面向异构IoT设备协作的DNN推断加速研究
2020-04-21李叙晶过晓冰
孙 胜 李叙晶 刘 敏 杨 博 过晓冰
1(中国科学院计算技术研究所 北京 100190) 2(中国科学院大学 北京 100049) 3(联想研究院 北京 100085)
近年来物联网(Internet of things, IoT)设备越来越普遍,根据Gartner数据显示,到2021年IoT设备数量预计将达到250亿[1].目前深度神经网络(deep neural network, DNN)发展迅速,已经广泛应用于各种各样的智能任务(如计算机视觉、视频识别和机器翻译),IoT设备期望能够执行DNN推断任务以实现实时数据处理和分析.例如在智能家居场景中,摄像机可以执行基于DNN模型的视频识别和语音翻译任务.然而,由于IoT设备资源受限,而且DNN任务需要大量的计算资源和内存占用,因此,IoT设备难以本地单独执行DNN推断任务.为了克服上述挑战,文献[2]提出在单个IoT设备和云服务器之间拆分DNN模型以实现任务推断加速.然而,受限于传输数据量较大以及网络通信延迟不可预测等因素,云协助执行DNN任务推断的方法难以保障数据处理效率,而且会增加对云服务的依赖性.
聚合多个IoT设备的计算能力以共同执行DNN任务是一种有效的解决方式.这种方式的优势在于减少对云服务的依赖,保护IoT设备的隐私性,并且能够实现分布式协同计算.文献[3]首次利用资源受限的多个IoT设备协作执行语音和视频识别等DNN任务.文献[4]提出DeepThings框架进行卷积层划分以减少整体执行延迟和内存占用.然而,现有研究工作仅考虑IoT设备同构情况,而且无法实现实时动态DNN任务拆分.如何在动态异构场景中进行DNN任务的高效拆分和协作推断是亟待解决的关键问题.
上述研究问题面临两大重要挑战.首先,不同参数配置(层类型、层数量、卷积核大小、输入特征规模等)和异构设备能力导致显著的推断延迟差异.按需执行DNN推断任务以获得每种系统设置和任务拆分策略下的推断延迟是不切实际的,因此需要提前预测当前系统状态和拆分协作策略所产生的推断延迟.现有DNN延迟预测模型建立在单层预测的基础上,通过单层预测延迟加和得到多层预测延迟.但是文献[5]通过实验发现单独执行每层的延迟加和与整体执行延迟的差值随着卷积层数量的增加越来越明显,现有的DNN延迟预测模型无法在可接受误差范围内进行推断延迟的有效评估和预测.而且现有延迟预测模型仅考虑特定参数配置,并未考虑设备能力对DNN推断延迟所产生的影响.因此,研究多种参数配置和异构设备情况下的精准多层延迟预测模型具有重要意义.
DNN任务拆分在分散计算量的同时会产生通信开销.虽然增加协作执行DNN任务的设备数量会降低单个设备的计算延迟,但是同时会导致设备间的通信延迟增加.因此,协作拆分策略需要高效权衡计算和通信延迟.由于DNN结构、网络状态以及设备能力是动态变化且高度异构的,DNN任务拆分和协作推断策略需要依据当前系统状态进行动态调整和高效决策,确定执行任务的设备数量,选择DNN任务的拆分位置以及为每个设备分配的计算任务,以获得最优DNN推断加速且充分利用IoT设备的计算能力[6].针对上述问题,传统优化方法计算复杂度高、求解时间长,难以应用.基于数据驱动的人工智能方法可以通过数据处理分析,经过训练和学习建立自动化决策模型,当系统状态发生变化时直接根据学习的决策模型制定决策,从而实现自适应、智能和实时决策.本文采用基于数据驱动的学习算法能够在设备能力、网络状态以及DNN任务多样化的情况下制定实时智能的DNN任务拆分和协作推断策略.
本文提出一种新颖的IoT设备协作执行DNN任务推断(IoT-collaborative DNN inference, IoT-CDI)框架,依据DNN结构、设备能力以及网络状态等多种因素,自适应调整DNN拆分和任务分配策略,能够在资源受限的异构IoT设备间实现DNN协作推断,充分利用IoT设备的计算能力以最小化DNN任务的推断时延.本文的主要贡献包括3个方面:
1) 细粒度刻画DNN模型层类型、参数配置以及设备能力等多种特征,挖掘特征与执行时延之间的复杂映射关系,生成可解释的多层延迟预测模型,通过大量实验评估多种常见的预测模型进而获得适合多层延迟预测的精准模型.
2) 将原始DNN拆分和协作推断问题转换为最短路径发现问题,并将该问题归约为NP难问题;提出基于进化增强学习(ERL)的自适应DNN拆分和协作推断算法,在异构设备间实现实时智能的DNN推断加速.
3) 利用真实实验进行验证.选取5种常见的DNN模型和多种类型的树莓派设备验证提出的IoT-CDI框架的有效性,实验结果表明:IoT-CDI能够显著提升推断速度,并且优于基准算法.
1 相关工作
1.1 端云协作推断研究
受限于IoT设备内存限制和计算资源约束,现有工作主要致力于研究IoT设备和云服务器间的DNN任务协作推断策略.文献[2]首次在神经网络层粒度上制定移动设备和云服务器之间的细粒度DNN拆分算法以降低推断延迟和能量消耗.文献[5]针对3种典型的DNN结构,将最优DNN任务拆分问题转换为图模型最短路径问题,并利用整数线性规划方法进行求解.文献[7]提出基于树形回归模型的DNN推断延迟预测算法.文献[8]作者设计灵活高效的两步剪枝算法,依据层级数据传输和计算延迟、可容忍精度损失、无线信道以及设备计算能力等多种因素确定修剪模型和最优DNN拆分位置,在降低计算和通信传输负载的同时满足DNN任务的推断精度需求.文献[9]设计自适应DNN拆分算法,能够在动态时变的网络负载状态下找到最优拆分策略.
尽管IoT设备与云服务器协作推断可以利用云服务器的计算能力降低推断延迟,但是仍然存在高度依赖云服务器、不可扩展推断、通信延迟较长以及设备隐私保护等问题.
1.2 IoT设备协作推断
由于云协助DNN任务推断面临上述问题,一种新兴研究趋势是将资源受限的IoT设备的计算能力聚合,多个IoT设备协作执行DNN推断任务.文献[10]首次利用多个IoT设备协同执行DNN推断,通过减少单个设备的计算成本和内存占用实现任务推断加速.文献[3]考虑模型和数据并行性、内存使用量、通信开销以及实时数据处理性能等多种因素,在IoT设备间提出一种高效分布式的DNN协作推断方法,并利用视频识别和动作识别模型进行性能验证.文献[4]作者采用卷积层融合分块划分(fused tile partitioning, FTP)和高效任务调度机制,动态平衡多设备间的计算负载,进而有效提升设备间协作推断速度.然而现有研究工作并没有考虑IoT设备能力异构以及环境状态动态变化的情况,而且现有求解方法难以在环境配置多样化和问题求解计算复杂度高的情况下实现实时自适应决策.值得注意的是,上述工作与利用权重剪枝[11-12]、量化[13-14]和低精度推理[15-16]等降低DNN模型计算开销的压缩与加速方法是正交的,可以同时利用这2种技术实现DNN推断加速.
2 背景介绍及研究动机
本节首先介绍DNN层类型和特性,然后根据真实实验分析引出本文的研究动机.
2.1 DNN层类型
DNN任务包含多种层类型,例如卷积层(conv)、全连接层(fc)、池化层、激活层以及Softmax层等.其中,卷积层和全连接层的计算花销和内存占用最多.文献[10]研究了3种常见DNN模型中不同层类型的内存使用和计算时间情况.实验结果表明卷积层占据总计算时间的86.5%~97.8%;全连接层内存占用最大,占内存开销的87%以上.因此,本文仅关注DNN模型中的卷积层和全连接层.
2.2 真实问题
1) 模型预测.目前研究工作仅考虑不同层类型在不同配置参数情况下的单层延迟预测模型[7].然而,文献[5]表明通过单层延迟累加方法评估多层延迟存在明显预测误差.我们进行真实实验对多层延迟预测问题进行全面分析,揭示单独执行每层的延迟加和与整体执行多层的实际延迟之间的真实关系.研究具有不同通道类型数量的DNN模型,随着不同通道类型数量逐渐增加,DNN模型的相似度逐渐降低.如图1所示,横坐标表示不同通道类型的数量,纵坐标表示整体执行延迟与单独执行延迟加和相比降低的比例.在卷积层通道类型相同的情况下,整体执行延迟与单独执行的延迟加和相比降低了50%,若不同通道类型数量较多则意味着卷积层相似度较低,单独执行的延迟加和近似等于整体执行延迟.本实验为制定多层延迟预测模型提供说服力,用于更好地指导DNN任务拆分和协作推断.
