面向供应商违约预测的机器学习实践案例设计
2020-04-23供稿栗辉蔡铮雒天骄傅伟康张博钰肖成勇LIHuiCAIZhengLUOTianjiaoFUWeikangZHANGBoyuXIAOChengyong
供稿|栗辉,蔡铮,雒天骄,傅伟康,张博钰,肖成勇 / LI Hui, CAI Zheng, LUO Tian-jiao, FU Wei-kang, ZHANG Bo-yu, XIAO Cheng-yong
内容导读
人工智能技术的快速发展对机器学习人才的需求不断扩大,机器学习课程也成为高校人工智能类专业的核心课程且具有高度实践性,因此将实际项目与理论教学融为一体,才能更好的使学生得到实践锻炼。本文设计了一个基于迁移学习算法的供应商违约预测的实践案例,通过改进基于间隔核密度估算的虚拟样本生成技术,本研究将其他相似供应商预测模型转换成辅助数据的形式。通过基于权重的迁移学习算法(TrAdaBoost),将生成的辅助数据中的知识迁移至源数据中来。最后通过对比没有使用迁移学习的模型,使用本研究技术架构训练得到的违约预测模型准确率更高、泛化能力更强。学生可通过该案例实践使用机器学习方法解决实际问题的完整过程。
随着人工智能技术的快速发展以及各行各业中的数据化浪潮的快速推进,应用机器学习算法分析数据,以便通过海量数据快速获得有效的规律,已经成为当下的发展趋势。因此对机器学习人才的需求不断扩大,同时对人才的多元化和综合实践能力提出了新的要求,机器学习课程也成为高校人工智能类专业的核心课程[1-2]。
机器学习课程涉及的算法众多,且具有高度实践性,但目前的课程教学多停留在算法本身,缺乏真实项目的教学资源,无法有效地让学生进行实践应用,也无法满足工程实践应用型人才的培养目标。因此将实际项目作为课程背景,与理论教学融为一体,才能更好的使学生得到实践锻炼,提高学生自主思考与解决实际问题的能力[2]。
本文设计了一个基于迁移学习算法的供应商违约预测的实践案例,通过分析某钢铁企业的供应商基本信息、采购、招投标等数据预测出可能违约的供应商,从而规避供应商违约风险。学生可通过该案例实践使用机器学习方法解决实际问题的完整过程。
供应商违约预测案例的技术架构
针对某钢铁企业供应商数据量可能不充足,不足以训练一个好的预测模型的问题,本案例采用迁移学习的技术架构,通过虚拟数据生成技术生成辅助数据来提取前人总结的违约模型的先验知识,解决了数据样本数量过小和样本不平衡问题。采用迁移学习的技术架构如图1所示。
源数据预处理及辅助数据空间的选择
特征空间构建
◆ 基于随机森林的特征选择
为了简化数据维度,挑选出对本案例的研究有参考价值的数据维度,人工剔除毫无相关性的维度后,将剩余的37个特征作为备选的特征集合。在此基础上进行特征空间的构建。然后对37个特征通过随机森林来统计各特征重要性的排序,最后筛选出10个重要性较高的特征。
这10个特征依次如下:退货率(reject)、延迟交货次数(delay)、失信记录(discredit)、下订单与交货之间时间差(time)、中标率(bid)、ISO体系认证(iso)、企业信用认证(credit)、采购金额(amount)、企业成立年数(year)、企业成员数(member)等10个特征。接下来,将对这10个特征的含义,及其与案例的相关性展开分析,以便进一步在这些特征中提取更多的信息。

