多协议交叉的HMM协议异常检测算法
2020-04-24吴楚田陈永乐陈俊杰
吴楚田,陈永乐,陈俊杰
太原理工大学 信息与计算机学院,太原030024
1 引言
随着社会和个人安防需求的增长,入侵检测技术在近十年得到了广泛应用和快速发展。入侵检测可以分为误用检测和异常检测[1]。其中,误用检测技术利用攻击数据特征建立攻击行为模型来检测攻击行为。异常检测技术以正常数据为样本建立模型,通过计算观测值的偏离度进行决策,可以检测未知的入侵行为,近年来获得了越来越多的关注。
目前异常检测技术的研究可以分为流量统计[2-3]、用户行为建模[4-5]、协议行为建模[6-9]等方法。其中流量统计方法主要依赖于数值化流量特征来建立统计模型,大多是数字或个人归纳得出,可靠性差。用户行为建模一般按单位时间提取用户访问行为序列来训练行为模型,适用于工作流程较机械化的工控网环境,对于用户多样化的大型网络网络效率较低。协议异常检测是一种新型的异常检测技术,利用协议高度规则化的特性弥补了前面两种方法的不足,近年来得到了诸多关注,其中最常见的方法就是基于马尔科夫链的模式匹配。文献[6]提出用十进制数表示TCP 报文首部的flag 字段以标志TCP 报文,从而得到一系列离散值序列来训练Markov链,任何偏离此模型的都被认为是入侵行为;文献[7]用均值评估法改进了基于Markov 模型的检测;文献[8]将隐马尔可夫模型(Hidden Markov Model,HMM)引入协议异常检测,以隐含状态表示协议行为,证明了基于HMM 的方法比Markov 模型更能准确地描述协议行为并获得了较好的检测率。然而仅用首部标志位的量化值作为观测样本特征的模型描述能力有限,而且还会削弱其他特征的作用(如时间、数据包大小等)。文献[9]则使用协议关键词来描述HMM 的观测序列来扩展样本空间,具有较好的通用性。
现有的协议异常检测方法通常是面向单一协议的建模,仅能检测单一协议的恶意攻击,在涉及多协议交互的网络环境下适用性有限。例如在视频监控网络中,一次会话中会包含SIP 呼叫管理、RTP 实时传输数据两类协议数据流,此外还有RTCP 与ICMP 共同监视连接状况[10]。在这种网络中经常会存在跨协议的攻击,如消息篡改攻击利用SIP协议漏洞来伪造SIP数据包来达到会话劫持、中断会话的目的,以及猜测攻击会未授权地发送带有不同质询响应字段的REGISTER消息,都会同时涉及到SIP 和RTP 两类协议[11]。例如,正常交互中检测到SIP BYE 消息后不会再有RTP 流,而在BYE 攻击过程中攻击者会伪造会话一方发送BYE消息来拆除会话,同时真正的用户仍在发送RTP 消息,在这种情况下如果仅依靠SIP模型进行匹配是无法识别出异常的,只有对两种协议的整体行为进行合理建模才可以实现检测。由此可见,依靠单个协议的模型匹配而忽略协议之间的关联性在涉及多协议的网络环境中很容易造成误判。针对以上问题,提出一种适用于复杂的多协议交互的网络环境的协议交叉检测方法,该方法利用HMM在协议异常检测方面的优势,通过考虑协议报文之间的语义和时序关联实现了协议报文合并算法,使基于HMM的协议异常检测的准确率得到提高,最后利用传输层数据辅助分析以降低误报率。
