基于注意力机制的单通道双人语音分离研究*
2020-04-25周晓东陈人楷孙华星莫钞然
周晓东,陈人楷,孙华星,莫钞然
(1.国网福建省电力有限公司信息通信分公司,福建 福州 350000;2.广州广哈通信股份有限公司,广东 广州 510000)
0 引 言
在传统电力调度通信系统中,调度通话双方甚至多方的语音必须在录音系统中存储,其存储方式为双方甚至多方的语音被存储在单个录音文件中。这种存储方式对于语音识别和声纹识别的准确率会带来阻碍,其中单声道多人语音问题被称为鸡尾酒会问题。解决鸡尾酒会问题的传统机器学习方法,主要有计算机听觉场景分析(Computational Auditory Scene Analysis,CASA)、非负矩阵分解(Non-negative Matrix Factorization,NMF)和生成模型的方法等。计算机听觉场景分析系统(CASA)[1]是利用一定的组织准则和适当的分离线索,模拟人类听觉系统处理声音的过程。CASA 的计算目标是理想二值掩码IBM。在混合语音中,如果目标语音占主导地位,则IBM 值记为1;否则,为0。但是,CASA 对噪声掩蔽不够彻底,分离出的语音仍含有较多的干扰声音,且在分离相对时延较大的一路信号时存在困难。文献[2-3]提出了非负矩阵分解(NMF)方法,求解两个非负矩阵,使得它们的乘积尽可能地接近输入矩阵。NMF 应用于鸡尾酒会问题的主要思路:学习单个说话者的语音特征wk,将所有说话者的字典矩阵串联起来形成一个最终的字典,再求解系数矩阵Hm,最后将第k 个说话者的基矩阵Wk(k=1,2,…,p)乘以系数矩阵(k=1,2,…,p),从而提取出第k 个说话者的语音信号的幅度谱Xk。文献[4-7]解释了基于生成模型的方法,应用最广泛的是GMM-HMM,但计算量较大,且只能用于说话人已知的情况。随着深度学习的发展,深度学习方法逐渐应用到鸡尾酒会问题中,基本思路是根据输入的语音信息,通过神经网络训练对应说话人的掩码,然后用这个掩码与混合语音信号相乘,从而分离出不同说话人。文献[8-11]提出了几种使用广泛的掩码,主要有IBM、IRM、SMM、PSM 和cIRM。其中,在不同信噪比下,IRM 性能都优于IBM、SMM 和IRM 性能类似,且都优于传统的非负矩阵分解的方法。文献[12-13]提出了深度聚类(Deep Clustering,DPCL)的方法,是一种说话人无关的分离模型。这种方法通过把混叠语音中的每个时频单元结合其上下文信息映射到一个新的空间,并在这个空间上进行聚类,使得在这一空间中属于同一说话人的时频单元距离较小,可以聚类到一起。文献[14]提出了深度吸引子网络(Deep Attractor Network,DANet)。研究表明,人的脑回路会产生感知吸引子,这些吸引子使吸引空间形变,将与之相似的声音吸引过来。DANet 与之类似,会在嵌入空间中形成参考吸引子,并将与之类似的声音吸引过来。文献[15]提出了置换不变网络(Permutation Invariant Training,PIT),实验结果显示,PIT 的性能优于传统的非负矩阵分解(NMF)、计算机听觉场景分析(CASA)和深度聚类(DPCL),且和说话人的数目和语言无关,容易实现,且易与其他方法结合。但是,PIT 在分离性别相同的说话人时,性能比性别相反的说话人时性能要差,且能分离的最大数目取决于网络结构。由于传统的方法都是在频域对语音信号进行处理,而将信号变换到频域时需要对信号加窗。为实现足够的频率分辨率,需要的窗函数对应的时间很长,且可能引起相位幅度的解耦。为解决以上限制,文献[16]首次提出在时域直接处理信号,并提出了TasNet(Time-domain Audio Separation Network)。实验结果表明,TasNet 减少了计算量,分离效果优于之前提出的DPCL、PIT 和DANet。
1 算法模型结构
本文的模型结构如图1 所示,主要包括预处理、特征提取、attention 模块和k-means 聚类4 部分。

