公交数据驱动的城市车联网转发机制
2020-04-21唐晓岚陈文龙
唐晓岚 顼 尧 陈文龙
(首都师范大学信息工程学院 北京 100048)
在城市车联网(vehicular ad hoc networks, VANETs)[1-3]中,装载有智能感知设备的车辆能够获取车辆速度、加速度、与周边车辆的距离、超车预警等信息.在行驶过程中通过车辆与车辆(vehicle to vehicle, V2V)通信[4-5]以及车辆与路边基础设施(vehicle to infrastructure, V2I)通信[6],将感知到的信息传输给周围的其他车辆或者路边单元,实现车辆之间的互联互通,进而支持各种智慧交通应用,例如事故预警、路况广播、广告推送和资源分享等,提高驾驶的安全性、舒适性和便捷性[7].国际上V2V和V2I通信标准主要有美国提出的专用短程通信标准(dedicated short range communications, DSRC)[8],近年来我国正在加速发展LTE-V2X(vehicle to everything)技术[9].
车联网的应用大致分为安全类应用和非安全类应用,不同种类的应用对服务质量的要求不同[10].安全类应用与交通安全密切相关,包括事故预警、车辆辅助控制等,这类应用对数据的实时性要求较高,对时延较为敏感.非安全类应用主要用于交通疏导和信息共享服务,包括路况信息扩散、多媒体资源分享等,这类应用对数据实时性要求相对较小,能够接受一定的时延.本文关注于非安全类应用,通过公交车的存储转发,实现城市车联网的数据传输.
城市交通状况的复杂多变和私家车驾驶行为难以预测等特点导致车车通信的间歇性连接,网络拓扑结构高度动态,通信链路不稳定,进而影响了车联网的数据传输性能[11].一些研究人员通过部署路边基础设施,提供较车载设备更为强大的通信能力和数据处理能力,从而改善数据转发[12-14];还有一些学者利用路边停放的车辆来协助数据转发[15-16].但是,在城市内大规模部署路边基础设施成本高昂,实施难度大,从市政规划到投入使用的预期时间长;而路边停放的车辆数量有限,且车辆状态在停止和行驶之间的频繁切换会影响这些方案的性能.相较而言,公交车作为重要的城市公共交通设施,其路线涵盖了城市中大部分主要道路,并且公交线路固定、发车时间规律,有助于按照预期路径传输车联网数据[17].因此,如何利用已有公交线路有效地转发数据是城市车联网数据传输的重要研究课题.
本文提出公交数据驱动的城市车联网转发机制,称为BUF(bus-data driven forwarding scheme).首先构建公交站点拓扑图,以目标场景中所有公交站点为顶点,依据是否有公交线路连续经过2个站点决定顶点之间是否连边,综合相邻站点之间的预期公交车数量和距离计算边的权值.然后使用迪杰斯特拉算法计算从源站点到目标站点之间权值最小的路径.当数据沿该路径传输时,依据邻居公交与最优路径的后续站点重合度,优先选择重合度高的公交做为骨干公交,实现数据转发.当不存在骨干公交时,选择后续将经过最优路径上的下一站点的公交做为候补公交,完成数据转发.若骨干公交和候补公交都不存在,则通过私家车建立多跳链路找到合适的公交转发节点.
本文的主要贡献有3个方面:
1) 构建公交站点拓扑图,边权值的计算综合考虑相邻站点之间的预期公交车数量和距离,公交车越多、距离越短,则数据传输成功率越高、时延越短,即边权值越小,传输性能越好,进而通过迪杰斯特拉算法计算从源站点到目的站点的最优传输路径;
2) 设计数据转发策略,依据后续站点重合度,优先选择骨干公交转发数据,其次选择未来经过下一站点的候补公交,再次使用私家车建立多跳链路寻找合适的公交节点,该策略保证了快速且稳定地沿最优路径转发数据;
3) 实验使用北京市真实路网和公交数据来建立城市车联网场景,结果表明BUF与其他方案相比具有更高的传输成功率和更短的时延.
1 相关工作
现有的车联网研究主要利用车载节点的协作来提升数据传输性能.Wang等人[18]提出基于车辆之间关联性的数据转发策略,依据车辆之间关联性计算数据转发概率,确定最优数据传输路径.Tang等人[19]利用模糊逻辑,综合车辆的速度变化率、速度优先度和信道质量等因素计算传输优先级,进而在每个路段内选择骨干节点来传输数据.针对车载多播传输,Hsieh等人[20]构建以源车辆为根的多播路由树,依据该路由树实现源节点向目的节点的多播传输;Souza等人[21]在MAODV协议的基础上,利用车辆的移动信息来构建更加稳定的多播树结构,并利用蚁群算法来优化多播树.文献[22]根据当前车流情况和可预测的车辆移动规律,估算不同道路的车辆密度,选择具有最短传输延迟的道路,沿该道路转发数据.文献[23]依据路径连通寿命、平均邻居数和路径跳数来计算路径权值,选择权值大的可靠路径传输.然而,私家车的行驶路线难以预测,车辆的高速移动和间歇连通导致路径选择更新频繁,维护困难.
部分研究利用固定的路边基础设施来优化车联网的数据转发.文献[24]令源车辆将数据发送给附近的路边单元,再利用路边单元之间的有线网络将消息转发到目的车辆附近的路边单元,并最终传递给目的车辆.该方法的消息传输延迟主要取决于车辆在行驶过程中遇到公共的路边单元的频率,因此需要密集部署路边基础设施.Tang等人[25]将数据在路边单元中的分布式存储问题转化为二部图的稳定匹配问题,实现较高的数据响应率和较短的传输时延.然而,路边基础设施的部署成本较高,实施难度较大,影响着相关方案的推广和落地.
在公交辅助数据传输的VANET体系结构中,公交车不仅是通信节点,而且是决定数据转发策略的路由节点.一些研究通过分析公交路线信息或挖掘公交历史轨迹,建立公交线路之间的关系,据此选择一系列公交节点将数据从源节点传输到目的节点.在文献[26]中,Zhang等人提出了以公交系统为主干的路由协议,通过收集和分析公交车实际轨迹,挖掘公交系统的社区属性,将联系频繁的公交线路划分到一个社区,进而设计社区内部和社区之间的路由方案,完成数据传输.在文献[27]中Sun等人依据公交轨迹在街道出现的概率建立路径图,计算街道一致性概率和路径一致性概率2个指标,从而选择公交密度大且不易偏离方向的数据传输路径.在文献[28]中,Chang等人旨在实现具有隐私保护的公交网络高效路由,每个报文与一张路由图关联,而非一条具体的路径,从而使得路由动态适应城市交通状况,并对中继节点隐藏与用户和目的地相关的隐私信息.
综上所述,现有使用公交数据的城市车联网路由算法主要基于历史轨迹数据或依靠路边基础设施的支持,而公交站点和公交线路之间的关系没有被充分挖掘.因此本文旨在优化以公交站点为顶点的路径选择,并探索公交车的转发策略来提升车联网传输效率.
2 公交站点拓扑建立和路径选择
在数据转发机制BUF中,首先建立公交站点拓扑图,计算从源站点到目的站点的最优传输路径;然后沿该路径,依据数据转发策略,选择合适的公交车辆进行数据转发.本节将详细阐述公交站点拓扑图的建立以及最优路径的选择过程.本文所使用的主要符号及其意义如表1所示.
