基于随机统计方法的地下水污染源反演识别
2020-04-22卢文喜刘洪超
张 宇, 吕 军*, 卢文喜, 刘洪超
(1.水利部松辽水利委员会, 长春 130021; 2.吉林大学新能源与环境学院,长春 130021)
由于人类活动强度的增大导致地下水污染程度日趋严重,对饮用水安全和生态环境构成了威胁。地下水污染具有存在的隐蔽性、发现的滞后性特点,这给地下水污染修复方案设计、污染风险评估、污染责任认定都带来了很大的困难。地下水污染源识别是制定合理修复方案的前提,也是进行地下水污染风险评估及污染责任认定的必要条件[1]。
地下水污染源反演识别是指运用有限且离散的地下水观测数据,对地下水污染数学模拟模型进行反演求解,识别确定污染源的个数、位置和释放历史。地下水污染源反演识别作为一种典型的数理方程的逆问题,其求解的复杂性在于问题的不适定性[2]。目前,地下水污染源反演识别的研究尚处在发展阶段,主要包括:地球化学指纹技术和数学模拟方法等。然而,单独使用地球化学指纹技术不能完全解决确定污染源位置及追溯污染质释放历史的问题,且该方法工作量大、经验性强、实施成本较为昂贵[3-4]。概括而言,地下水污染源反演识别的数学模拟方法可划分为确定性方法和随机统计方法两类[5]。Skaggs等应用吉洪诺夫正则化及准可逆性方法追溯一维均质各向同性含水层介质已知单个污染源位置的污染源释放历史[6-7]。然而,该方法采用解析解进行研究,不能满足实际场地污染源反演识别的需要。Mahar[8]运用模拟-优化模型的求解结果对监测井孔进行优化布设,把水质观测数据作为反馈信息循环迭代识别污染源的释放历史。Bagtzoglou[9]运用随机统计方法进行污染源反演识别研究。Gzyl等[10]提出了一种基于地质统计学的多步方法识别污染源位置及释放历史。与国外的研究相比,中国对于地下水污染源反演识别问题的研究尚处于起步阶段。朱嵩[11]运用结合马尔科夫链蒙特卡洛(MCMC)抽样的贝叶斯方法求解理想算例水动力-水质耦合场条件下的污染源识别反问题;江思珉等[12]基于污染羽形态对比进行地下水污染源识别研究,确定了二维非均质含水层中多个污染源的位置及释放历史;肖传宁等[13]对比分析了基于两种耦合方法的模拟-优化模型在地下水污染源识别中的计算结果。
