基于多路径网络的权值调整图像语义分割算法
2020-04-21秦晓飞何玉帅严浩通
秦晓飞,何玉帅,孙 越,严浩通,林 轩
(1.上海理工大学 光电信息与计算机工程学院,上海 200093;2.上海理工大学 机械工程学院,上海 200093)
引 言
图像语义分割就是机器自动从图像中分割对象区域、识别其中的内容,对该图像像素按照类别标签进行标注。随着计算机网络的发展,越来越多的应用场景需要高精度、高效率的图像语义分割技术作为核心,尤其在自动驾驶、无人机应用及穿戴式设备应用中图像语义分割技术起着重要的作用。图像语义分割属于图像场景解析,是在像素层面上对场景进行解析。
近年来,深度学习取得了重大突破,能够提高图像语义分割精度。具有代表性的深度学习网络有 AlexNet[1]、GoogleNet[2]、VGGNet[3]等,这些网络在近年的ImageNet图像分类大赛中已成为主流。Long等[4]提出了基于全卷积网络(FCN)的语义分割算法,该网络使用VGG-16作为基准网络,在当前图像分类的标准CNN网络中对输出层添加了上采样,恢复输入图像的空间分辨率。此法可接受任意大小的输入图像,FCN方法是在网络的输入端输入原始图像,经过具有5次卷积和池化操作的编码器后,将提取到的语义信息经过3个全连接层输出,得到最终的预测图。但得到的结果不够精细和敏感,没有充分考虑像素与像素间的关系,缺乏空间一致性,导致边缘信息缺失。
针对该问题,本文提出了一种基于多路径网络的权值调整图像语义分割算法。该算法优点是改善了边缘信息的缺失情况,模型收敛快,泛化能力强。通过跳跃连接的方式,将输入端信息传递至输出端,以反向传播的形式弱化损失函数,更新网络参数。同时,将多路径网络输出的特征映射作为权值调整模块输入,精确保证图像语义信息边缘的完整性,提高网络结构的最终预测质量。
1 多路径网络权值调整图像语义分割算法
1.1 算法框架