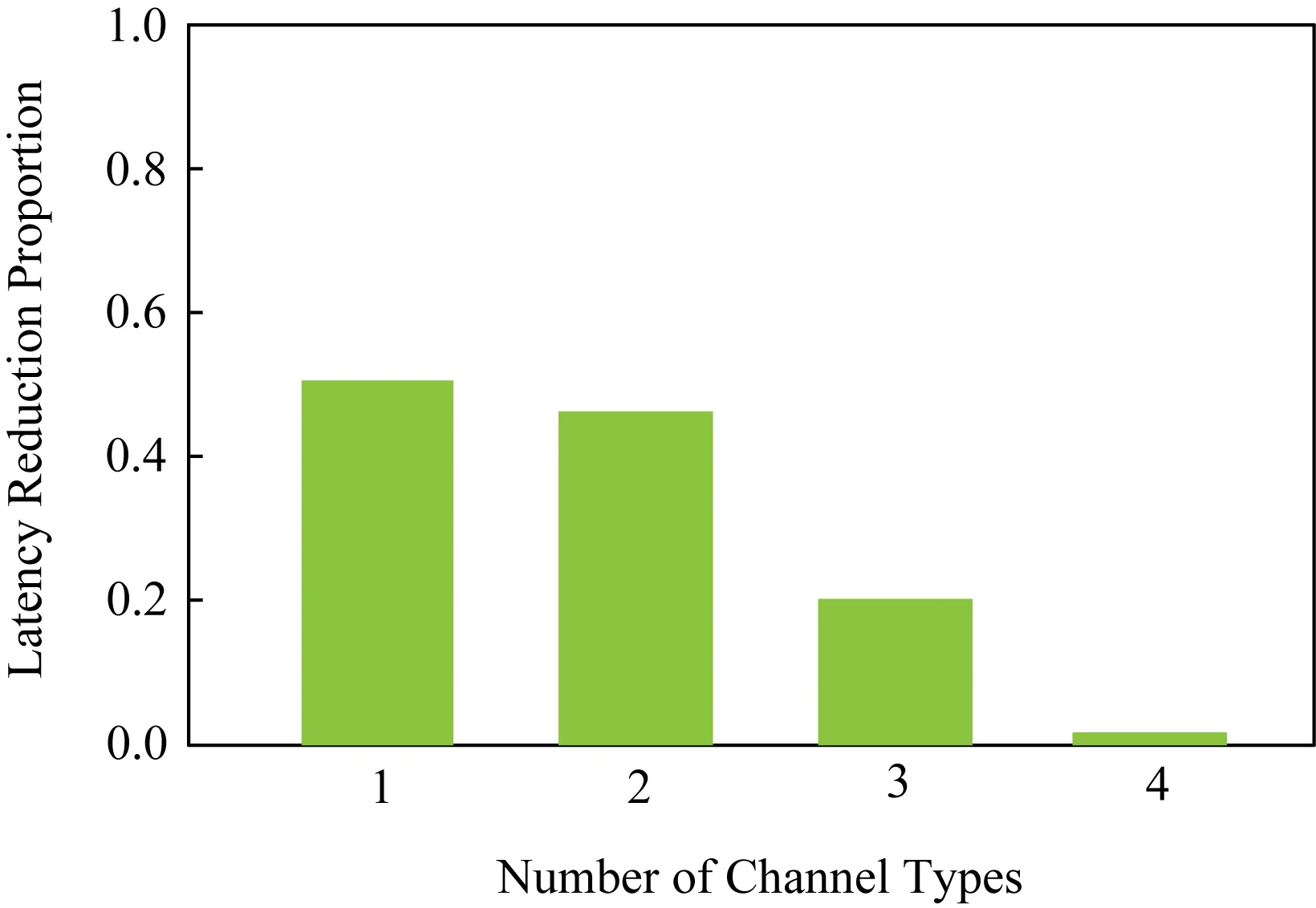
Fig. 1 Latency difference of grouped and separated execution图1 整体执行和单独执行的推断时延差异性
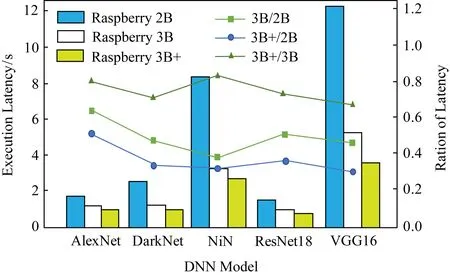
Fig. 2 Inference latency of heterogeneous devices for multiple DNN models图2 多个DNN模型在异构设备上的推断延迟
2) 设备异构性.首先测量5种常见的DNN模型在3种型号树莓派(树莓派2B、树莓派3B和树莓派3B+)上执行的推断延迟.在每种型号树莓派设备上分别执行5种DNN模型,实验结果如图2所示,柱状图表示推断时延,折线图表示不同设备执行时延的比值,例如AlexNet模型在树莓派2B上执行所需的推断延迟为1.66 s,而在树莓派3B上执行推断延迟降低为1.06 s,仅为树莓派2B推断延迟的64%,由此可知,设备能力差异性会显著影响DNN任务的推断延迟.而且随着DNN模型计算量的增加,不同设备执行DNN任务产生的推断时延差异也越来越明显.VGG16模型在树莓派2B和3B上执行的推断延迟分别为11.68 s和5.24 s,执行速度提升约2.23倍.本实验表明,DNN拆分应该考虑设备的异构能力,充分利用设备的计算资源以实现近似最优推断加速.为此,需要设计精准模型以分析设备异构能力对DNN推断延迟产生的影响.
3 IoT-CDI模型
3.1 系统模型
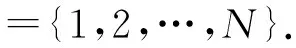
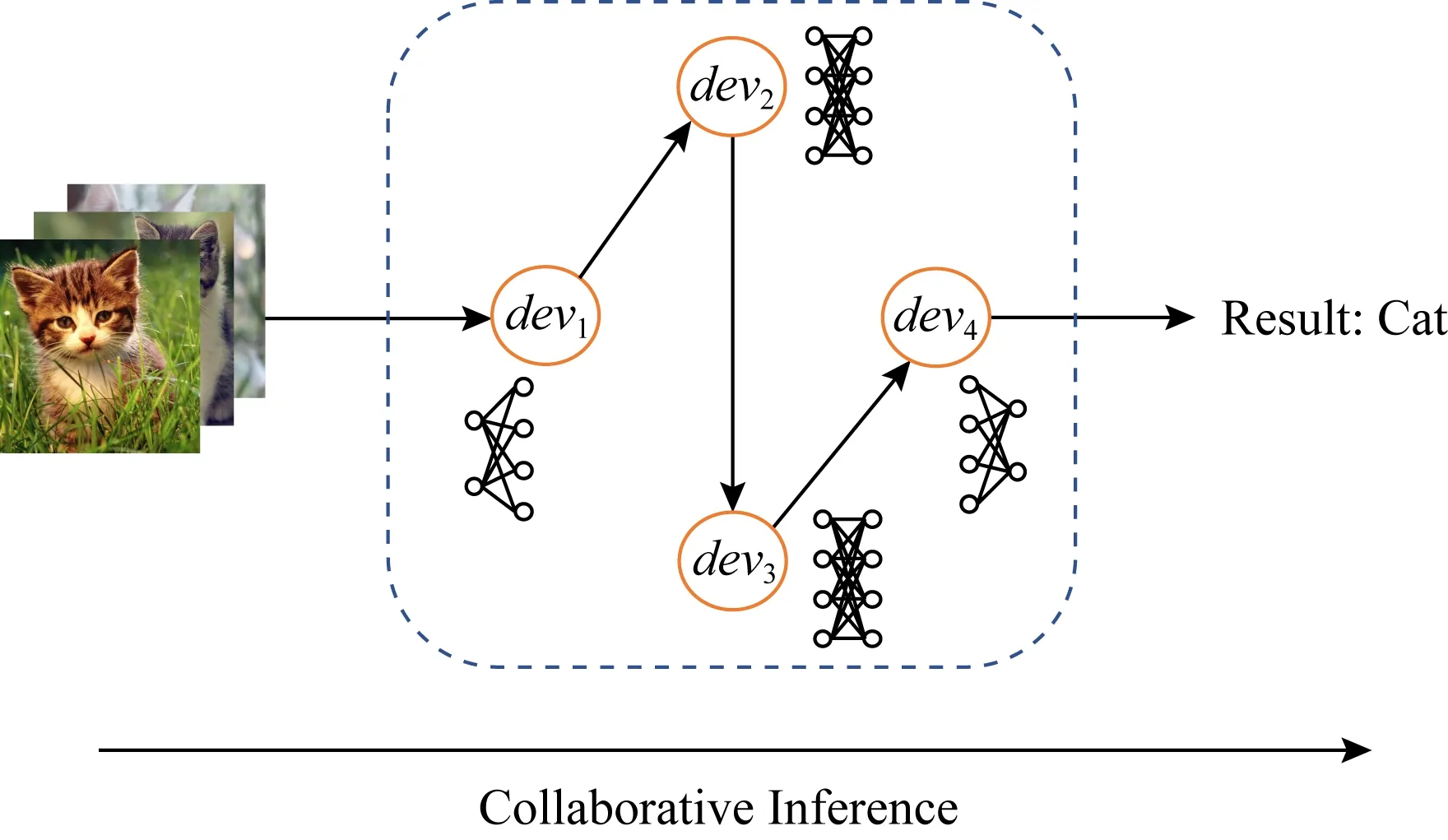
Fig. 3 An illustration of IoT-CDI图3 IoT-CDI场景示意图
给定可用设备数量N和DNN子任务数量(层数)K,目标是找到DNN任务的拆分位置和这些设备的最优任务分配.对于每个子任务k,找到一个IoT设备devi来执行它,每个IoT设备devi执行完分配的计算任务(DNN任务的某些层)后将产生的输出数据传输给执行下一层任务的设备,直到DNN任务推断完成.研究目标是最小化DNN任务的整体执行时延.如果所有子任务都在一个IoT设备上执行,单个IoT设备资源受限会导致计算延迟较长.然而如果任务分配给多个IoT设备,通信延迟明显增加.因此,需要合理拆分和分配DNN任务,有效权衡通信和计算延迟,实现DNN任务整体推断延迟最小化.
