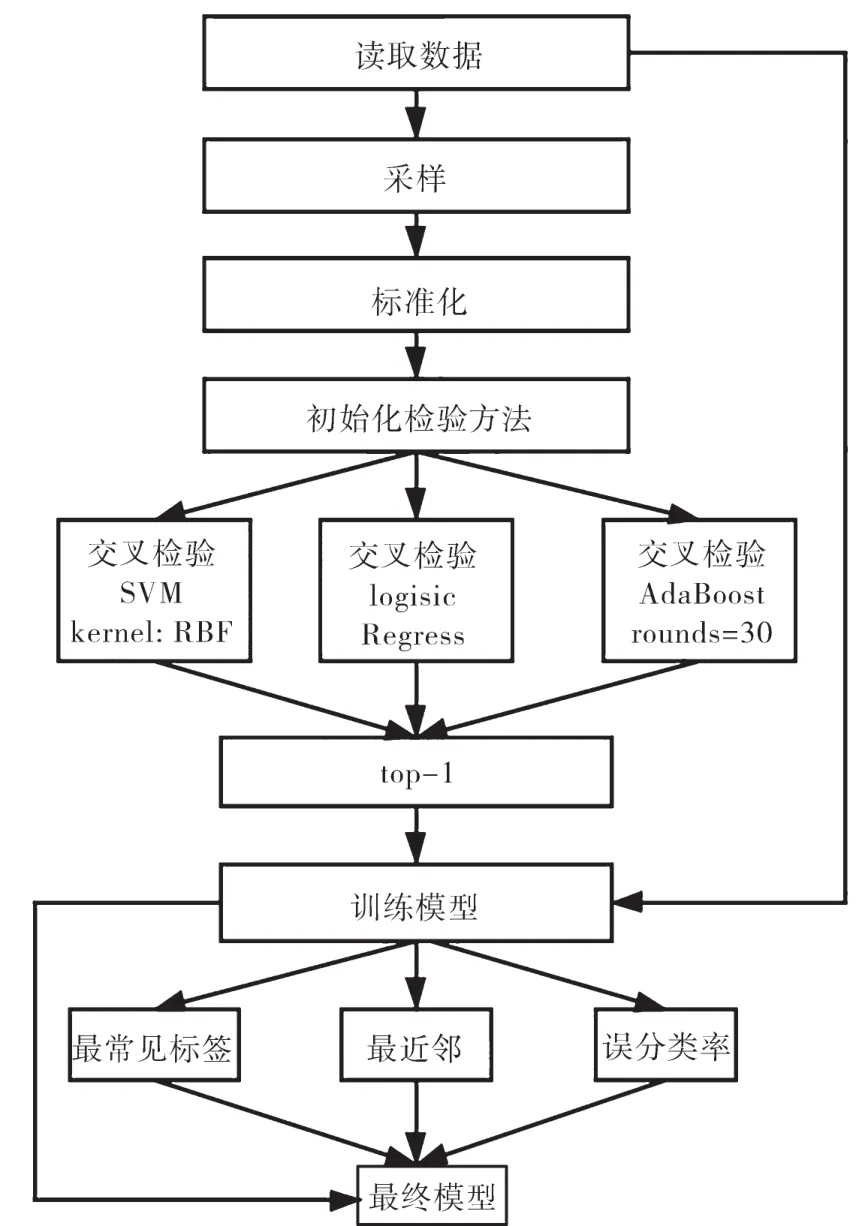
图3 算法优化步骤
4 实例分析
驱动器运行在客户端,因此不受主节点的管理和约束。执行器则不同,它运行在集群中的从节点上,因此会受到主节点的管理和约束。一个分布式应用程序在集群中的流程如下:(1)用户向客户端提交应用程序,本机启动驱动器;(2)客户端向集群提交应用程序、所需执行器的数目及相应资源;(3)主结点收到请求,根据合适的调度策略,寻找从结点并启动执行器;(4)执行器与驱动器建立连接;(5)执行器分配并调度任务;(6)所有任务运行完毕,应用程序退出。
5 结 论
本文根据电力行业对于数据分析的需求及特点,提出了一种面向行业的分布式算法封装框架。该框架具有轻便、智能、可扩容以及支持并行化等特点。本文所涉及的主要内容如下,一是基于主从模式和实时内存计算实现了分布式并行计算框架,为海量数据计算提供基础支撑。二是通过设计优化器,将声明式机器学习任务转换成精密的学习计划。在这个过程中,优化器在后台尝试快速给用户返回一个优质的算法,让用户避开了烦琐的算法选择过程。此外,本文展示了在分布式架构基础上优化器的强大潜力,为非专业开发人员进行数据分析提供了较好的帮助。