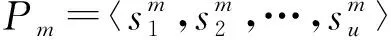

Table 1 The Main Symbols and Their Descriptions in This Paper
构建公交站点拓扑图G=(V,E),其中顶点表示公交站点,顶点之间的边表示存在公交线路连续经过这2个站点.换句话说,若存在至少一条公交线路的站点序列Pm满足〈si,sj〉⊆Pm,则在si和sj之间连边.由于绝大多数公交线路的去程和回程所经过的站点相同且站点顺序互为逆序,而本文所设计的公交站点拓扑图为无向图,因此针对每个公交线路,仅取其一个行驶方向的站点序列来构建公交站点拓扑图.

(1)
显然,预期公交数量越大,在2个站点之间通过公交车转发数据的成功率越高.此外,站点si和sj之间的道路距离记为Di,j,距离越大,意味着在这2个站点之间的数据传输时延可能越长.综合预期公交车数量和距离的影响,对于公交站点拓扑图中站点si和sj之间的边,其权值可计算为
(2)
其中,α是预期公交车数量的权值且0<α<1,max(F)和min(F)分别表示拓扑图中所有相邻站点间的预期公交车数量F的最大值和最小值,max(D)和min(D)分别表示所有相邻站点间距离D的最大值和最小值.函数max()和min()用于对Fi,j和Di,j归一化,由于Fi,j与Qi,j负相关而Di,j与Qi,j正相关,故其归一化方法不同.边权值Qi,j越小,则该路段的传输能力越强.
举例,图1(a)所示场景中有12个公交站点和7条公交线路,相应的公交站点拓扑图如图1(b)所示.拓扑图中顶点代表12个公交站点,依据图1(a)中公交线路所经过的站点信息连边.以公交线路b1为例,其依次经过站点s1,s6和s11,因此节点s1和s6以及s6和s11之间连边.既经过站点s1又经过站点s6的公交线路为C1∩C6={b1,b3,b5}∩{b1,b5,b6}={b1,b5},若b1和b5在单位时间内(例如10 min)发车频率均为2,则从站点s1到s6的道路上预期公交车数量为F1,6=4.进而将F1,6和D1,6归一化并加权得到边权值Q1,6.

Fig. 1 An instance of scenario and its bus stop topology图1 场景和公交站点拓扑图示例
当任意车载节点需要传输数据时,若数据的目的地在其通信半径以内,则直接将数据发送到目的地;否则,将数据发往最近的公交站点.以该站点为源站点,以距离目的地最近的公交站点为目的站点,在公交站点拓扑图中,使用迪杰斯特拉算法计算从源站点到目的站点的权值最小的路径R,以该路径为数据传输的最优路径.接下来依据数据转发策略,选择合适的公交车沿最优路径将数据传输到目的地.针对最优路径的计算,本文将传输路径规划问题转化为公交站点拓扑图中最小权值路径计算问题.该问题是图论中的经典问题,能够通过迪杰斯特拉算法求解.本文暂未对迪杰斯特拉算法做改进和创新,未来的研究工作可以深入探索更为高效的最小权值路径求解算法.
以图1(b)为例,从源站点s3到目的站点s10的最优路径为R=〈s3,s6,s9,s10〉,该路径在图1(a)中以深色背景道路展示.
从源站点到目的站点的最优路径优先使用权值较小的边,可能导致该边被多个数据流量占用.当传输数据过多时,算法将流量集中于某些边,造成拥塞导致传输效率下降.为解决该问题,本文设计了拥塞处理机制.当车辆转发数据失败时,若两车仍处于通信范围内,则携带数据的车辆再次尝试转发数据.若3次尝试均失败,则判定该路段上产生拥塞,重新为数据包规划路径,避开当前拥塞路段.同时将拥塞消息广播给附近的车辆,其他车辆接收到拥塞消息后只进行一次数据传输的尝试,若失败则立即重新规划传输路径.拥塞消息具有一定的有效期,有效期结束则恢复原有的路径规划.拥塞处理机制有助于加速数据转发和缓解拥塞状况.
3 公交车的数据转发策略
3.1 骨干公交和候补公交转发
当一个公交车载节点携带数据到达站点si时,称该节点为当前公交、该站点为当前站点,接下来预期沿着最优路径R将数据传输到下一个站点sj.
当前公交计算在站点si和sj之间转发数据的骨干公交集合,即KBi,j={bg|〈si,sj〉⊆Pg}.由于骨干公交将到达的站点为R中下一个站点sj,因此,相较其他公交,骨干公交能够以更高的概率和更短的时延沿最优路径传输数据.若当前公交的通信半径内存在多个骨干公交(称为邻居骨干公交),则计算每个邻居骨干公交与最优路径的后续站点重合度:
(3)

后续站点重合度反映了骨干公交的未来行驶路线和最优路径的重叠程度,重合度越高意味着骨干公交沿最优路径转发数据的距离越远,因此当前公交选择后续站点重合度最大的邻居骨干公交转发数据.当存在多个具有最大重合度的骨干公交时,选择发车频率δm最大的节点做为下一跳.
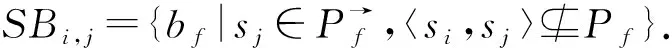
在图1(a)场景中,数据传输的最优路径为R=〈s3,s6,s9,s10〉,当前站点是s6时,沿最优路径的下一个站点是s9.经过s6的公交线路集为C6={b1,b5,b6},b1经过的站点序列为P1=〈s1,s6,s11〉,b5的站点序列为P5=〈s1,s6,s9,s7,s2〉,b6的站点序列为P6=〈s3,s6,s9,s10〉.从s6到s9的骨干公交集合是KB6,9={b5,b6}.若同时存在b5和b6线路的邻居骨干公交,则计算Y5=2和Y6=3,故优先选择b6公交转发数据.当数据继续传输至站点s9时,骨干公交集合为KB9,10={b6},若不存在b6线路的邻居骨干公交,由于b2也去往预期的下一站点s10,故选择候补公交SB9,10={b2}来转发数据.
候补公交通常不沿最优传输路径行驶,绕行导致传输代价升高.为了避免代价过高的转发,本文为候补公交设计绕行判定策略.分别计算骨干公交和候补公交传输数据到最优路径上的下一站点的路径权值,若候补公交的路径权值大于骨干公交的ρ倍,则判定绕行代价过高,舍弃该候补公交;否则,可以选择该候补公交转发数据.ρ的取值依据公交线路规划和服务质量需求分析得到,在本文实验中,ρ=2.
实际应用中可能不存在候补公交的长距离绕行,例如本文实验中最多绕行3个站点,这是因为最优路径上2个站点之间有公交连续经过,其路径距离通常不会过长,而城市公交线路的规划避免了长距离的绕路.除短距离绕行外,还有部分候补公交无绕行,这源于快速公交和普通公交的路线重叠,例如:普通公交b1和快速公交b2的行驶路线完全相同,但b1比b2停站多,b1经过的站点序列为P1=〈s1,s2,s3〉,b2站点序列为P2=〈s1,s3〉,当数据从站点s1发往s3时,普通公交b1是候补公交,其传输过程不存在绕路.
在市中心主干道路上传输数据时,可能存在不同公交线路的传输效率相近的情况.考虑到在分布式车联网中,每个携带数据的车载节点独立执行转发决策,难以在全局层面实现分流控制,因此当存在多个优先级相同的公交节点时,携带数据的节点执行简单高效的随机选择.