2 算法框架
由于现有的关于HMM 协议异常检测的研究都是根据各类协议数据包分别建立相应的HMM,然后根据分离出的不同协议的观测序列分别计算检测结果,这样做缺乏对协议间的关联性的考虑,不适用于复杂的多协议交互的网络环境。本文提出的协议异常检测方法,将在同一会话中出现的多类协议进行建模(如SIP与RTP)使用正常交互下的协议数据流作为样本来实现异常检测。具体的算法流程实现如图1所示,主要包括模型构建和异常检测两部分。
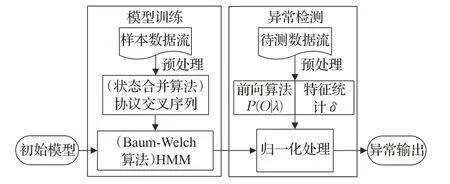
图1 交叉协议异常检测算法框架设计
要实现协议异常检测,首先要对协议行为进行建模:通过对样本数据流进行协议分类,以关键字为属性表示为可观测状态,使用状态合并算法通过时间标记寻找协议间的关联,经过对单个协议报文序列进行合并、衔接、去除循环等操作之后,得到多协议交叉的HMM,从而提高模型的处理效率和检测率;之后的异常检测过程需要使用Baum-Welch算法估算模型参数得到交叉协议模型后,将待检测的网络流量经过预处理后提取出协议数据和少量特征,经过前向算法计算样本与模型的偏离程度,并与报文特征两种指标进行归一化处理,将计算结果作为判断依据决定是否为攻击行为。
3 协议交叉模型
为判别多类型的协议数据流是否存在异常,首先需要建立一个协议交叉模型,本章讲述协议交叉模型的建立方法。从HMM协议异常检测的原理(3.1节)出发;首先通过构建协议报文(3.2节)实现对样本数据流的分类与序列化处理;然后提出协议报文合并算法(3.3节),为协议报文序列建立语义与时序关联,经过合并、衔接、去除循环等一系列操作后,得到精简的可观测状态集;最后经过协议交叉模型的初始化和一系列训练过程(3.4节),得到一个多协议交叉的HMM,用于协议异常行为的检测。
3.1 传统的HMM异常检测
HMM是一个能够用参数表示随机过程统计特性的概率模型,它包含隐藏和观测两种状态,其中隐藏状态间的转移是间接地通过观测序列来描述的[12],HMM 的状态变迁如图2 所示。任何一个HMM 都可以定义为λ={A,B,π},其中包含五个元素:
(1)隐含状态S:模型中允许出现的有限状态有N个,隐藏状态集合可表示为S={S1,S2,…,SN},它们满足Markov性质但是无法直接观测到。
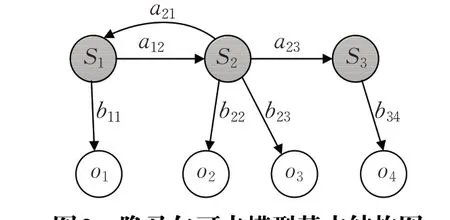
图2 隐马尔可夫模型基本结构图
(2)观测状态O:模型中可见观测变量个数为M ,则观测状态集合可表示为O={o1,o2,…,oM},可观测状态与隐含状态不是一一相关。
(3)初始状态分布概率π :表示隐含状态在初始时刻t 时的概率分布矩阵π={πi},其中πi=P(qt=Si),其中qt表示t 时刻模型所处的隐藏状态,qt∈S,πi≥0,
(4)隐含状态转移概率矩阵A:描述隐含状态之间的转移概率,用N×N 的矩阵A={aij}表示,其中aij=
(5)观测状态转移矩阵B:表示隐藏状态下取得所有观测矩阵的概率分布B={bij},其中bij=P(oi|Si),1 ≤i ≤N,1 ≤j ≤M 。
