彩色图像多尺度引导的深度图像超分辨率重建
2020-04-23于淑侠胡良梅张旭东付绪文
于淑侠,胡良梅,张旭东,付绪文
彩色图像多尺度引导的深度图像超分辨率重建
于淑侠*,胡良梅,张旭东,付绪文
合肥工业大学计算机与信息学院,安徽 合肥 230601
为获得更优的深度图像超分辨率重建结果,本文构建了彩色图像多尺度引导深度图像超分辨率重建卷积神经网络。该网络使用多尺度融合方法实现高分辨率(HR)彩色图像特征对低分辨率(LR)深度图像特征的引导,有益于恢复图像细节信息。在对LR深度图像提取特征的过程中,构建了多感受野残差块(MRFRB)提取并融合不同感受野下的特征,然后将每一个MRFRB输出的特征连接、融合,得到全局融合特征。最后,通过亚像素卷积层和全局融合特征,得到HR深度图像。实验结果表明,该算法得到的超分辨率图像缓解了边缘失真和伪影问题,有较好的视觉效果。
深度图像;超分辨率重建;卷积神经网络;多尺度引导;多感受野特征
1 引 言
近年来,随着计算机视觉领域对场景深度信息的需求不断扩大,高分辨率深度图像的获取变得至关重要。然而,由于传感器等硬件条件的限制,由深度相机得到的深度图像分辨率普遍不高,很难满足实际应用需求[1-3]。例如PMD Camcube相机分辨率只有200´200[4],微软的Kinect相机分辨率也只有640´480[5]。如果通过提高硬件设施来提高深度图像的分辨率,成本将会很高,并且也存在一些很难克服的技术难题,因此通常通过软件处理的方法提高深度图像分辨率。
目前深度图像超分辨率重建问题,根据是否加入高分辨率(high resolution,HR)彩色图像作为引导,可以分为:1) 仅用低分辨率(low resolution,LR)深度图像超分辨率重建,2) HR彩色图像引导LR深度图像超分辨率重建。许多学者对仅用LR深度图像超分辨率重建的问题展开了研究[6-10]。Mandal等[6]提出了一种可以基于图像噪声级别自适应的鲁棒超分辨重建算法。Aodha等[7]使用基于图像块的多感受块(multiple receptive block,MRB)模型对LR深度图进行进行超分辨率重建。Li等[8]通过添加自相似结构的几何约束来扩展文献[7]中的模型框架。Xie等[9]提出了一种新的框架,首先重建深度图像的边缘图,然后重建HR深度图。Chen等[10]提出了一种利用卷积神经网络实现单幅深度图像超分辨率重建的方法,首先利用卷积神经网络获得HR深度图像边缘图,然后用HR深度图像边缘图引导LR深度图像超分辨率重建。在该类方法中,由于输入网络的LR深度图像包含高频信息很少且没有同场景HR彩色图像作为引导,所以由此类方法得到的重建图像通常在边缘部分不是很理想。
同场景的HR彩色图像与LR深度图像包含相对应的关系,使用同场景HR彩色图像引导LR深度图像超分辨率重建有利于LR深度图像恢复高频信息,因此在对LR深度图像进行超分辨率重建时,通常会使用同场景彩色图像引导[11-16]。Liu等[11]提出了一种基于HR彩色图像引导的LR深度图像超分辨率重建鲁棒优化框架。Kiechle等[12]提出了一种双模共稀疏模型重建LR深度图像。Li等[13]将基本的引导插值问题转化为一个分层的全局优化框架,然后对LR深度图像进行重建。