目前为止,国内有关地下水污染源识别问题的研究还仅限于运用单一一种确定性方法或随机统计方法解决污染源反演识别中某一方面的问题。尚未见到将多种方法组合使用以综合解决污染源反演识别问题方面的研究报道。因此,如何在现场调查的基础上,通过科学合理的方法反演识别污染源的特征是一个亟待解决且具有重要理论和实际意义的科学问题。鉴于此,以某垃圾填埋场垃圾渗滤液地下泄漏的情形为例,对地下水污染源的反演识别问题进行研究。通过污染质运移模拟模型、替代模型、随机统计方法(伴随状态方法及贝叶斯方法)的综合运用,反演识别出地下水污染源个数、位置及释放历史。
1 地下水污染源反演识别的随机统计方法
运用随机统计方法进行的地下水污染源反演识别主要包括二个方面:第一,运用伴随状态方法反演识别污染源的个数及位置;第二,基于上述反演识别结果,运用贝叶斯方法反演识别污染源的释放历史。
1.1 伴随状态方法
伴随状态方法,又称伴随变分方法,是一种借助泛函分析进行灵敏度计算的方法[14]。针对梯度类优化方法中梯度向量计算量大且难以求解的问题,通过引入伴随状态变量,推导出梯度向量的显式计算公式,从而可以一次性地算出灵敏度矩阵H。
在对流-弥散方程一般形式的基础上运用伴随变分方法推导出伴随方程。充分考虑模拟模型初始及边界条件的基础上,对构造出的变分等式分部积分,随之推导出求解伴随方程所需的伴随初始和边界条件。上述过程中,推导出的伴随方程和伴随状态下的定解条件共同构成了求解地下水污染源识别反问题的数学模型,从而可以直接借助数值计算方法的求解结果推断出污染源的个数及位置。
如果定义伴随状态下的时间变量τ,τ=T-t(τ为逆向时间,T为水质监测末刻时间),为了与一般情况下的对流-弥散方程及其定解条件进行区分,定义基于伴随状态方法变换后的对流-弥散方程及其定解条件为
(1)
式(1)中:Ω为渗流区域;t为时间,s;i、j为直角坐标系坐标x、y、z;ψ*为伴随状态变量;c为污染物的溶解浓度,m/L3;ui为渗流速度,L/s;Dij为水动力弥散系数,L2/s;η为含水层介质的有效孔隙度,无量纲;q0、q1分别为单位体积多孔介质污染源项和汇项的体积流量,L3/s;cs为源项污染物浓度,m/L3;c0(x,y,z)为污染物的初始浓度;Γ1为第一类边界条件;Γ2为第二类边界条件;Γ3为第三类边界条件。
说明:式(1)中t为正演模型的时间变量,T为正演模型水质监测末刻的时间(实为定值,本次研究T=1 440 d,即4年),τ为反演模型的时间变量,三个变量的量纲均为T,但是因为应用于不同的模型中,因此用3个变量加以表示。