3.2 问题描述
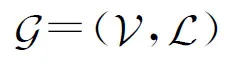
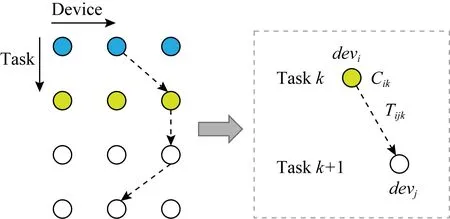
Fig. 4 Graph illustration of IoT-CDI图4 IoT-CDI图模型示意图
IoT-CDI问题可以转换为从第1层1st到最后一层Kth的最优路径问题,问题表示为:
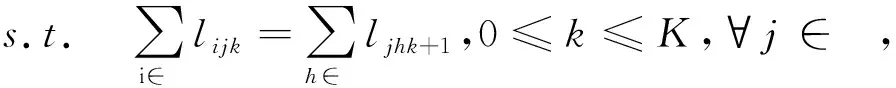
(1)
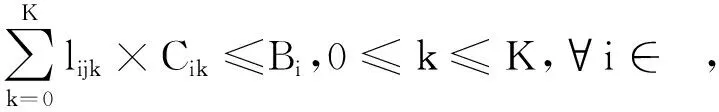
(2)
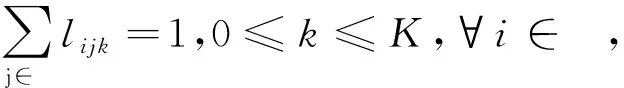
(3)
lijk∈{0,1}.
(4)
式(1)表示如果第k+1层分配给IoT设备devj,需要选择从IoT设备devj出发的一条边.式(2)表示每个设备的内存限制.式(3)确保每一层仅由一个设备执行.
此外,DNN推断通常由多个输入数据流组成,因此优化目标需要是面向数据流的,一旦确定DNN拆分策略,需要根据策略对每一帧按序处理,我们引入流水线处理概念如图5所示.具体来说,对于2个连续的数据帧,IoT设备devi首先完成数据帧1分配的任务,当数据帧2到达后IoT设备devi将立刻执行数据帧2的任务.很显然,流水线处理方式的瓶颈在于处理单帧时间最长的设备即Tijk的最大值.我们通过实验验证这一事实.将VGG16模型拆分为3部分,分别在不同设备上执行,每个设备执行一帧的时间分别为2.374 s,7.768 s和1.456 s,执行单帧任务时3个设备推断时延的最大值为7.768 s,实验测试100帧的总执行延迟大约等于100×7.768 s.为了使DNN拆分和任务分配策略能够支持流水线处理,将延迟计算公式修改为每个IoT设备单独执行延迟的最大值.本文提出的多设备协作执行DNN任务的方式聚合了多个设备的计算能力,充分利用并发处理能力,从而可以有效提高总体吞吐量,通过在多个IoT设备间实时自适应拆分DNN任务,实现最小化处理完所有数据帧的总推断延迟的目标.
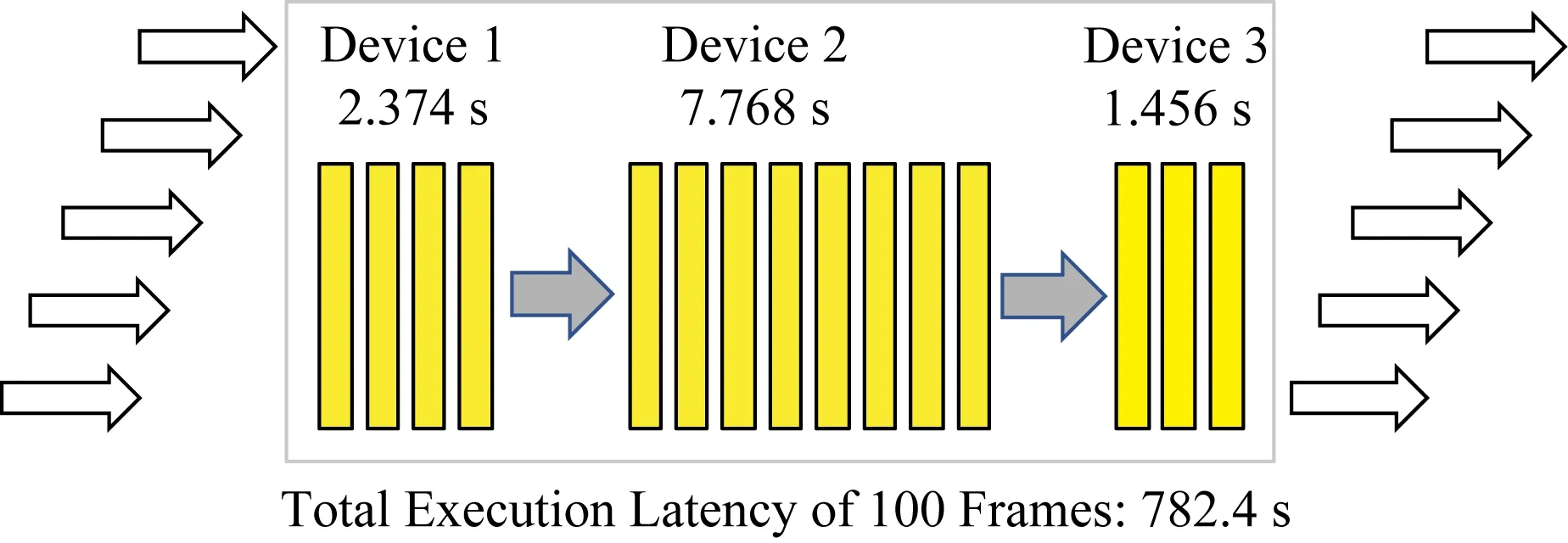
Fig. 5 An example of pipelined processing for the DNN model图5 DNN模型流水线处理示意图
3.3 问题求解
首先证明IoT-CDI问题是NP难的,利用已知NP难问题——广义分配问题(general assignment problem, GAP)[17-18]进行证明.GAP假定有M个物品和N个箱子,将物品i投入到箱子j中,获得收益为Mi,j.目标是把每一件物品装进一个适当的箱子里,在每个箱子成本限制约束下,使得总体收益最大化.通过参数映射和转换,IoT-CDI问题归约为GAP问题,从而证明该问题为NP难问题.
由于IoT-CDI问题为NP难问题,难以在多项式时间内获得最优DNN拆分和协作推断策略,因此,精准算法例如枚举法并不适用于求解该问题.此外,由于DNN模型结构多样性、设备能力异构且通信状态动态变化,需要实时调整协作推断策略.为此,我们采用基于数据驱动的人工智能方法进行求解,能够基于环境信息进行实时自动化决策.增强学习(reinforcement learning, RL)是一种有效的数据驱动方法,通过与环境交互获得奖赏的方式不断学习和指导行为以获得最大收益.本文利用增强学习算法确定最优DNN拆分策略,在异构设备间进行协作推断,实现推断加速.