Park等[14]在马尔科夫模型中加入了非局部平均项,使重建图像更加可靠。Li等[15]提出了一种深层次的端到端深度图像超分辨率重建卷积神经网络,提升了重建性能,但是该网络提取的特征单一。Xiao等[16]通过两个金字塔式子网络提取LR深度图像和HR彩色图像特征。以上提到的关于HR彩色图像引导LR深度图像超分辨率重建的卷积神经网络,虽然重建效果相对较优,但是仍然存在一些问题,在使用彩色图像引导时,使用了单尺度引导,不利于对图像精细结构的恢复;在网络的每一层只提取了单一感受野特征,没有充分提取图像特征。
针对以上问题,本文构建了彩色图像多尺度引导深度图像超分辨率重建卷积神经网络。在不同的尺度上,该网络可以在HR彩色图像分支中学习到丰富的HR特征,将其作为相对应尺度上深度图像分支中特征的补充,这种多尺度引导结构有益于恢复图像细节信息。在LR深度图像分支,首先构建了多感受野残差块(multiple receptive field residual block,MRFRB),该结构能提取并融合不同感受野下的特征,然后将每一个MRFRB输出的特征连接、融合,从而得到全局融合特征。最后,通过亚像素卷积层和融合后的特征,重建HR深度图像。综上,本文采用彩色图像特征多尺度引导深度图像重建有益于对细节信息的恢复;本文构建的MRFRB可以提取不同感受野下的特征,有益于图像结构信息的重建。
2 理论推导
为有效提高深度图像分辨率,本文构建了彩色图像多尺度引导深度图像超分辨率重建卷积神经网络。该网络包含三个分支:彩色图像分支、深度图像分支、图像重建分支。由于LR深度图像包含较少高频信息,同场景的HR彩色图像包含较多与其相关的高频信息,因此可以通过同场景HR彩色图像引导LR深度图像超分辨率重建以获得更优的重建结果。由于图像中不同的结构信息具有不同的尺度,因此在彩色图像分支,本文提取了不同尺度下的彩色图像特征,用以引导相对应尺度的深度图像重建。对于深度图像超分辨率重建问题来说,输入的LR深度图像与输出的HR深度图像是高度相关的,如果能充分提取LR深度图像的特征,将会得到更优的重建结果。因此在深度图像分支中,本文构建了MRFRB,该结构可以提取并融合不同感受野下的特征,然后将每一个MRFRB输出的特征连接、融合,从而得到全局融合特征。在图像重建分支中,通过亚像素卷积和全局融合特征重建HR深度图像。
2.1 网络概述
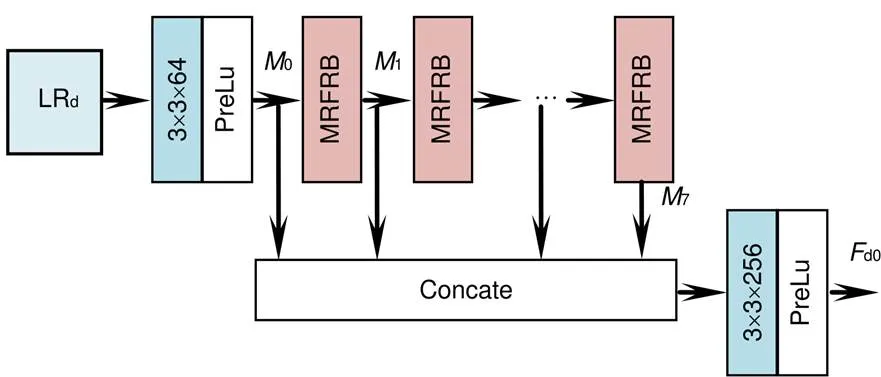
本文构建的整体网络架构如图1所示。假设超分辨率重建倍数为2,那么彩色图像分支总共有4-1层;在深度图像分支,除去深度图像特征提取(deep image feature extract,DIFE)部分总共有4层,包含个亚像素卷积层、个连接层、2个卷积层。在本文框架中设超分辨率重建倍数为4。
在彩色图像分支中,所有的卷积层卷积核大小均为3´3,步长为1,输出特征图个数为64,卷积过程中不改变特征图大小。HR彩色图像用HRc表示,假设HRc的大小为4´4。输入的HRc首先经过三个卷积层,得到c1,c1大小为4´4,包含64张特征图。c1经过池化核大小为2´2,步长为2的池化层,得到c。具体过程如下:
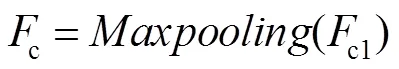
式中:表示最大池化,c的大小2´2,c经过三个卷积层,得到c2。c2大小为2´2,包含64张特征图。至此,该网络在彩色图像分支提取了尺度不同的特征c1、c2,用于在不同尺度下引导深度图像超分辨率重建。
在深度图像分支中,LR深度图像用LRd表示,其大小´。LRd经过深度图像特征提取块(deep image feature extract block,DIFE)得到d0,d0的大小与LRd相同,包含256张特征图。经过亚像素卷积层得到d1。具体过程如下:
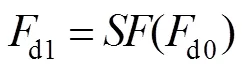
式中:表示亚像素卷积操作,超分辨率重建倍数为2,d1的大小为2´2,因此d1包含64张特征图,进而将由深度图像提取的特征d1与彩色图像提取的特征c2进行连接操作,得到d2。具体过程如下:
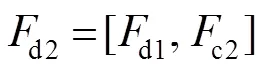
式中:表示亚像素卷积操作,超分辨率重建倍数为2,d4的大小为4´4,因此d4包含64张特征图,进而将d4与c1进行连接操作,得到d5。具体过程如下:
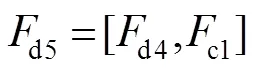
在图像重建分支中,LR深度图像首先经过一个卷积核大小为3´3,步长为1,输出特征图个数为16的卷积层,特征图的大小为´(该层卷积层输出特征图的个数与超分辨率重建倍数相关,假设超分辨率重建倍数为,则该层输出特征图个数为2)。然后经过亚像素卷积层得到d,其大小为4´4。具体过程如下:
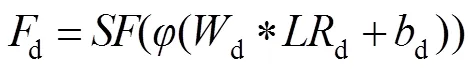
式中:表示激活函数,d和d分别表示卷积核和偏置,“*”表示卷积操作,表示亚像素卷积,这里的超分辨率重建倍数即为期望的超分辨率重建倍数,因为该网络是以超分辨率重建倍数4为例,所以这里取为4。
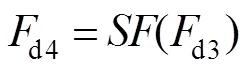
假设最终得到的HR深度图像用HRd表示,具体过程如下:
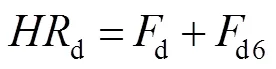
式中:“+”表示元素级相加操作,即两幅图片对应元素相加。
2.2 深度图像特征提取块
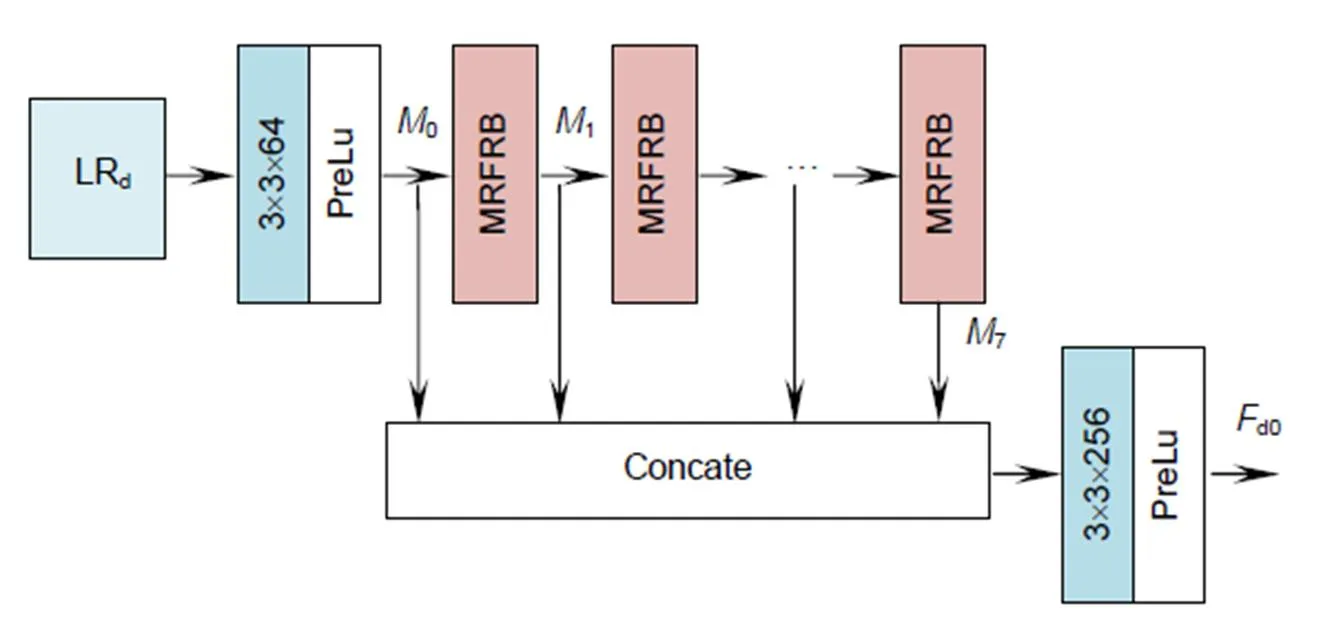
在对深度图像提取特征时,本文直接将LR深度图像LRd输入网络,这样使得后续的DIFE过程都是在LR空间下进行,降低了计算复杂度,同时使网络可以提取图像的原始特征信息。该部分网络结构如图2所示,包含两部分:多层次特征融合和MRFRB。对于深度图像超分辨率重建问题来说,输入网络的LR深度图像所包含的信息是最可靠的,因此为了充分挖掘LR深度图像的特征,本文构建了MRFRB,该结构可以提取不同感受野下的特征,并将其融合。然后使用多层次特征融合,将各个MRFRB块所提取的特征进行融合,得到全局融合特征。
2.2.1 多层次特征融合
为了能充分利用每个MRFRB块所提取的特征,本文将各个MRFRB块所提取的特征进行连接操作。具体过程如下:
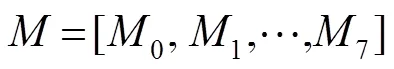