1.2 贝叶斯方法
地下水污染源反演识别问题,从概率统计的角度可以看成是一种贝叶斯推理问题,即通过水质观测数据不断地更新污染源的先验信息,从而得到反演问题的解[15]。
(2)
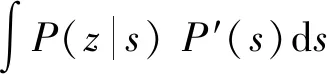
2 地下水污染源反演识别实例研究
以某垃圾填埋场垃圾渗滤液地下泄漏的情形为例,对地下水污染源的反演识别问题进行研究。计算目的层可概化为二维均质各向同性的潜水含水层(1 300 m×800 m),以100 m×100 m为基本单元,将含水层均匀剖分成104个网格。含水层水流运动为稳定流,含水层厚度为30.5 m。东西边界为线性变化的给定水头边界,南北边界为隔水边界,如图1所示。含水层水文地质参数见表1。
研究区存在3个潜在的污染点源,分别记为S1、S2和S3(实际上S2并未排放污染物),监测井及污染源的分布如图1所示。假定S1、S2和S3分时段排放污染物至含水层中,导致地下水遭受污染。现定义每个污染物浓度监测时段为一个应力期(stress period,SP),每个应力期的时长为4个月,整个监测过程一共持续了4年,共计12个应力期(表2)。
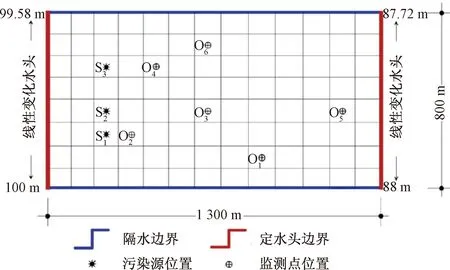
图1 研究区示意图

表1 水文地质参数值
2.1 基于伴随状态方法的地下水污染源反演识别研究
根据上述伴随状态方法的求解思路和污染物浓度监测数据(表2),反演追溯各应力期的污染羽分布图(图2)。伴随状态方法下的污染源追溯初始时间是从正演过程的污染物监测末刻开始,而并非从污染物初始排放时刻算起。所以伴随状态方法反演得到的第一个污染羽[图2(a)]对应的是污染物监测末刻(τ=T-t),即正演过程的第11个应力期。
图2 (a)显示的是在τ=1 440 d(反演末刻)得到的潜在源位置处的污染羽分布,从中可以确定污染源的位置。同样可以求解出在该时刻各个网格单元内的污染物浓度,表3是104个单元格中污染物浓度较大的8个单元格坐标及污染物浓度。
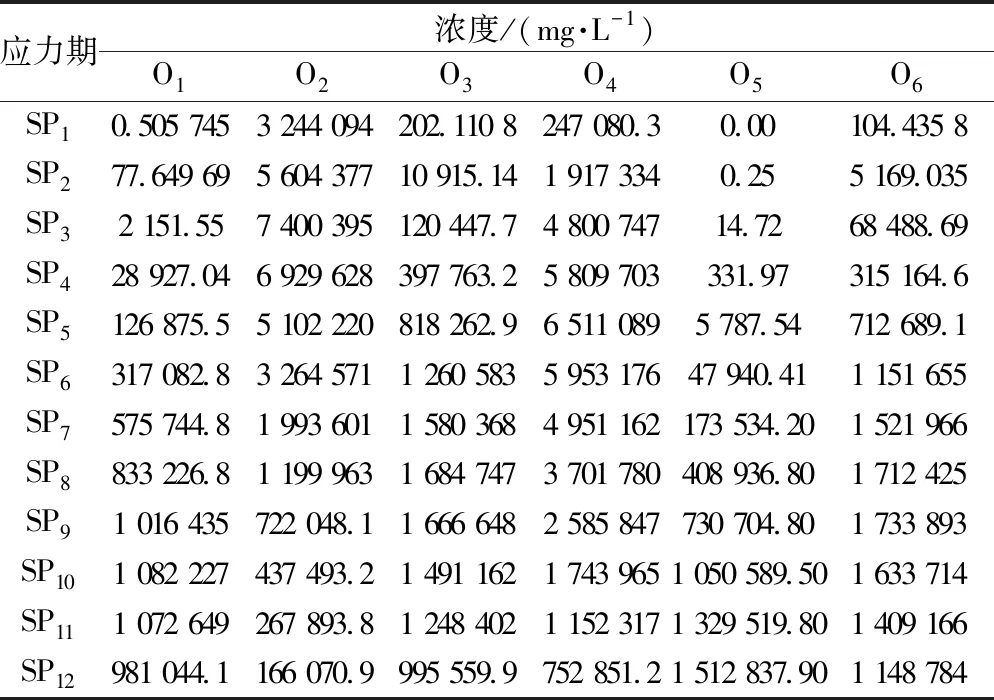
表2 监测井在各应力期的污染物浓度
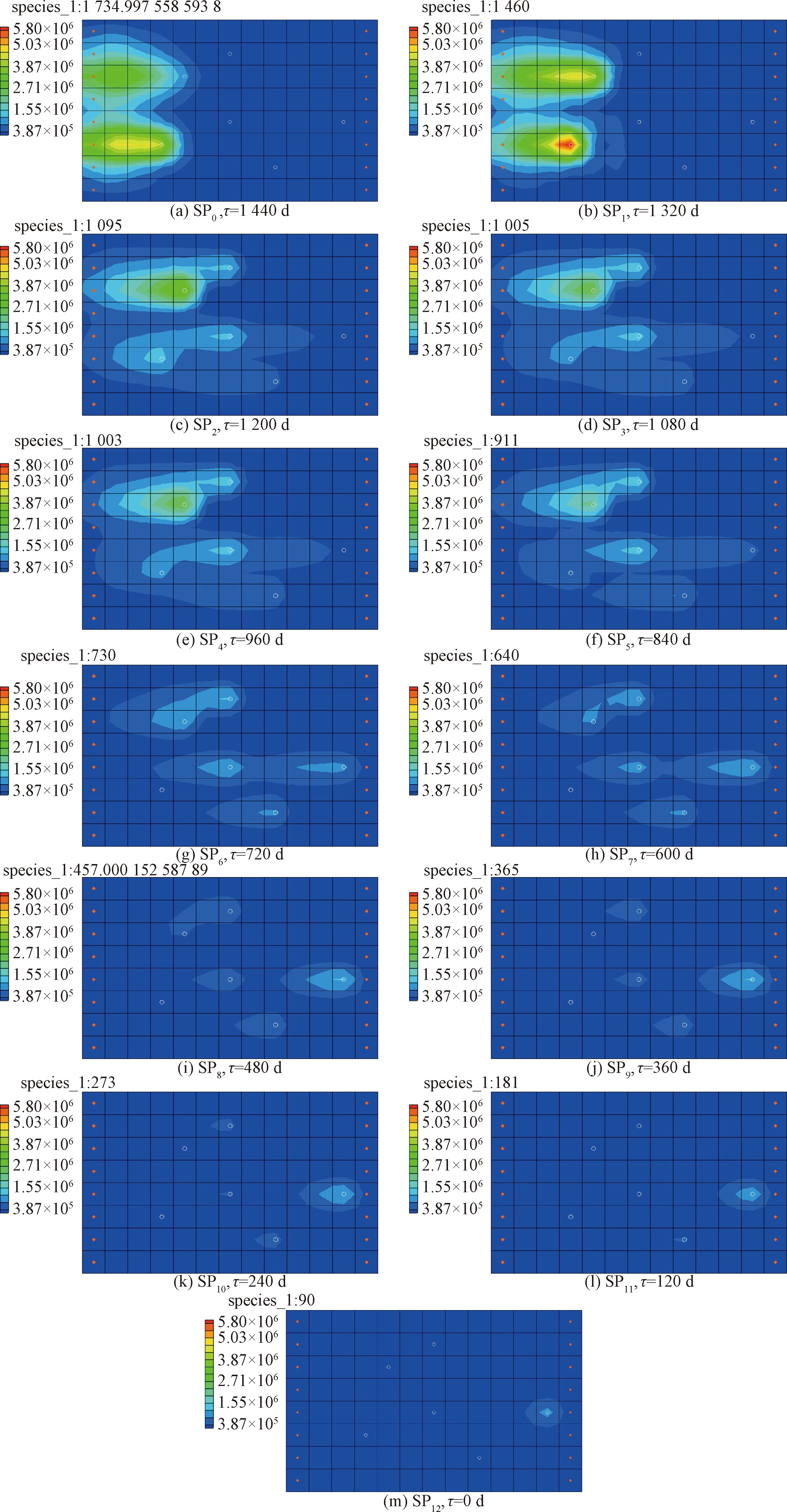
图2 伴随状态方法反演得到的污染羽分布图
