嵌入语言深度感知的汉语作文评分算法
2020-04-24钟启东张景祥
钟启东,张景祥
济南大学 信息科学与工程学院,济南250022
1 引言
作文批改的工作量之巨是一线语文教师深有感触的[1]。而要在大型考试阅卷中保证阅卷教师不产生阅读疲劳且秉持客观公正则更加困难。多数情况下,同一份试卷由同一位阅卷者在不同的时间段多次评阅往往会得到不同的分数。计算机自动阅卷系统应运而生。国外已取得不少成果,其中典型的系统有作文自动评分(PEG)系统[2]和基于隐含语义分析(LSA)的系统[3]等。存在的问题是,基于统计学的系统往往缺乏自然语言处理;基于文本相似性比较的系统往往缺乏语言特性的分析。这些系统和技术很难直接应用于汉语作文阅卷之中。
近年来国内学者也对作文的机器评阅进行了有意义的研究与探索[4]。一些学者借鉴了英语作文自动评分,分析了类似于词汇等级、错别字等浅层语言特征,对作文作者语言特性的感知还不够深入。有鉴于此,有学者针对作文的文采和优美句型做了有益的探讨[5-6]。
本文在对国内语文教育和作文人工评阅分析的基础上,对机器评阅与人工评阅的差异进行了思考,认识到对语感特征的认可是人工评阅优于机器评阅的地方。将语感特征进行量化分析并应用于汉语作文的自动评分中是提升机器评阅质量的有效途径,本文对此做了积极的探讨,提升了对语言的深度感知,实现了比纯粹数理统计更加贴合人类阅卷的评分。
2 语感特征的自动识别
2.1 上下文关联的自动识别
观察高中作文的整体教学过程以及相关语料可以很容易得出结论:优秀作文通常具备段落的首尾呼应或者“总分总”(总写-分写-总写)的作文结构。这类结构可以使得整篇作文中心明确、条理整洁,犹如铿锵有力的演讲将笔者的思想感情完美地展现,使得阅读者明显在语感上更加有层次感和结构性。
虽然不限文体但是考场作文的特性依然使得议论文无论出题倾向还是考生意愿都占据了很大的优势[7]。
从考场统计发现,考生们较少使用临场发挥式的灵感突现等散文性文体,而更倾向于呈现考生本人的素材积累以及文采、论调等议论性文体。
首尾呼应、总分总等作文结构并非议论文的专属,已成为许多作文的得分点。因此对这些作文特征的计量对于计算机自动评分是至关重要的。
首尾呼应一般在文章结构中分为以下两种形式。
(1)总分总结构的首尾呼应
这种形式的结构是非常常见的一种作文结构形式,开篇提出论点(开门见山),中间若干分论点,结尾总括论点(或重申论点,或总结引申)。几个分论点之间可以是并列关系、层递关系、对比关系等等,但不能是包含关系或交叉关系。文章整体的首尾呼应一般体现在作文第一段和最后一段之间的关联性。