式中:[0,1,¼,7]表示对0、1、¼、7特征的连接操作,表示连接后的特征。因为0、1、¼、7各包含64个特征图,因此包含512张特征图。这512张特征图会包含一定的冗余信息,为了去除这些冗余信息、降低计算复杂度,将输入一个卷积核大小为3´3,步长为1,输出特征图个数为256的卷积层,得到全局融合特征d0。具体过程如下:
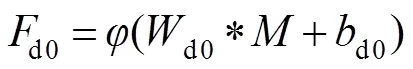
式中:表示激活函数,d0和d0分别表示卷积核和偏置,“*”表示卷积操作。
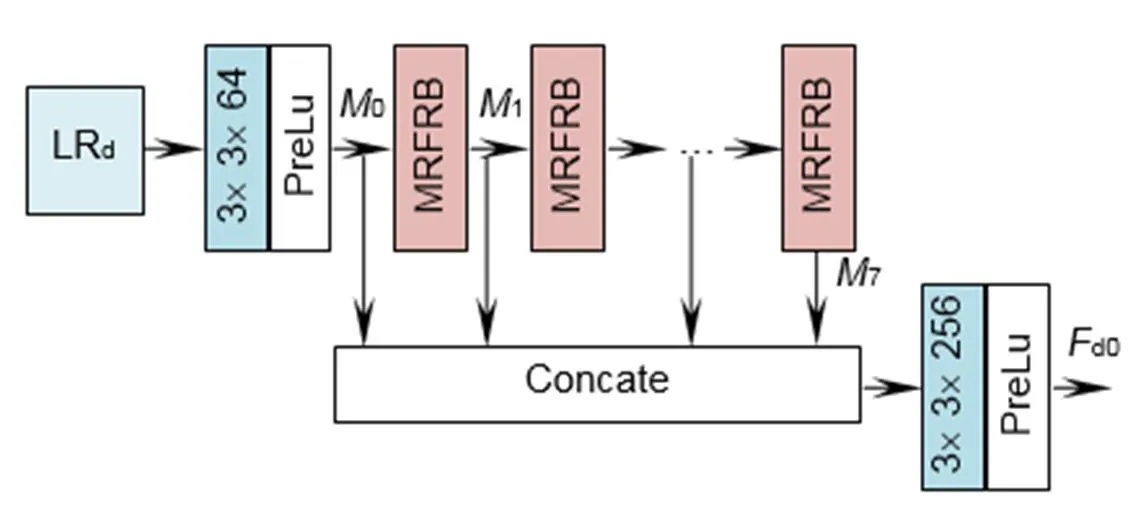
图2 深度图特征提取块
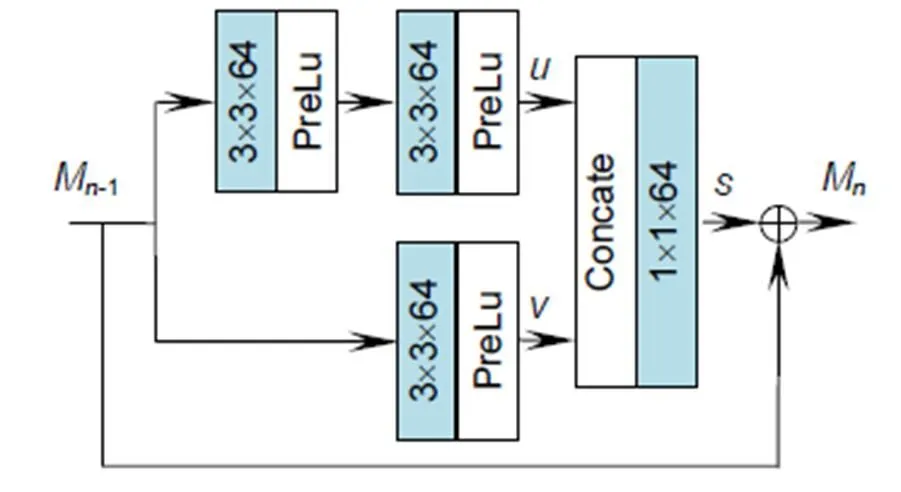
图3 多感受野残差块
2.2.2 多层次特征融合多感受野残差块(MRFRB)
对于深度图像超分辨率重建问题来说,输入的LR深度图像与输出的HR深度图像是高度相关的,因此如果能充分挖掘LR深度图像的特征信息,将会得到更优的重建结果。本文构建了MRFRB,如图3所示,该结构能提取不同感受野下的特征并将其融合,MRFRB使用了双支路,在支路一使用两个卷积核大小为3´3,步长为1,输出特征图个数为64的卷积层,因此在上面的支路输出是感受野为5´5的特征,支路二使用一个卷积核大小为3´3,步长为1,输出特征图个数为64的卷积层,因此下面的支路输出是感受野为3´3的特征。具体过程如下:
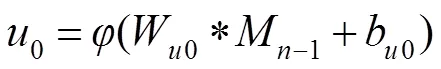
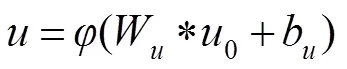
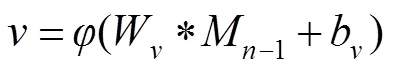
式中:表示激活函数,和分别表示卷积核和偏置,“*”表示卷积操作,、分别为感受野为5´5、3´3的特征。
对两个支路得到的特征、进行连接操作,、连接之后具有128个特征图,为了保证MRFRB块输入输出特征图数目相同,将、连接之后的特征图输入卷积核大小为1´1,步长为1,输出特征图个数为64的卷积层。即为不同感受野特征融合之后的特征。具体过程如下:
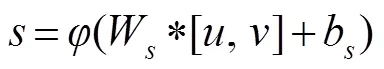
为了提高网络性能,本文在该部分使用了残差连接,具体过程如下:
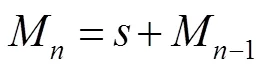
式中:M-1和M分别表示MRFRB块的输入和输出,表示所提取的特征。
2.3 网络训练
本文基于反向传播的随机梯度下降法[17]训练网络,使用均方误差(mean-square error, MSE)作为损失函数,则:
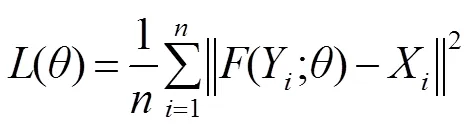
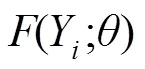
3 实验结果与分析
3.1 实验设置
本文实验的PC配置为 NVIDIA Titan X、RAM 16 G、Linux 64位操作系统,训练测试通过Tensorflow实现。