图1 基于迁移学习的供应商违约预测技术架构
◆ 特征提取
为了进一步提取出更多的信息,对部分特征进行特征提取。在时间维度上对特征进行分解,可以得到特征的年度极值、均值和变化率。对以上10个特征进行特征提取之后,分解特征达到17个。
数据标注
本案例通过图2供应商的违约评价模型将供应商分成5类:违约情况严重、违约情况较重、违约情况一般、违约情况较轻、几乎无违约行为。对应的模型评分为0.6以上、0.4~0.6、0.2~0.4、0.1~0.2、<0.1。
辅助数据空间的选择
TrAdaBoost算法是根据每次迭代中的分类错误率自动调节样本点权重进而纠正数据分布的算法架构[3]。辅助数据并不需要和源数据具有相同的分布,所以其他供应商的违约模型是一个可行的辅助数据空间来源[4]。其次,辅助数据和源数据具有相同的任务[5],即都是用于判定供应商的违约信用问题。因此,本研究收集的模型类型包括供应商信用评价模型、供应商违约模型。综上所述,筛选标准有以下两点:
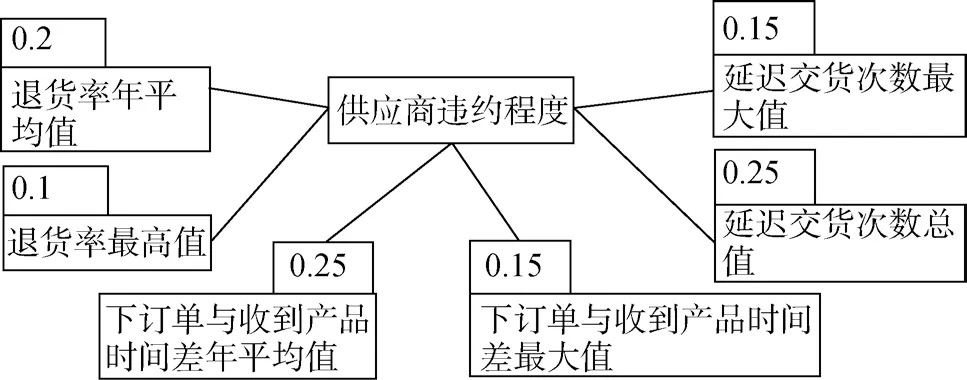
图2 源数据类别标注模型
(1) 选取的模型的特征体系与本研究源数据的特征体系尽量相似;
(2) 选取的供应商性质与本实验中的钢企物料供应商的性质尽量相似,供应商品的模式尽量相似。
基于虚拟样本技术生成辅助数据
虚拟样本的取值分布使用了基于间隔核密度估算的支持向量机的方法。并对其进行算法上的调整,依据源数据的分布,生成虚拟样本的数据取值,再通过收集到的模型进行类别判定,生成辅助数据。
辅助数据生成流程
(1) 虚拟数据取值分布确定:将源数据用SVM分类决策算法处理[6],挑选出其中拉格朗日乘子不为0的样本点集合Tt。然后通过中间插值法得到虚拟数据集Ts。
(2) 模型选择:研究供应商违约模型30例。
(3) 将虚拟数据Ts转换成可代入模型评定的数据格式。然后将其代入模型的指标体系中进行判断。每个模型都会得到一个带自己判定结果的数据集,但其中必然会出现判断结果不一致。此时,用投票的方法,取多数作为最终结果。至此,Ts数据集就有了模型判定的类别标注,成为了带有模型判定标注的数据集Tc。
(4) 将数据集Tc按照转换策略生成所需的辅助数据集Tr。
得到的辅助数据是二分类支撑界面附近的样本点。通过重复以上步骤多次,并多次二分类,得到分布在违约严重、违约较严重、违约一般、违约较轻和几乎不违约五种类别分界面附近的辅助数据。
辅助数据取值采样策略
图3是SVM对样本二分类后的分布图。按照样本的分布位置,将样本分为两大类。第一类样本位于虚线(支撑界面)外侧,这部分样本的分布情况决定了分界面(实线)的位置。第二类样本位于两虚线的内侧,这部分样本远离分界面,对于分界面位置的确定没有影响。在SVM中,两类样本的拉格朗日乘子α不同。第一类样本的拉格朗日乘子不为0,第二类样本的拉格朗日乘子为0。基于以上分析,本研究将第一类样本点作为构造源,通过插值法进行构造。这样产生出来的虚拟数据能最大程度挖掘分类模型的边界知识。假设构造源数据Ts的数据为X=(x1,x2,x3,x4…xN),虚拟数据的取值为Xf=(xf1,xf2,xf3…xfN)。则Xf=1/2(X1+X2)。
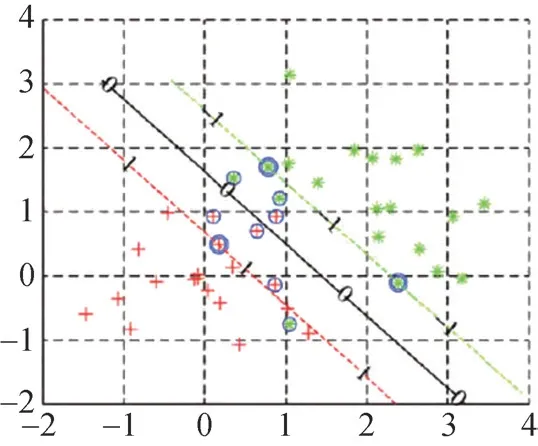
图3 SVM对二分类数据分类后的样本分布示意图
本实验依照SVM的拉格朗日乘子不为0的标准,从1万多条的供应商源数据中选出构造源样本点 1064个。通过中间插值的方法得到虚拟数据样本点56.7万个。
虚拟数据向模型可标注数据的转换策略
得到虚拟数据的取值采样后,需要将其放入收集到的模型中得到这些模型对样本点的分类结果。把虚拟数据代入到模型时,会出现特征不相和的情况。为此,需要将虚拟数据转换成模型可标注的数据格式。调整策略为:
(1) 模型中的特征feature_a存在,而虚拟数据没有的时候,对模型进行改造,舍弃这部分源数据没有的特征。调整剩下的特征的权重,使其总和为1,得到相应的判定结果。
(2) 相关的特征之间进行转换。比如模型中的准时交货比率特征nodelay_rate并不在虚拟数据的特征集中,但计算项目交货总次数JHamount与(1-nodelay_rate)的乘积,即可得到特征延迟交货次数年份总值delay_all的取值。
(3) 特征概念相似,模型中为feature_a,而虚拟数据特征为feature_b,但两者体现同样的含义,可以将feature_b用feature_a的取值替代。比如本实验中源数据的特征指标中标率bid反映模型中的产品市场占有率。辅助数据中的中标率bid特征的取值就取模型生成数据的产品市场占有率这一特征值。
(4) 虚拟数据中有特征feature_b,而模型中并无这个特征,而且无相似特征feature_a可以取代。此时,辅助数据缺失这部分特征的取值。此时,辅助数据缺失特征的取值采用源数据中的众数。
基于权重的迁移学习算法TrAdaBoost
TrAdaBoost算法是基于实例的迁移学习算法,适用于相似领域的实例之间的迁移。
定义1(基本符号):
设Xb为源数据空间, Xa为辅助数据空间。 设Y = { 0 , 1 } 为 类 空 间。 训 练 数 据 为
定义2(测试数据集(未标注)):
S={(xti)},其中当i=1,2,…,k。
定义3(训练数据集):
{Ta=(xai,f(xai))},其中 xai∈ Xa,当i=1,2,…,n;Tb={xbj,f(xbj)},其中xbibX∈ ,当j=1,2,…,m。其中,f(x)是实例x的真实类标。Ta为辅助训练数据集。Tb为源训练数据集。最终的训练数据集T={xi,f(xi)}。对其定义:xi=xdi,i=1,2,…,n;xsi,i=n+1,…,n+m。
其中,源数据集Tb与测试数据集S是同分布的。而辅助数据集Ta与S并不是同分布的,但一般会选择分布相似的样本,但也可能很不一样。严格地说,就是输入:辅助训练集Ta,源训练数据集Tb,未标注的测试数据集S,分类器Learner。输出:假设hf=X→Y。
具体的算法流程:

①设置pt满足

②运用分类器,在合并的训练数据集T上训练。通过调节T上的权重分布pt,得到更新后的分类算法ht=X→Y。
③计算ht在Tb上的错误率:

⑤设置新的权重向量:

(3) 输出最终分类器

对于数据的筛选过程可以看出本算法的原理是根据该样本点是否被分类器正确分类来不断更新样本点的权重,进而减少分布差异大的数据权重。在每次迭代中,不能被正确分类的数据权重每次都会乘以一个小于1的因子(由源数据集上错误率计算得到)。经过多次迭代,这个不能被正确分类的样本点的权重就会很小,将从数据集中“删除”。同时,那些正确分类的数据,每次迭代会乘以小于1的因子的倒数,权重会增大,从而被“留下来”。TrAdaBoost算法将其他领域中分布相似的样本点筛选到了本案例数据量较小的源数据之中。
供应商违约预测实验结果
为了证明本文的技术架构能有效地提高对供应商违约预测的准确率,使用单一的机器学习算法(SVM)在源数据集和合并数据集上进行试验,对比证明TrAdaboost算法和辅助数据集确实具有提高供应商违约预测准确率的效果。从表2得到基于TrAdaBoost算法的供应商违约预测结果与其他两种方案的预测准确率对比,证明了本研究的技术方案确实可以解决小样本数据类别不平衡的问题,能够提高模型的预测准确率。

表2 TrAdaBoost算法预测结果与单一虚拟生成技术预测结果对比
结束语
本案例通过机器学习解决了实际问题中的源数据预处理、辅助数据生成技术、迁移学习算法分析处理等过程,通过对企业数据的分析,实现了供应商违约预测,具有较好的实际应用价值,能够帮助学生通过案例实践来掌握课程知识,并锻炼其解决实际问题的能力,达到课程教学的目的。

《雪松》赵艺含