以一篇2017 年全国一卷的优秀高考作文为例,它在展示考生语言组织能力的同时也充分表达了构思的逻辑和思想的传递,如图1所示。结构合理的作文会让阅卷老师清晰感受到考生的思路并对作文成绩给出较高评价。该作文第一段和最后一段紧扣主题,阅卷老师很容易对作文的中心进行解读,进而使得全文语感上了一个层次。
(2)段落中的前后呼应
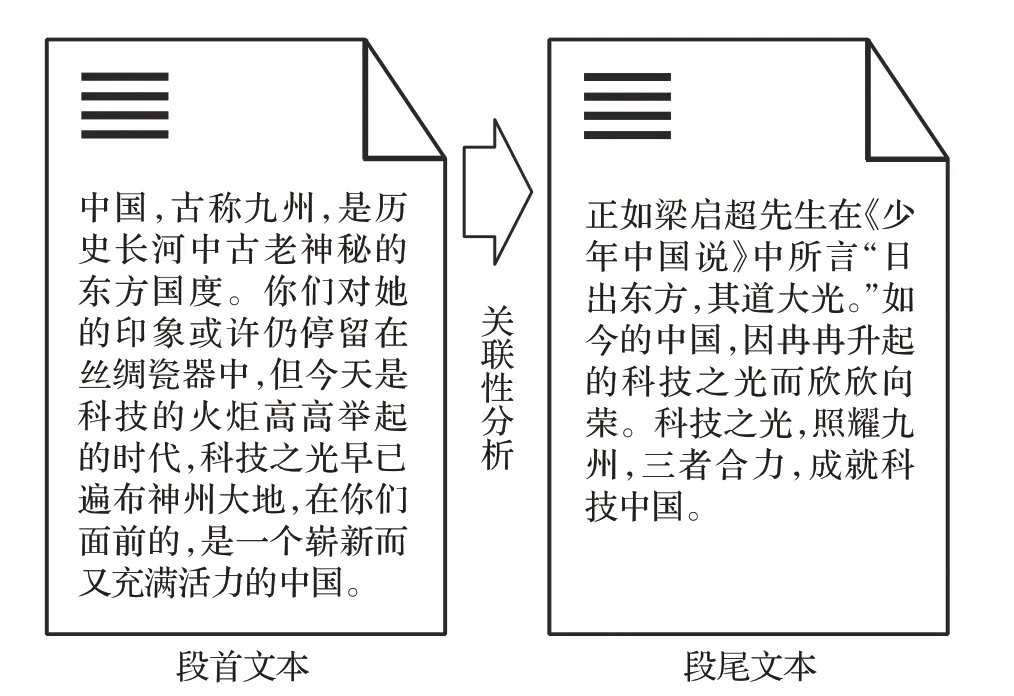
图1 首尾文本关联示意图
除了作文整体的首尾呼应,单独段落中也可能存在前后呼应。这些上下文关联的存在让段落的思想表达更加完整。
图2给出了一则段落中上下文关联的例子,它让全段的强调语气非常明显。这样的结构可视作是考生逻辑思维能力的反映。

图2 段前段尾关联示意图
本文针对这两种形式的上下文关联特征提出技术方法进行自动识别,如图3 所示。该流程在经过分词、分句、段落截取、词性标注等预处理抽取对应各处文本之后进行识别。其流程包括以下步骤。
(1)工整性检验
工整性是对于文章结构的契合度的要求。有些作文属于残篇或者作文结构问题很大的情况就需要进行排除。比如,Paragraph ≤1 的时候,基本可以排除在检测之外;段前段尾的检测需要Sentence ≥2;在进行文本抽取的时候可以用多种方式进行分段,比如“。”“:”“?”等等。
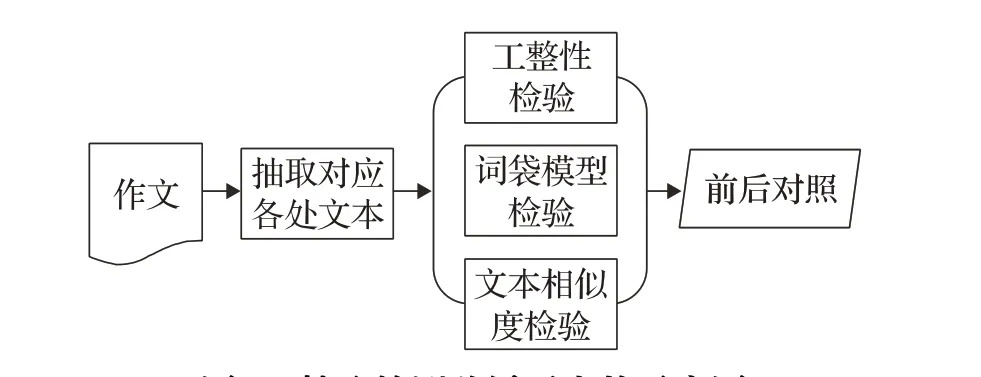
图3 抽取检测首尾呼应的示意图
工整性检验可以降低因作文不齐整性对自动检测的干扰,进一步减少检测过程中可能出现的误判。
(2)词袋模型检验
上下文呼应的一个特征就是主题的一致性,而一致性最直观的表现就是共有关键词。如图2所示,段落开始是对“中国”“速度”的总领而段尾是对“中国”“速度”该意义的进一步阐述。这两个部分都离不开这两个核心关键字。通过构造这样的共有关键字词袋,可以比较准确地判断两者的关联性。
TextRank算法是一种用于文本的基于图的排序算法[8],其基本思想来源于谷歌的PageRank 算法。TextRank算法通过把文本分割成若干句子并进行词性标注,且过滤停用词保留指定词性的词如名词、形容词等组成单元并建立图模型,再利用投票机制对文本中的重要成分进行排序。
使用TextRank算法计算图中各点的得分时,需要给图中的点指定任意的初值并递归计算直到收敛。图中任意一点的误差率小于给定的极限值时就可以达到收敛。
和LDA、HMM等需要大量语料库训练的模型和算法不同,TextRank 不需要事先对多篇文档进行学习训练,它可以仅利用单篇文档本身的信息即可实现关键词提取、文摘。
(3)文本相似性的检测
文本相似度计算在许多领域有着广泛的应用,如信息检索、数据挖掘、机器翻译、文档复制查重检测等。在上下文关联的检测中,进行文本相似度计算也是很重要的支持技术。它可进一步将词袋模型中略过的信息进行确认。