本文使用的训练数据集包含4部分,分别是Middlebury[18]、RGBZ[19]和RGBD[20]、ICL-NUIM[21]。Middlebury数据集包含丰富的HR深度信息,图像的边缘清晰,是目前验证超分辨率重建算法优劣常用的数据集,从Middlebury数据集随机选取了52个场景。RGBZ和RGBD数据集是TOF拍摄的真实场景深度图像,从RGBD和RGBZ数据集随机选取了10个场景。ICL-NUIM数据集包含丰富的HR深度信息,从中随机选取了65个场景。为了充分利用这些深度图像,本文对图像进行了旋转90°,180°,270°之后再对所有的图像进行水平镜像,最终得到1016个场景的图片。在每个训练批次中,当超分辨率重建倍数为2或4时,从1016个场景中随机剪裁大小为64×64的4个场景的图像块进行训练。每个epoch迭代100次。当超分辨率重建倍数为8时,考虑到图像本身的大小,调整图形块的大小为32×32。本文通过双三次下采样来获得LR的训练图像。
网络参数:本文使用He等[22]的方法初始化卷积层,所有的卷积层后使用激活函数PreLu。网络的初始学习率被设置为5×10-4,每15个epoch学习率下降2倍,直到学习率小于5×10-9。
评价指标:本文用均方根误差(root mean squared error,RMSE)和结构相似度指数(structural similarity Index,SSIM)作为评价指标。RMSE是MSE的算术平方根,数值越小,表明重构图像质量越好。SSIM是指两幅图像之间的结构信息相似程度,SSIM值越接近1,表明重建深度图与原始图像越接近,重建效果越好。
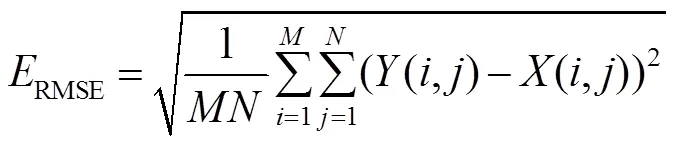
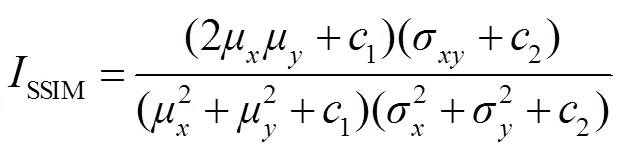
式中:´是重建的HR图像的大小,代表参考图像,和分别表示参考图像的灰度平均值和方差,和分别表示重建的HR图像的灰度平均值和方差,是参考图像与重建HR图像的协方差,1和2是防止分母为0的常数。
3.2 彩色图像对重建结果的影响
本小节对有无彩色图像引导对实验结果的影响进行了实验分析,构建了无彩色图像引导卷积神经网络(去除了本章所构建网络中的彩色图像分支,网络的其他结构均无变化)如图4所示,在下文中用without color表示此结构。
图5为有无彩色图像引导在Middlebury数据集上的实验结果的定性比较,放大倍数为4。图5(a)为真值图像;图5(b)为文献[6]的重建结果,由局部放大图可知其存在边缘模糊的问题;图5(c)为无彩色引导的重建结果,由局部放大图可知其在边缘存在伪影问题;图5(d)为本章方法重建结果,由局部放大图可知,本章方法在边缘部分重建效果较好,验证了彩色图像的引导有益于重建性能的提升。
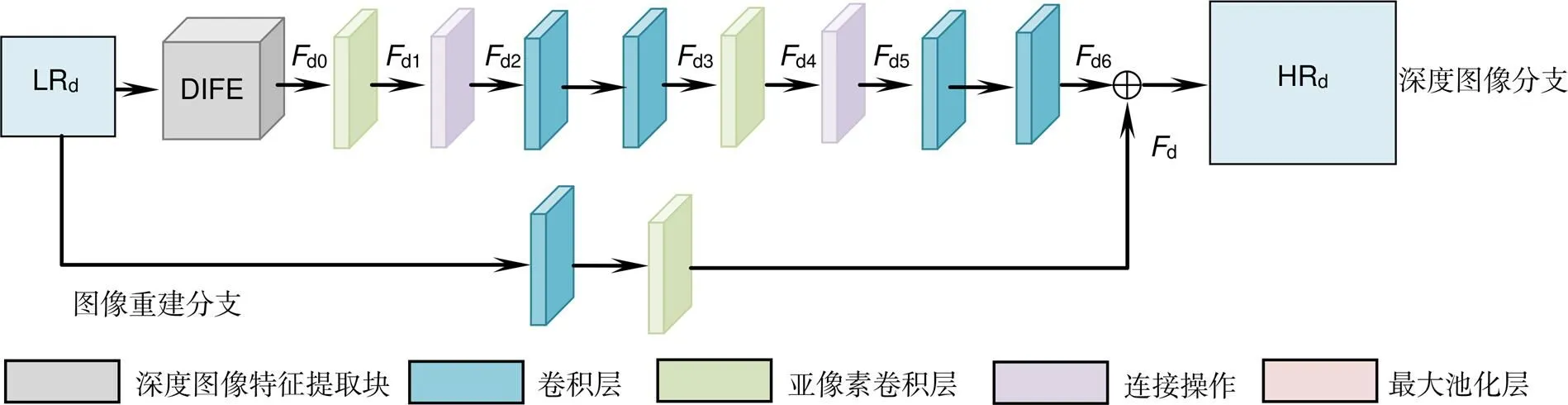
图4 无彩色图像引导网络结构

图5 有无彩色图像引导在Middlebury数据集上的实验结果的定性比较。(a) 真值图像;(b) 文献[6]方法;(c) 无彩色图引导;(d) 本文方法
表1给出了有无彩色图像引导在Middlebury数据集上的实验结果的定量比较,放大倍数为4。从实验结果的定量比较分析可知,加入彩色图像的引导有助于重建结果的提升。与未加入彩色图像引导结果做比较,加入彩色图像引导的结果RMSE平均降低约0.02,SSIM平均增加约0.0001。
