最小熵迁移对抗散列方法
2020-04-21卓君宝王树徽黄庆明
卓君宝 苏 驰 王树徽 黄庆明
1(智能信息处理重点实验室(中国科学院计算技术研究所) 北京 100190) 2(中国科学院大学计算机科学与技术学院 北京 100049) 3(数字视频编解码技术国家工程实验室(北京大学) 北京 100871)
大数据时代的到来,网络上涌现了大量的高维图像数据.图像检索越来越受到学术界和工业界的关注.随着深度学习的普及,深度散列方法[1-7]也备受关注,其性能远远超过了传统的无监督方法[8-10]和基于浅层模型的有监督方法[11-13].然而深度学习方法往往需要大量的标注信息,搜集这些标注信息往往耗费巨大人力物力.此外,大多数现有的深度学习方法都基于独立同分布的假设,即训练集(源域)和测试集(目标域)的分布一致.然而在现实应用中,源域和目标域往往存在较大的差异.因此利用有标注的数据集(源域)并迁移到相关的无标注目标域[14-19]受到极大的关注和发展.然而在图像检索领域,跨域迁移学习的研究处于起步阶段,仍待继续研究.跨域图像检索的难点在于目标域无标注且与源域存在较大域间差异,这种差异往往导致在带标注源域上训练好的模型应用于目标域时检索性能大幅度下降.如何学习具有判别力和域不变的散列码是跨域图像检索的重点.
深度适配散列(deep adaptive hashing, DAH)[20]首次将域适配的方法应用于跨域图像检索任务中,在学习散列码的同时,DAH引入最大均值差异(maximum mean discrepancy, MMD)[14-15]来度量域间差异,通过最小化MMD来学习域不变的散列码.此后迁移对抗散列(transfer adversarial hashing, TAH)[21]提出将跨域识别中经典的域对抗网络[19]应用到跨域图像检索中.TAH通过引入一个域分类器来判别源域和目标域的分布是否一致,采用对抗思想促使所学的源域与目标域散列码分布趋于一致,进而学习到域不变的散列码,取得了当前最好检索性能.
然而现有深度跨域图像检索方法仍然存在2个问题:1)在学习散列码时,标注信息仅仅被用于构建2个样本是否相似的监督信息去指导网络的学习,忽略了标注信息的语义信息.这使得所学的散列码的判别力不足,造成检索性能的瓶颈.2)现有的分布对齐方法学习域不变特征的能力仍然不足,使得将源域学习得到的散列函数应用于目标域时性能仍然有较大下降.
针对上面2个问题,我们提出语义保持模块和最小熵损失来改进现有深度跨域图像检索方法.首先,我们在散列特征后再引入一个分类子网络,通过源域的标注信息来训练该分类子网络并将语义信息反传给生成散列特征的子网络,有效保持了散列码的判别力.此外,在目标域上,由于没有语义标注信息,无法像源域那样引入监督信息.因此我们引入最小化目标域样本的类别响应分布的熵来促使目标域样本的类别响应能够集中在某个类别上.最小熵损失有效增强了散列码的泛化能力.
基于TAH模型以及我们所提的语义保持和最小熵损失,我们构建了一个新的可端到端训练的跨域图像检索网络.由于语义保持采用的多类别的交叉熵损失也是一种熵,因此我们称所提的模型为最小熵迁移对抗散列(min-entropy transfer adversarial hashing, METAH).我们在2个数据集上进行了大量实验,与领域内现有主要模型进行了详尽的对比,实验证明了所提模型取得了更优的性能,证明了所提语义保持模块和最小熵损失的有效性.
1 相关工作
跟我们工作相关的2个任务分别是跨域识别和基于散列的图像检索.我们将从这2个任务进行相关工作的阐述.
1.1 跨域识别
跨域识别又称为域适配(domain adaptation, DA),跨域识别已经得到很大的发展,这里我们只回顾和我们方法比较相关的深度域适配方法.
深度域混淆网络(deep domain confusion, DDC)[14]基于AlexNet架构,其在fc7层上使用单核的MMD来度量域间的差异,通过最小化MMD来使域间差异减小从而学到域不变的特征.深度适配网络(deep adaptation network, DAN)[15]则在多个全连接层上使用多核的MMD来度量域间差异,进一步加强特征迁移能力.深度相关对齐(deep correlation alignment, DCORAL)[17]和深度无监督卷积域适配(deep unsupervised convolutional domain adaptation, DUCDA)[16]则用源域特征协方差和目标域特征协方差之间的差值矩阵范数来度量域间差异,从而减小深度网络的特征分布距离以学习域不变的特征.群体匹配差异(population matching discrepancy, PMD)[22]则是对源域和目标域间的样本计算最优匹配,将匹配的样本对间的距离进行累加来表征域间差异,通过最小化PMD来学习域不变的特征.
生成对抗网络(generative adversarial network, GAN)[23]的提出让基于特征的跨域迁移方法又有了新的突破.域对抗网络[19]、对抗判别域适配(adver-sarial discriminative domain adaptation, ADDA)[24],和条件对抗域适配(conditional adversarial domain adaptation, CADA)[25],都是利用对抗思想将目标域特征空间向源域特征空间靠近,从而让目标域的特征可以适配源域的特征分类器.
1.2 散列方法
散列方法是经典的研究方向,主要包括无监督散列[8-10]和有监督散列[1-7,11-13].这里只回顾和我们的方法比较相关的有监督深度散列方法.
卷积神经网络散列(convolutional neural network hashing, CNNH)[4]采用2阶段策略:1)先学散列码;2)学习一个深度网络将图像映射到所学的散列码.深度神经网络散列(deep neural network hashing, DNNH)[5]改进了CNNH,不采用2阶段训练策略而是同时学习图像特征和散列函数,这种端到端训练方式能够更加充分利用深度网络的特征学习和函数拟合能力.深度散列网络(deep hashing network, DHN)[6]进一步优化DNNH,通过引入交叉熵损失和量化损失来保持相似度和约束量化误差.散列网络(HashNet)[7]则解决了符号函数的病态梯度问题,直接优化符号函数,HashNet是单域图像检索最好的方法.深度语义排序散列(deep semantic ranking hashing, DSRH)[26]则考虑了多标签图像间的语义相似度.
2 最小熵迁移对抗散列方法
2.1 模型框架
如图1所示,我们的模型采用孪生网络结构,且上下2个子网络权值共享.子网络基于AlexNet,该网络由conv1~conv5共5层卷积层和fc6~fc8共3层全连接层构成.我们用1个输出为b的全连接层fchashing替换fc8用于学习散列函数f.由于fchashing难以学习到离散的输出,因此我们对其放宽了限制,即约束fchashing输出[-1,1]的连续值.为了能将所学的散列函数泛化到目标域,我们在fchashing后经过梯度取反层(图1中2个沙漏所表示),之后引入1个域分类器ad_net.该域分类器的作用在于促使fchashing学到域不变的散列特征.此外,为了更好地保持散列码的语义信息,我们在fchashing后增加语义保持模块,这里我们用1层全连接层fccls来构建语义保持模块,它将散列码映射到类别空间.我们称所提方法为最小熵迁移对抗散列(METAH).