文本相似度计算方法有很多种,如余弦相似度、欧氏距离、jaccard距离、编辑距离等[9-10]。根据不同的作文评阅环境可以选用不同的计算方案。
对短文本来说,本文经比较后发现文本余弦相似度效果相对来说更理想且处理起来也相对简便。这也是本文系统中采用的模型。
2.2 非流畅语句的自动识别
语感,即对使用语言既定用法的敏感性,是对语言用法的有效性或合适性的感觉,也是特定的文化背景的人对其语言产生的微妙因果关联[11]。
语感是一个有着显著文化、本土化特征的词语。显然,特定语言的特定文本的流畅性与之有着不可分割的密切联系。
人们在学习外语时,常会提及语感这个概念。对于作为母语的汉语,人们往往习以为常并不觉察,但它发挥的作用其实比外语更加显著[12],计算机阅卷应该客观地把它考虑进来。
从评分角度来看,语感很大程度表现成既定用法、语句以及语境适用性的指标,似乎比较主观难以量化,这与作文评分的主观性是不谋而合的。事实上,经过量化建模,语感是可以成为衡量语句乃至作文的重要特征的。
语言的流畅性必然包含句子成分的完整性和通顺程度。比如,“在水里游来游去,无数只鱼儿欢快地唱着歌。”这样的句子虽然在口语中不妨碍人们理解其传达的意思,但从书面语的角度看是不通顺的。而作为改进,“无数只鱼儿欢快地唱着歌,在水里游来游去”这样的表述因为句子逻辑的通顺性,使得其可读性更好。因此在对作文表达能力的评分上,流畅性占据的权重是不可忽略的。
计算流畅度的技术流程从分词开始。设经过分词处理后的语句集合为count(w)=w1,w2,…,wn,其中wn是句子分词后第n 个词组。接下来需要判定句子主成分是否缺失,以及是否符合汉语句子的典型句式。
由于汉语句子比较复杂,类似于“疑罪从无”的原则,本文采用的方法是计算不符合句式的“不流畅度”来标定流畅度。例如,经过分词和词性过滤后,如果句子的主要成分是“n(wn-1)v(wn)n(wn+1)v(wn+2)n(wn+3)”,则判定这个句子为不通顺句子。
实例计算存在明显歧义的句子“牧童牵着牛在吃草”,经过计算标识得到的结果也是不通顺句。又例如“钟楼传递着钟声,忽然惊醒了海的酣梦”该句在逗号前的部分经过分词和词性过滤后,也是不通顺句子。但如果改写成“钟楼悠扬的钟声,忽然惊醒了海的酣梦”则系统判定不属于“不通顺句”,即计入通顺句。
在多种这样的规则下,可以将作文的句子粗略分为两组,一组是不完全通顺句子M 组,一组是通顺句子N组,这里就不再赘述。根据下面的公式就可以大致将作文的流畅度也就是表达项中的语言流畅计算出来,这也是通篇文章的阅读语感比较直接的体现,其公式如式(1):

2.3 作文素材的自动识别