4 DNN任务拆分策略
在本节中,首先通过具体参数配置和多种典型的预测模型详细阐述和分析所提出的精准多层延迟预测模型.在此基础上,利用进化增强学习算法智能自适应确定异构设备间的协作推断策略.
4.1 卷积层和全连接层的参数配置
卷积层包含输入特征维度(输入高度in_height,输入宽度in_width)、卷积核大小(核高度kernel_height,核宽度kernel_width)、通道规模(输入通道in_channel,输出通道out_channel)、步长stride和padding.全连接层参数配置包括输入特征维度in_dim和输出特征维度out_dim.参数配置范围如表1所示.通过随机组合生成各层的可配置参数,并测量每种参数组合的执行延迟Y.类似于文献[7],根据上述模型参数确定可解释参数向量X,包括浮点数操作(FLOPs)、内存占用规模和参数规模.可解释参数向量X的具体定义为:X=(FLOPs,mem,param_size),其中mem=mem_in+mem_out+mem_inter,mem_in表示输入数据的内存占用规模,mem_out表示输出数据的内存占用规模,mem_inter表示临时数据的内存占用规模,内存和参数特性的详细定义可以参考文献[7].CPU操作和内存操作在一定程度上影响程序的执行时间,DNN模型中CPU操作和内存操作体现在浮点数操作、内存占用规模和参数规模上.通过各种参数配置组合获得大量[X,Y]数据对用于延迟模型训练和预测.

Table 1 The Scope of Parameter Configuration for conv and fc Layers
4.2 多层延迟预测模型
本节我们对卷积层和全连接层的多层延迟预测模型进行全面研究.多层延迟预测模型的可解释参数向量X包括层数、浮点数操作量总和、内存占用规模总和和参数规模总和.为进行多层预测分析,首先生成任意层数的DNN模型,生成特征参数的随机组合,在具有不同计算能力的IoT设备上执行获得任意层数不同参数配置情况下的执行时延Y.获得[X,Y]数据对后,建立设备能力、任务特性和执行延迟的关联模型,研究多种常见的预测模型用于拟合多层输入数据和执行时延,挖掘多种特征参数与执行时延间的复杂映射关系.使用决定系数R2、平均绝对误差(mean squared error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)作为预测模型准确性的评价指标.分别研究线性回归(linear regression, LR)模型、RANSAC回归(RANdom SAmple Consensus regression, RANSAC)模型、核岭回归(kernel ridge regression, KRR)模型、k最近邻KNN(k-nearest neighbor)模型、决策树(decision tree, DT)模型、支持向量机(support vector machine, SVM)模型、随机森林(random forest, RF)模型、Ada Boost ADA模型、梯度提升回归树(gradient boosted regression trees, GBRT)模型和人工神经网络(artificial neural network, ANN)模型.
与卷积层相比,全连接层执行时间较短、参数较少且层数不多.例如,AlexNet模型仅包含3个全连接层,ResNet模型仅包含一个全连接层.我们通过实验证明全连接层整体执行延迟与单独执行延迟加和的误差低于2%.因此,我们仅研究全连接层在不同设备上执行的单层预测模型,进行不同预测模型对全连接层的预测性能比较,从表2可以看出多种预测模型均可以很好地预测全连接层的执行时延.

Table 2 Performance Comparison of Various Single-Layer Prediction Models for Fully-Connected Layer on Raspberry Pi 3B
对于卷积层,由于输入特征参数类型较多、配置范围较广、执行层数较多且特征参数间耦合关系复杂,因此延迟预测相对比较复杂.增加ANN预测模型,由于神经网络可以有效获取非线性关系和具有强泛化拟合能力,而且能够在不需要假设特征变量与结果之间的映射关系的情况下可以获得近似实际模型.以树莓派3B为例,表3针对卷积层进行不同多层延迟预测模型的性能比较.从表3中可以看出,RF,GBRT和ANN这3种预测模型的性能优于其他模型.例如与RANSAC模型和ADA模型相比,ANN模型MAPE指标分别降低43%和81%.第6节实验将进一步验证这3种多层预测模型的准确性.
Table 3 Performance Comparison of Various Multi-Layer Prediction Models for Convolutional Layer on Raspberry Pi 3B

表3 针对卷积层的多层预测模型在树莓派3B上的性能比较
4.3 基于进化增强学习的DNN任务拆分策略
1) 增强学习相关知识
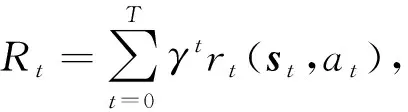
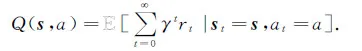
深度增强学习(deep reinforcement learning, DRL)[19]被提出用于解决维度诅咒问题.DRL利用深度神经网络近似表示Q函数Q(st,at)≈Q(st,at|θ),其中θ表示神经网络的模型参数.DQN(deep Q-network)是一种典型的DRL方法[20].DQN将经验元组存储在经验池中,每次从经验池中随机选取一批次样本进行训练,然后更新参数θ以最小化损失函数.
然而,基于反向传播的DQN方法无法进行长期优化,难以在奖励稀疏(采取一系列行为后才能获得收益)的情况下学习到最优行为.此外,面对高维动作和状态空间,高效探索仍然是一个亟待解决的关键挑战,这种情况下存在收敛困难的挑战.总结而言,DQN这种传统DRL算法面临着稀疏奖励、缺乏有效探索以及收敛困难等重要挑战.因此不能直接应用传统的DRL算法(例如DQN)解决IoT-CDI 问题,因为该问题行为分解为连续子行为,存在稀疏奖励以及行为状态空间巨大等问题,收敛十分困难.为此,提出进化ERL算法[21]用于在异构设备间实现DNN拆分和协作推断.
2) 基于进化增强学习的DNN任务拆分策略
从DRL角度,用于确定DNN拆分策略的设备被建模为智能体Agent.为了减少状态和行为空间维度,将DNN拆分任务分解为层级序列子任务,每一层当作一个子任务,在每次决策时只需要为每一层模型选择合适的执行设备,通过依次添加各层行为获得整体行为集合,根据行为集合进行DNN任务拆分和协作推断,DNN任务执行时延作为收益,用于衡量行为集合的性能表现.首先定义该问题的状态、行为和回报等基本元素.
① 状态.在每个时刻t,状态st包含5个部分:
ⅰft表示当前层数;
ⅱcomt表示当前网络状态,即通信速率;
ⅲct={c1,t,c2,t,…,cN,t}表示每个IoT设备的能力;
ⅳlt={l1,t,l2,t,…,lN,t}表示每个IoT设备完成预先分配的子任务所需的累积延迟;
ⅴet={e1,t,e2,t,…,eN,t}表示当前子任务分配到每个IoT设备执行所产生的推断延迟,从以上描述可知st=(ft,comt,ct,lt,et),状态维度为3N+2.
② 行为.at表示从N个IoT设备中选择一个设备用于执行当前子任务.
③ 收益.如果当前子任务是最后一个,则收益为DNN任务的整体推断时延(针对数据流情况,收益为每个IoT设备执行各自任务所需时延的最大值),否则收益为零.
基于反向传播的DRL算法难以获得该问题的最优策略,因为该问题面临稀疏奖励和困难探索等挑战.与传统深度增强学习DRL方法相比,ERL融合自然进化策略中基于种群的方法,使得多样化探索成为可能,并且利用适应度指标学习和生成更优后代,从而可以有效地探索多种策略,并且不断朝着高收益方向进化[22-23].
ERL过程如下:将进化应用于候选样本种群中,通过增加随机偏差不断产生新后代.执行选择操作,适应度值较高的后代有更多机会保留和产生新的后代.适应度值越高则意味着性能越优,通过选择操作后生成的下一代会提供更优性能.在本文中,每个样本则代表一组神经网络的参数,添加在子代上的随机偏差表示对神经网络权重进行随机扰动.
整体算法流程如算法1所示.

在算法1中,开始时对参数进行初始化.然后描述如何在训练时更新神经网络,具体来说,父代神经网络通过扰动神经网络的参数生成C个子代神经网络,并且在每次迭代过程中评估每个子代获得的收益值即适应度值.如果一个子代具有更高的适应度值,那么以更高概率选择这个子代并且生成后代.通过每个子代获得收益值与所有子代平均收益值的差值归一化计算每个子代增益值g.依据C个子代增益值g更新父代神经网络参数(行③~⑨).