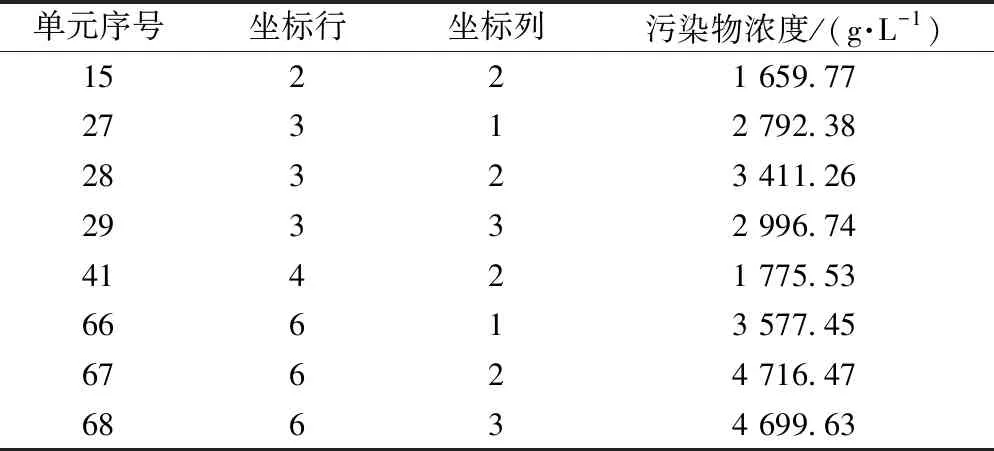
表3 反演得到的潜在源位置处的污染物浓度(τ=1 440 d)
将伴随状态方法得到的污染源特征与真实情况比对,结论如下:
(1)运用伴随状态方法可以确定污染源的个数。在得到的污染物初始分布图中可以明显识别出2个主要的污染源,排除了污染源S2的干扰。实际上,污染源S2在整个监测期内从未排放过污染物。
(2)运用伴随状态方法还可以确定污染源的位置。根据各个网格上的污染物模拟浓度,我们可以推断出污染源可能位于以(6,2)和(3,2)为中心的区域内。与真实污染源的位置(6,3)和(3,3)相比,相对位置误差为7.7%,可以满足10%的精度要求。
2.2 基于贝叶斯推理的地下水污染源反演识别研究
伴随状态方法可以有效识别出污染源的位置及个数。然而随着问题复杂程度的增加,伴随状态方法已不适用于反演识别多个污染源分时段排放污染物的释放历史问题。基于贝叶斯推理的污染源识别方法通过增加源强的先验信息,缩小了解的空间范围。同时通过构造一个平稳分布与目标分布相同的马尔科夫链来得到反演问题可能解的样本,并根据这些样本进行统计推断,进而得到反演问题的解估计。
通常情况下,基于贝叶斯方法进行地下水污染源识别需要反复多次直接求解模拟模型本身,因此会带来庞大的计算负荷和冗长的计算时间,严重制约地下水污染源识别的计算效率。替代模型作为模拟模型的代替模型,可有效实现模拟模型与反演过程的连接,大幅度减少反演计算的时间。本文对比运用替代模型前后污染源识别的计算时间,检验该方法的可行性与有效性。
2.2.1 模拟模型的初步建立
研究区地质、水文地质条件与地下水流场图同上述情形。研究区存在3个污染源,污染源S1、S2、S3的位置如图3所示。各污染源分时段排放污染物至含水层中,设定每个应力期的时长为4个月,污染源活跃于前4个应力期。整个监测过程从污染物开始排放的时刻起一共持续了4年,共计12个应力期。

图3 研究区示意图
根据水文地质概念模型,建立数学模型为
(3)
基于确定的污染源位置和污染场地附加信息初步建立溶质运移模拟模型。模型的参数设置见表1。
2.2.2 数据的准备
数据的准备为替代模型建立所用到的输入-输出样本集的获取。
假设各时段污染源源强M的先验分布为均匀分布U[0,60],其先验概率密度函数为
(4)

图4 水质监测数据折线图