在应用于协议异常检测的HMM中,由网络流量得到的协议报文序列经过处理可视为观测序列,而隐藏在这些流量背后的协议行为则为不可见的状态转移序列,即隐含状态。利用HMM 可解决两类常见问题:一种是模型参数λ 未知,通过调整参数使观测状态序列{o1,o2,…,oM}的概率尽可能大,来反推模型参数;另一种是给定的可观测状态序列{o1,o2,…,oM}和模型λ={A,B,π},它通过计算O 可能出现的概率检测结果与已知模型是否吻合。将HMM 映射到协议异常检测问题中,Baum-Welch 重估算法可以根据从网络流量中提取的观测样本序列解决第一类问题,即通过量化正常的网络流量训练出完整的HMM模型;再通过向前算法计算待检测样本序列的出现概率解决第二类问题,判断协议行为是否不符合正常行为轮廓,从而得出异常。
3.2 协议报文序列构建
现有的HMM 协议异常检测方法将标志位量化后作为观测样本,对模型进行训练,这种方法会造成观测值样本空间有限,不能满足多样的协议行为描述需求。网络流量可以看作由不同类型的协议报文组成,而协议规范定义了每个报文类型,所以协议的语义关键词可以用来表示不同的报文类型[13]。本文选用语义关键词和时间标记来描述协议报文,即报文p=(t,k);其中,k 是唯一标志报文类型的特定字符串,如SIP中的关键字可以是INVITE、INFO、CANCEL等请求命令码和180、200、403等响应状态码;t 是该报文的截获时间,单位为s。
以往的基于HMM 的协议异常检测方法都是根据需求文档(Request For Comments,RFC)或实际实现对不同协议单独建模的,本文为实现交叉验证的HMM考虑了协议报文的语义先后顺序。因此,需要采集协议在实际实现中的协议数据报文作为样本数据,这里假设训练集是完备的,即用于训练的协议数据报文可以覆盖到协议交互的所有行为。具体的构建步骤如图3 所示。首先,根据RFC文档中的关键字,使用基于正则表达式的动态协议识别方法[14]分离出不同协议的数据流量,并依次设置协议名s;通过WinDump 工具从报文中提取各个协议报文的语义关键词k;接着为后续实现序列合并,对各个协议样本序列进行协议类型标记,将协议报文表示为p=(t,k,s)。最终,可以得到一系列具有语义特征和时序标记的协议报文序列,即L={p1,p2,…,pn}。
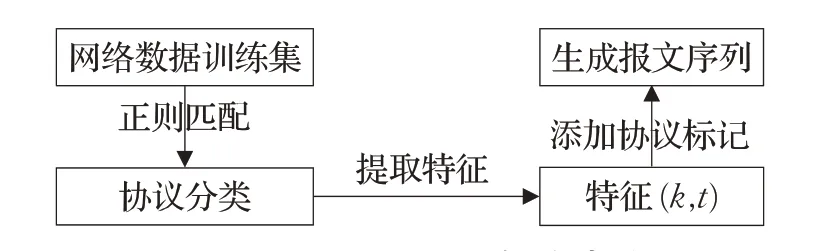
图3 协议报文序列构建步骤
3.3 协议报文序列合并
考虑到协议间的关联,本文提出基于语义和时序关联的协议报文序列合并算法,以实现对多个协议报文序列进行合并、衔接、去除循环等操作,从而得到针对不同协议报文合并化的可观测序列,并根据该序列训练得到协议交叉的HMM进行多协议攻击的异常检测。