5 IoT-CDI框架
IoT-CDI框架整体流程示意图如图6所示,包含离线训练和在线执行2个阶段,离线阶段生成多层延迟预测模型和完成ERL算法的训练过程,在线阶段基于系统状态动态确定拆分位置和任务分配,多个设备协作共同执行DNN任务.不同DNN任务的拓扑结构不同,每层的计算量和生成的中间数据传输量均有差异,网络状态变化直接影响数据传输时延,设备能力异构显著影响计算时延,因此需要根据这些动态因素,自动化调整DNN任务拆分和分配策略以有效降低推断时延.IoT-CDI框架能够根据当前系统状态,包括通信状态、设备能力以及DNN任务需求,确定DNN模型的拆分位置以及每个设备的任务分配,在异构设备间实现分布式、协作DNN任务推断.利用一个主设备(IoT设备或者网关)管理和控制整个流程.
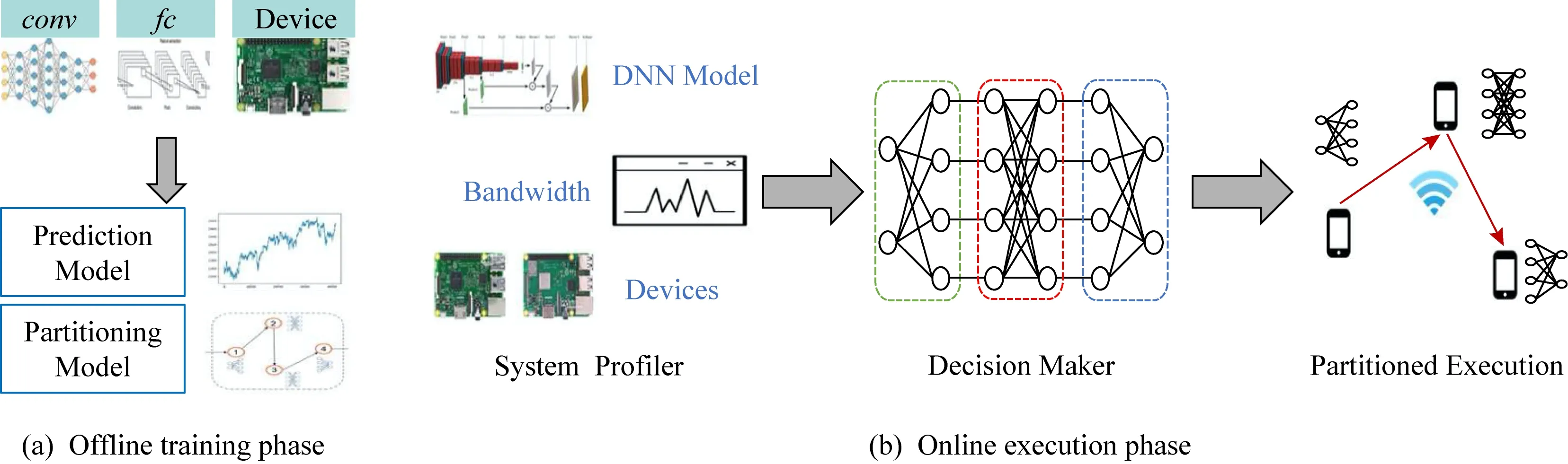
Fig. 6 The overview of IoT-CDI framework图6 IoT-CDI框架整体流程示意图
5.1 离线训练阶段
该阶段主要进行多层延迟预测模型训练和ERL拆分策略训练.针对卷积层和全连接层2种层类型,刻画任意多层不同参数配置情况下的延迟预测模型,允许在不执行DNN任务的情况下准确评估推断任务的实际执行时延.由于不同层类型、层参数配置以及层数会产生明显时延差异,因此构建不同层类型的预测模型(卷积层和全连接层2种),改变每种层类型的层数和每层参数配置,利用这些参数确定计算规模和数据传输规模,并且分析参数配置相同时不同设备能力对执行延迟的影响.通过实验获得参数配置、设备能力和执行延迟的真实测量数据,基于数据进行预测模型训练.分析多种常见的预测模型,涉及回归、k最近邻、决策树、组合和人工神经网络模型等多种类型模型.通过实验发现全连接层参数种类较少,预测相对简单,很多模型均可获得准确预测性能;而卷积层参数类型较多且配置复杂,因此具有强泛化和非线性拟合能力的预测模型性能比较准确.值得注意的是,通过将模型参数映射为计算规模和传输规模,并分析不同设备能力对执行延迟的影响,提出的预测模型是DNN模型无关的且设备能力相关的,既能够适应于异构设备,而且当DNN模型结构和参数改变时也能依据预测模型快速获得精准的执行时延,避免带来额外执行开销.
基于生成的多层延迟预测模型,训练ERL算法以便在DNN模型、网络状态以及设备能力动态变化的情况下获得近似最优DNN任务拆分和协作推断策略.ERL模型状态信息包括模型参数、层数、通信状态以及设备能力,行为策略是为确定DNN模型每一层的执行设备,收益为执行DNN模型所产生的推断时延(包括计算时延和通信时延).训练20 000次达到收敛,将训练完成后的ERL模型存储在主设备上,后续基于输入的系统状态确定最佳拆分策略.
5.2 在线执行阶段
该阶段包括3个步骤:1)系统分析器system profiler获取当前系统状态,包括DNN推断任务、当前通信状态以及设备能力等;2)将这些信息反馈给决策器decision maker,决策器利用离线训练完成的多层延迟预测模型评估每种候选决策的推断延迟,并且利用同样在离线阶段训练完成的ERL拆分模型获得最优拆分策略,在异构多设备间实现DNN推断加速和设备资源的充分利用;3)每个设备依据拆分策略各自执行分配任务.
IoT设备需要通过相互通信传输命令和数据,为了有效识别设备,每个IoT设备需要注册一个IP地址.在知道DNN任务拆分和分配策略后,维护每个设备自身的IP处理表,该处理表记录自身分配到的推断任务以及自身任务的前驱和后继节点.主设备维护整体IP处理表,该表记录每个设备的执行任务.一旦系统状态发生变化,例如通信速率变化或者新设备加入或退出,将会触发拆分策略调整,主节点将更新记录.然后主节点向所有设备分发IP处理表的更新信息,每个设备依据更新信息修改自己的IP处理表.
DNN推断过程依据IP处理表执行.一个IoT设备将从前驱设备接收计算所需的输入数据,在完成分配任务后将生成的输出结果发送给后继设备.为实现上述过程,我们采用远程调用框架(remote procedure call, RPC)来实现设备间交互,能够在2个设备间进行通信和数据传输.以VGG模型为例,假定设备1执行VGG模型的1~5层,其后继设备为设备2,设备2执行VGG模型的6~10层,设备1完成分配的层数后将生成的输出结果发送给后继设备2,2个设备按照策略共同执行DNN任务.当环境状态发生变化后,依据ERL算法调整拆分和分配策略,例如设备1执行1~7层,设备3执行8~10层,需要更新每个设备的IP处理表,修改分配任务以及前驱后继节点.
6 实验验证
我们利用真实实验验证提出的IoT-CDI框架.首先证明提出的多层延迟预测模型是精准的;然后,与基准算法相比,发现ERL方法能够显著降低推断延迟,实现推断加速.此外,我们还评估通信状态和设备数量等因素对实验性能的影响.
6.1 实验设置
1) 设备类型.使用3种型号的树莓派设备作为异构IoT设备,分别是树莓派2B、树莓派3B和树莓派3B+,使用Raspbian GNU/Linux10 buster操作系统.不同型号的树莓派具有不同计算能力,提供差异化的推断性能.不同型号树莓派的具体规格见表4所示.为了在树莓派上执行DNN任务,我们安装Python3.7.3,Keras 2.2.4和Tensorflow 1.13.1等基础软件和平台.
2) DNN模型.使用5个常见的DNN模型,分别是AlextNet,DarkNet,NiN,ResNet18和VGG16.VGG16代表长DNN模型(层数较多),AlexNet代表短DNN模型(层数较少).AlexNet模型和ResNet18模型计算量较小,VGG16模型和NiN模型计算量较大,但VGG16模型通信量较小,NiN模型通信量较大.
3) 通信方式.利用IoT设备间的平均传输速率来模拟不同的无线网络.实验设置3种网络环境,3G网络,WiFi和4G网络,传输速率分别为1.1 Mbps,18.88 Mbps和5.85 Mbps.