污染物浓度数据来源于5口监测井,分别为O1(7,9)、O2(6,4)、O3(5,7)、O4(3,5)、O5(2,7),如图4所示。图4中纵坐标表示污染物浓度,折线图表征O1~O5五口监测井的水质监测数据;横坐标表示12个应力期(共4年,每个应力期为120 d),即SP1=120 d,SP2=240 d,…,SP12=1 440 d。
2.2.3 替代模型的建立
替代模型,又称近似模型,是指能代替原来的模拟模型近似反映其某种输入输出关系的模型,其本质是模拟模型的代替模型。在解决污染源反演识别问题时用简单的替代模型代替复杂的模拟模型,不仅节省时间且减小计算负荷,能够有效地提高反演问题求解的计算效率。
(1)训练及检验样本的选取。采用拉丁超立方抽样方法在[0,60]内抽取120个样本共8组并进行随机组合,组成初始输入样本集。以产生训练样本同样的方式,生成替代模型的检验样本集,检验样本集的数目为20。将训练样本数据输入到上述初步建立的溶质运移数值模拟模型中,运行模型即得到5口监测井处12个监测时段的污染物浓度,作为相应的输出响应,即形成输出数据集。输入数据集和输出数据集组合成训练样本集,为替代模型的建立准备基础数据。
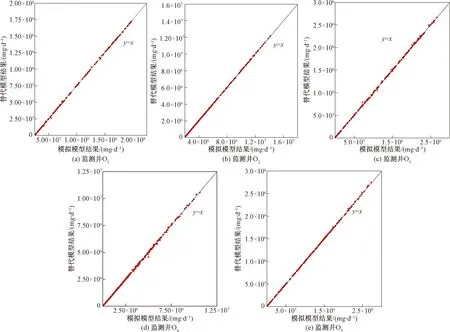
图5 替代模型结果与模拟模型结果拟合图
(2)替代模型的建立。克里格(Kriging)模型由南非的Danie Krige于1951年提出,它是一种典型的通过插值方法建立的替代模型。本研究根据克里格方法的原理基于MATLAB平台编写程序分别建立5口监测井的克里格替代模型,并基于自适应权重粒子群优化算法进行参数的优化。
(3)替代模型的检验。将20组检验样本输入训练好的克里格替代模型,获得输出响应(12个时段的监测井污染物浓度值),并将其与溶质运移模拟模型的输出响应对比,对比结果如图5所示。结果表明:克里格替代模型对模拟模型有较高的逼近精度,其对比结果接近1:1完美线,能够识别并取代模拟模型的输入输出关系。
2.2.4 MCMC算法
贝叶斯定理数学表达式简单,但其后验概率密度函数的求解相当困难。为了解决这一问题,本次研究采用Markov Chain Monte Carlo(MCMC)算法中的Metropolis-Hastings搜索策略。