Fig. 1 Framework of the proposed method图1 所提方法的结构图
2.2 学习散列函数
我们采用经典的最大后验估计(maximum a posterior, MAP)来使得所学的散列函数能够保持成对样本间的相似度或不相似度.
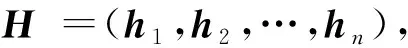
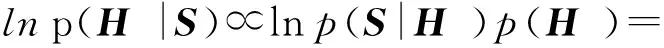
(1)
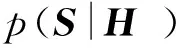
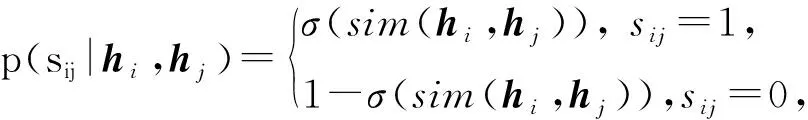
(2)


(3)
将式(2)和式(3)代入最大后验估计式(1)可以得到以下损失:
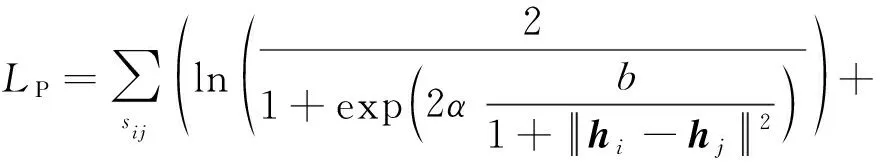
(4)

