基于AHP-GRA 的用户身份可信评价方法*
2020-04-25梁晓实邹福泰
梁晓实,邹福泰,谭 越
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
随着互联网和社交媒体的快速发展,我国网民数量不断攀升,网络用户身份信息逐渐复杂,规模也越来越大。在各类网络应用中,需要对用户身份信息可信性做出评价,从而提供不同的服务。随着电子商务、网络支付等领域的发展,我国的经济活动对网络依赖性逐步增强,涉及到资金和财产的网络活动加剧,对用户身份进行认证的需求变得更加迫切。因此,拥有一种可以结合多种属性、安全可靠地进行用户身份可信评价的方法,对于日益增长的网络监管需求至关重要。
依据《信息安全技术个人信息安全规范》[1]定义,用户身份信息是指以电子或者其他方式记录的能够单独或者与其他信息结合识别特定自然人身份或者反映特定自然人活动情况的各种信息,包括姓名、出生日期、身份证件号码、个人生物识别信息、住址、通信通讯联系方式、通信记录和内容、账号密码、财产信息、征信信息、行踪轨迹、住宿信息、健康生理信息以及交易信息等。
结合上述定义,可以将用户身份信息大体分类为自然属性和社会属性。自然属性包括个人的外貌、体型、声音信息等。此类信息较为稳定,且不易被修改,可以用于辨别个体与其他个体之间的差异。社会属性包括个体的社会关系、人际交往、社会职能、社会行为等方面。此类信息会随着个体的时间以及环境变化而产生较大的波动。此外,还有用户社会活动所带来的信息,一并归入社会属性。
目前,网络身份管理技术已经在政府、银行、电商、社交网络等领域建立了各自的管理与服务系统,但当前对于用户的身份信息管理仍存在一些问题:身份信息易被复制和伪造;身份隐私信息易被滥用误用;身份信息被冒用盗用等。因此,如何有效评价身份与身份信息可信,成为统一管理网络实体多形态身份的关键。为了解决上述问题,本文提出了一个新型的身份可信认证系统,主要贡献如下:
(1)创新性地提出一种将层次分析法和逆向灰色关联分析结合的用户身份可信评价方法;
(2)收集多种来源的用户身份信息,并通过多层次关联决策分析,提高用户身份可信评价准确性;
(3)实现了基于层次分析法和灰色关联分析的用户身份可信评价系统,采用合理数据集进行性能评估实验。
1 相关工作
目前,已有多个国家提出过公民身份信息可信管理。其中,美国于2011 年4 月发布《美国网际空间可信标识国家战略》[2],将可信身份体系建设提升为国家战略。2013 年,英国政府通过政务服务,引导开放了分级的第三方身份服务市场,通过市场竞争,提供跨部门的身份保障服务[3]。
在技术方面,随着访问控制技术的发展,目前业界已经提出一系列的评价标准,用于跨域系统的互联互通和访问授权时的身份认证。例如,开放身份互联接口标准(Open identity interconnection interface standard,OpenID)[4],就是一个以用户为中心的身份识别框架,可以有效降低管理方的身份管理成本。身份认证标准(Security Assertion Markup Language,SAML)[5]是目前国际上广泛认可的一个单点登录和身份认证规范,实现了联合身份认证和认证授权信息交换的标准化。FIDO 标准[6]是一种基于开放协议标准的在线认证技术,目的在于减少用户对传统口令的依赖。
目前,在不同网络身份平台上的身份互联互通认证依然存在难题。针对这种问题,目前主要有两种解决思路[7]。第一种是建立一个第三方的可信身份服务平台,由平台与公安、工商、电信运营商等权威认证源对接进行身份验证,为用户提供跨系统、跨平台的可信身份认证服务。平台作为可信第三方不存储用户信息,仅提供相关应用接口。第二种则由第三方直接建立相关身份数据库,并向其他应用依赖方提供登录授权服务。这种服务本质上是采用OpenID 和OAuth 结合的一种互联互通的身份服务和授权登录技术。
随着互联网平台的发展,单因素身份识别技术在实际场景中遇到了越来越大的挑战,因此多因素身份识别技术开始进入大家的视野。目前,大部分的多因素识别研究和应用都集中在静动态信息结合,即利用用户提供的静态身份信息或凭证,结合用户的行为进行综合评价。一些大型互联网企业如阿里、腾讯、新浪等已经开始使用以行为为中心的身份认证技术,他们通过监控用户的操作和登录行为,并根据用户行为是否异常判断用户的身份可信程度。
但是,追踪用户的动态行为需要相对复杂的计算和系统。本文意在解决多平台下的身份互通认证,故考虑仅使用静态信息的方式,即通过用户提供的个人信息,对比权威认证源提供的身份信息,对用户进行身份进行可信评价。
2 相关知识
2.1 层次分析模型
层 次 分 析 法[8](Analytic Hierarchy Process,AHP)由美国运筹学家萨蒂于20 世纪70 年代提出。因其在处理复杂决策问题上十分实用和有效,该方法很快在世界范围内得到了传播与重视。层次分析法将与决策有关的因素分解成目标层、准则层、方案层等层次,在此基础之上进行定性和定量分析。具体可以分为以下步骤。
2.1.1 建立层次结构模型
将与决策有关的各个元素按照不同属性自上而下地分为若干层次,同一层的因素从属于上一层的因素,该层因素对上层因素有影响,同时又支配下一层的因素或受到下层因素的作用。最高层只有一个因素,即为需要决策的目标。最低层为方案层,包含决策时的备选方案。中间层为准则层,可以有若干子层,对应决策所需的各个考虑因素。
在本系统中,目标层为用户身份可信等级;准则层包含两层,分为不同身份信息类别和对应的子类别。本系统中使用层次分析法的目的在于确定准则层各因素的影响因子,与方案层的选择无关,因此不设置方案层具体实例。
2.1.2 构造判断矩阵
在所述层次结构模型的基础上,针对决策层的因素,采用比较尺度表通过两两比较的方式,确定各项元素对上层某个因素的相对影响程度,从而构造一个判断矩阵。