MCMC算法参数设置如下:污染源源强归一化后的先验分布为x∈[0,1]上的均匀概率分布。随机游走的建议分布为q(x*|xt)=U(xt-step,xt+step),步长step为参数先验范围的0.2%,即参数的搜索步长为0.002,迭代进行105次。污染源强度的反演迭代曲线如图6所示。

图6 污染源强度的反演迭代曲线
由图6可以看出,S1在经历了大约3 500步,S2在经历了大约2×104步迭代后(burn-in阶段),各时段的污染源源强反演结果开始进入收敛区域。表明在此情况下,污染源源强能够被准确的识别。舍弃S1、S2的burn-in阶段的结果,对其后的链进行统计,统计结果见表4。
图7为2个污染源待反演4个时段的源强的后验概率分布直方图,直观地表现了在获得水质观测数据以后,上述待反演源强的分布规律。可以看出,后验分布并不服从均匀分布,贝叶斯方法更新了源强的先验分布。
运用贝叶斯方法反演识别污染源过程的主要计算负荷来自于反复多次调用模拟模型。初步建立的模拟模型在CPU为Intel i7 2.50 GHz,内存为8 GB的计算机上运行一次平均需要6 s。如果用一般的模拟模型来解决此问题,模拟模型需要运行105次。因此,求解此问题需要33.33 h。如果将克里格替代模型引入反演问题的求解中来代替模拟模型,在训练和检验克里格模型的过程中模拟模型需要运行140次,需要14 min。而获得反演问题的解只需要5.56 h。因此,替代模型的引入大大减小了反演问题求解的计算负荷。
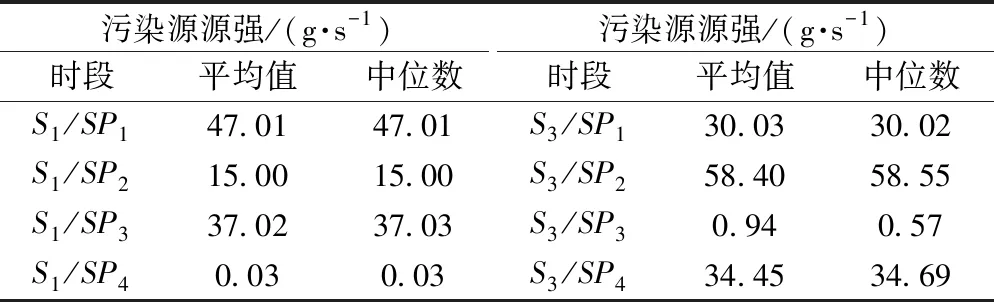
表4 污染源源强反演统计结果
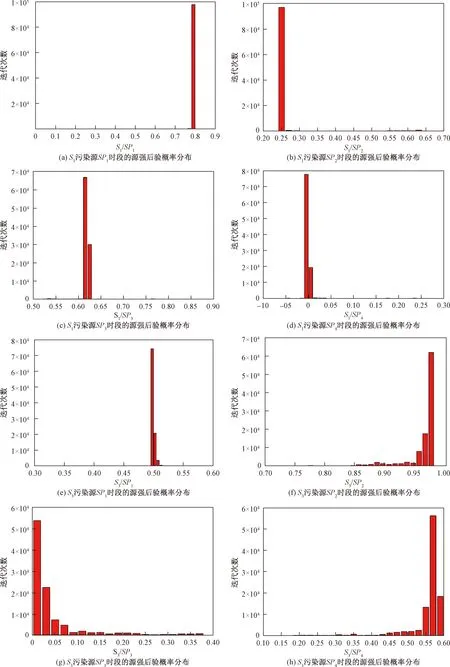
图7 污染源源强的后验概率分布直方图
3 结论及建议
通过污染质运移模拟模型、替代模型、随机统计方法(伴随状态方法及贝叶斯方法)的综合运用,反演识别地下水污染源的特征。主要得到以下结论及建议。
(1)伴随状态方法和贝叶斯方法的联合运用可以反演识别出污染源的个数、位置及释放历史。
(2)克里格模型对模拟模型具有较高的近似精度。贝叶斯方法反演识别污染源过程中,以替代模型作为模拟模型的转化形式,用替代模型代替模拟模型大幅度地减小了计算负荷,并保持了较高的精度。
(3)研究将计算目的层概化为均质各向同性的潜水含水层。在今后的研究中,需要针对实际的污染场地研究丰富本文的相关理论,如水质监测数据的消噪处理、缺失数据的内插与外延等相关理论与方法的研究。