通过上一节的协议报文序列构建得到带有时间标记的不同协议的报文序列Li。正常的协议交互行为都是按照协议规范进行通信的,它们从开始按照规范运作直至结束,有一定的先后关系,即协议报文序列满足一定的时序关系。因此,通过时间标记t 确认合并的先后顺序,并把要合并的序列Li的报文p 进行衔接,生成一个新序列LT。另一方面,为减少HMM 中的状态空间并考虑到协议间的依赖关系,设置一个时间窗ω=0.1 s,将LT中s 值不同但包的前后间隔不超过ω 的报文pi中的关键字进行合并,记为ot,合并后的新序列为O={ot}。此外,由于协议交互过程中可能出现的一些重复交互动作而产生重复的子序列会影响HMM 训练过程中状态转移概率的计算,为保证对主要序列的准确建模,报文序列的合并过程有必要对协议报文中的重复子序列进行删减序。一般情况下,长度为n 的母序列为O={o1,o2,…,on} ,子序列为C={or,or+1,…,or+m-1} ,其中m <n。在这里以一次交互为单位将子序列长度设置为2,并用δi记录子序列Ci的最大重复数,在后期判断异常时使用。具体算法描述如下所示。
算法1 协议报文序列交叉缩减算法
输入:报文序列L={p1,p2,…,pn},其中pi=(t,k,s)。
输出:精简后的协议交叉报文序列O={o1,o2,…,oM},子序列的最大重复数δ。
1. List LT=New List(L1,L2)
2. LT.sortedBy(pi.t)
3. for (i=0;i <LT.length-1;i++)
4. if (pi+1-pi.t <w&&pi+1.s!=pi.s) do{
5. LT.add(new Tuple2(pi,pi+1)).delete(piand pi+1)}
6. end for
7. for (i=1;i <LT.length-1;i++)
8. δi=1
9. Ci= ||oi,oi+1
10. for (j=1;j <LT.length/2,j++)
11. while |oi+2j,oi+2j+1|==Ci//搜索相同子序列
12. delete |oi+2j,oi+2j+1|//删除重复子序列
13. δi++,Update Stemp//更新序列
14. end while
15. end for
16. end for
17. δ=max(δi)
18. O=Stemp
通过算法1,可以获得合并且精简后的协议交叉报文序列O={o1,o2,…,oM},将该序列作为HMM 的观测状态序列用来训练交叉协议的HMM 模型。该算法对多协议组合建模的思想适用于涉及网络协议较多的网络环境,如VoIP网络、视频会议等。
3.4 协议交叉模型构建
训练HMM模型的主要任务是通过观测序列o1,o2,…,oM直接计算模型参数。首先,根据协议异常检测的需求对HMM模型λ={A,B,π}的参数进行初始化:
(1)初始状态空间S 应包含两个状态数,用0 表示正常状态,1表示异常状态,即S={0,1}。
(2)初始分布π 表示完全正常的情况下,初始时刻的数据包正常的概率为1,即π={0,1}。
(3)状态转移矩阵A 表示协议行为中正常态转正常态、异常态转正常态的概率均为1,即
(4)可观测状态O={o1,o2,…,oM},oi=(ki),M 为可观测值的总数,k 为协议关键字。
(5)观测状态转移矩阵B={bij}表示在正常或异常状态下不同观测值oi出现的概率,在异常状态下的概率采用均匀分布,在正常状态下的概率需要根据协议的不同设置相应的值。