表1 1 ~9 比较尺度表
2.1.3 层次单排序及一致性校验
根据所述判断矩阵,求出其最大特征根以及所对应的特征向量,将特征向量归一化处理后记为w。w 满足:

计算归一化后的特征向量的一致性校验值CI:

引入随即一致性指标RI:

最后,计算判断矩阵的检验系数CR:

若CR<0.1,认为该成对比较矩阵通过一致性检验,可以用做该层因素的影响权重;否则,验证不通过,需要重新构造合理的一致性矩阵。
2.1.4 层次总排序及一致性校验
确定某层所有因素对于总目标重要性的排序过程,该检验从最高层开始逐层向下确定权值。层次总排序计算方法为:

其中aj表示其上层A 中第j 个因素对总目标的排序权值,bij为该层第i 个因素相对于上层第j个因素的层次单排序权值。总排序的一致性检验同式(4)。
2.2 灰色关联分析理论
由于影响身份可信评价因素的复杂性,身份可信是很难被严格量化。本系统使用逆向灰色关联分析,实现对身份可信的量化评估,通过关联系数或综合关联度等特征量分析内在联系,发现影响身份可信评价因素的主要关系和主要特征。灰色关联分析(Grey Relation Analysis,GRA)[9-11]可以很好地运用于各类综合评价问题,核心思想是按照一定的规则确立参考标准序列,并确定各个评估对象序列与其的相似程度,判断相互间的联系是否够紧密,从而得出最终的评价结果。
使用灰色关联分析评估的步骤如下。
(1)确定参考序列和比较序列。将问题抽象为分析序列,构造参考序列和比较序列。其中,参考序列是反映系统行为特征的数据序列,以每个指标的最优值构成参考序列。在本评价系统中,各个指标最优值对应为各个指标划分的上限。比较序列是影响系统行为的因素组成的数据序列。
(2)无量纲化处理。对原始数据进行无量纲化处理,消除各维度特征间的量纲差异,同时也令参评数据在各维度的得分为1,有利于后期的优化与计算。考虑到参评数据可能存在某些维度为0 的情况,本系统中使用mask 矩阵对其进行增量转换,从而消除0 值对于无量纲化时的影响。
(3)计算关联系数。计算各因素的灰色关联系数,比较序列xi在第k 个指标上的关联系数ξi,计算方法如下:
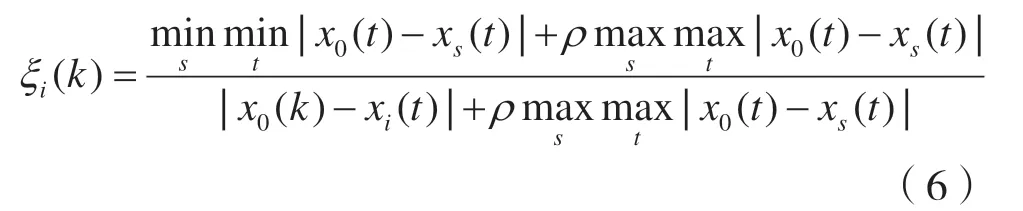
其中ρ ∈[0,1]为分辨系数,一般取值0.5。
(4)计算关联度。对传统的关联度计算准则进行修改,基于层次分析模型算出的各项特征因素的权重,对关联系数矩阵进行加权求和,具体计算公式如下:

其中,rj代表第j 级指标与参评序列的关联度,wi代表权重向量w 中的第i 个权值,εij代表关联系数矩阵中第i 行第j 列的元素。关联度rj的值越接近1,说明两个序列间的相关性越好。
3 模型设计
3.1 模型概述
本文设计了一种基于层次分析法和灰色关联分析的用户身份可信评价方法,以现有的权威身份认证提供商提供的身份信息为原始输入,个体用户后续输入的身份属性信息通过属性聚类及相似度计算进行评分,使用层次分析法和灰色关联分析将各条属性可信评价进行多层次关联决策分析,并得到用户身份可信评价。该方法的示意图如图1 所示。
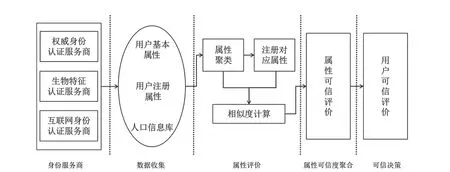
图1 模型框架
(1)身份服务商:身份服务商提供多种权威性身份认证信息数据,包括身份证号、指纹、虹膜、声纹、护照号、姓名、性别、就医记录、犯罪记录、婚姻情况、家庭成员、手机号码以及政治面貌等。
(2)数据收集:收集身份服务商提供的身份信息数据,采集用户注册网络平台、多媒体时的信息数据。
(3)属性评价:对同一用户的同一属性的信息进行聚类,选取类内方差最小的信息作为该属性代表信息。利用用户注册的关键信息,如身份证号、银行卡号、手机号码等与权威信息数据库中数据进行匹配,将用户注册的各属性信息与权威信息数据库中对应属性进行相似度计算,得到相似度评分。
(4)属性可信度聚合:将各属性相似度评分根据范围量化划分为不同的可信等级,如0 ~0.2 不可信,0.2 ~0.5 偏不可信,0.5 ~0.8 偏可信,0.8 ~1可信。对于部分关键信息,如指纹、虹膜、性别等,只划分不可信和可信两个等级,且可信的阈值较高,如99%。
(5)可信决策:使用层次分析法和灰色关联分析,将各条属性可信评价进行多层次关联决策分析,并得到用户身份可信评价。可信评价等级划分为4 级,分别为不可信、偏不可信、偏可信和可信。
3.2 数据预处理
图2 显示了基于层次分析法和灰色关联分析的用户身份可信评价方法所采集的数据。将这些数据分成以下几类,包括:
(1)个体辨识类:指纹、声纹、身份证号、护照号;
(2)医疗类:就医记录、医疗检查;
(3)司法类:犯罪记录、裁决记录、诉讼记录;
(4)家庭类:婚姻情况、家庭成员;
(5)通讯类:手机号、微信号、邮箱、社交账号;
(6)个体特征类:性别、出生日期、民族、宗教信仰;
(7)人事类:政治面貌、教育经历。
可见,共计7 大类,21 种不同的身份属性信息。