作文本质上是考生所学所思的一个综合性展现。它对考生语言材料如成语、谚语、古诗词、歇后语、名言甚至一些时政动态的掌握有一定程度的要求。在不同的场合,它可以被称作作文素材,而在本系统中则被计入语感概念中的个人语言素材。
一篇优秀的考场作文除了对作文本身的题目必须要有相当的领会并且能灵活处理表达关系以外,还应该要表现考生的学识、知识储备甚至时政观念。
近些年的语文作文出题对一些时事热点的倾向尤为明显,比如2017 年高考全国一卷的高考作文的题目就是“外国人眼中的中国关键字”。如果考生对共享单车、长城甚至网购等新事物缺乏必要的了解,那无疑会在作文中难以把握事物的表象以及本质,更难形成令人信服的论点。
在作文中熟练引用各类学识能体现考生阅读广阔而且能对所学的课本知识活学活用。同样的,如果一篇作文有着相当的成语、谚语等作文素材的增色,其阅读语感必然比一般白话文式的作文要优秀得多。
对于大量的诗词、成语等等字符串的自动识别可以使用字符串匹配完成但是效率不高。因为传统的字符串匹配系统是非常简单粗暴的暴力匹配,也就是利用模式串和匹配串之间进行逐个字符进行匹配,如果是失败则模式串位置归0 并滑动一位。这样的模式在有大量的素材进行检索的任务中是非常低效率的。
本系统采用的AC自动机(Aho-Corasick automation)模式匹配是1975 年产生于贝尔实验室的一个算法,可用于多模匹配,提高模式串匹配的效率。使用AC自动机自动检测作文素材的流程如图4所示。
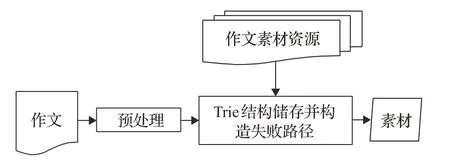
图4 作文素材自动识别流程图
首先将素材预处理,并按Trie 数据结构加以储存,同时构建失败路径(失败指针),最后对长度为m 的匹配串检测n 个模式串是否在其中存在,完成对作文素材的自动识别。
这里以“不可理喻”“美中不足”“不可救药”“不到黄河不死心”这三个成语一个俗语作为例子,其最终形成的AC自动机如图5。
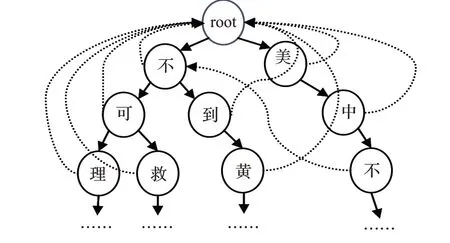
图5 AC自动机结构图
AC自动机在建立了Trie和失败路径的基础上进行检索作文素材在作文中是否存在甚至存在了多少次的速度是相当快的。其查找步骤如下:
(1)从根节点开始查找。
(2)取得匹配串字符,根据该字符选择对应的子树并进入该子树进行检索,如果期间失配则根据失败路径跳跃至有共通前缀的相应节点继续检索。如果该字符没有对应的子树,则查找失败。
(3)重复第二步。
(4)在某个节点,全部字符串被取出,表示查找完成。
在结合类似KMP算法的next数组思想和Trie字典树[13]的构想之后,对于作文这个匹配串就不需要和传统方法一样每一条作文素材都从头开始蛮力匹配。这样可以很好地提升需要识别大量作文素材的任务的识别效率。