该算法以多路径网络作为基准网络,以调整模型作为辅助设计的深度卷积神经网络。多路径网络思想被视为ResNet思想和Inception网络思想的结合,在类Inception网络框架基础上填充残差块,在信息传递过程中,将梯度消失或者梯度爆炸问题解决,不仅提高分割精度,还可以帮助网络优化,加快训练的收敛速度。调整模型捕捉多路径网络输出特征的全局上下文信息,选择性突出类别依赖项的特征图,让网络进行语义上下文学习,预测场景中的物体类别。算法结构如图1所示,即:1)给定一幅输入图像;2)通过多路径网络提取特征语义信息;3)应用调整模块对特征图权重调整;4)调整后特征图与调整前特征图卷积操作;5)将上一步中的输出进行上池化卷积操作,得到最终预测图。

图1 本文的算法结构图Fig. 1 Algorithm structure
1.2 多路径网络模型
在神经网络中,为了更好减轻网络模型学习困难、提升图像语义分割精确度,本文引用了多路径块网络模型:在类Inception网络框架思想上,按全卷积网络的深度植入5个基本结构单元。图2为多路径网络模型的基本结构,其中:表示多路径网络模型中的第一阶段残差单元;表示多路径网络模型中的第二阶段残差单元。网络结构可以让数据信息从输入到输出多路径流动,不仅防止了梯度弥散和梯度爆炸问题产生、有效加快网络收敛速度,而且在更新网络权重时,语义信息可以得到有效传递,大幅提升网络性能。
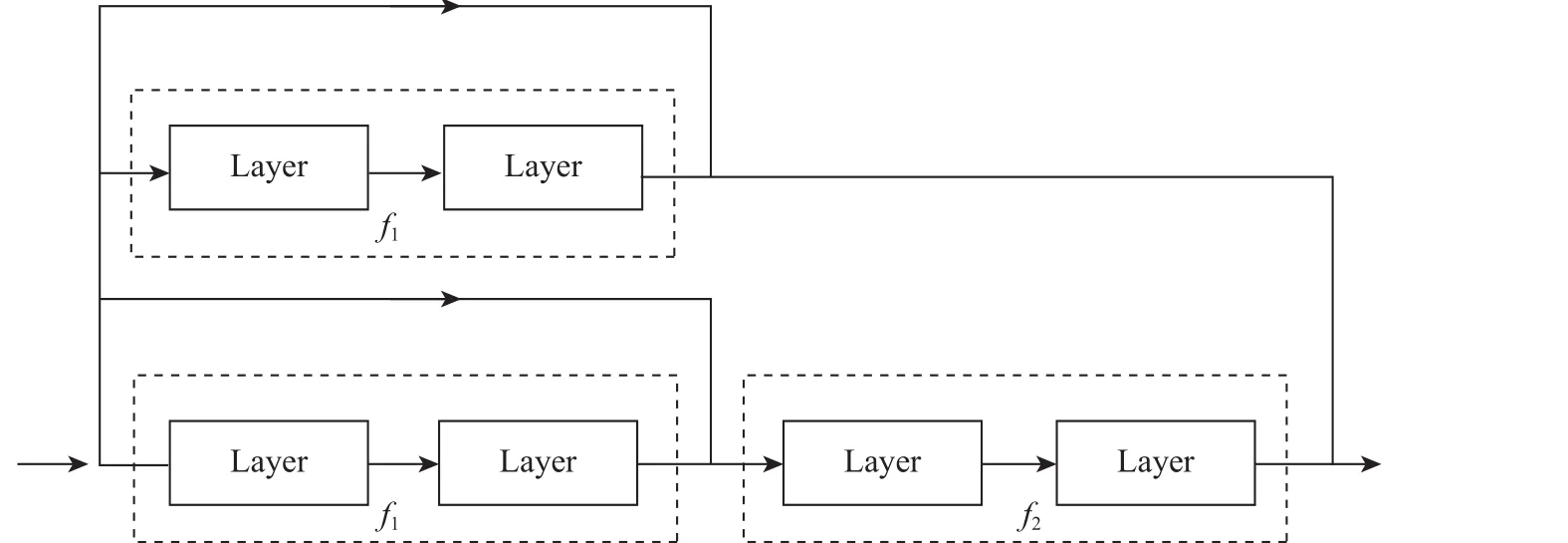
图2 多路径网络模型的基本结构Fig. 2 Basic structure of dense residual network model

为了更好解析多路径网络,本文运用递归算式推理。假设多路径块输入为,其输出为y2,则
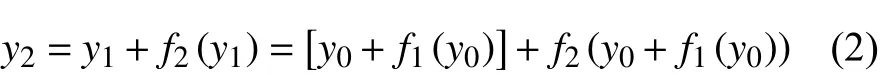
式中f1、f2表示标准的残差块模型。经实验证明,多路径网络模型优化残差映射相对优化原始映射而言,效率更高。
1.3 调整模型