(5)
其中,1=(1,1,…,1)是全为1的b维向量,|·|是绝对值函数,即将输入向量的每个元素取绝对值.
2.3 对抗分布对齐
在跨域图像检索中,由于源域和目标域存在较大分布差异,且目标域没有标注信息,将源域训练好的模型应用于目标域时会造成性能大幅下降.因此我们需要在学习散列码的同时缩小域间差异,使得所学习的散列码是域不变的.
域对抗网络[19]是一个典型的域分布对齐方法,发展至今,域对抗方法具有良好的理论保证且在跨域识别达到较优的性能.本文也采用域对抗思想来减小域间差异.域对抗思想是引入一个域分类器,其作用是区分样本特征来自源域还是目标域.由于我们训练时知道样本来自于源域或目标域,域分类器可以通过这种标注来训练,即最小化二分类交叉熵损失.而另一方面,我们希望所学到的特征是域分类器区分不开的,即最大化二分类交叉熵损失.从分布拟合的角度来看,域分类器用于区分2个域的分布,而特征生成器则拉近2个域的分布,进而减小域间差异.
记GF为散列特征生成器即conv1~conv5,fc6~fc7,fchashing所组成的子网络,其可训练参数为θF.域分类器GD的可训练参数记为θD.则域对抗网络的损失为

(6)
式(6)是二分类的交叉熵损失.对抗学习则是寻求损失函数LD(θF,θD)的鞍点:
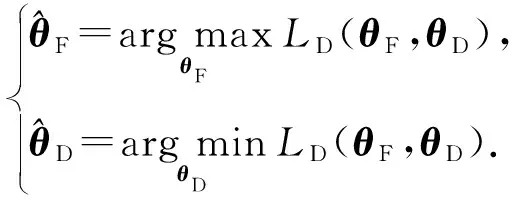
(7)
求解式(7)需要分开优化,且这种方式训练比较困难.因此我们也采用梯度取反层[19]来实现对抗学习,具体方法是引入梯度取反层(图1沙漏所示),操作为
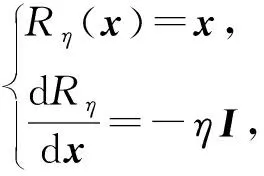
(8)
其中,I是单位阵.梯度取反层正向计算时其输出保持不变,而反向传播时将原梯度取反并乘以η.
因此,域对抗网络的损失为