图2 身份信息分类
3.3 执行流程
本文设计的模型流程如图3 所示。
首先,根据已有信息与权威身份服务商提供的信息作对比,计算相似度;其次,构建层次分析模型,构造判断矩阵并输出权重向量;再次,确定参考序列,并对序列中的数据进行无量纲化处理,计算关联度;最后,寻找到关联度最高的比较序列,并输出最终评价结果。
4 实验结果与分析
4.1 实验环境
本文实验使用Linux 系统(Ubuntu 18.04)进行实验,系统内存2 GB。
4.2 数据来源
本文使用的数据为模拟数据集。模拟1 000 个用户的身份服务商提供的个人信息作为权威信息数据库,及他们在平台上注册时输入的信息数据作为评价数据。每个用户有一组权威数据及一组评价数据。对这1 000 个用户的模拟数据进行实验。事先根据合理性对1 000 个用户的待测评数据已进行了等级标记。

图3 网络结构
4.3 评价指标
为了评估本文提出的检测模型的表现,本文共选取2 个实验指标,分别为宏F 值(Macro F-Score,Macro-F1)和Kappa 系数:


其中p0表示总体分类精度,pe为:

4.4 实验步骤、结果与评估
计算每组评价数据与权威数据之间的相似度,使用层次分析法和灰度关联分析对计算出的相似度进行分析。
4.4.1 构造判断矩阵
由图2 身份信息分类可知,共选取7 个类别21种属性的身份信息,因此共需要构建8 个判断矩阵。判断矩阵的参数由小组成员共同确定,具体如下。
(1)二级指标个体辨识类I1的判断矩阵B1如图4 所示。
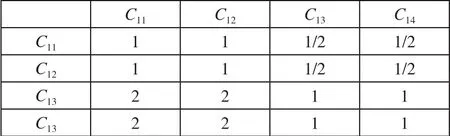
图4 二级指标个体辨识类I1 的判断矩阵B1
二级指标医疗类I2的判断矩阵B2如图5 所示。

图5 二级指标医疗类I2 的判断矩阵B2
二级指标司法类I3的判断矩阵B3如图6 所示。
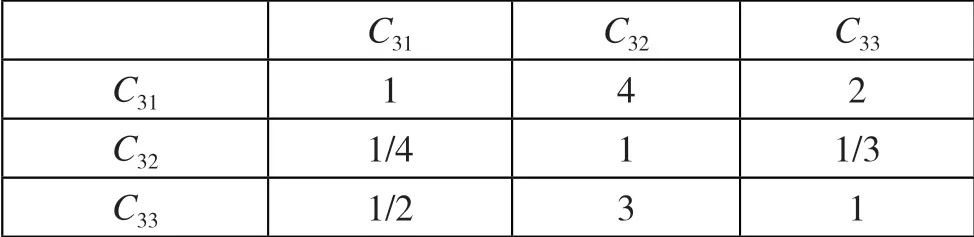
图6 二级指标司法类I3 的判断矩阵B3
二级指标家庭类I4的判断矩阵B4如图7 所示。