解析与利用全局上下文信息对图像语义分割是至关重要的。通过模型捕捉来自深度残差网络模型的特征,本文利用其语义上下文信息设置一组缩放因子,有选择性地突出类别相关项的特征图。假设调整模型将输入特征图视为H×W×C的立方体,其中:C为特征图维度;H为特征图高度;W为特征图宽度。像素本身为XN},其中N=H×W表示像素总和。特征映射学习每个像素包含的电报密码本为对应的平滑因子为K为电报密码词的个数。本文应用叠加算法对每个维度的对应像素累加,调整模型可表示为

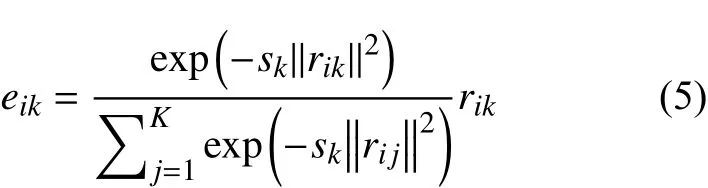
式中:sk为电报密码本的平滑因子;可表示为

其中dk为电报密码本。
这种调整算法充分利用全局上下文信息,输出具有丰富信息的特征图。将深度残差网络模型输出和调整模型输出结合,上池化至原图大小得到最终的预测。
2 实 验
2.1 评价指标与数据集
实验采用的操作系统是Windows10 64位,GTX 1080 Ti显卡,32 GB内存台式工作服务器,运行环境为Pytorch平台。
本文评价图像语义分割算法的指标是具有权威性的平均交并比(mean intersection over union,MIoU)指标,计算两个集合的交集和并集之比。在语义分割问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可变形为正真数(intersection)比真正、假负、假正(并集)之和,逐类计算IoU再平均,其表示如下:
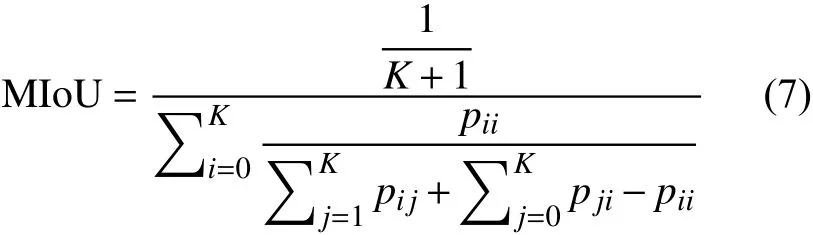
式中:pii为真实值为i、被预测值为i的数量;pji为真实值为j、被预测值为i的数量;pij为实值为i、被预测为j的数量。
深度学习需要大量数据训练本文提出的网络模型,如果数据过少,导致过拟合现象,虽在该数据样本上有较好效果,但在实际应用上泛化能力特别差。基于此,本文采用了2016年ImageNet场景分析挑战赛上使用的数据集。与其他数据集不同,ADE20K数据集包含150个类别和1 038个图像标签。它被分成包含20 000张图像的训练集,包含2 000张图像的验证集,包含3 000张图像的测试集。ADE20K数据集可以解析场景中对象,因此这是一个更具有挑战性的数据集。