3.2 私家车多跳链路传输
当不存在骨干公交或候补公交时,当前公交利用数量相对较多的私家车建立多跳链路来寻找合适的公交节点.在图2场景中,当数据传输至站点s9时,当前公交的通信范围内不存在骨干公交或候补公交,此时以该车为起始节点通过私家车建立多跳链路,经过探寻在三跳内找到合适的公交转发节点,成功建立多跳链路实现数据传输.

Fig. 2 Establishment of a multi-hop link to find a backbone or supplement bus图2 构建多跳链路寻找骨干公交或候补公交
为了提高多跳链路的传输性能,在下一跳节点选择时,计算当前车辆z和邻居车辆w之间链路的传输指标:
NRz,w=(RVz,w+1)×RDz,w×RLz,w,
(4)
其中,RVz,w表示车辆z和车辆w的相对速度值,RVz,w≥0;RDz,w表示车辆z和车辆w的相对行驶方向,同向行驶RDz,w=1,反向行驶RDz,w=0;RLz,w表示车辆z和车辆w的相对位置,若w位于z的前方,则RLz,w=1,否则RLz,w=0.
在多跳链路建立过程中,当前车辆总是选择NRz,w取最小正值的邻居车辆来转发数据.NRz,w>0保证数据只向同向行驶的前方车辆传递(排除RDz,w=0或RLz,w=0的情况).当有多个NRz,w为正值的邻居车辆时,考虑到相对速度小的车辆之间通信链路的稳定性好,所以优先选择NRz,w较小的车辆转发数据.注意:式(4)使用RVz,w+1是为了避免RVz,w=0的节点不能被优先选择.
多跳链路的建立过程如算法1所示.

当前车辆(携带数据的公交节点)发送HELLO报文来收集邻居车辆(在其通信范围内的私家车)的速度和位置信息;据此计算邻居车辆的传输指标NR,选择NR取最小正值的车辆作为中继节点.当前公交向中继节点发送路径请求报文ROUTE_REQ,该中继作为新的当前车辆检查是否存在邻居骨干公交,若是则向后续站点重合度最高的骨干公交发送ROUTE_REQ报文,骨干公交返回ROUTE_REPLY报文(其中记录发送节点的ID),当前节点向上一跳返回ROUTE_REPLY报文;否则,当前车辆检查是否存在邻居候补公交,若是,则向任意一个候补公交发送ROUTE_REQ报文,该候补公交返回ROUTE_REPLY报文,当前节点向上一跳返回ROUTE_REPLY报文;否则,即不存在合适的邻居公交,当前车辆重复上述过程,选择中继节点.在多跳链路构建的时间阈值内,若起始节点收到ROUTE_REPLY报文,表示找到了去往公交转发节点的多跳链路,则依据ROUTE_REPLY报文中记录的沿途各个车载节点ID,将数据发送到公交节点.
当数据沿最优路径转发,通过以上策略无法找到合适的转发节点时,数据将由当前公交继续携带到下一站点.此时数据传输轨迹偏离了预期的最优路径,因此当前公交以下一站点为源站点,重新计算最优路径,数据沿新路径向目的站点传输.在图1(b)中,当数据在源站点s3处被b7公交车携带且周围没有合适的转发节点时,数据被携带至下一站点s4,此时偏离了最优路径,因此以s4为源站点重新计算最优路径R=〈s4,s7,s10〉,沿该路径传输数据.
4 实验结果与分析
4.1 实验环境设置
