低分辨率条件下鞋类的自动分类方法
2020-04-22杨孟京糜忠良唐云祁
姜 衡, 杨孟京, 糜忠良, 唐云祁*
(1.中国人民公安大学刑事科学技术学院,北京 100038;2.上海市现场物证重点实验室,上海 200083)
根据洛卡德的物质交换与转移原理,触物必留痕,相应的,如果嫌疑人在现场,他将留下脚印。足迹发挥了越来越重要的作用,这是因为依据嫌疑人留下的足迹可以推断出嫌疑人所穿鞋的鞋型,再到犯罪现场周围的视频监控中排查是否有人穿此鞋型从而实现对犯罪嫌疑人的追踪溯源[1]。然而现实案件中的监控视频大多是比较模糊的,并不能直接判断出鞋型,且人工完成费时费力。此时我们就可以借助计算机自动对视频监控下的鞋进行初分类,只需判断鞋的类别,如判断其是皮鞋还是运动鞋,初步确定嫌疑人的范围,为下一步锁定嫌疑人奠定基础。
鞋类的自动分类本质上是计算机图像分类的问题,是计算机视觉领域的主要研究方向。 如果能将图像分类引入上述视频监控下鞋类的判别,那么将大大减少技术人员的工作量, 并且能尽快的缩小和确定侦察范围,从而使案件在短时间内破获。 近年来,卷积神经网络逐渐成为图像分类领域的热点,不同于传统基于特征的匹配技术的识别方法,因其能自动提取更抽象、更本质的特征,卷积神经网络的性能远远优于传统的手动或半自动提取功能。由于这种性能,卷积神经网络在人脸识别,指纹识别和图像处理方面做出了突出贡献。现将基于卷积神经网络设计鞋类自动分类模型,结合犯罪现场的特点、国家制鞋标准技术委员会制定的鞋类分类标准,将鞋分为两类,分别是皮鞋和运动鞋,将休闲鞋归纳为运动鞋中的一般运动鞋类;建立低分辨率鞋类数据库,包括59 853幅皮鞋和47 878幅运动鞋图像;选择合适的框架结构和网络,调整网络深度、网络权值参数、根据模型选择合适的损失函数,设计适合鞋类自动分类的网络模型,实现对低分辨率下鞋类的自动分类。
1 相关工作
1.1 图像分类
图像分类有很多种方法,2012年以前主要是用尺度不变特征变换(scale invariant feature transformation,SIFT)、局部二值模式(local binary mode,LBM)[2]等算法来手动提取特征,再将提取的特征用来训练,最后用支持向量机等分类器进行分类,精度低,工作量大[3];2012年,Krizhevsky等[4]提出的AlexNet首次提出了应用深度学习对图像进行分类,精度达到了83.6%;2014年Google团队所提出的GoogleNet[5]同样也应用了深度学习的思想,精度达到了93.3%。
2015年初,微软提出了PReLU-Nets(参数修正线性单元)[6],在ILSVRC(大规模图像视觉识别挑战赛)数据集中首次超过人眼识别。不久之后,Google在训练网络时对每个mini-batch进行正规化,并称其为Batch normalization,将该训练方法运用于GoogleNet,在ILSVRC2012的数据集上达到了4.82%的top-5错误率[7]。因此,Google将归一化用到激活函数中,对传输数据进行标准化处理。由于训练期间使用随机梯度下降法,因此这种归一化只能在每个小批量中进行,因此称为批量归一化。 该方法可以在训练期间实现更高的学习率并减少训练时间;同时减少过拟合,提高准确率。
尽管卷积神经网络已经具有强大的图像学习能力,但是这种模型缺乏对图像空间不变性的学习,特别是缺乏图像旋转的不变性[8]。Google DeepMind提出的空间变换[9]旨在通过提高卷积神经网络对图像空间不变性的学习能力来提高图像分类的准确性。
1.2 鞋类的分类方式
对鞋类进行自动分类的前提是必须先对鞋类有个明确的分类标准和定义,在制鞋工艺越来越发达,鞋子种类越来越丰富的今天,分类的方式也多种多样,这是不利于本研究的,为此参考了全国制鞋标准化技术委员会2017年制定的制鞋标准[10],其中“日常穿用”按照功能划分为“休闲鞋”“正装鞋”和“其他”三大类,“功能类”按照不同的功能划分为“职业鞋” “康复鞋”“专业运动鞋”和“其他”四大类,由此可见,鞋类标准体系按照功能进行分类已被广为接受和采纳,并将在使用的过程中根据实际情况加以完善,目前中国推行的鞋的分类方式[11]同样也验证了这一点。
2 网络模型设计
本文中研究的鞋类自动分类属于一个二分类问题,鞋类图像被分为两类,一类是皮鞋图像,另一类是运动鞋图像。设计的鞋类识别网络(footwear identification network,FINet)有5层,包含3个卷积层和2个全连接层,每一个卷积层后是1个Relu激活层和1个最大池化层。下面将详细介绍本文所提出的鞋类的自动分类模型。具体网络模型设计及参数配置如图1和表1所示。
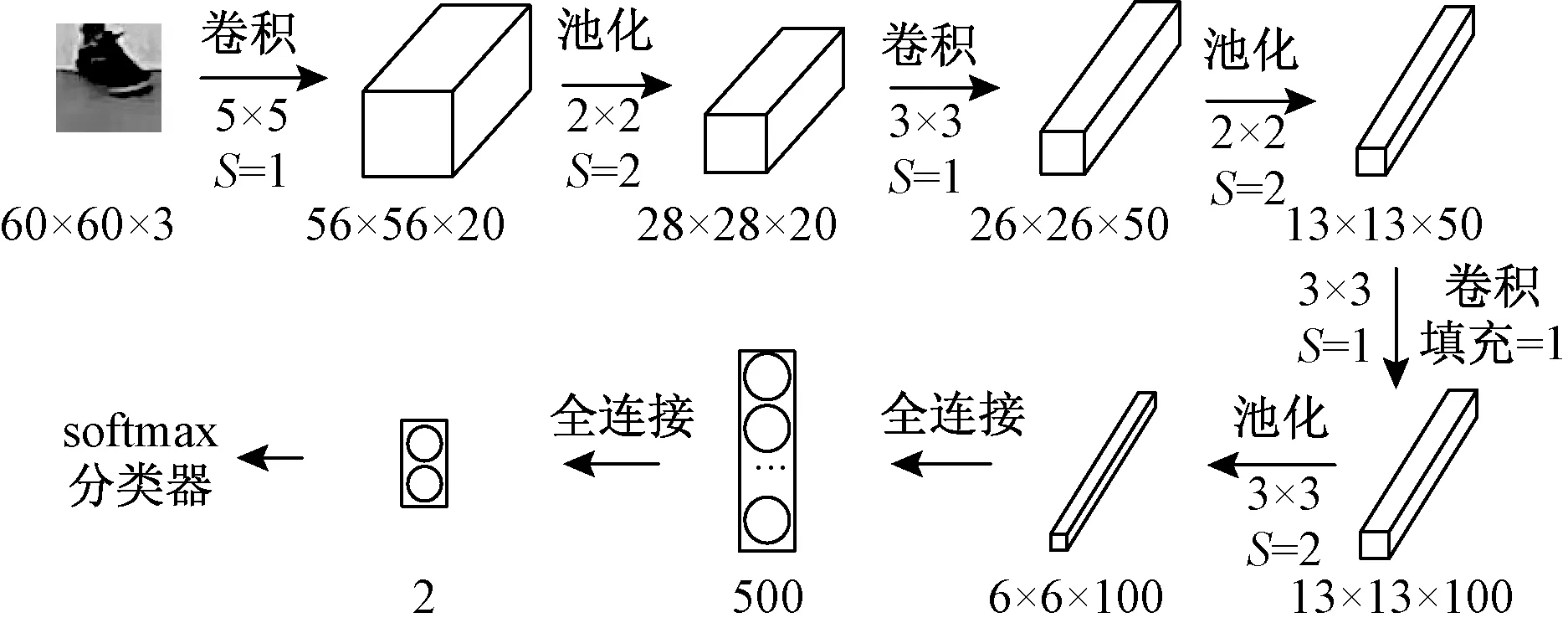
图1 FINet结构图