确定了初始参数λ(0)={A(0),B(0),π(0)}后,本文采用Baum-Welch重估算法来实现模型参数的估算。该算法利用前向概率αt(i)和后向概率βt(i)计算符合观测序列O 出现概率的数学期望,再通过期望值迭代更新参数使之不断逼近最优解。其中,观测序列o1,o2,…,oT的出现概率可以根据前向变量得到:

由于Baum-Welch 算法在迭代过程中,αt(i)和βt(i)的递推会涉及到多次相乘,随着t 的增加,递推值会越来越小,导致下溢问题。避免浮点数下溢,本文设置一个比例系数将每次的迭代结果放大,每次迭代结束后,再把比例系数取消,继续下一次迭代。处理方法如下:


通过比较前后两代参数下观测序列o1,o2,…,oT的概率,根据式(4)判断参数训练是否达到收敛:
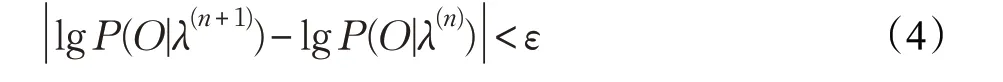
若计算结果满足式(4),则表示上一次参数评估的结果与此次差异小于某个阈值(如0.05),意味着模型收敛可以停止计算,输出模型参数。使用训练好的模型参数通过前向算法则可实现异常检测的模型匹配过程,通过计算观测序列概率P(O|λ)来匹配相应的模型,检测算法的计算复杂度为O=(N2T),其中N 为模型中的可观测状态数,T 为待观测序列长度,由此可见模型中的状态数对模型的效率有很大的影响。假设单个协议建模过程中每个协议平均会产生长度为N 的可观测状态集,若需合并建模的协议有m 个,那么多协议建模会产生m×N 个状态数,因此检测复杂度会以m2倍增长。而算法1通过删除重复子序列、合并短时内协议连续序列等操作可以缩减协议模型中的可观测状态数,利用第5章的多组交互样本证明算法1的缩减效率可以达到6~10 倍,由此可见m ≤3 时,整个检测算法的检测速率仍能和单协议建模检测持平并有机会在m=2 的时候有所突破,足够满足多数情况。
4 异常检测
异常检测过程中,首先需要对待检测数据流进行预处理操作,处理结果作为观测序列并依据已建立的模型计算出现概率P ,结合序列化过程中统计的特征δ 作为影响异常判断的两个指标,通过归一化处理得到异常程度D,确定阈值后可用于判断异常行为。
4.1 检测指标计算
首先根据协议报文序列构建(3.2 节)、协议报文序列合并(3.3 节)对SIP 和RTP 的待检测数据流进行预处理,得到合并后的观测序列O={o1,o2,…,oM}并统计报文特征δi。
在正常的协议交互过程中,某些行为是有限重复的,即子序列重复数应该保持在一个正常的范围内,例如一些端口探测、Flooding攻击则是重复多次地进行一种协议行为,因此被检测的观测序列中子序列重复数小于等于δi才能视为正常。本文利用正常模型的子序列最大重复数δ={δi}来体现序列的一个特征,并要求待检测序列的子序列C′j={P′j,P′j+1}的重复数δ′i<δ,同样,也为最大重复数特征计算偏差值D1j=δ′i-δ。