综上,从定性和定量两个方面分析结果可知,加入彩色图像作为引导有助于重建性能的提升。
3.3 与其他方法的比较
Middlebury数据集为标准的深度图像数据集,也是目前验证深度图像超分辨率重建算法优劣最常用的数据集,在Middlebury数据集上评估了本文提出的方法。由于篇幅限制,本文将实验的图像分为了A、B两组。对比的方法包括代表性的算法:双三次插值,Mandal[6]、Chen[10]、Liu[11]、Kiechle[12]、Li[13]、Park[14]、Dong[23]、Hui[24]、Kim[25]、Lai[26]。其中Chen[10]的定量结果引自文献[10],Dong[23]和Hui[24]的定量结果引自文献[24]。
在Middlebury数据集上采用RMSE、SSIM指标分别评估了本文的方法,实验结果如表2~5所示。表2、3分别是不同的方法在Middlebury数据集A、B重建结果的RMSE定量分析,由表2、3可知,本文算法均优于传统算法(Mandal[6]、Liu[11]、Kiechle[12]、Li[13]、Park[14]),和基于深度学习的算法(Chen[10]、Dong[23]、Hui[24]、Kim[25]、Lai[26])相比,取得了11个最优值,4个次优值。表4和表5分别是不同的方法在Middlebury数据集A、B重建结果的SSIM定量分析,由表4和表5可知,本文算法取得了14个最优值,1个次优值。和次优结果相比,本文的RMSE指数平均降低了约0.083,降低比例约5.87%。SSIM指数平均增加了约0.0011。
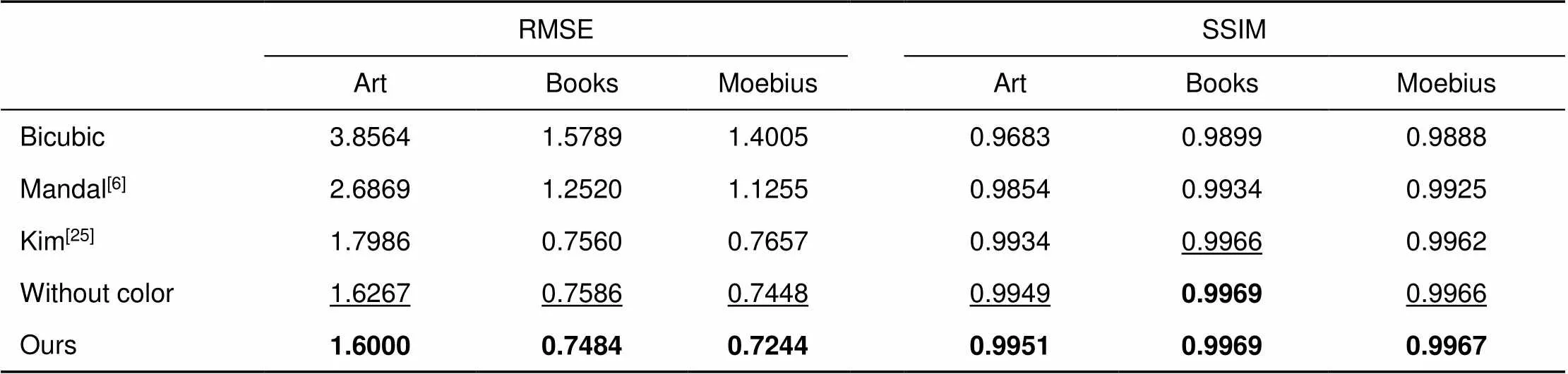
表1 有无彩色图像引导在Middlebury数据集上的实验结果的定量比较
注:粗体字表示最优值,下划线标识次优值。
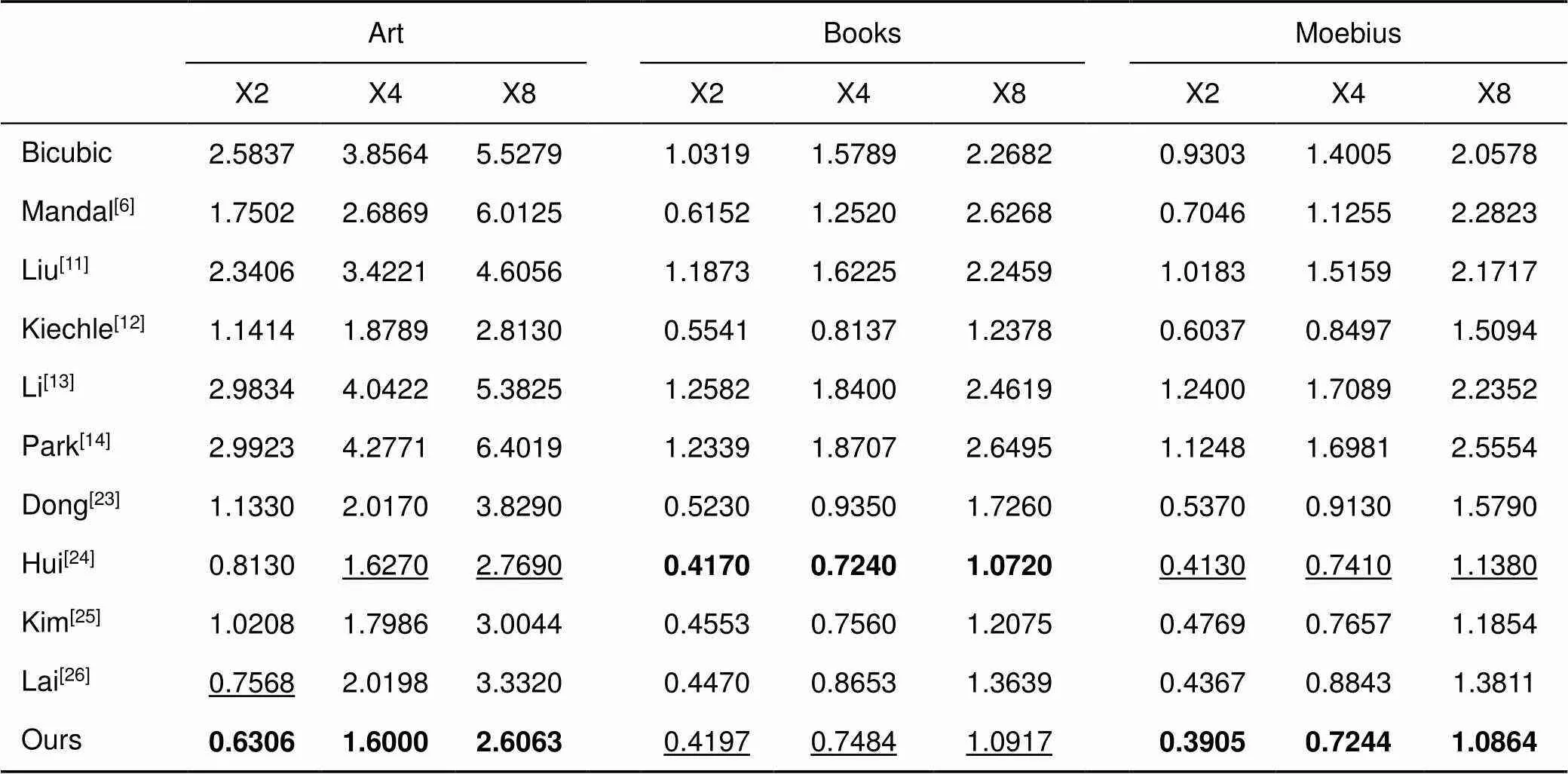
表2 不同的方法在Middlebury数据集A上重建结果的定量分析(RMSE)
注:粗体字表示最优值,下划线标识次优值。
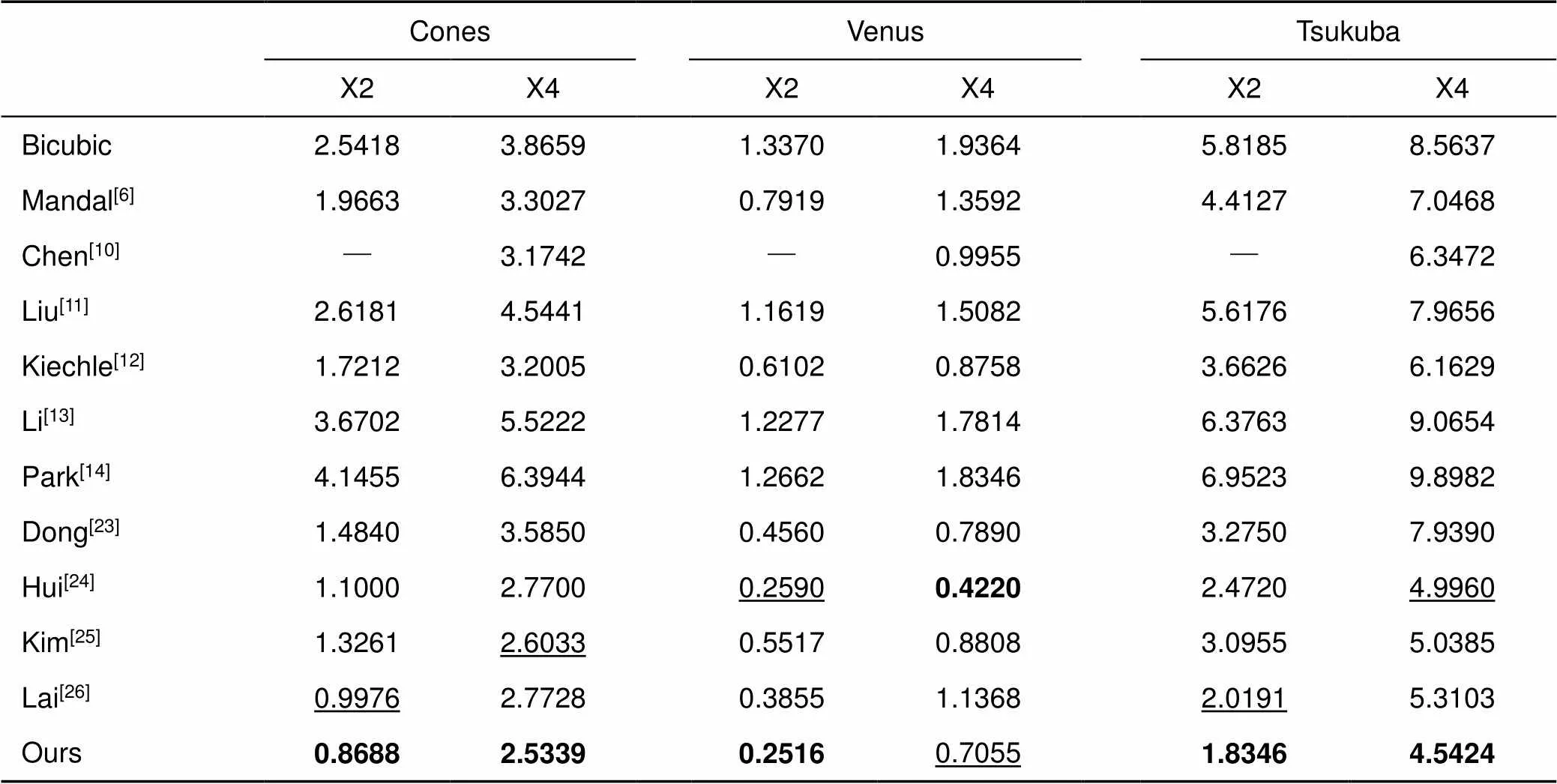
表3 不同的方法在Middlebury数据集B上重建结果的定量分析(RMSE)
注:粗体字表示最优值,下划线标识次优值。
图6是当超分辨率重建倍数为8时本文方法和其他方法在Middlebury数据集上的重构结果图像对比,红色矩形区域对应局部放大区域。从图6(b)、6(c)可以看出,Liu[11]和Li[13]两种方法在边缘处出现模糊的问题。Kim[25]需要用双三次插值进行预处理,并且在网络每一层只提取了单感受野特征,从图6(d)可以看出,该方法得到的超分辨率重建结果在边缘有伪影问题。从图6(e)可以看出,本文重建的深度图具有较好的视觉效果,接近真实值,有效地缓解了边缘失真和伪影的问题,因为本文的网络使用多尺度引导的方法重建图像,提取多感受野特征。
4 结 论