车联网研究最终需要在真实的车辆上安装车载单元(on-board unit, OBU)来实现车内信息采集和车辆之间通信,并通过对车载单元底层传输模块的重新编码来支持所提出的传输算法,从而实现对算法性能的评估.考虑到车载单元安装与车内总线等硬件相关,车辆改装成本高、难度大,且车载单元价格昂贵(大约几万元/个),目前难以实现大规模部署实验,因此科研人员一般采用仿真实验来评估算法性能.本文使用北京市真实路网和公交线路,并选择合适的网络参数,使得仿真实验的设计尽可能接近真实水平.将来随着车联网的发展和普及,真实实验的部署环境逐步成熟,我们将尝试真实实验来验证算法性能.
实验场景选自北京市东二环周围5 km×4 km的区域,城市路网信息来自开放的地图协作平台OpenStreetMap[29].场景中包含859个交叉路口、1 989条街道(如图3所示)、198个公交站点(如图4所示)以及68条公交线路[30](部分线路如图4所示).公交发车间隔为300 s,在3 000 s的仿真时间内公交车总数为680辆.公交车沿各自固定的公交线路行驶,私家车随机分布并行驶在道路上.使用道路交通模拟器SUMO 0.30.0[31]生成公交车和私家车的行驶轨迹.依据2015年北京市交通运行报告[32],早晚高峰期间全路网车辆平均速度分别为28.1 km/h和25.1 km/h,同时参考相关工作的实验设计,本文实验中将车辆速度的区间范围设置为10~40 km/h,增加车辆速度的随机性,以检验算法的鲁棒性.仿真环境配置见表2.
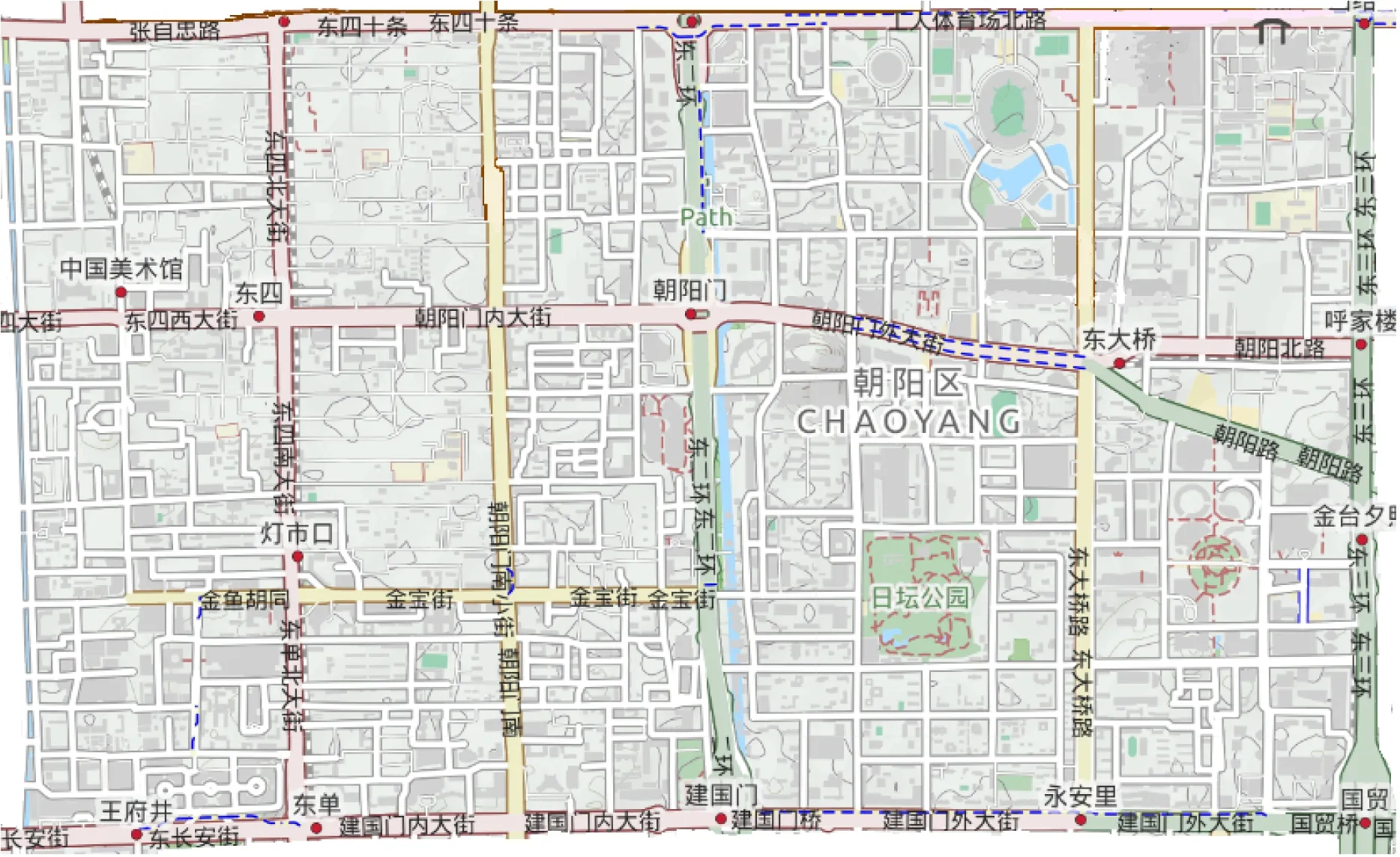
Fig. 3 The scenario around the East Second Ring Road in Beijing图3 北京市东二环附近的场景
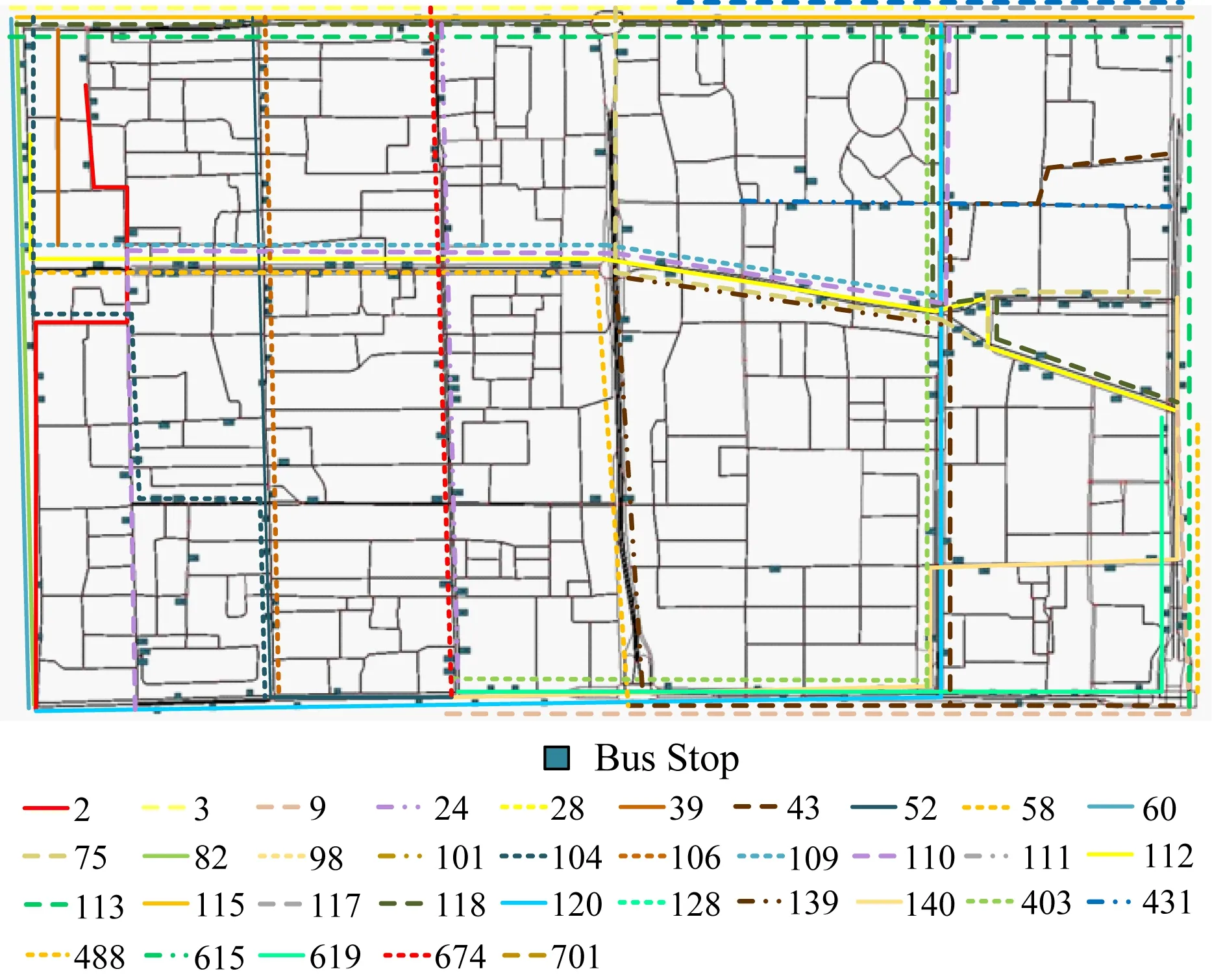
Fig. 4 The road map, the bus stops and a part of bus lines in the scenario图4 场景中的路网、公交站点和部分公交线路
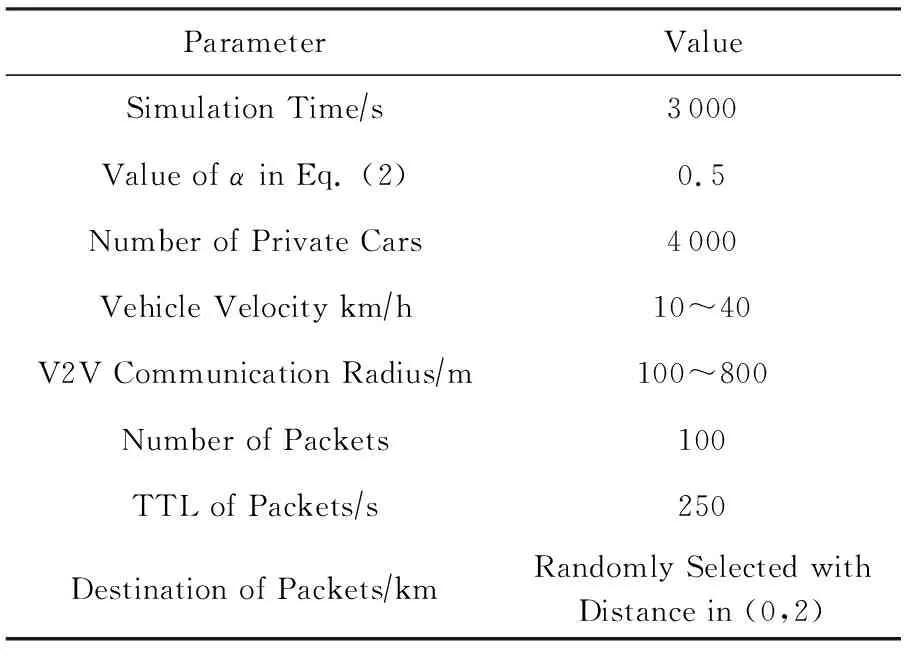
Table 2 Simulation Environment Configurations
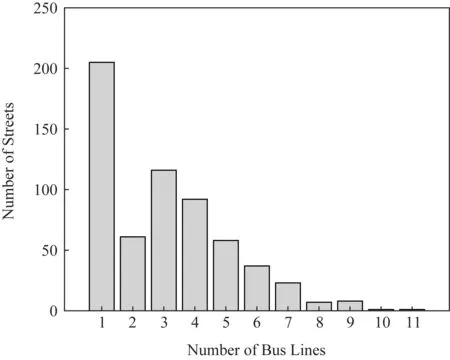
Fig. 5 Distribution of bus lines on main streets图5 主干街道公交线路分布情况
为了验证所选场景的可用性,对所有长度大于150 m的主干街道统计其公交线路分布情况,如图5所示.在710条主干街道中,609条有公交线路经过,其中404条街道的公交线路不少于2条,而公交线路不少于5条的街道(即公交密集型街道)有198条,约占街道总数的28%.图6(a)展示了途经若干个公交站点(x轴)的公交线路数量(y轴),反映了公交线路长度的分布情况,可见途经3~6个站点的公交线路较多.图6(b)展示了有若干个公交线路(x轴)通过的公交站点数量(y轴),反映了公交站点热度的分布情况,可见有2~6条线路通过的公交站点较多.