(9)
2.4 语义信息保持

(10)
其中,〈·,·〉是内积.引入该分类损失大大增强了散列特征的判别力,增强了模型的泛化能力.
2.5 最小熵
在目标域中,一个理想的散列码在经过fccls后得到的分类响应应该集中于某一类上.由于目标域没有标注,我们无法知道目标域样本应该属于哪一类,因此我们通过最小熵来促使目标域样本分类响应集中于某一类上.熵的计算为
(11)
源域由于有标注信息,其样本的分类响应往往集中在所标注的类别上;而目标域由于存在域间差异,其在分类响应上往往不够集中.最小熵能够在语义层减小源域和目标域的域间差异,进而影响特征层,使得特征层的域间差异也相应减小,即增强了散列码的域不变能力具有更强的泛化能力.
2.6 总损失
综合2.2~2.5节,我们采用最终目标损失来训练所提的最小熵迁移对抗散列方法:
L=λPLP+λQLQ+λDLD+λCLC+λELE,
(12)
其中,λ*是一些控制各个损失间平衡的超参数.
3 实验与结果
我们在2个常用数据集上进行了大量实验,并与领域内现有主要模型进行了详尽的对比.实验证明了所提模型取得了更优的性能.
3.1 实验设置与对比算法
NUS-WIDE是一个跨模态检索常用的数据集,其包含269 648个文本-图像对.该数据集标注了81个语义概念用于测试检索算法的性能.为了公平比较,我们沿用文献[5-8]的设定,只在出现频率最高的21个语义概念所涵盖的195 834张图像上做实验.查询集包含2 100张图像,训练集包含10 000张图像,剩下的作为被检索的数据库.
VisDA-2017是一个跨域识别常用的数据集,其包含2个域,源域由CAD模型渲染生成的12类图像构成,记为Syn,目标域是在COCO上选取的相应类别的子集,记为Real.由于该数据集域间差异比较大,我们构建2种设定:1)查询集和数据库都采用Real域而带标注训练集为Syn域,记为Syn→Real;2)查询集和数据库都采用Syn域而带标注训练集为Real域,记为Real→Syn.
我们在汉明距离小于2(Hamming radius 2)的检索结果上计算平均精度均值(mean average precision, MAP)作为评测性能.对比算法包括局部敏感散列(locality sensitive hashing, LSH)[8]、谱散列(spectral hashing, SH)[9]、迭代量化(iterative quantization, ITQ)[10]等传统无监督方法;核散列(kernel supervised hashing, KSH)[12]、监督离散散列(supervised discrete hashing, SDH)[13]等有监督浅层模型;CNNH[4], DNNH[5],DHN[6],HashNet[7]等单域有监督深度模型以及传递散列网络(transi-tive hashing network, THN)[27],TAH[21]等跨模态或者跨域的有监督深度检索方法.为了更好地验证和分析我们所提的语义信息保持模块和最小熵的有效性,我们构造了2个变体METAH-e和METAH.其中METAH-e中λE=0,即不加最小熵损失.
为了公平比较,我们的算法也是基于在ImageNet上与训练好的AlexNet上.我们采用Caffe框架来微调conv1~conv5等卷积层和fc6~fc7等全连接层.此外,我们多加1层全连接层fchashing层,并在fchashing层后接2个分支:1)2层全连接层构成的子网络ad_net用于对抗学习;2)1个分类全连接层fccls构成的语义保持模块.fchashing,ad_net,fccls等新加全连接层的学习率设置为conv1~conv5,fc6~fc7学习率的10倍.整个优化过程采用冲量为0.9的小批量随机梯度下降法(stochastic gradient descent, SGD).1次迭代对每个域随机抽取64张图像用于估计梯度.权重衰减设为0.0005.在3.3节中的梯度取反层中的参数η的更新为:η=2/(1+exp(10i)),其中i是当前迭代的次数.式(12)中的超参数设置如表1所示:
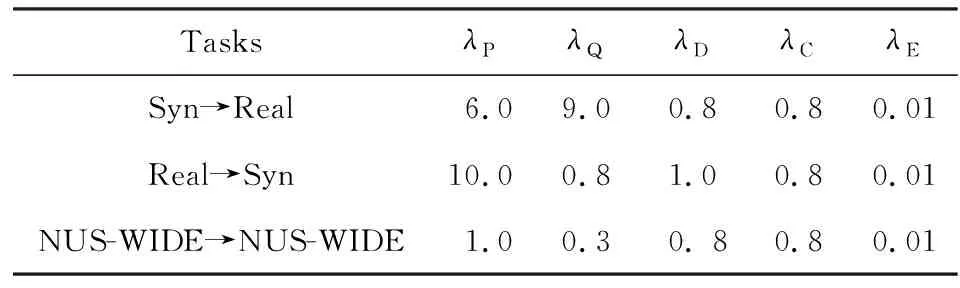
Table 1 Values for Hyper-Parameters表1 超参数设置
3.2 定量实验结果
NUS-WIDE上的平均精度均值如表2所示.我们可以看出:即使在训练集和测试集域间差异几乎不存在的情况下,我们的方法也能取得最优的结果.在散列码的长度分别为48 b和64 b的设定中,我们的方法比TAH[21]的平均精度均值分别提高了0.086和0.087.在32 b设定中,我们的方法提升很小,原因在于32 b维度太小,模型能力较弱,不能同时学习散列码和保持语义信息.而在48 b和64 b的设定中,语义信息保持(METAH-e)所带来的性能提升则非常显著.由于域间差异几乎不存在,METAH相比于METAH-e性能提升很小甚至起负迁移的作用.
上述现象符合我们的预期,因为最小熵的作用在于减小域间差异,对于域间差异几乎不存在的设定中,强行减小域间差异反而会带来反作用.

Table 2 MAP Results Within Hamming Radius 2 on NUS-WIDE
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
VisDA-2017上Syn→Real的平均精度均值如表3所示.在散列码的长度分别为32 b,48 b,64 b的设定中,我们的方法比TAH的平均精度均值分别提高了0.048,0.101,0.101.可以看出由于32 b维度较小,METAH的平均精度均值提升相比于48 b和64 b较小.由于该任务中源域和目标域存在较大差异,因而我们所提的最小熵作用更加明显.因此在32 b,48 b,64 b的设定中,METAH相比于METAH-e的平均精度均值分别提升了0.023,0.024,0.038.值得注意的是我们对不同长度的散列码都采用同样的超参数,而TAH各个设定的超参数都是通过交叉验证获得的,所以METAH具有更大的潜能.
VisDA-2017上Real→Syn的平均精度均值如表4所示.相比于最好的对比算法TAH[8],我们的方法METAH在散列码的长度分别为32 b,48 b,64 b的设定中平均精度均值分别提高了0.001,0.008,0.071.相比于Syn→Real,在Real→Syn上METAH的提升较小,原因可能是我们使用了和Syn→Real同样的超参数设置,即λC=0.8,λE=0.01,然而对于跨域图像检索的设定,目标域是无标注的,因此通过交叉验证针对不同长度散列码去搜索最优的参数是不可取的,所以我们这里针对所有不同长度散列码都只用一套相同的超参数.此外,在散列码的长度分别为32 b,48 b,64 b的设定中,METAH相比于METAH-e的平均精度均值分别提升了0.008,0.010,0.003.证明了所提的最小熵在减小域间差异上的有效性.