对于基于HMM 的协议交叉检测模型λ,利用前向算法计算每个需要检验的观测序列的概率P( )O|λ,P 越小说明偏离模型的可能性越大,是异常行为的可能性就越大。由于本文选择对正常行为建模,因此需要为正常行为序列的出现概率设置下限K 。由于前向算法中只有对有相同长度的观测序列计算概率才有效,因此,为保证不同长度的观测序列具有可比性,本文采用滑动窗口算法,依文献[8]的最佳实验结果将窗口长度w 取值为6,通过计算长度为w 的子序列q 的概率得到整个观测序列的概率P=min P(q|λ),而K 则设置为所有可能出现的正常短序列的最小概率值,即K=min lg P(l|λ),其中l 为观测序列O 中的一个连接[15]。为后续结合其他特征,放弃直接比较的方法,设计一个新的统计量D2表示计算观测序列与HMM 协议模型的偏差,即D2j=Pj-Kj。
4.2 异常判断
利用子序列重复数δ 可以帮助识别HMM 模型不能检测的异常,并且统计过程包含在构建序列内,并未造成计算负担。因此,本文采用最大重复数δ 和观测序列的概率P 两个指标来判断异常,利用极差变换法对两个指标的偏差值进行归一化处理,其中D1属于正向指标,取:
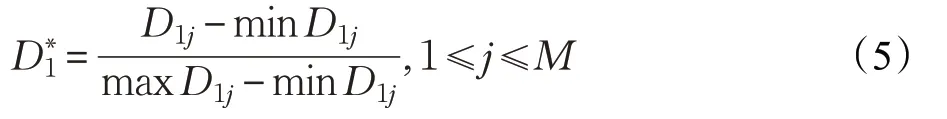
对于逆向指标D2,则取:
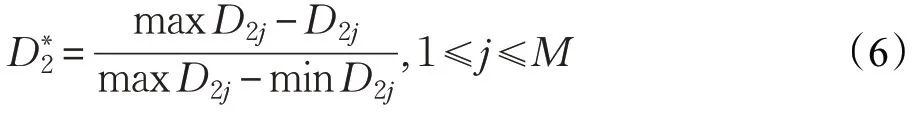
经过极差变换后,指标值在0~1之间,越靠近0说明异常的可能性越大。本文将两个指标加权求和得到判断指标:

最后通过预先设置好的阈值ψ 来判断异常,如果D <ψ,则属于异常行为。其中,通过改变权值θ 和阈值ψ 的大小可得到不同的检测率。
5 实验评估
为了验证本文提出的检测模型,在实验室下搭建了视频监控网络的通信环境,包含一个交换机、接入24台摄像头、两台NVR,摄像头与NVR之间进行视频传输业务,流量大小在450~600 Mb/s。将正常交互行为下获取的网络数据中的主要通信协议SIP 与RTP 提取出来作为模型的训练数据集。检测数据集来源于中科院信息工程研究所研发的鹰眼平台,这是一款对目标设备进行漏洞扫描和验证的视频监控系统安全测评工具,其中包含了诸多恶意攻击脚本和漏洞验证脚本。在实施模拟攻击之前,对该工具中涉及到实验内容的脚本按攻击种类进行了标记,包含消息篡改、缓冲区溢出、DDos攻击、重放攻击、猜测破解5大类恶意脚本。通过鹰眼平台执行标记后的攻击脚本,将产生的应用层异常交互信息作为检测数据集,对本文的协议交叉检测方法进行性能检测。然后将只要涉及到RTP 的脚本标记为RTP 下的攻击,涉及到SIP的脚本即标记为SIP下的攻击,这样协议标记间是存在重叠样本的,分开标记可以方便后续对单协议建模方法进行性能检测,用来与多协议交叉建模方法进行对比。整体检测数据集的内容如表1。
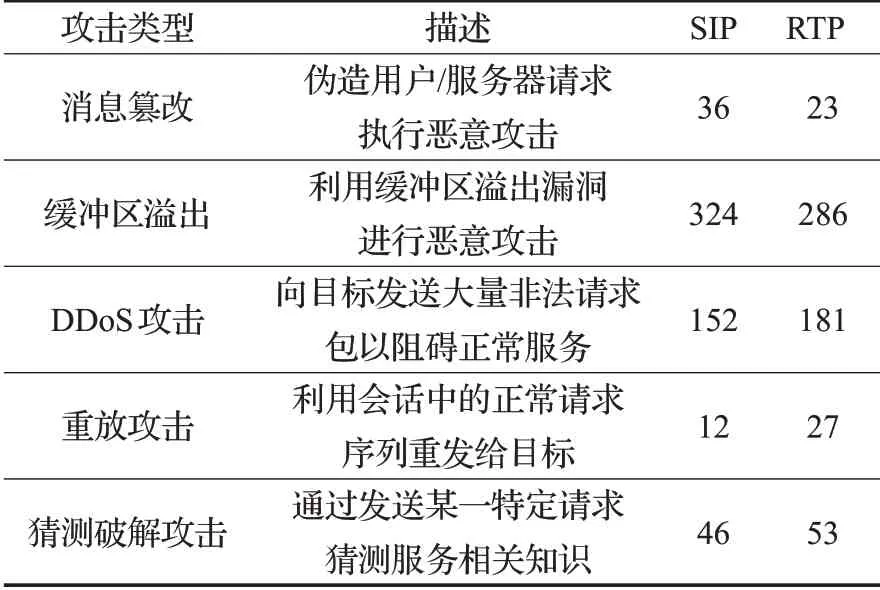
表1 用于检测的攻击数据的攻击数目
5.1 参数训练
为验证检测算法在上述环境的有效性,需要通过状态合并算法和Baum-Welch 算法为SIP 和RTP 训练好协议交叉的HMM。在算法的参数评估过程中,主要通过对式(7)中的权值θ 和阈值ψ 进行调整来获得最优的检测率。首先,计算指标时为获得最优的加权比例,分别记录了正常数据流和异常数据流下θ 从0~1 时D 值的平均值,计算结果如图4。当θ=0.6 时,正常数据流和异常数据流的Dˉ相差最大,说明此时分类效果最为明显。
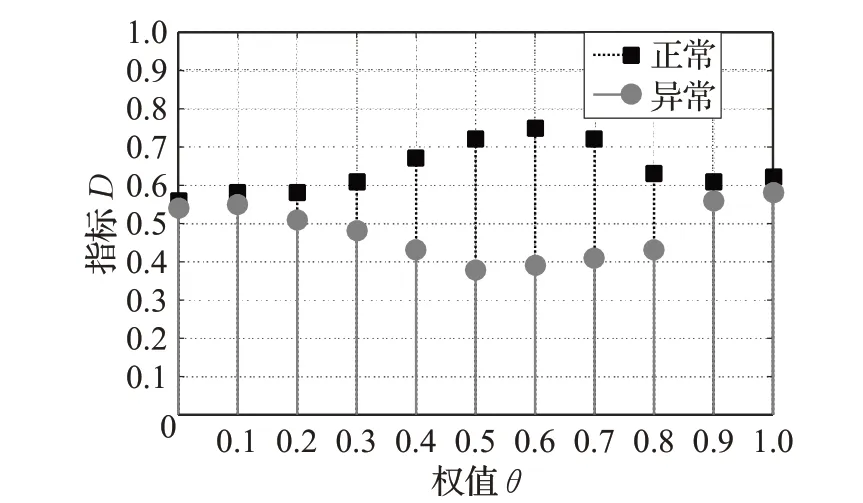