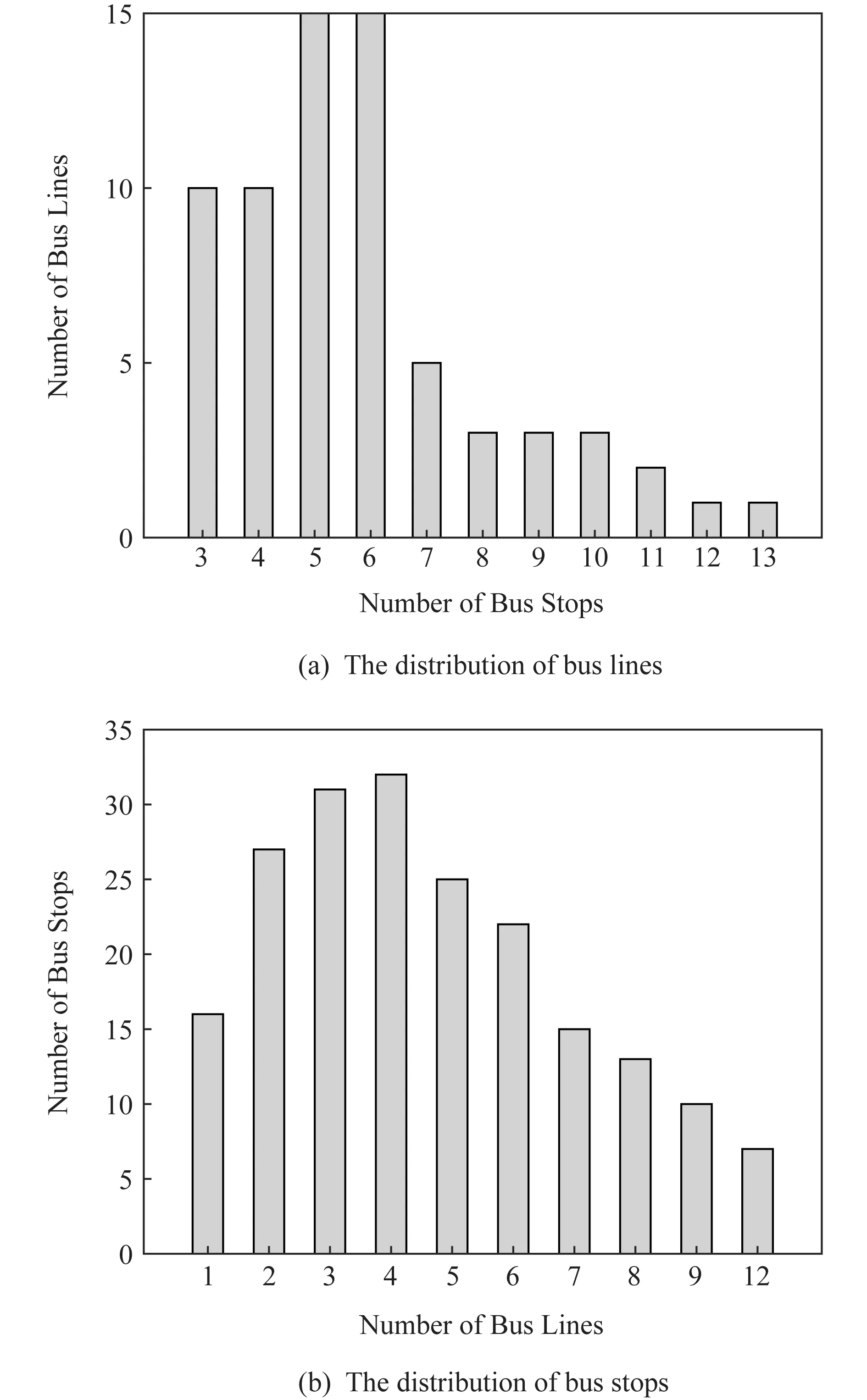
Fig. 6 The distributions of bus lines and bus stops图6 公交线路和公交站点的分布情况
为了验证本文提出的数据转发机制BUF的性能,选择VANETs中2种公交路由算法BTSC[27]和BLER[33]作为对比方法.在以街道为中心的BTSC算法中,数据沿着公交密度高的街道转发,2个公交之间的多跳链路使用蚁群算法建立.在BLER算法中,以公交线路为顶点,在具有通信机会的不同线路之间连边,构建无向图,并根据通信机会大小,计算每条边的权值,数据传输路径即是无向图中源点到目的点的最大权值路径.为了分析骨干公交、候补公交和私家车对BUF转发决策的影响,实验对比分析了BUF的2个变体,分别为BUF-B和BUF-BS.在BUF-B中,仅使用骨干公交转发数据,未使用候补公交和私家车;在BUF-BS中,使用骨干公交和候补公交转发数据,未使用私家车.对比BUF和BUF-B能够分析骨干节点的作用,对比BUF-B和BUF-BS能够分析候补公交的影响,对比BUF和BUF-BS能够看到私家车多跳链路的效果.
实验分析了3个性能指标,包括数据包传输成功率、平均传输时延和平均传输跳数.传输成功率是指在数据包生命期内到达目的地的数据包占所有生成数据包的比率,传输成功率越大表明网络性能越好.平均传输时延是指成功传输的数据包从源点到目的地花费的平均时间,传输时延越短表明网络的数据传输速度快、效率高.平均传输跳数是指成功传输的数据包从源点到目的地的平均转发次数,跳数越少表明网络的传输开销越小.
4.2 结果分析
当车载节点的通信半径取自100 m到800 m时,5种对比方法的传输成功率、平均传输时延和平均传输跳数分别如图7~9所示.为了保证实验结果的可靠性,开展20次独立重复实验,计算所有实验结果的平均值和四分位距(interquartile range, IQR).同时,为了避免在相同横坐标处不同方法的标记重叠而影响清晰度,在结果图中将部分标记的位置略做偏移.