图7 二级指标家庭类I4 的判断矩阵B4
二级指标通讯类I5的判断矩阵B5如图8 所示。
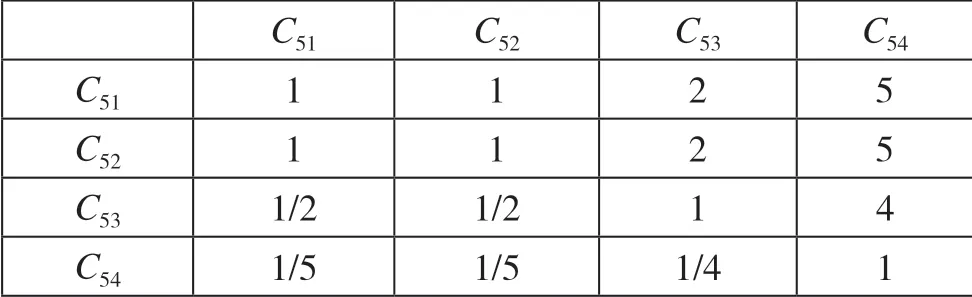
图8 二级指标通讯类I5 的判断矩阵B5
二级指标个体特征类I6的判断矩阵B6如图9所示。

图9 二级指标个体特征类I6 的判断矩阵B6
二级指标人事类I7的判断矩阵B7如图10 所示。

图10 二级指标人事类I7 的判断矩阵B7
一级指标的判断矩阵A1,如图11 所示。
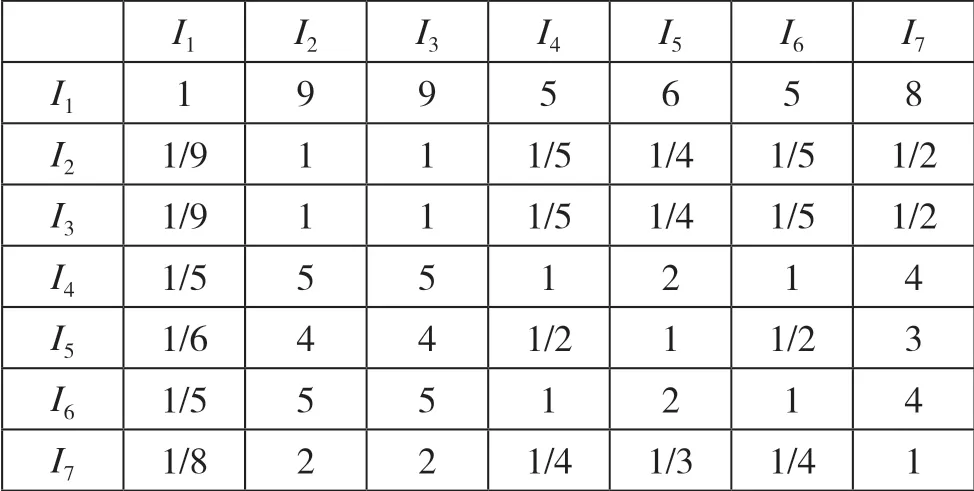
图11 一级指标的判断矩阵A1
4.4.2 计算8 个矩阵的归一化特征向量和一致性检验结果
使用python 计算,得出8 个对比判断矩阵的一致性检验结果和归一化特征向量分别为:
对比矩阵B1通过一致性检验,各向量权重向量Q1为[0.166 666 67,0.166 666 67,0.333 333 33,0.333 333 33],CI=0.0,CR=0.0。
对比矩阵B2通过一致性检验,各向量权重向量Q2为[0.833 333 33,0.166 666 67],CI=0.0,CR=0.0。
对比矩阵B3通过一致性检验,各向量权重向量Q3为[0.558 424 54+0j,0.121 957 19+0j,0.319 618 26+0j],CI=0.009 147 353 644 82+0j,CR=0.010 163 726 272+0j。
对比矩阵B4通过一致性检验,各向量权重向量Q4为[0.666 666 67,0.333 333 33],CI=0.0,CR=0.0。
对比矩阵B5通过一致性检验,各向量权重向量Q5为[0.364 229 38+0j,0.364 229 38+0j,0.206 381 36+0j,0.065 159 88+0j],CI=0.009 246 313 859 65+0j,CR=0.008 255 637 374 69+0j。
对比矩阵B6通过一致性检验,各向量权重向量Q6为[0.312 5-0j,0.312 5-0j,0.312 5-0j,0.062 5-0j],CI=-1.480 297 366 17e-16+0j,CR=-1.321 694 076 93e-16+0j。