针对深度图像分辨率低的问题,本文构建了一种彩色图像多尺度引导深度图像超分辨率重建卷积神经网络。在彩色图像分支,该网络可以提取不同尺度下的彩色图像特征,用以引导相对应尺度的深度图像重建。在深度图像分支,构建的MRFRB块可以提取并融合不同感受野下的特征。实验结果表明,本文方法得到的重建图像,从定性和定量两个方面均取得了较优的结果。接下来的工作考虑通过构建更优的网络结构,从而得到更优的重建结果。
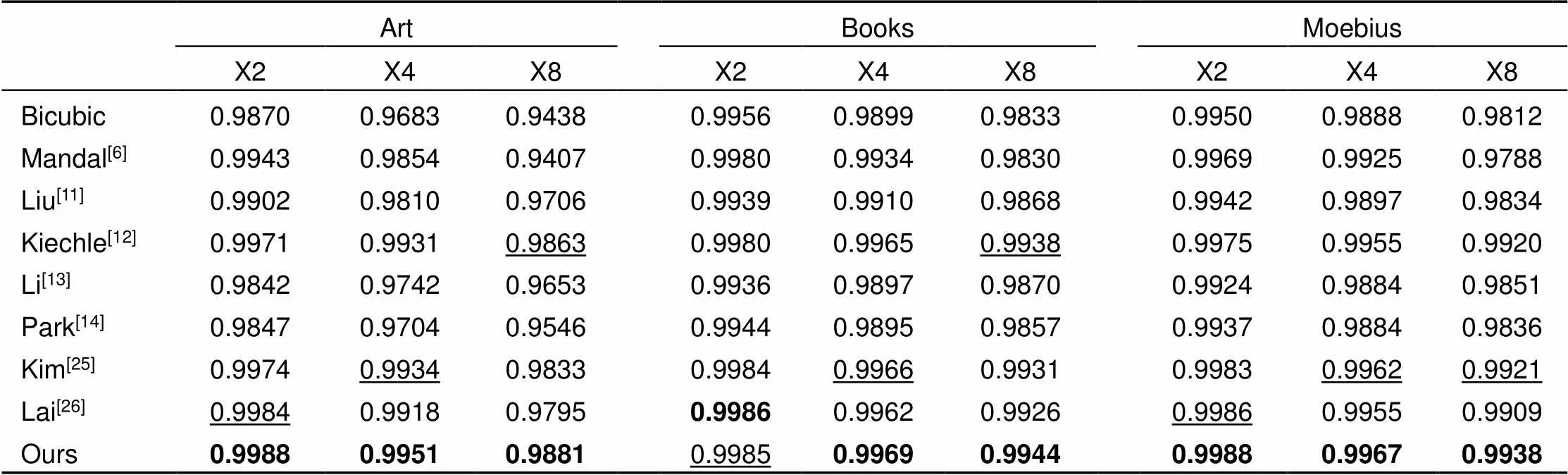
表4 不同的方法在Middlebury数据集A上重建结果的定量分析(SSIM)
注:粗体字表示最优值,下划线标识次优值。
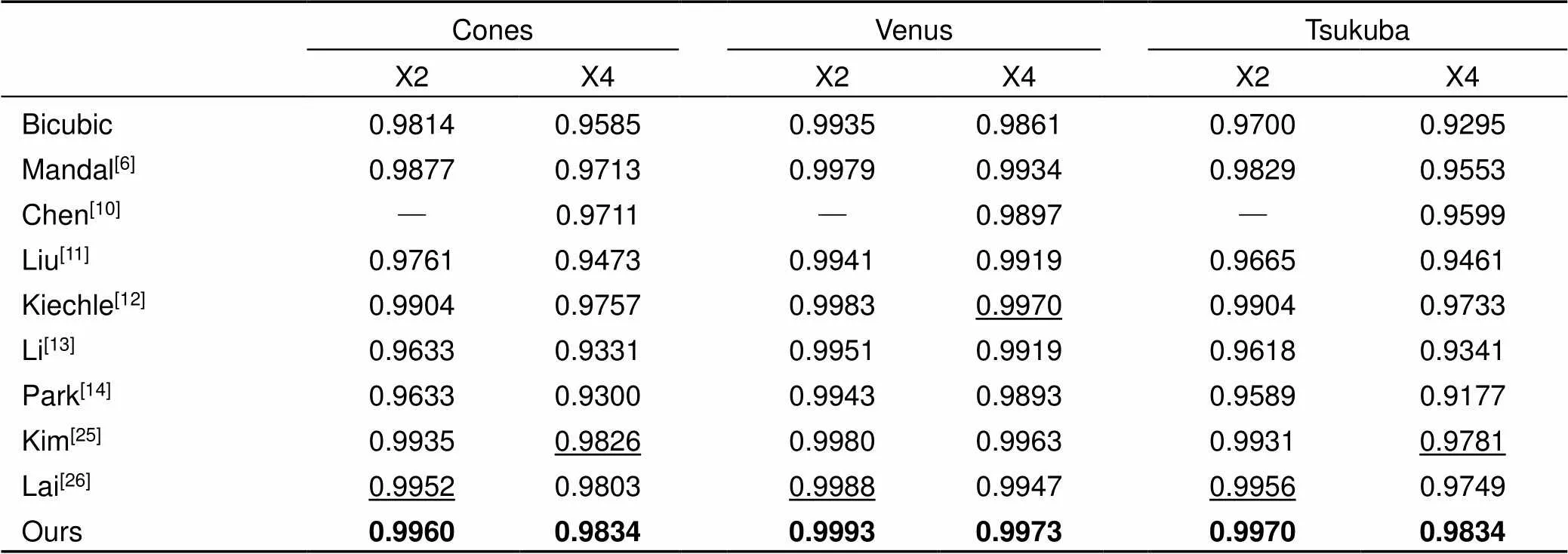
表5 不同的方法在Middlebury数据集B上重建结果的定量分析(SSIM)
注:粗体字表示最优值,下划线标识次优值。
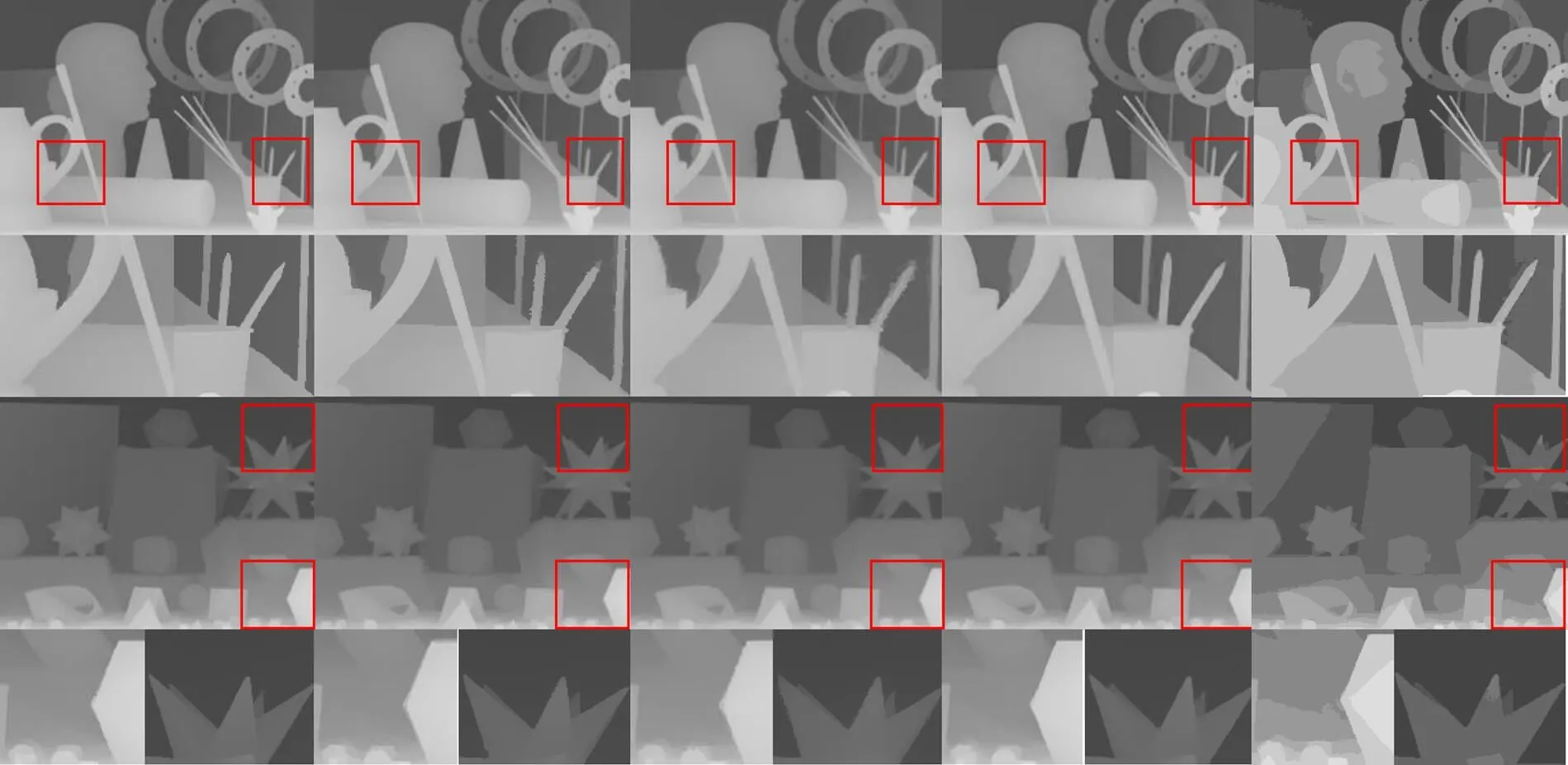
图6 不同方法在Middlebury数据集上的超分辨率重建结果。(a) 真值图像;(b) 文献[11]方法;(c) 文献[13]方法;(d) 文献[25]方法;(e) 本文方法
[1] Palacios J M, Sagüés C, Montijano E,. Human-computer interaction based on hand gestures using RGB-D sensors[J]., 2013, 13(9): 11842–11860.
[2] Nguyen T N, Huynh H H, Meunier J. 3D reconstruction with time-of-flight depth camera and multiple mirrors[J]., 2018, 6: 38106–38114.
[3] Yamamoto S. Development of inspection robot for nuclear power plant[C]//, Nice, France, 1992: 1559‒1566.
[4] Kolb A, Barth E, Koch R,. Time-of-flight cameras in computer graphics[J]., 2010, 29(1): 141–159.
[5] Xie J, Feris R S, Yu S S,. Joint super resolution and denoising from a single depth image[J]., 2015, 17(9): 1525–1537.
[6] Mandal S, Bhavsar A, Sao A K. Noise adaptive super-resolution from single image via non-local mean and sparse representation[J]., 2017, 132: 134–149.
[7] Aodha O M, Campbell N D F, Nair A,. Patch based synthesis for single depth image super-resolution[C]//, Florence, Italy, 2012: 71–84.