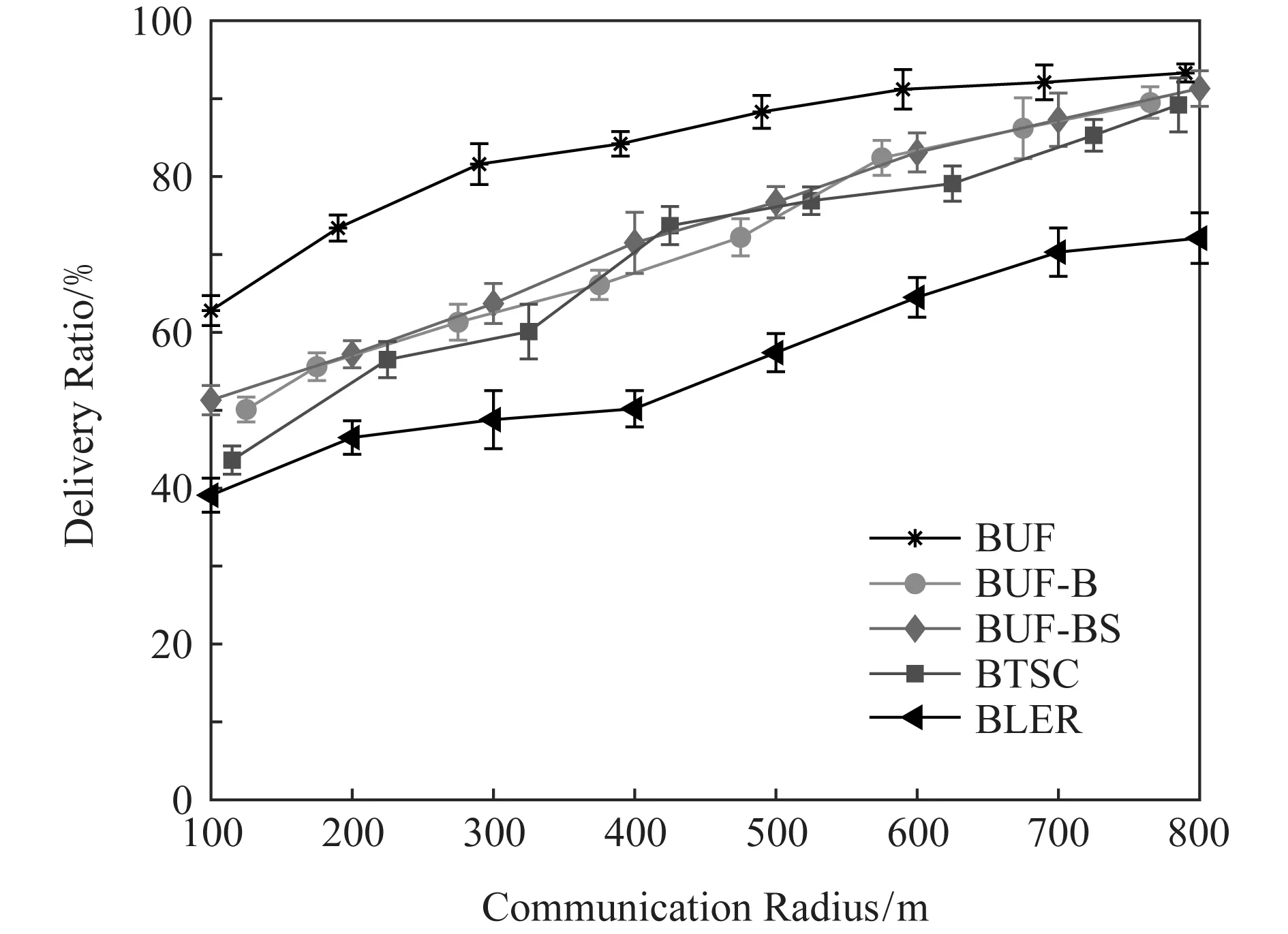
Fig. 7 Delivery ratio with different communication radii图7 传输成功率随通信半径的变化
如图7所示,所有方法的传输成功率有相同的变化趋势.随着通信半径的增大,数据传输的成功率逐渐升高.相较其他方法,本文提出的BUF机制在各种通信半径下所达到的传输成功率最高.由于缺少其他社会车辆的参与,BUF-BS的传输成功率低于BUF,可见私家车优化传输效果明显.根据2015年北京市交通运行分析报告[32],实验选用的东二环附近车流量达到每天19万辆,7:00—22:00平均车流量可达每小时4 500辆,可见实际道路上的私家车密度较大,能够辅助数据传输.同时BUF-B的传输成功率略低于BUF-BS,说明候补公交有一定的辅助作用.BUF-BS较BUF-B无明显优化效果是因为候补公交的传输机会较少,一方面候补公交的优先级低于骨干公交,只有不存在骨干公交时才会选择候补公交;另一方面候补公交通常不沿最优路径行驶,携带数据的车辆与候补公交的相遇概率小.在BTSC中,通过蚁群算法构建多跳链路,该算法的收敛需要一定时间,导致部分多跳链路建立失败,影响了数据传输.BTSC算法未达到文献[27]中展示的效果,是因为文献[27]的实验场景中公交线路是模拟的,公交车辆密度大且分布均匀,而本文实验使用真实公交线路,车辆密度小且分布不均匀,算法性能下降.