Table 4 Raspberry Pi Specification表4 树莓派规格
4) 基准算法.考虑4种对比算法.设备执行(device-execution, DE)算法是指仅在生成任务的本地设备上执行DNN任务.最强执行(maximum-execution, ME)算法是指将DNN任务分配给计算能力最强的设备.均衡执行(equal-execution, EE)算法是指将DNN任务平均分配给所有可用设备.经典最短路径Dijkstra算法得到DNN模型从第一层到最后一层的最短执行时延,利用单层预测模型确定每条边权值,记做SE(short-execution).使用DE算法作为基准.本文提出的算法记作ERL.
5) 性能指标.使用推断延迟加速(inference latency speedup)来评估不同算法的性能.延迟加速表示为与DE算法相比推断延迟降低的倍数.每个实验重复200次并计算200组结果的平均值使结果更加准确.
6.2 预测模型准确性
延迟预测数据集:针对卷积层和全连接层2种层类型,分别设置不同参数范围,层参数和参数范围如表1所示,通过随机组合生成各种可配置参数集合,将配置参数转换为浮点数操作、内存占用规模和参数规模等相关可解释变量,获取3种型号的树莓派设备在不同参数设置情况下的执行时延,得到卷积层和全连接层的参数设置和执行时延的真实测量数据集.针对多层延迟预测,按照实际DNN模型规律生成多层参数配置,层数范围是1~40,将每层参数配置转换为可解释变量,逐层加和获得累积的可解释变量,并通过树莓派执行得到多层推断时延.基于真实测量得到的多层参数配置和推断时延的数据集,训练多种常见的预测模型,分别对卷积层和全连接层进行预测,不同预测模型的预测性能如表2和表3所示.
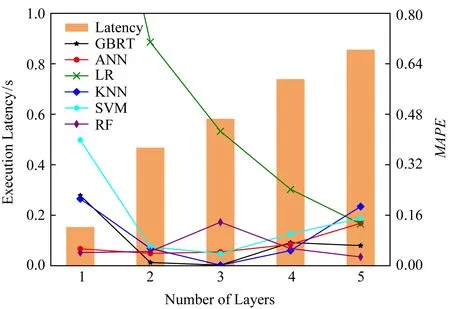
Fig. 8 Each layer’s latency and prediction accuracy of AlexNet图8 AlexNet模型每一层的延迟及预测准确率
下面验证卷积层多层延迟预测模型的准确性.以VGG16和AlexNet为例,分别如图7和图8所示.其中柱状图表示实验测量的真实执行时延,例如当横坐标为7时表示执行VGG16模型前7层所需时延为6.08 s;折线图表示不同预测模型的预测性能,以平均绝对百分比误差MAPE为评价指标.从图7,8中可以看出,RF,GBRT和ANN这3种预测模型能够准确预测任意层数的推断延迟,3种模型任意层预测结果的平均百分比误差低于4%.能够精准预测的主要原因首先在于精准刻画能够影响推断延迟的模型参数,并将这些参数映射为计算规模和通信规模这种可解释变量.上述3种预测模型具有良好的层次拟合和泛化能力,能够有效获取特征变量和延迟之间复杂非线性关系.此外,进一步考虑设备能力对推断延迟产生的影响,获取每种类型设备参数配置和执行时延的真实数据集,并对每种设备进行预测模型训练,从而能够准确预测各种设备在不同参数设置情况下的推断时延.
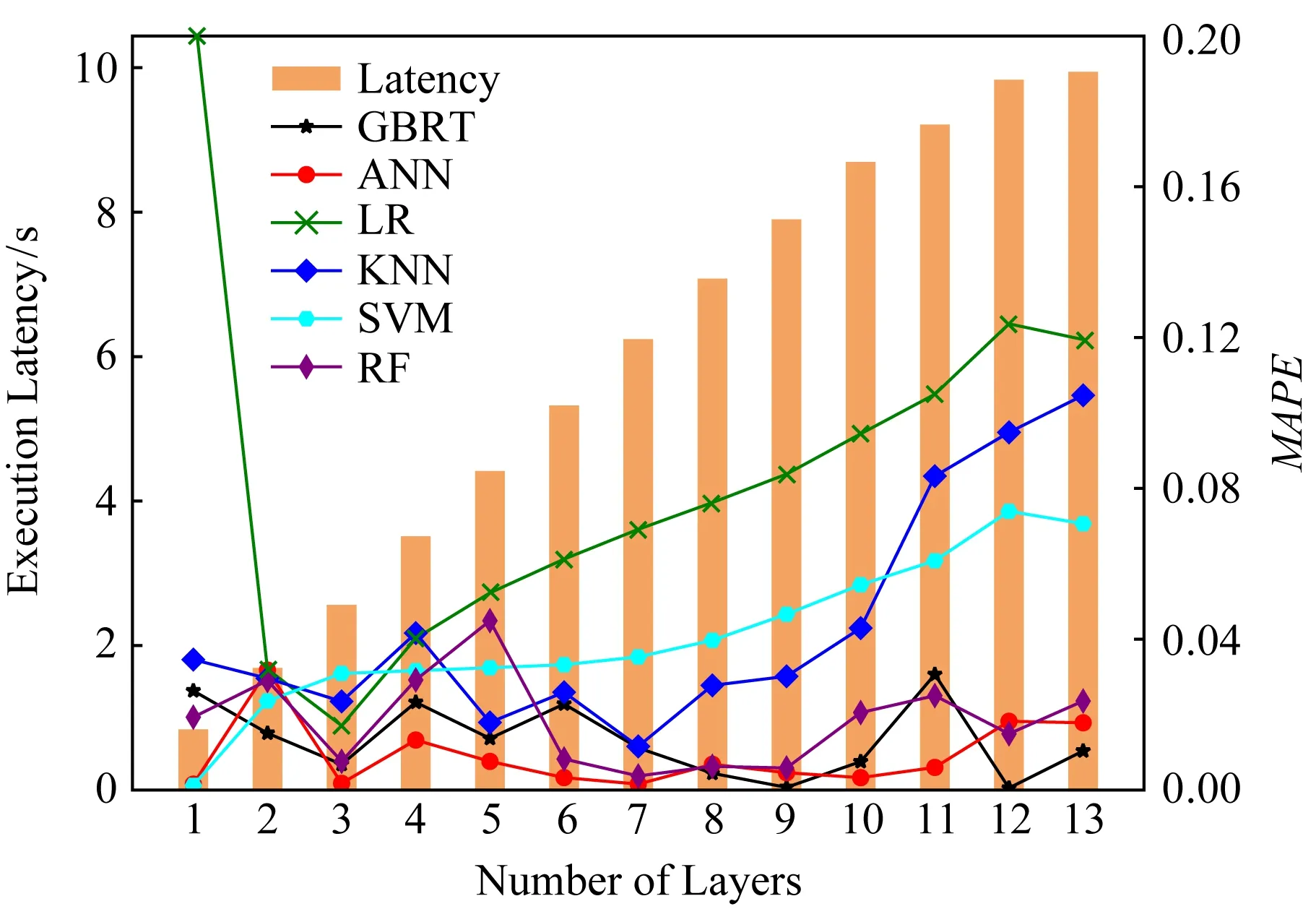
Fig. 7 Each layer’s latency and prediction accuracy of VGG16图7 VGG16模型每一层的延迟及预测准确率
6.3 性能比较
1) DNN拆分.图9给出3种典型DNN模型的不同拆分策略.从图9中可以看出,DNN拆分策略随着DNN模型和设备数量的变化而不同.VGG16模型计算量大,数据传输量小,因此它倾向于利用更多的IoT设备来获得更优性能.NiN模型计算量大,数据传输量也很大,过多的通信开销会导致性能下降.因此,NiN模型倾向于采取较少设备协作以降低通信开销.ResNet18模型计算量小,需要考虑协作推断降低的计算开销能否抵消增加的通信开销,因此ResNet18模型的拆分策略需要权衡计算增益和通信开销.由此可以得出结论,需要根据DNN模型特性和环境状态自适应调整DNN拆分策略.