表1 FINet的网络参数设置
网络的输入尺寸是60×60×3的三通道鞋类图像。第1层卷积层使用20个5×5×3的卷积核对输入图像进行卷积,移动步长为1个像素。因此输出的特征图尺寸为(60-5)/1+1=56个像素。由于有20个卷积核,所以最后生成的特征图的规模为56×56×20。这些特征图由Relu激活函数处理后,然后由最大池化层处理,大小为2×2,移动步长为2,则池化后图像的宽高都为(56-2)/2+1=28个像素,数量为20个。
第2层卷积层的输入是28×28×20尺寸的特征图,通过50个3×3×20的卷积核处理, 移动步长为1,输出的特征图尺寸为(28-3)/1+ l=26。 输出的结果经过 Relu激活后再经过一个最大池化层的处理,池化核的大小是2×2, 移动步长是2,得到输出的特征图规模为13×13×50。
第3层卷积层使用3×3大小的卷积核,其移动步长为1,填补输入图像周围的像素,使得输出跟输入匹配。该层中的卷积核数量是100,卷积输出特征大小是13×13×100。输出的结果经过Relu激活后再经过一个最大池化层的处理,池化核的大小是3×3,移动步长是2,得到的输出的特征图规模为6×6×100。
第1层全连接层的输入尺寸为6×6×100,采用 6×6×100尺寸的滤波器对输入进行卷积运算,每个滤波器都会生成一个一维的运算结果。共有500个这样规模的滤波器,所以最后的输出为500维的向量,再通过Relu激活函数操作后,得到本层最后500维的输出值。该层的参数总数为6×6×100×500=1 800 000。
第2层全连接层的神经元共有2个,所以最后的输出为2个数据。该层的参数总数为500×2=1 000。
模型训练时的具体参数和说明如下:
(1)数据集总共有122 302张彩色鞋图像,包括皮鞋图像43 941张、运动鞋图像78 361张。
(2)为评估模型的性能,引入了LeNet-5和AlexNet两个网络模型与所设计的鞋类分类模型做对比,在3个网络模型中均对原始图片进行不同大小的归一化,LeNet-5网络模型中的大小为60×60、AlexNet网络模型中的大小为227×227、所设计的FINet模型中的大小为60×60。
(3)设置的学习率为0.000 1。
(4)训练过程采用GPU(图形处理器)的训练方式。
(5)使用relu激活函数。
实验的硬件配置为Intel(R)Pentium(R)CPU G4600 @3.6 GHz,内存8 GB,GPU为NVIDIA GeForce GTX950 m。软件配置为Windows10,CUDA9.1 GPU并行计算库,开源深度学习框架Caffe。
3 实验结果分析
为了验证实验结果的可靠性以及所设计网络模型的泛化能力,选择的评价指标有:精度(ACC)、错误率(ER)、真正例率(TPR)、假正例率(FPR)、查准率(Pr)、查全率(Re),计算公式分别为