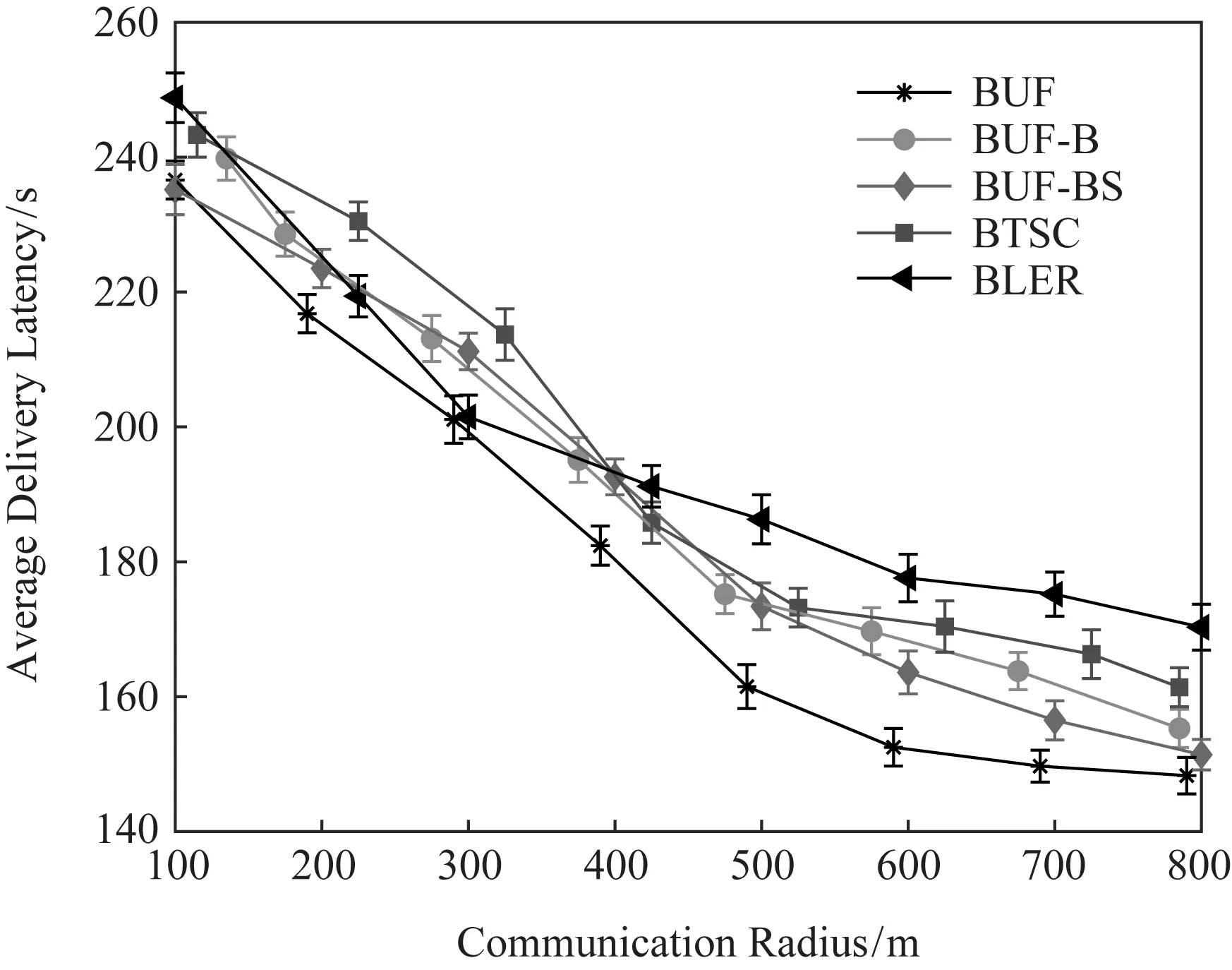
Fig. 8 Average delivery latency with different communication radii图8 平均传输时延随通信半径的变化

Fig. 9 Average number of hops with different radii图9 平均传输跳数随通信半径的变化
在图8中,随着通信半径增加,各个算法的数据传输时延都明显缩短.在5个对比算法中,本文提出的BUF机制在不同通信半径下都达到了最短的传输时延.BUF-B和BUF-BS由于缺少私家车建立的多跳链路的辅助,传输时延比BUF长.
如图9所示,较大的通信半径导致数据包到达目的地所需的传输跳数更少.当通信半径大于500 m时,BUF的传输跳数大于BTSC和BLER,这是因为BUF尽可能利用多跳中继来传递更多的数据包,尽管如此,考虑到BUF具有较高的传输成功率和较短的传输延迟,相对较大的传输开销是可以接受的.
综上所述,本文提出的BUF机制的传输成功率相较BTSC和BLER分别提高了约16%和33%,平均传输时延比BTSC降低7%,比BLER降低9%,传输跳数略大于对比算法.
为了验证拥塞处理机制的性能,开展一组对比实验,统计BUF算法(加入拥塞控制)和BUF-C算法(未加入拥塞控制)的数据传输成功率,结果如图10所示:
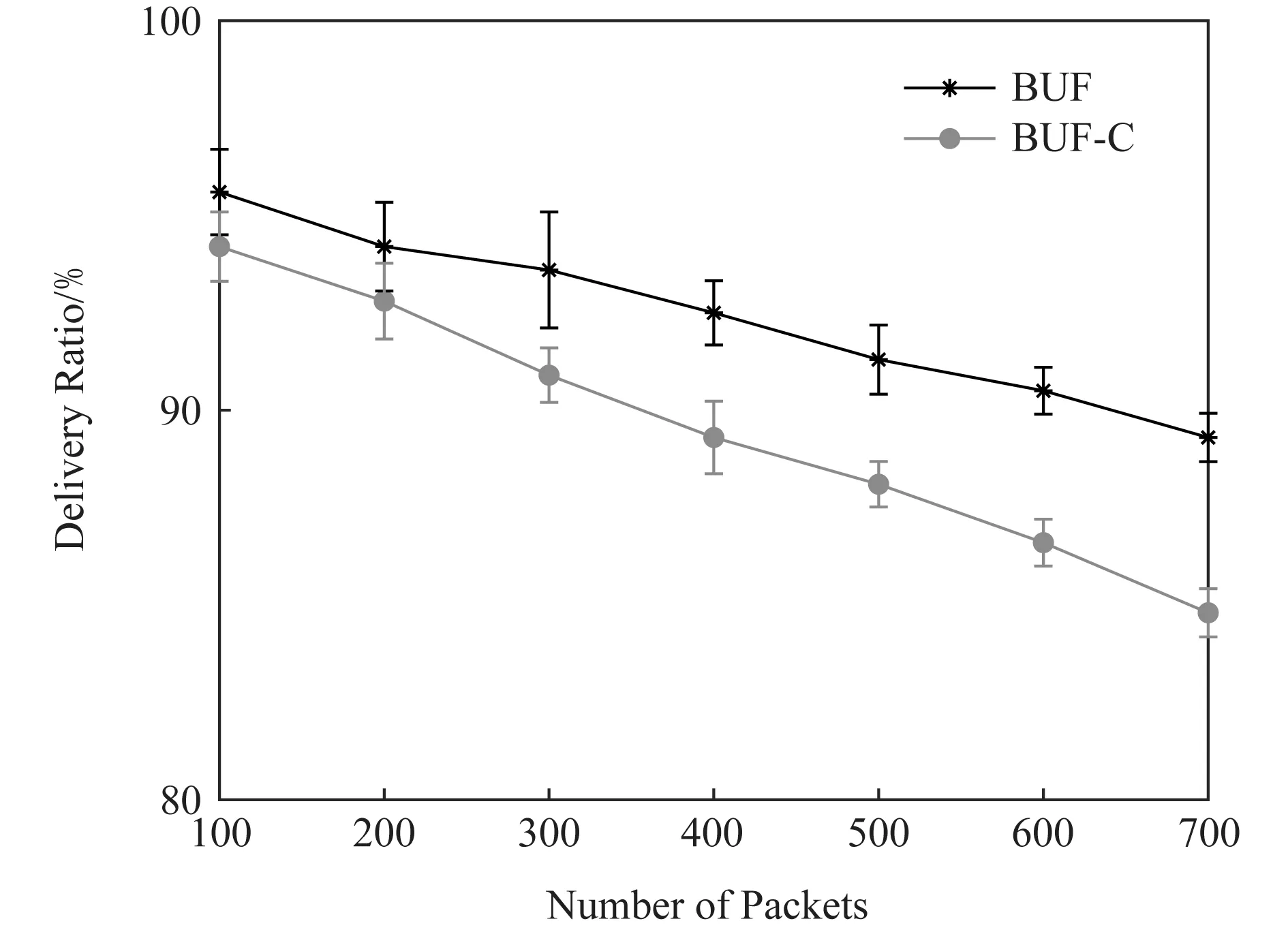
Fig. 10 The effect of congestion handling scheme on delivery ratio图10 拥塞处理机制对传输成功率的影响
由图10可知:当网络中数据包较少时,2个算法性能相差不大,BUF的传输成功率略高于BUF-C.但随着发包数量的增加,网络拥塞加重,2个算法的差距不断增大,BUF较BUF-C传输了更多的数据包.该实验说明拥塞处理机制有助于提升数据传输质量,特别是在网络流量较大时,该机制能够降低拥塞对传输性能的影响.