2.2 结果分析
训练时,本文设置初始学习率为0.01,动量系数为0.9,重量衰减为0.000 1。对于数据增强,本文采用随机翻转缩放算法,经验证集迭代100 000次的结果作为最终的训练模型。为验证本算法的有效性,在ADE20K数据集上对本文算法与FCN、ParseNet、SegNet等语义分割算法做性能指标评估,实验数据如表1所示。从表1数据可看出,与近年来优秀的语义分割算法进行对比,本文提出算法比其中最优算法的MIoU提高了2.4%。
图3和图4是ADE20K数据集中的室外和室内2种典型的原始图像及其分割结果。图中只采用了FCN与本文算法做比较,是因为FCN在语义分割领域中具有重要的地位,目前较为流行的语义分割框架几乎全部建立在FCN的基础上。对比两种算法的分割结果可以看出,本文所提算法较FCN算法对物体边缘分割的效果有明显提升,场景解析、分割的类边缘信息丰富,验证了本文算法的有效性。
3 结束语
针对图像语义分割技术,本文提出了一种基于多路径网络的权值调整图像语义分割算法。对特征语义信息的提取,本文采用了多路径网络模型,不仅有效加快了网络收敛速度,而且在更新网络权重时信息可以得到有效的传递。为了提高场景中类别边缘的分割效果,本文引入了调整模块对得到的特征映射重新调整权值。实验发现,图像语义分割对细微物体的分割能力仍需要加强,这也是下一步的研究方向。
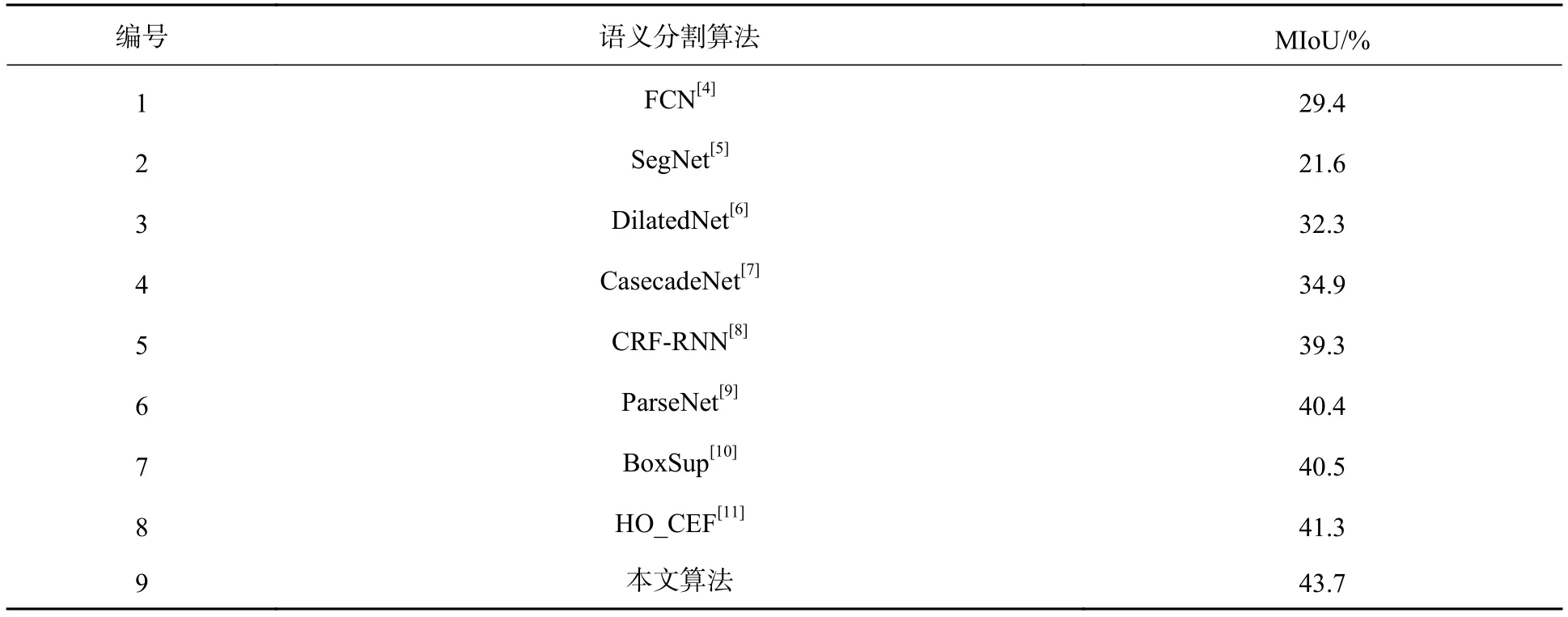
表1 图像语义分割算法对比数据Tab. 1 Comparison of semantic image segmentation algorithm data
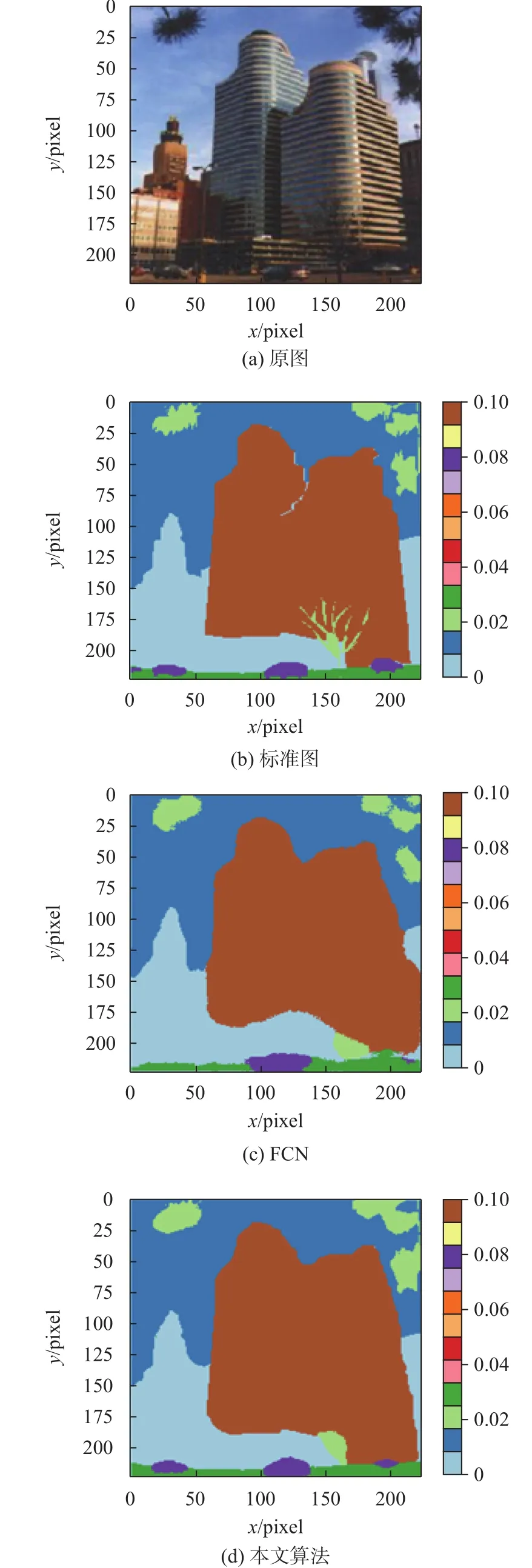
图3 室外实验对比Fig. 3 Outdoor experiment comparison
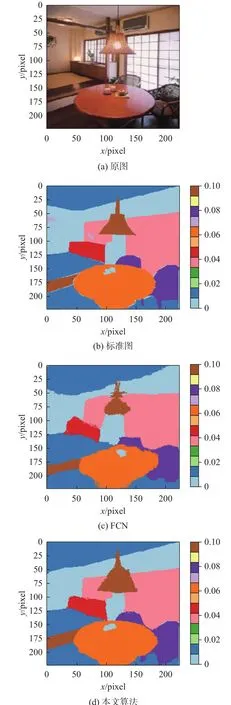
图4 室内实验对比Fig. 4 Indoor experiment comparison