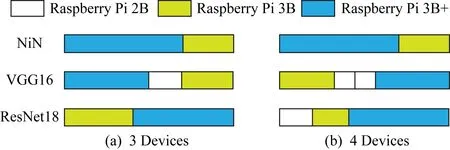
Fig. 9 Illustration of partitioning strategy for three DNN models图9 3种DNN模型的拆分策略
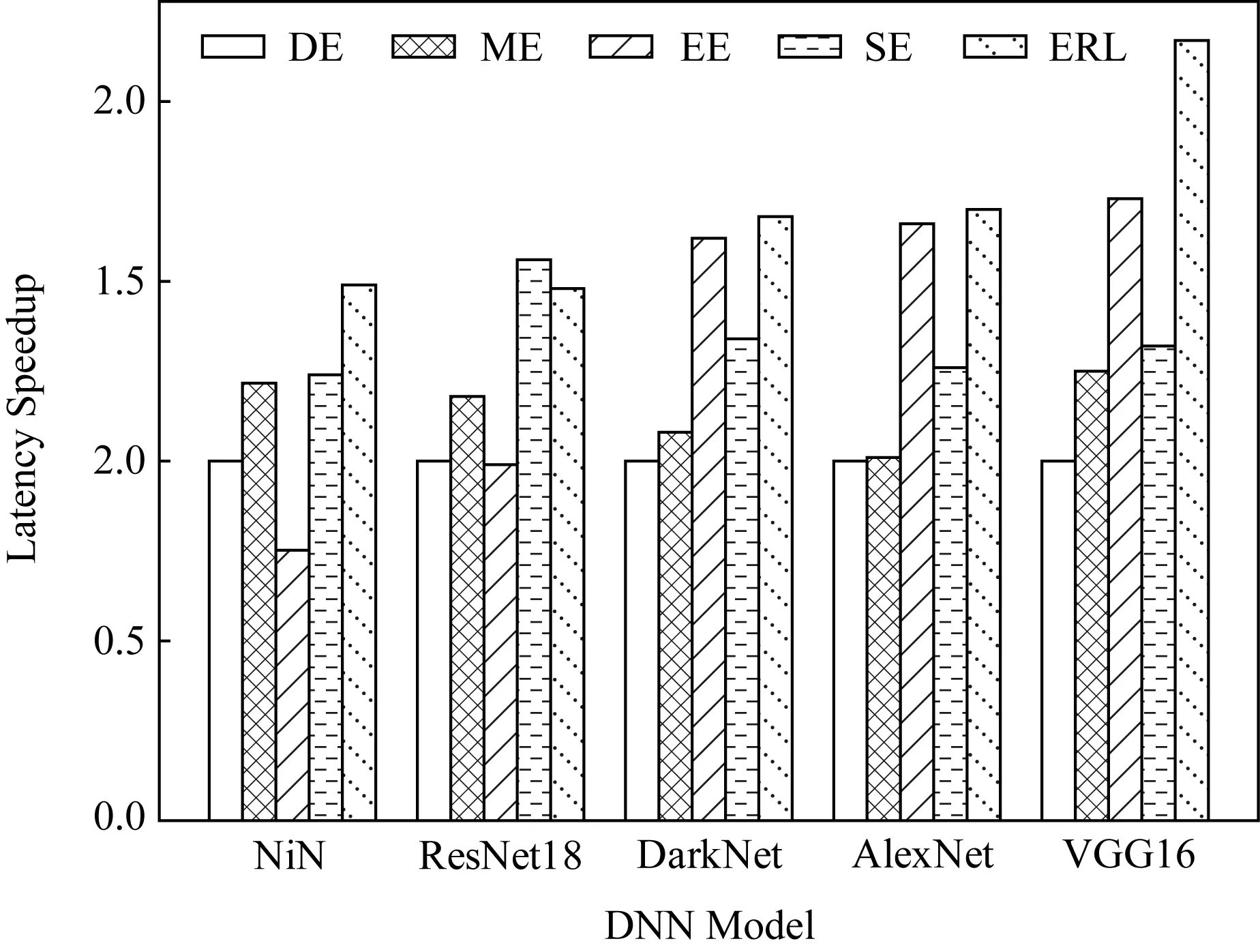
Fig. 10 Measured latency speedup of five algorithms for five DNN models图10 5种算法针对5种DNN模型的延迟加速情况
2) 延迟加速.比较5种算法针对不同DNN模型的延迟加速情况,设备数量设定为3,通信方式为WiFi.从图10中可以看出,与DE,ME,EE和SE算法相比,我们提出的ERL算法有不同程度的提升.随着计算需求增加,性能提升越明显,例如VGG16模型使用ERL算法延迟加速大约是DE算法的2倍.主要是因为IoT设备资源受限,计算量较大时单独执行性能较差,DNN任务拆分的需求越强烈.然而,当数据传输量较大时,DNN任务拆分产生较高的通信时延会严重降低协作执行的优势,因此延迟加速在NiN模型中并不明显.
由于单个IoT设备无法承受沉重的计算负担,因此DE和ME算法性能都不理想.虽然EE算法可以通过协作推断获益,但是平均决策并不是最优拆分策略.由于单层预测不准确的原因,SE算法性能并不理想.本文提出的ERL算法能够有效权衡计算和通信开销,充分利用了备的异构能力,可以实现更优的DNN推断加速.
6.4 环境状态适应性
1) 通信状态影响.本实验评估通信状态对延迟加速的影响.分别在3G,4G和WiFi这3种通信条件下以VGG16模型为例对5种算法进行性能比较,如图11所示.值得注意的是,当通信速率提高时,ERL算法与基准算法相比性能提升更明显.当使用3 G网络时,通信条件较差,协作执行产生的计算增益难以抵消数据传输产生的通信花销.因此,NiN模型EE算法性能低于DE算法.当使用4G网络时,ERL算法延迟加速是DE算法的2.07倍.当使用WiFi进行通信时,延迟加速提升到2.36倍.主要原因在于当通信条件较好时,DNN拆分所需的数据传输延迟降低,因此协作执行优势更明显.
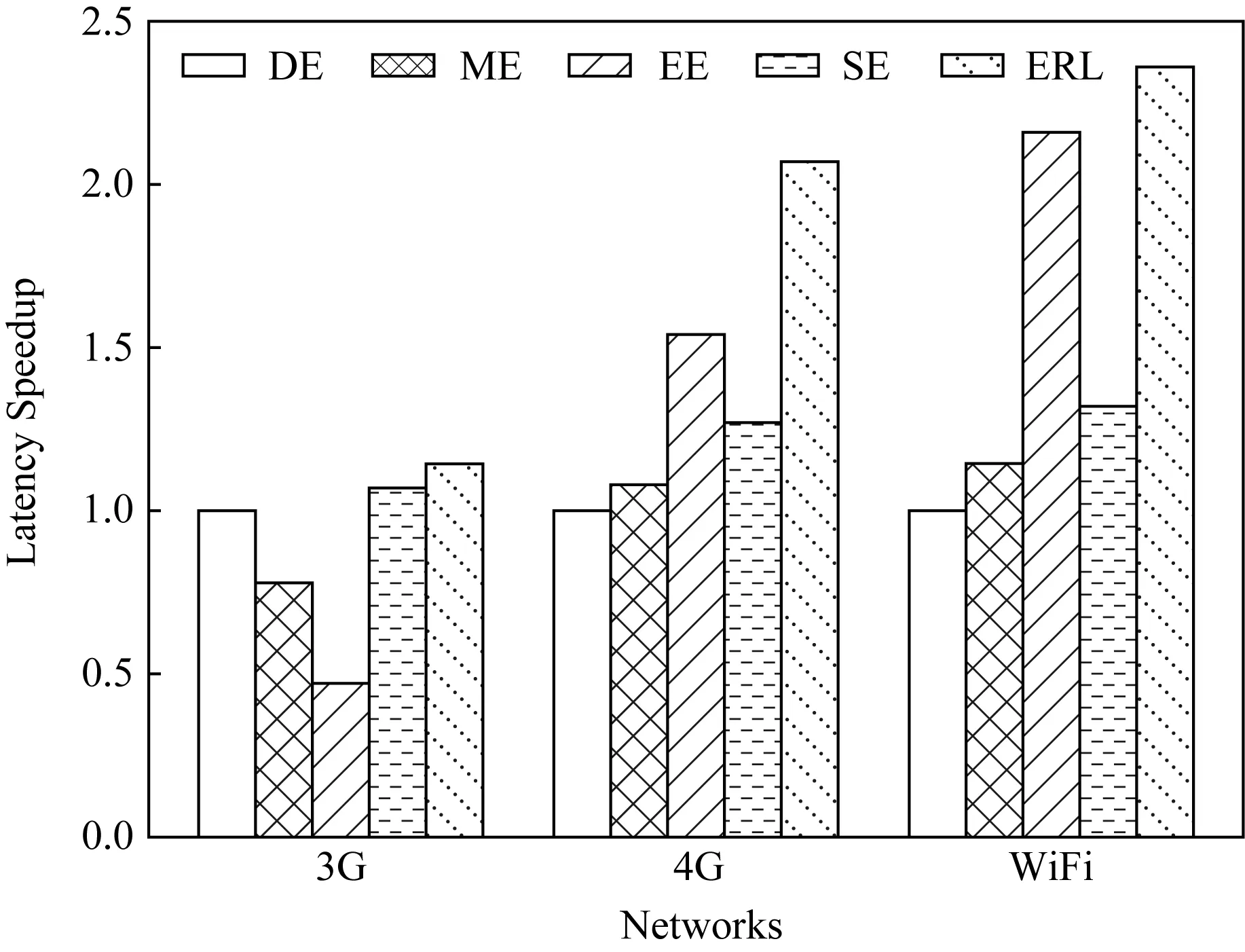
Fig. 11 Latency speedup under different networks for five algorithms图11 不同网络条件下5种算法的延迟加速情况
为了进一步验证所提出的ERL算法能够适应于各种通信状态,设置通信速率从1 Mbps到20 Mbps,以VGG16模型为例比较5种算法的延迟加速性能.通过实验发现,ERL算法性能在任意通信速率时均为最优,推断延迟降低2倍以上.从图12可以看出,随着通信速率提升,延迟加速越来越明显,这是由于通信速率提升能够有效降低拆分所带来的通信花销,从而降低整体执行时延.DE,ME和EE算法无法根据网络状态调整拆分策略,因此随着通信速率增加,延迟加速性能提升不明显.而ERL算法和SE算法能够根据当前网络状态有效权衡通信和计算开销,从而能够随着通信速率增加实现显著推断加速,有效降低DNN任务的推断时延.