3 实验结果和结论分析
3.1 实验系统简介
实验系统使用Java 开发了一个Forecasting 基础模块,在此基础上完成高考语文模拟平台。
计算机无法直接处理原始的作文的文本,必须经过自然语言处理的分词、关键词提取等预处理之后再进行下一步处理。鉴于中科院计算所NLPIR 汉语分词系统相对成熟[14-17],本系统预处理中的分词部分也采用NLPIR接口。
Forecasting 模块对作文的文本长度、段落数量、平均句长、作文实际名词数、平均语句名词数等特征进行了提取,作为系统的基础特征。
3.2 评价方法
本文采用皮尔逊相关系数(Pearson correlation coefficient)、全局准确性、平均误差对作文预测值和人工评分进行比较和评测。
(1)皮尔逊相关系数的计算公式如式(2):

其中,X,Y 分别代表通过本系统得出的预测分数序列和人工阅卷的实际得分序列,cov(X,Y)表示X 和Y 的协方差,σ 表示其序列的标准差。相关系数适用于观察两个序列之间的相关性,其值的范围在-1和1之间,越靠近0 则相关性越低,反之绝对值越大越接近1 则相关性越强。通过皮尔逊系数,得到本系统与人工阅卷的分数相关度。
(2)平均误差(Average Error)可以用式(3)表示:

其中,size 是测试集的大小,Score 是实际得分,Predict是预测得分。
(3)全局准确率(Global Accuracy)可按式(4)计算:

其中,size 是测试集的大小,而CountCorret 指的是预测分数与实际分数的分差必须在阈值之内才为正确。
该设置参考了独特的高考作文评分规则总分双评差值阈限[18],即一篇作文须由两名阅卷老师进行独立评分。如果出现对同一篇作文两人的分数差距过大而且无法统一的情况下则交由阅卷组组长或者质检组(可视为第三位老师)进行第三次评分。
本文采用较高考语文作文更严格的阈值作为预测值,以此模拟阅卷老师和质检组之间的阅卷差异容忍度,并设为全局准确率。
3.3 实验设置、对比与分析
依照新课标高考作文评分标准指导,在基本要求达到的前提下(不离题、字数足够、结构正常等等),全文阅读语感越流畅、蕴含丰富,阅卷老师给的分数就越高。因此,以本文所提出的语感的特征为指导量化的标准,本文设计了一系列特征如表1。实验将把表1所提出的特征加入基础特征之中,考察这些特征对作文的自动评分的影响。

表1 面向作文自动评分的语感特征
这些特征在Forecasting 模块中均进行了实际测试。为确保样本多样性和可靠性,本文收集了38 个题目的作文数据,训练数据和测试数据比例为3∶1,测试结果如表2。
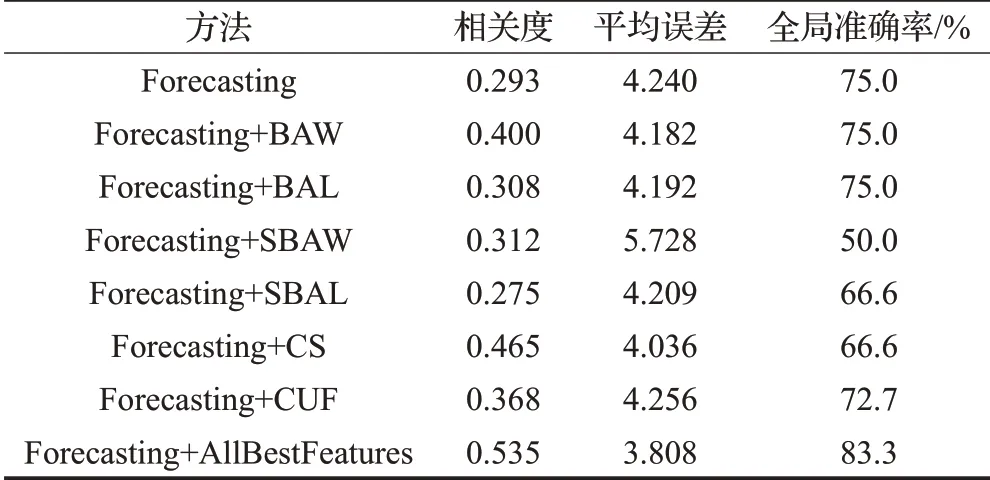