图4 正常与异常数据流下D 与权值的关系
然后,以0.6作为最优权值,通过调整检测阈值ψ 来获取最优的检测率,检测结果如图5所示。根据实验结果可知,当ψ=0.42 时,误报率和漏报率能够维持在一个较为理想的区间。因此,本文将模型中的权值θ 设置为0.6,阈值ψ 设置为0.42,并将该协议交叉HMM用于后续的性能比较。
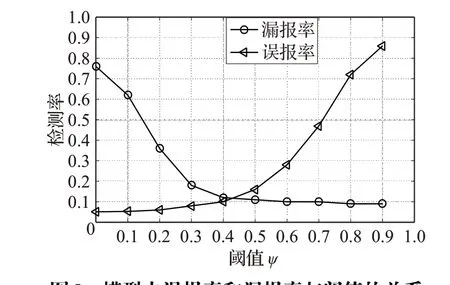
图5 模型中误报率和漏报率与阈值的关系
5.2 检测性能评估
利用以上实验数据对文献[7]中基于头部标示数值化属性训练的HMM以及文献[9]中以关键字、频率为状态属性训练的HMM的检测方法进行模拟,与本文的协议交叉模型(Protocol-cross HMM,简称Pc)进行性能方面的比较。表2给出以上三种检测方法针对SIP和RTP协议在不同类型攻击下的综合检测率。
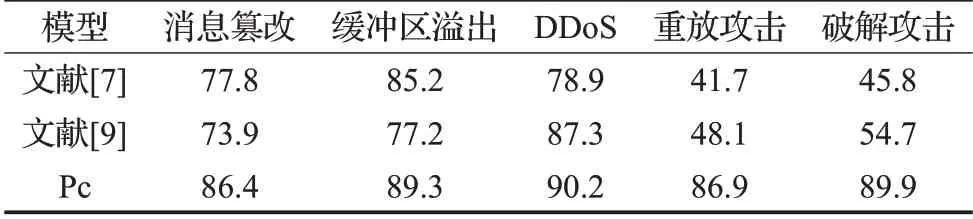
表2 三种检测方法在不同攻击行为下的检测率 %
由实验结果可见,本文提出的检测方法对SIP和RTP协议的攻击检测的准确率均高于文献[7,9]的检测方法:
(1)由于前两种检测方法根据标示位或关键词建立协议报文序列建立HMM,而未考虑协议报文间的时序与语义关联,因此对DDoS、消息篡改等需要多包完成或涉及多协议的攻击行为下,会产生较高的漏报率、误报率。
(2)同时Pc 检测方法对后两类攻击行为的检测率有显著提高,这是因为本文在不改变计算复杂度的同时添加了第二个检测指标——子序列重复数δ,该指标对于存在大量循环操作的攻击行为具有进一步的校验作用,如端口扫描、重放攻击等。
此外,还将文献[9]中对SIP、RTP 两类协议建立的HMM单独拿出来与Pc方法的两类协议交叉HMM的检测性能进行比较,分别标记为SIP、RTP、SIP&RTP 三种模型,结果如图6所示。
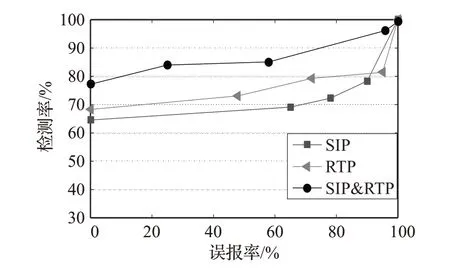
图6 三种模型的检测性能
由图6的实验结果可见,本文提出的协议交叉检测方法对攻击的检测性能略高于两个协议独立建模的检测方法。同时,在实验过程中有超过122个攻击样本未在两类协议的单独模型中识别,却在本文提出的新模型检测算法中检测到,由此可见,该检测方法的漏报率低,即检测覆盖率有所提升。以上均证明协议交叉检测方法优化了对以往只面向单一协议攻击的协议异常检测方法。因此,协议交叉检测方法对于具有多协议协作的网络环境有较好的检测能力。
6 总结
本文采用协议异常交叉验证的思想,考虑了协议报文的时间和语义关联,提出了协议报文合并算法应用于HMM 的协议行为建模,因此提高了此类模型对协议异常的检测能力,并在模型建立的过程中统计数据特征“子序列重复数”检验循环操作类攻击来提高检测方法的覆盖率。该检测方法不仅可以对协议异常进行有效检测,而且对泛洪攻击、端口扫描等攻击也具有较好的检测效果。此外,本文算法在合并协议数量不超过3类时可达到较好的检测速率,适用于多协议交互的网络环境,如VoIP网络、视频会议系统等。由于建模过程依赖对正常协议数据的采集质量,一些采集过程艰难的协议数据(例如只能靠RFC的数据)在建模方面有较大难度。