图1 模型结构
1.1 预处理
在将语音信号输入到神经网络之前,要先对语音信号进行降采样到8 kHz,然后对其做短时傅里叶变化。本文在实验中使用32 ms 的汉明窗,窗移为8 ms。为了保证语音信号的局部一致性,对语音信号进行100 帧的分割。
1.2 特征提取
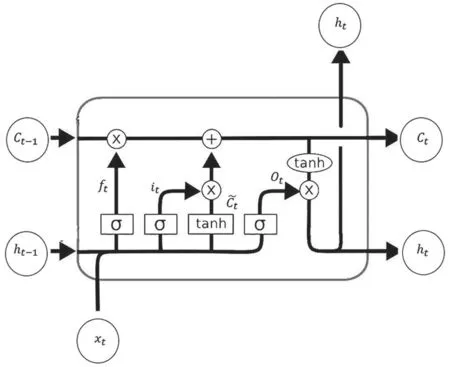
图2 LSTM 结构
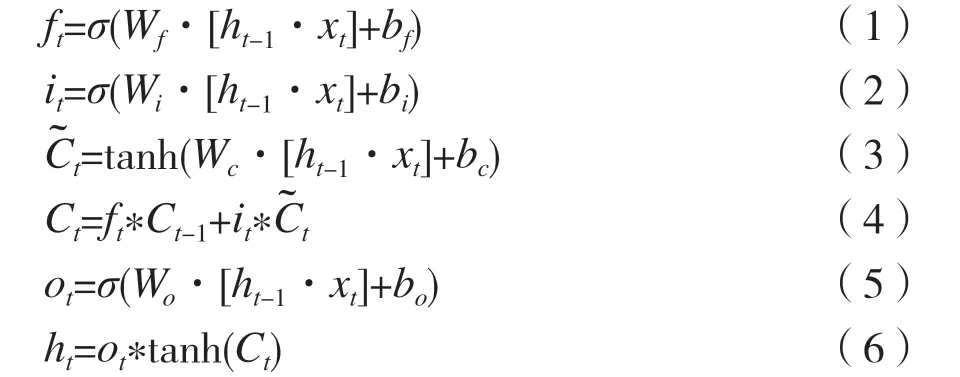
本文使用双向LSTM(BiLSTM)提取语音信号的特征。LSTM 是RNN 的特例,解决了RNN 长距离依赖的问题。LSTM 主要包括遗忘门、输入门和输出门,结构如图2 所示。ft是遗忘门输入,xt是当前时刻输入,it是输入门输入,是输入门神经元输出,ht是当前时刻隐藏层输出,ht-1是上一时刻隐藏层输出,Ct是输出神经元最终输出,Wf、bf、Wi、bi和Wc、bc、Wo、bo是在训练过程中需要学习的参数。双向LSTM 由前向LSTM 和后向LSTM 组成,如图3 所示,输出yt为两个LSTM 输出的组合,如式(7)~式(9)所示,可以更好地捕捉数据之间的数据依赖。
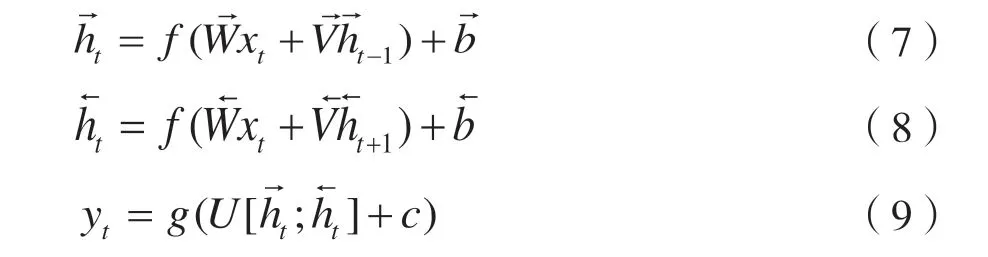

图3 双向LSTM 结构
1.3 注意力机制
人类在观察一幅图片时,可通过快速扫描获取整体图像信息获得重点观察区域,也就是注意力焦点,然后对这一区域投入更多资源,目的是取更多细节信息而忽略其他无用信息。这是在长期进化过程中人类逐渐形成的一种生存机制,使得可以从大量信息中用有限的资源筛选出更高价值的信息。神经网络中的注意力机制与此类似,核心是从大量信息中筛选出对当前任务更有效的信息。注意力模型在机器翻译、图像描述、文本摘要中被广泛使用,主要包括hard attention、soft attention、global attention、local attention 和self attention 等类型。在本文模型中采用的attention 机制的结构如图4 所示。

图4 attention 模型结构
初始时令Q=K=V=I,其中I 为输入向量且I=[i1,i2,…,in],其中n 为向量维度,计算Q 和K 的点积,并除以K 的维度,然后将所得结果通过softmax函数,从而得到每一特征向量的权重α:

经过attention 模块后,所得向量为:
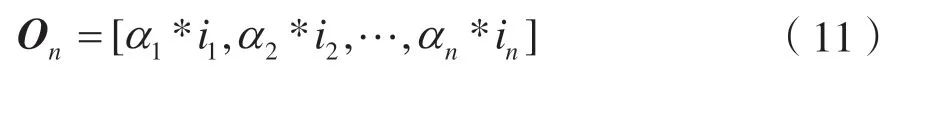
1.4 聚 类
无监督聚类算法主要包括k-means、高斯混合聚类、密度聚类以及层次聚类等。由于k-means具有原理简单、实现容易等优点,因此本文选择k-means 算法对经过attention 模块后的语音特征进行聚类,算法流程如下:
(1)首先确定K 值,即聚类后的集合数目;
(2)从数据集中随机选择K 个数据点作为初始质心;
(3)对于数据集中的每一个点,分别计算它们与这K 个点的欧氏距离,根据距离远近分别将这些数据划分到K 个质心所在的集合中;
(4)对(3)中K 个集合中的每个数据点,分别重新计算每个集合的质心;
(5)如果(4)中得到的新的质心没有变化,则聚类结束,所得的K 个集合就是最后的划分结果,否则返回(3)。
2 实验过程
2.1 数据集
本文中,训练和测试所用的数据集为wsj0 数据集。其中,训练集包含50 个男性说话人和51 个女性说话人,测试集包含10 个男性说话人和8 个女性说话人。每个说话人有141 ~142 条语音,每条语音持续时间为5 ~6 s,采样率为16 kHz,比特率为256 kb/s,在预处理中将其降采样到8 kHz。实验中按照测试集中的语音是否出现在训练集中,将测试集划分为开放的数据集和封闭的数据集,并按照性别将测试集划分为男性和男性混合、男性和女性混合、女性和女性混合3 种情况。
2.2 训 练
假设语音信号经过短时傅里叶变化后的向量为I=[i1,i2,…,in],每层双向LSTM 有600 个节点,经过attention 模块后输出的向量为O=[o1,o2,…,on]。对每一个时频点,若说话人A 的信号能量高于B,则记mi为1,否则为0。那么,对于每一个输出向量O,在对应的时频点上有M=[m1,m2,…,mn]。在本文的模型中,损失函数为:
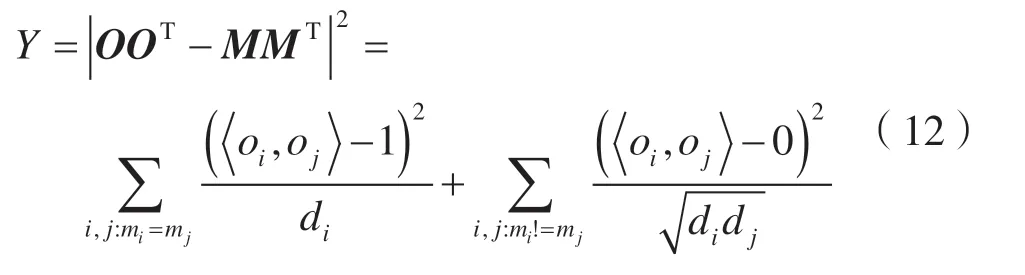
2.3 实验结果
将文献[12]中的结果与本文的模型进行性能对比,结果如表1 所示。评价指标为SDR。SDR 是评价语音信号损失的指标,值越大说明语音信号损失越小。

表1 不同情况下混合说话人的语音分离结果
从表1 可见,在封闭数据集下,当混合语音由男性和男性组成时,SDR(Signal-to-Distortion Ratio)增加了20.58%;当混合语音由女性和女性、男性和女性组成时,SDR 分别增加了17.25%、1.88%,整体SDR 增加了22.78%;在开放数据集下,SDR 在男性和男性混合、女性和女性混合、女性和男性混合时,SDR 分别增加了3.56%、20.87%、1.04%,整体SDR 增加了17.67%。需要说明的是,上述数据通过“(本文数据-DC+k-means)/DC+k-means”获得。综上,本文的模型相比于原来的模型在不同性别的语音混合情况下,SDR 都有所提升,其中在女性和女性的语音混合时性能提升幅度最大。
3 结 语
本文提出了一种双向BLST 和注意力机制融合的语音分离模型。在算法模型中使用双向LSTM 来提取语音信号的高维特征,用attention 模块为每一个语音特征分配权重,用k-means 对输出结果进行聚类,从而在混合语音中分离出两个说话人。实验结果表明,与传统没有attention 模块的深度聚类模型相比,本文的算法模型取得了更好的分离性能。在封闭/开放的数据集上,新算法的SDR 增长率在不同声音混合情形下都有不同数量的提升。在电力调度领域中,实际情况下可能不止有2 个人在同时说话,对于3 人或3 人以上的语音分离任务将是未来的研究重点。