4.3 参数分析
1) 发车间隔的影响
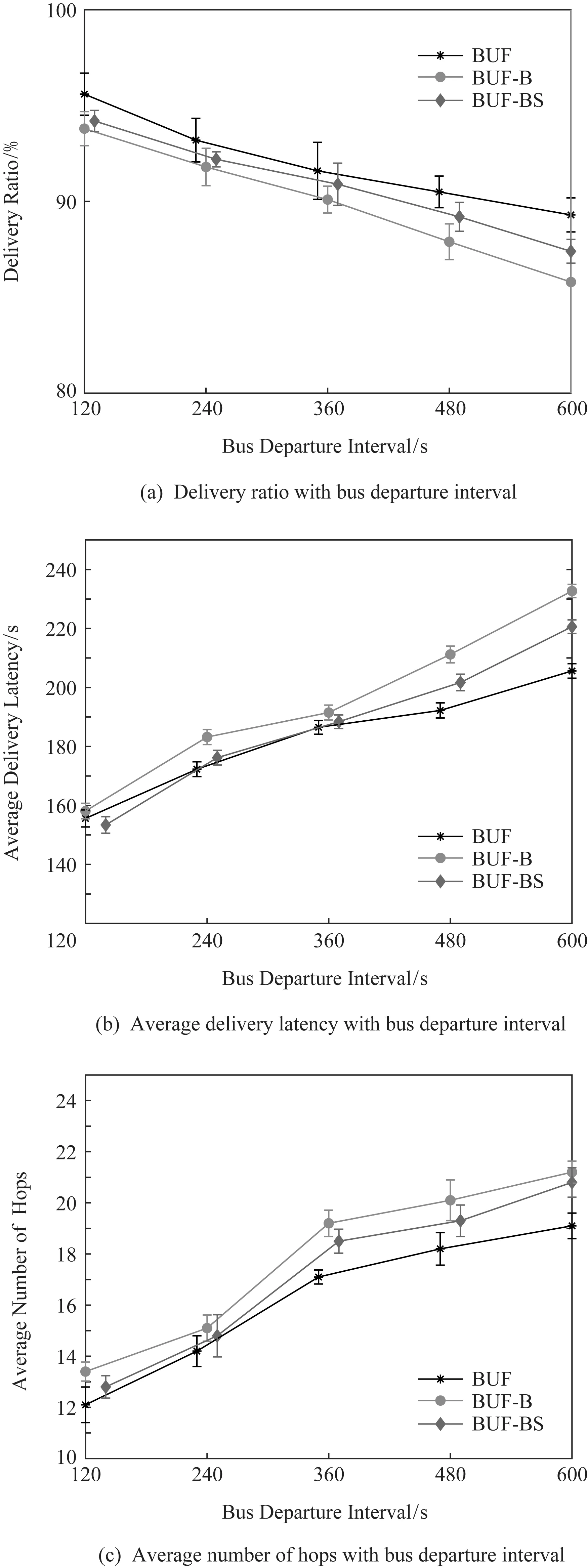
Fig. 11 The effect of bus departure interval on data transmission图11 公交发车间隔对数据传输的影响
公交车的发车间隔影响着场景中的公交车规模,进而影响着车联网数据传输性能.为了进一步研究发车间隔对本文提出的BUF方案及其变体BUF-B和BUF-BS的影响,将公交发车间隔分别设置为120 s,240 s,360 s,480 s和600 s,3种机制的数据传输成功率、平均传输时延和平均传输跳数如图11所示.

Fig. 12 The effect of the value of α on data transmission for BUF图12 BUF中α取值对数据传输的影响
如图11(a)所示,随着公交发车间隔的增大,3个方案的传输成功率均下降,其中BUF-B和BUF-BS受到的影响较大,这是由于发车间隔增大导致道路上的公交车密度减小,数据转发机会减少.同理,在图11(b)中,当发车间隔变大,数据缺少合适的下一跳转发公交,因此被携带的时间更长,BUF-B和BUF-BS的传输时延变长,而BUF机制通过私家车建立多跳链路更快地找到下一跳转发公交,因此受发车间隔影响而导致时延增加的幅度较小.如图11(c)所示,当发车间隔较短时,数据传输的平均跳数较小,这是由于公交节点的密度较大,使得当前车辆有机会在大量邻居公交节点中选择更合适的下一跳节点;随着发车间隔的增大,当前节点不得不选择优先度较低的转发节点,导致传输跳数增加.
2) 权值的影响
在式(2)中,预期公交车数量和站点间距离的权重(α和1-α)的取值直接影响了边权值的计算,进而影响最优路径的选择.针对不同应用的服务质量需求,对α的测量执行多轮筛选,逐步缩小取值范围,直到α取值满足精度要求.本文实验对α的测量使用2轮筛选,初次筛选为粗筛,将α的取值范围设为0.1~0.9递增变化,间隔0.1,相应地,距离的权值1-α从0.9到0.1递减变化,此时BUF机制的实验结果见图12.
由图12(a)可见,当α取值较小(α<0.7)时,传输成功率随着α变大逐步上升,直到达到峰值(约90%),表明预期公交车数量是边权值计算中的主要因素.当α过大(α=0.8或α=0.9)时,传输成功率下降,表明距离因素在转发节点选择中具有一定的影响.在图12(b)中,随着α取值逐渐增大,数据传输时延逐渐减小.当α=0.7时,传输时延达到最小值(约150 s);当α值继续增大时,传输时延出现了增大的情形.由图12(c)可见,当α=0.7时,数据传输所用跳数达到最小值(约14跳).因此,该场景的实验中,α的最佳取值靠近0.7.
为进一步精确α取值,在第2轮数据筛选中,α取值在[0.6,0.8]范围内且以0.025为步进长度,实验结果如表3所示.
由表3可见,当α=0.725时传输成功率最大,当α=0.675时传输时延最短,当α=0.7时传输跳数最少.根据不同的服务质量需求,选取最终的α值,例如以最大化传输成功率为目标时,α=0.725.该实验表明,α值太大或太小都会降低BUF机制的性能,证明了预期公交车数量和站点间距离对数据传输的影响,而针对具体应用的理论分析和采样实验是选择合适α值的有效方法.

Table 3 Effect of α in the Range of [0.6,0.8] on Data Transmission
5 总 结
本文提出公交数据驱动的城市车联网转发机制(BUF),旨在利用公交站点和公交线路等信息选择传输路径和转发节点,从而提升车联网数据传输性能.首先构造公交站点拓扑图,以公交站点为顶点,依据公交线路经过的站点序列,在顶点之间连边,并根据预期公交车数量和站点间距离计算边权值,进而由迪杰斯特拉算法计算权值最小的路径做为最优路径.为了保证数据沿最优路径传输,优先选择后续站点重合度最高的骨干公交转发数据;当没有骨干公交时,后续将经过期望的下一站点的候补公交做为转发节点;当骨干公交和候补公交都不存在时,由私家车建立多跳链路来寻找合适的公交转发节点.该转发策略增加了数据快速沿最优路径传输的机会.使用北京市真实路网和公交线路的仿真结果表明,与其他算法相比,BUF机制具有较高的传输成功率和较短的传输时延.
将公交线路数据与车辆轨迹大数据结合,有望进一步优化车联网数据转发,未来的研究工作可以探索利用人工智能方法来解决该问题.