(1)
ER=1-ACC
(2)
(3)
(4)
(5)
式中:TN、TP、FP、FN分别表示皮鞋识别成皮鞋、运动鞋识别成运动鞋、运动鞋识别成皮鞋、皮鞋识别成运动鞋的数量。
接下来从以下几方面对本实验结果进行展示:鞋类数据库的构建、数据预处理和结果分析。结果分析包括不同网络结构对结果的影响、加入中心损失函数对结果的影响、不同批尺寸对结果的影响以及分类错误原因分析。
3.1 数据库的构建
收集犯罪现场出现率较高的47双不同的鞋(共122 302幅鞋图像),其中皮鞋24双(共43 941幅鞋图像)、运动鞋23双(共78 361幅鞋图像)。运动鞋都是选择颜色与皮鞋相同或相近的鞋,在视频监控下容易与皮鞋发生混淆导致刑事技术人员的判断错误。皮鞋包括普通皮鞋、休闲皮鞋、高跟鞋、靴子;运动鞋包括休闲鞋和专业运动鞋,休闲鞋有布鞋、板鞋和拖鞋,专业运动鞋有跑步鞋、登山鞋、篮球鞋和羽毛球鞋。各鞋类示例图如图2所示。

图2 鞋类示例图
3.2 数据预处理
3.2.1 视频采集
征集5名志愿者,收集了47双不同的鞋,然后志愿者模拟犯罪嫌疑人或行人穿着这些鞋在离摄像头较远的地方分别以0°、15°和30°的角度在摄像头下行走,创造模糊监控画面的条件。视频采集路线如图3所示。

图3 视频采集路线
3.2.2 视频分帧、图像裁剪、图像尺寸归一化处理
由于所获取的是视频,实验数据输入要求的是图像,所以需要对视频进行分帧,把视频分成一张张的视频帧,利用的是MATLAB(R2016a)软件对采集好的视频进行分帧;分帧后所得到的图像包含行人的所有特征,由于只对图像中的鞋子部分感兴趣,为了消除其他无关区域对图像分类的干扰并减少数据量,需要对图像中的有效区域进行提取,提取的方法是手动分割图像中鞋子的部分;为了加速神经网络的训练和测试,所有图像最终尺寸标准化,尺寸为60×60。
3.3 结果分析
本实验采用了122 302张鞋图像,其中4/5用于训练网络模型、1/5用于测试网络模型的泛化能力,结果见表2。经训练和测试后,在测试错误率上,所设计的FINet只有4.3%,低于LeNet-5网络模型和AlexNet网络模型; 在速度上, batch size都设128的情况下,所设计的网络模型训练阶段每遍历一次训练数据的迭代时间约为44.73 s, 测试阶段遍历一次测试数据耗时约4.22 s,而 AlexNet网络训练时每遍历一次训练数据的迭代时间约为666.43 s, 测试阶段遍历一次测试数据耗时约48.36 s, LeNet-5网络耗时最低,但其错误率较高。 综合测试的错误率、训练时间和成本,最终选择使用了所设计的5层网络结构进行训练和分类。