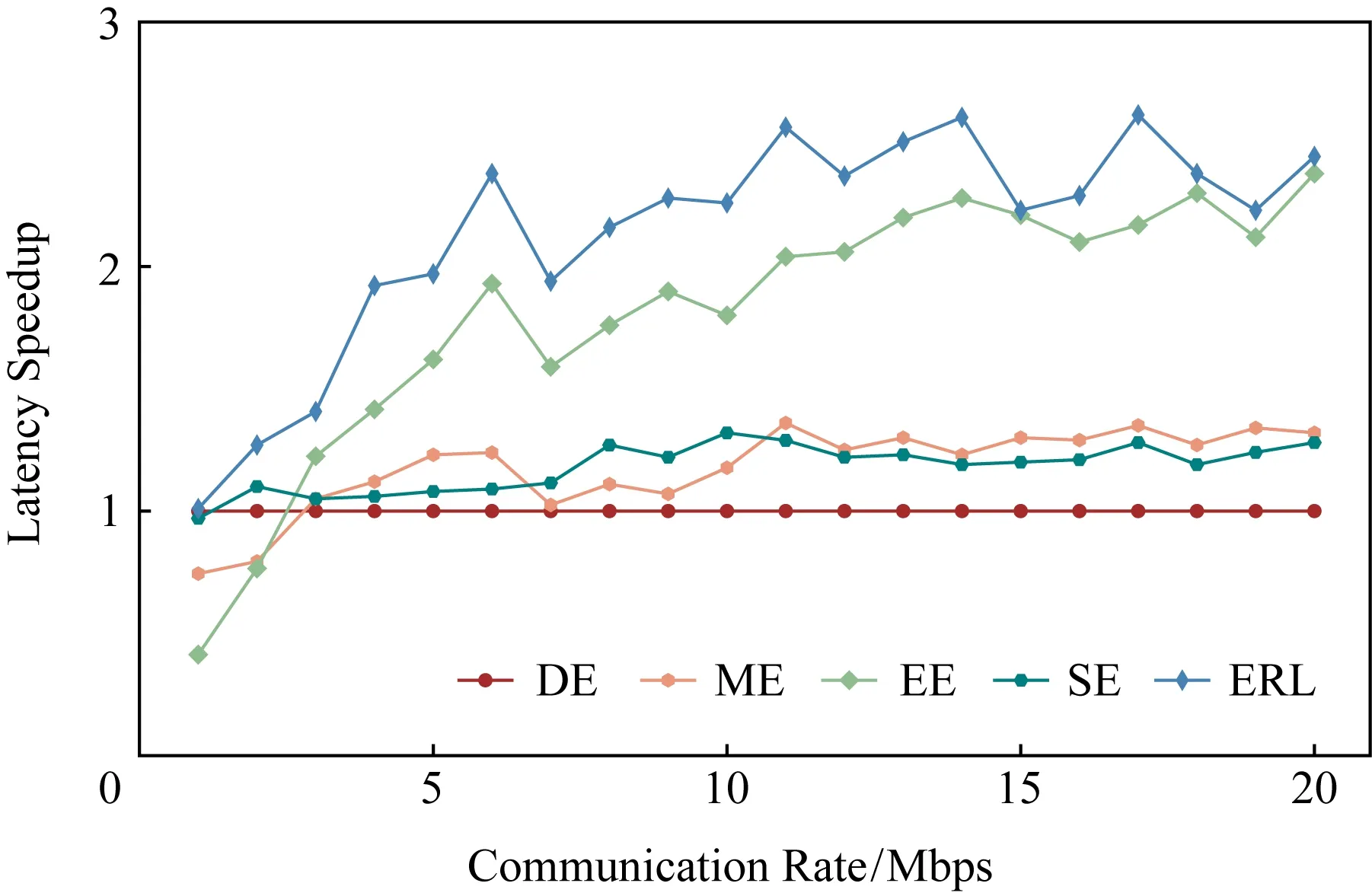
Fig. 12 Latency speedup under different communication rate for five algorithms图12 不同通信速率时5种算法的延迟加速情况
2) 设备数量影响.使用不同数量的IoT设备评估5种算法的性能.以NiN模型为例,从图13可以看出,本文提出的ERL算法在推断延迟加速方面性能最优.当设备数量分别为2,3,4时,ERL算法延迟加速分别是EE算法的1.81倍、1.98倍和5.28倍.由于NiN模型通信花销不可忽视,EE算法并不能灵活调整拆分策略,难以有效权衡计算和通信花销.而本文提出的ERL算法能够智能确定拆分策略以获得近似最优性能.
7 讨 论
1) 设备异构性.实验使用不同型号树莓派设备来体现设备异构性,3种型号树莓派的性能差异如表4所示,分别在3种型号树莓派上运行AlexNet以及DarkNet等5种DNN模型,实验测量数据如图2所示.通过实验可以看出3种设备存在明显性能差异,能够体现设备异构性.后续将考虑树莓派、手机以及穿戴设备等多种不同种类设备,分析不同类型设备的性能差异,对设备能力进行细粒度建模,在此基础上研究多种类型设备间的协作推断问题.
2) 设备数量.单个IoT设备能力不足,多个设备协作执行可以有效降低推断时延,然而增加协作设备数量在降低计算时延的同时会增加通信时延开销.为防止通信瓶颈,协作执行DNN模型的设备数量不会太多,通过图9可以发现,对于数据传输量较大的DNN模型(例如NiN模型)即使可用设备较多时也倾向于使用少数设备.即使数据传输量较少且计算量较大的DNN模型(例如VGG16模型),协作执行设备数量也不会太多.未来将进一步研究不同DNN模型所需协作设备的最优值,在设备数量充足的情况下能够根据DNN任务需求自适应调整协作设备数量以实现最优推断加速.
3) IoT-CDI框架的实用性.IoT-CDI框架主要解决2个问题:①针对现有单层预测方法误差不可忽视的问题,设计细粒度多层预测方法,能够精准评估任意层DNN任务的推断时延.②针对设备能力、DNN任务特性以及网络状态动态变化且异构的情况,采用基于增强学习的智能化决策算法,为克服稀疏回报以及收敛困难等问题,使用进化增强学习快速获得拆分策略.IoT-CDI框架使用基于数据驱动的方式实现精准预测分析和实时智能决策,然而相比于传统方法,存在系统开销较明显(需要存储模型)、扩展性以及在线调整等问题,未来工作将着眼于该框架的实用性,解决实际部署存在的问题以提高可行性.
8 结 束
本文提出一种新颖的IoT设备协作执行DNN任务的IoT-CDI框架,根据DNN任务需求、设备能力以及网络状态等多种因素,在异构IoT设备间实现实时自适应的DNN任务协作推断.具体地,提出不同层类型、参数配置以及设备能力情况下的多层延迟预测模型,能够准确预测不同拆分情况下DNN任务的推断时延.此外,提出基于进化增强学习的智能DNN任务拆分和协作推断算法,能够在设备能力、网络状态以及任务需求异构且动态变化的情况下获得近似最优策略.实验结果表明:该算法能够有效权衡通信延迟和计算延迟,充分利用设备计算能力,显著降低DNN推断时延.