表2 面向作文自动评分的语感特征
结果表明在加入本文提出的语感特征进行语言的深度之后有了一定的提升。单独特征效果最显著的就是作文素材的使用数,相关度比原系统提升了0.172,平均误差降低了0.204。但是,作文符合条件的段落中首尾断句相似度sum 值这个特征表现不佳,相关度比原系统还低0.018,不过平均误差却降低了0.031。这可以理解为单独段落的前后呼应在作文的评分中起到的作用并不明显。
最终融合所有本文所提的语感特征进行语言深度感知之后的作文评分比之前的系统有相当大的提升,相关度比原系统提升了0.242,平均误差降低了0.432,全局准确率也提升到了83.3%。
由于不同文体在本文特征的预测下的表现可能存在差异性,而且本文特征比较着重于议论文的优势评分结构,所以本文格外设置对于议论文与非议论文的对比实验。实验将以Forecasting和AllBestFeatures综合特征进行测试,主要比较平均误差和全局准确性。
从表3中可知,语言深度感知的特征对于有着文章结构明显、平铺直序、着重于知识积累等特点的议论文的分数预测有着比较明显的效果,但是对于其他可能比较讲究抒情和意境的文体效果欠佳。
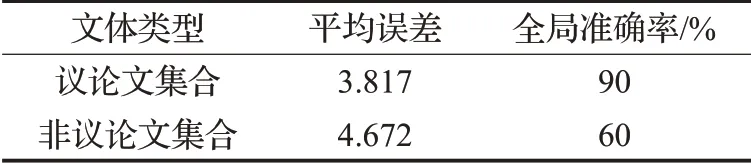
表3 文体实用误差比较
综合表3、表4来看,本文所提出的语言深度感知的作文特征优势在于,特征的独立性较强,不需要大量训练材料进行繁复的模型训练,且覆盖作文评分的层面比较全面,劣势在于评分比较偏向结构性强的文体。
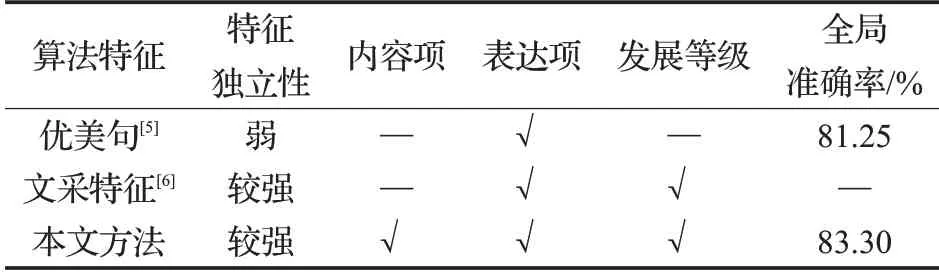
表4 各算法性能比较
4 结语
以人工评分的作文为参考,本文提出的综合前后对照、作文素材、语句流畅等语感特征对于作文自动评分系统有一定的提升作用。但是也存在着一些不足,如指标相较于评分标准来看依然比较少,有些指标效果不算理想,所以也可能会造成如一篇45 分的作文得到51 分这样的较大偏差。
不仅如此,本文所提出的语言深度感知特征在评分上更偏向于议论文这样强调结构的文体,其用于其他文体的阅卷可能会有比较大的偏差。另外,实验所采取的实验数据本身较少,而且比较集中分布于40~52分的区间,这对于作文自动评分的客观性存在一些制约。
但是它依然有一些可取之处:更合理贴合于新课标的评分体系和人工阅卷;覆盖更多指标;量化作文的评分体系;相较于传统的优美句、文采这些的特征走出一条比较新颖的、从语言深度感知出发的尝试之路。
丰富特征体系对积极贴合新课标语文教学的要求、提升作文自动阅卷的准确性是有积极意义的。在未来的工作中,将探索更多对评价作文水平和语言表达能力有意义的方法以更深层次感知语言,提升作文自动评分的精确度以及有效性。