表2 不同网络模型测试错误率、训练时间和测试时间对比
在鞋类识别中,精度表示皮鞋或运动鞋被识别正确的概率,错误率表示皮鞋或运动鞋被识别错误的概率,但是在一些案件中更关心被识别成皮鞋里面有多少比例是真正的皮鞋,或者在皮鞋中有多少比例被错误识别成运动鞋了,精度和错误率显然就不能满足上述任务需求,这时就需要引入其他的指标来评价我们所设计的模型了,图4和图5是不同网络模型的ROC曲线(接受者操作特性曲线)和P-R曲线, FINet模型的性能优于其他两种网络模型。
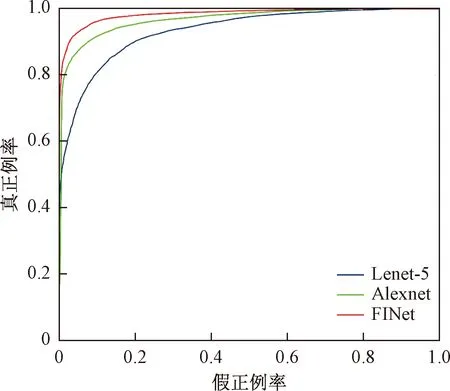
图4 不同网络模型的ROC曲线

图5 不同网络模型的P-R曲线

图6 中心损失函数结构
3.3.1 加入中心损失函数对实验结果的影响
中心损失函数(center loss function)能使相同类型的样本更紧凑,不同类型样本更分散。本文所研究的鞋类分类问题中无论是皮鞋还是运动鞋类,都包含了二十几双不同的鞋,类内差距较大,中心损失函数正好能解决这一问题。其结构如图6所示,softmax损失函数是常见的分类函数,其输出结果表示正确分类的概率,当概率值越高的时候,对应其损失函数也就越小。加了中心损失(center loss)之后,损失值变小,正确分类的概率即精度比原来提高了0.7%,结果如图7所示。
3.3.2 批尺寸对实验结果的影响
选取一个合适的批尺寸(batch size)将数据分批次输入给机器学习对于最终的分类结果也是非常重要的,选取5个常用的批尺寸,对比实验中控制迭代次数等其他参数不变,最终结果如表3所示:批尺寸在区间[16,128]的测试精度呈上升趋势,批尺寸在128时达到最高值,精度达到最高值后又呈下降趋势,表明当批尺寸设128左右能使网络达到最优化。
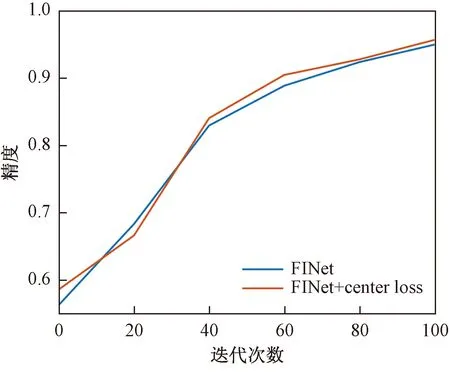
图7 中心损失函数实验效果

表3 不同批尺寸下的精度对比
综合以上分析,最终选择使用所设计的5层并加上中心损失函数,批尺寸为128的网络结构对实验中的鞋类图片进行训练和分类,分类错误率不到5%。最后将识别错误图片导出进行分析,部分图片如图8所示。识别错误的主要原因有:①人在行走时太快而形成的运动模糊[图8(a)];②亮度太低而产生的模糊,以至于机器提取不到鞋的特征[图8(b)];③背景因素的干扰以至于机器不能准确识别[图8(c)],本实验数据中有白色、黑色和蓝色三种背景,甚至有的图像中背景中出现了多种颜色的背景。

图8 部分识别错误的代表性图片
4 结论
在现实案件中低分辨率监控视频大量存在,并且亮度低,场景模糊,导致视频图片质量较差,很容易产生主观判断错误,针对这种情况使用深度学习的方法,鞋类的自动分类是一个基本二分类的问题,首次利用卷积神经网络用于鞋类的自动分类,测试准确率达到了95%以上,验证了该网络模型的有效性。然而,本文方法还存在不足,重心放在了鞋类的识别上,对于鞋类的自动检测部分还没涉及,提取监控视频中的鞋图像只能手工截取的方式,耗费了大量时间和精力;本实验所用数据库种类还不够齐全,只分了皮鞋和运动鞋两类。下一步研究工作将是视频中行人鞋的自动检测、增加实验尽可能补全数据库,尽可能覆盖犯罪现场可能出现的鞋。