对比矩阵通过B7一致性检验,各向量权重向量Q7为[0.8,0.2],CI=0.0,CR=0.0。
对比矩阵A1通过一致性检验,各向量权重向量Qa1为[0.487 891 93+0j,0.031 094 56+0j,0.031 094 56+0j,0.151 596 13+0j,0.099 639 98+0j,0.151 596 13+0j,0.047 086 71+0j],CI=0.041 964 656 624 4+0j,CR=0.029 762 167 818 7+0j。
4.4.3 计算身份可信评价等级划分中各评价因素的关联度
(1)确立标准序列和参评序列
模型中,选取和AHP 模型相同的I1~I7共7个维度的准则作为等级划分的标准。在7 个维度下共21 个属性,根据计算得出的子层权重进行综合量化,具体的量化公式如下:
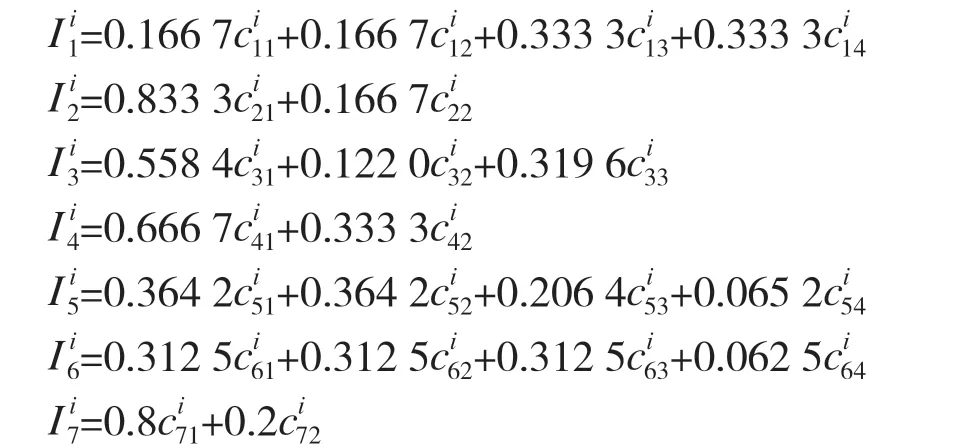
本模型根据之前计算的相似度,已经将各个属性按照相似度进行基本分级,将各个层级的最佳案例作为评价级别的代表参数。每次选取一组待评价数据作为参评序列一同进行关联度计算。如前文所述,本次模型中逆向使用灰色关联分析模型,将4个评价等级序列作为候选序列,参评序列作为标准序列,从候选序列中选出与之最相似的序列,从而实现了对目标事件的等级分级。其中,Level 1 最可信,Level 4 最不可信。
(2)进行无量纲化及关联度计算
将待评数据根据计算的权重向量进行处理,由21 维变成7 维。根据确认的候选序列,与参评序列构成矩阵,对其进行无量纲化和差序列计算。具体无量纲化规则如2.2 节所述。根据计算的一级权重进行关联度计算,取关联度最大的列,即为与参评序列最相近的候选序列,代表了该待评数据的分类。
以用户1 的待测评数据为例。经过无量纲化后的矩阵为:

计算得出的关联度矩阵为:

根据4.3.2 节计算得出的权重,求出各列关联度为:

可以看出,level 1 关联度最高,即把用户1 的可信等级分为Level 1 最可信。
4.4.4 实验结果与评估
根据以上步骤,使用AHP-GRA 算法对1 000名用户进行可信等级评价,最后得出的评价结果如图12 所示。