[8] Li J, Lu Z C, Zeng G,. Similarity-aware patchwork assembly for depth image super-resolution[C]//, Columbus, OH, USA, 2014: 3374–3381.
[9] Xie J, Feris R S, Sun M T. Edge-guided single depth image super resolution[J]., 2016, 25(1): 428–438.
[10] Chen B L, Jung C. Single depth image super-resolution using convolutional neural networks[C]//, Calgary, AB, Canada, 2018: 1473–1477.
[11] Liu W, Chen X G, Yang J,. Robust color guided depth map restoration[J]., 2017, 26(1): 315–327.
[12] Kiechle M, Hawe S, Kleinsteuber M. A joint intensity and depth co-sparse analysis model for depth map super-resolution[C]//,Sydney, NSW, Australia, 2013: 1545–1552.
[13] Li Y, Min D B, Do M N,. Fast guided global interpolation for depth and motion[C]//Amsterdam, The Netherlands, 2016: 717–733.
[14] Park J, Kim H, Tai Y W,. High quality depth map upsampling for 3D-tof cameras[C]//, Barcelona, Spain, 2011: 1623–1630.
[15] Li W, Zhang X D. Depth image super-resolution reconstruction based on convolution neural network[J]., 2017, 31(12): 1918–1928.
李伟, 张旭东. 基于卷积神经网络的深度图像超分辨率重建方法[J]. 电子测量与仪器学报, 2017, 31(12): 1918–1928.
[16] Xiao Y, Cao X, Zhu X Y,. Joint convolutional neural pyramid for depth map super-resolution[Z]. arXiv:1801.00968, 2018.
[17] Lecun Y, Bottou L, Bengio Y,. Gradient-based learning applied to document recognition[J]., 1998, 86(11): 2278–2324.
[18] Scharstein D, Szeliski R, Zabih R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[C]//, Kauai, HI, USA, 2001: 131–140.
[19] Richardt C, Stoll C, Dodgson N A,. Coherent spatiotemporal filtering, upsampling and rendering of rgbz videos[J]., 2012, 31(2): 247–256.
[20] Lu S, Ren X F, Liu F. Depth enhancement via low-rank matrix completion[C]//, Columbus, OH, USA, 2014: 3390–3397.
[21] Handa A, Whelan T, McDonald J,. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM[C]//, Hong Kong, China, 2014: 1524–1531.
[22] He K M, Zhang X Y, Ren S Q,. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification[C]//, Santiago, Chile, 2015: 1026–1034.
[23] Dong C, Loy C C, He K M,. Image super-resolution using deep convolutional networks[J]., 2016, 38(2): 295–307.
[24] Hui T W, Loy C C, Tang X O. Depth map super-resolution by deep multi-scale guidance[C]//, Amsterdam, The Netherlands, 2016: 353–369.
[25] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//, Las Vegas, NV, USA, 2016: 1646–1654.
[26] Lai W S, Huang J B, Ahuja N,. Deep Laplacian pyramid networks for fast and accurate super-resolution[C]//, Honolulu, HI, USA, 2017: 624–632.
Color image multi-scale guided depth image super-resolution reconstruction
Yu Shuxia*, Hu Liangmei, Zhang Xudong, Fu Xuwen
School of Computer and Information, Hefei University of Technology, Hefei, Anhui 230601, China
Feature extraction block of depth map
Overview:In recent years, as the demand for depth information in the field of computer vision has expanded, the acquisition of high-resolution depth images has become crucial. However, due to the limitations of hardware conditions such as sensors, the depth image resolution obtained by the depth camera is generally not high, and it is difficult to meet the practical application requirements. For example, the PMD Camcube camera has a resolution of only 200´200, and Microsoft's Kinect camera has a resolution of only 640´480. If the resolution of the depth image is increased by improving the hardware facilities, the cost will increase, and there are some technical problems that are difficult to overcome, so the depth image resolution is usually improved by a software processing method. In order to obtain better super-resolution reconstruction results of depth images, this paper constructs a multi-scale color image guidance depth image super-resolution reconstruction convolutional neural network. The network consists of three branches: a color image branch, a depth image branch, and an image reconstruction branch. The relationship between high resolution (HR) color image and low resolution (LR) depth image of the same scene is corresponding. Super-resolution reconstruction of LR depth image guided by HR color image of the same scene is conducive to restoring high-frequency information of LR depth image. So the LR depth image super-resolution reconstruction can be guided by the same scene HR color image to obtain more excellent reconstruction results. Because different structural information in the image has different scales, so the multi-scale fusion method is used to realize the guidance of HR color image features to LR depth image features, which is beneficial to the restoration of image details. For the depth image super-resolution reconstruction problem, the input LR depth image is highly correlated with the output HR depth image, so if the features of the LR depth image can be fully extracted, a better reconstruction result will be obtained. Thus in the process of extracting features from LR depth images, this paper constructs a multi-receptive residual block to extract and fuse the features of different receptive fields, and then connect and fuse the features of each multiple receptive field residual block output to obtain global fusion features. Finally, the HR depth image is obtained through sub-pixel convolution layer and global fusion features. The experimental results on different data sets show that the super-resolution image obtained by this algorithm can alleviate the problem of edge distortion and artifacts, and has better visual effect.
Citation: Yu S X, Hu L M, Zhang X D,. Color image multi-scale guided depth image super-resolution reconstruction[J]., 2020,47(4): 190260
Color image multi-scale guided depth image super-resolution reconstruction
Yu Shuxia*, Hu Liangmei, Zhang Xudong, Fu Xuwen
School of Computer and Information, Hefei University of Technology, Hefei, Anhui 230601, China
In order to obtain better super-resolution reconstruction results of depth images, this paper constructs a multi-scale color image guidance depth image super-resolution reconstruction convolutional neural network. In this paper, the multi-scale fusion method is used to realize the guidance of high resolution (HR) color image features to low resolution (LR) depth image features, which is beneficial to the restoration of image details. In the process of extracting features from LR depth images, a multiple receptive field residual block (MRFRB) is constructed to extract and fuse the features of different receptive fields, and then connect and fuse the features of each MRFRB output to obtain global fusion features. Finally, the HR depth image is obtained through sub-pixel convolution layer and global fusion features. The experimental results show that the super-resolution image obtained by this method alleviates the edge distortion and artifact problems, and has better visual effects.
depth image; super-resolution; convolutional neural network; multi-scale guidance; multiple receptive field characteristics
National Natural Science Foundation of China (61876057)
* E-mail: ysx123@mail.hfut.edu.cn
TP391.41;TP183
A
于淑侠,胡良梅,张旭东,等. 彩色图像多尺度引导的深度图像超分辨率重建[J]. 光电工程,2020,47(4): 190260
10.12086/oee.2020.190260
: Yu S X, Hu L M, Zhang X D,Color image multi-scale guided depth image super-resolution reconstruction[J]., 2020, 47(4): 190260
2019-05-17;
2019-10-21基金项目:国家自然科学基金资助项目(61876057)
于淑侠(1991-),女,硕士研究生,主要从事智能信息处理的研究。E-mail:ysx123@mail.hfut.edu.cn
版权所有©2020中国科学院光电技术研究所