Table 3 MAP Results Within Hamming Radius 2 on Syn→Real
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
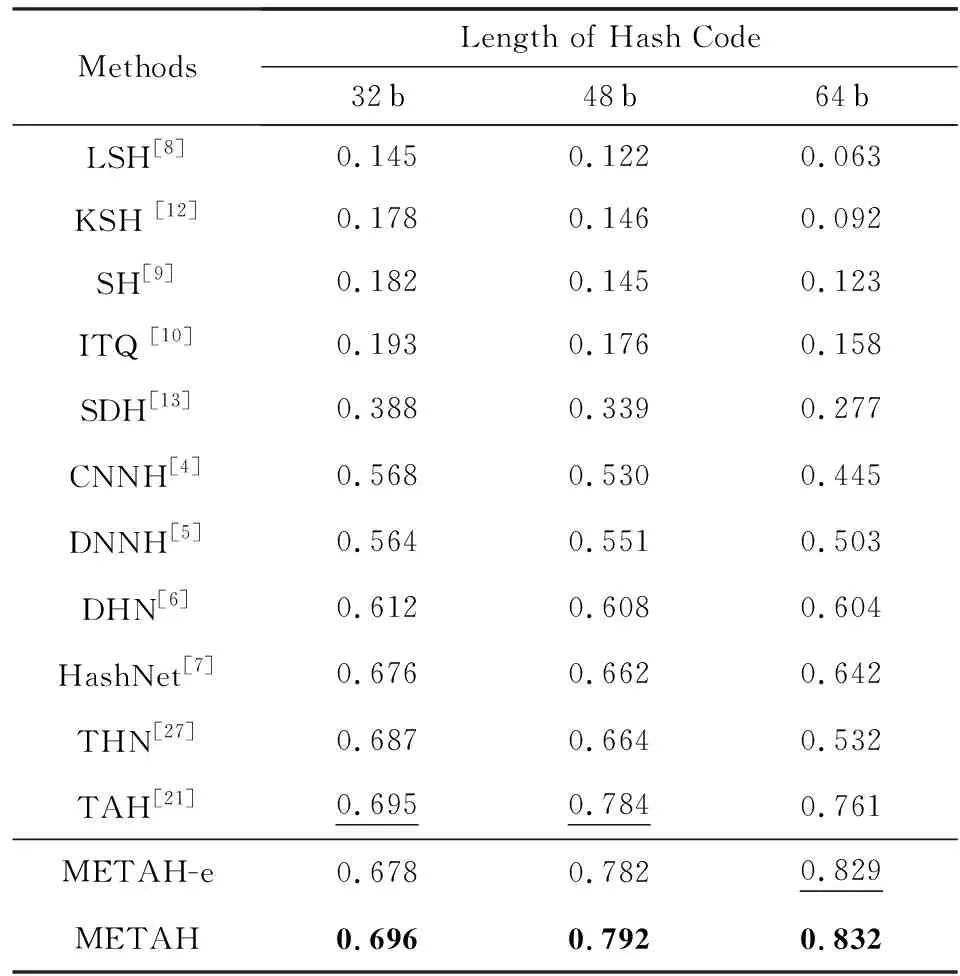
Table 4 MAP Results Within Hamming Radius 2 on Real→Syn
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
3.3 定性实验结果
我们在VisDA-2017数据集上进行了可视化实验.在Syn→Real任务中,我们在Real域随机选取了1个查询,并在Real域构成的数据库中进行检索,我们列出前10的检索结果,与TAH,METAH-e的对比结果如图2所示.虚线框指错误检索结果,实线框指正确检索结果.可以看出METAH-e和METAH的查询结果相比于TAH错误结果更少,证明了所提方法的有效性.在Real→Syn上的检索结果如图3所示,我们可以观察到相似的现象,即METAH-e和METAH的查询结果相比于TAH错误结果更少.

Fig. 2 Examples of top 10 retrieval images and P@10 in Syn→Real图2 在Syn→Real上前10检索结果和P@10值

Fig. 3 Examples of top 10 retrieval images and P@10 in Real→Syn图3 在Real→Syn上前10检索结果和P@10值
4 总 结
在本文中,我们针对现有深度跨域图像检索方法所学散列码判别力和域不变能力不足这2个问题,提出了语义保持模块和最小熵损失来改进现有的模型.语义保持模块能够使所学到的散列码包含更多的语义信息.最小熵能使目标域样本与源域样本在语义空间上分布更加对齐,使得散列码更具域不变性.大量的实验表明我们的模型相比于领域内主要模型取得了更优的性能,验证了所提改进技术的有效性.