图12 可信等级评价分布
具体评价数据为Level 1(可信)248 个,Level 2(偏可信)327 个,Level 3(偏不可信)281 个,Level 4(不可信)144个,得出的混淆矩阵如表2所示。
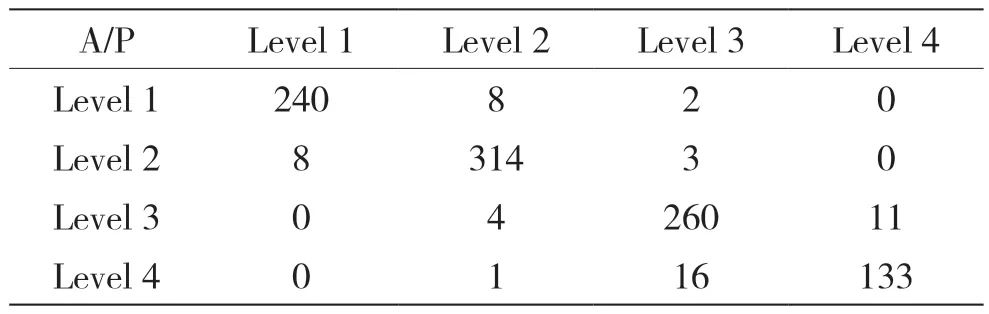
表2 AHP-GRA 方法混淆矩阵
本文同时也建立了K-Means 聚类模型作为对比实验。K-Means 是一种快速、有效的强聚类方法,基于各个数据在特征空间中的位置分布规律进行聚类,通过不断迭代优化最终达到收敛。
得出的混淆矩阵如表3 所示。
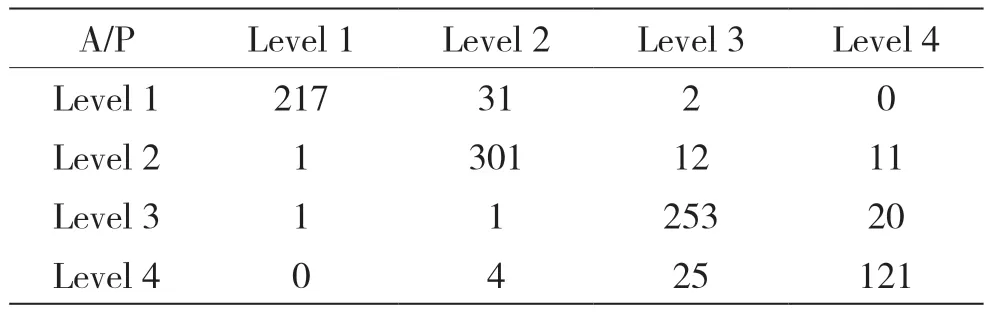
表3 K-Means 混淆矩阵
对两类方法进行评估,可以得出评价结果如表4 所示。

表4 两类方法的评价结果
可以看出,K-Means 的Macro-F 值和kappa 系数均低于AHP-GRA。
具体来说,一位用户的个体辨识类信息可信度极高,但是其他类别信息可信度较低。考虑到可能用户在自身发展过程中其他类别信息有变化,未能及时更新,故该用户应属于较为可信级别。再考虑另外一个用户,个体特征类、人事类等信息可信度较高,但是个体辨识类信息存在不太可信的情况,考虑到个体辨识类信息为不可改变的信息,故该用户应属于较为不可信级别。K-Means 方法在无监督的情况下并不能很好地区分这两类用户的可信程度,而AHP-GRA 模型可以。AHP-GRA 模型可以对每个因素赋予合理的影响因子,从而得出相对合理的评级结果。
5 结 语
本文提出了一种基于AHP-GRA 的身份可信评价方法,旨在解决不同身份不同网络身份平台上的身份互联互通认证问题。本评价系统以现有的权威身份认证提供商提供的身份信息为原始输入,个体用户后续输入的身份属性信息通过属性聚类及相似度计算进行评分,使用层次分析法和灰色关联分析将各条属性可信评价进行多层次关联决策分析,并得到用户身份可信评价。通过对模拟数据集进行评价,结果表明,基于AHP-GRA 的可信评价模型能够给身份认证体系提供一个较为合理客观的评价结果。
