基于信用评分和数据挖掘对商业贷款违约情况的预测方法研究
2020-04-20聂纪予


摘要:随着贷款消费的发展,信贷管理中存在着诸多问题并且也面临着一些难以掌控的风险,如果能利用数据挖掘技术,通过对贷款人的各类数据进行分析,从而得出一个相对准确的借贷判断,那么对于金融部门会有很大价值。本文对数据挖掘的关键技术和相关挖掘分析方法进行了分析与解释,利用现有的数据对多个模型进行比较得出了相对准确性较高的建模方法,最后对这一方法对社会的价值进行了简要的评述。
关键词:贷款违约;支持向量机;CART;信用评分模型
中图分类号:F832.33;F224 文献识别码:A文章编号:2096-3157(2020)04-0144-04
一、研究背景
随着国家经济实力的稳步发展,国民生活条件得到了进一步的提高,人们的支出也随之加大,贷款这种方式也因此越来越受到人们的青睐。而且信息技术的不断发展使贷款脱离了银行的限制,越来越多的商业团体也开通了贷款业务,如蚂蚁花呗等方式使得贷款消费更加得大众化,选择贷款消费的人也越来越多。贷款违约现象给金融部门会带来严重的经济损失。因此,建立合适的个人信用评分方法迫在眉睫。
为保障银行或者其他金融部门的安全,信用评分应运而生。该模型利用客户的历史资料和行为特征,对客户进行评分,从而来决定客户所能持有的金额限度,保证还款等业务的安全性。20世纪40年代以来,信用评分技术发展速度惊人。以美国为代表的西方资本主义国家已经建立了非常完善的信用评分系统。我国目前也在进行这方面的研究,但是还不太成熟,这个领域中仍然还有很多机会。
传统的理念当中,采用的变量较少,每个变量均与客户信用具有较强的关联关系,对信用评估起着决定性作用。但当前的大数据背景,使得可用于评分的变量增多,每个变量的比重有所下降,但变量的联合可以进行更好的预测。当然这需要对大量的数据进行复杂的分析处理。而处理许多变量和弱特征时,就需要一种复杂的技术算法作为其基础。
利用数据挖掘的方法来处理贷款问题在国外已有初步研究。Herzog等在对抵押预期的分析中,发现收入波动性大的借款人更有可能发生拖欠行为[1]。我国这方面的研究起步较晚,但在研究的阶段也取得了一定的成果。孙大力提出在应用信用评分模型时除了借鉴国外的成熟方法,还应注意结合我国国情与特殊情况,特别关注总体样本、个人信用动态变化、特征变量的选取、临界值判断等具体问题[2]。王春峰等采用多种方法,主要有Logit回归、线性判别法、神经网络模型和遗传规划模型等,研究了信用风险控制理论[3]。
二、数据与方法
1.研究数据
在本研究中,笔者选用了UCI网站的数据集(http://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients)。該数据集共包含30000条数据。因变量Y是是否违约,0是未违约,1是违约。自变量给出了23个选项。
2.模型描述
根据UCI上的违约信用评分数据,我们采用混合SVM的方法建立分类模型,模型判别的结果是消费者是否违约。我们的建模思路主要分以下两步进行。第一步,使用CART模型选择合适的特征;第二步,将第一步选出的特征放入SVM进行分类。
首先,我们对所使用方法的基本原理进行简要介绍。
(1)CART算法
CART(Classification And Regression Tree,分类回归树)是在给定输入X条件下输出随机变量Y的条件概率分布的学习方法,本身属于决策树分类法。决策树的生成过程就是使用满足划分准则的特征不断将数据集划分为纯度更高,不确定性更小的子集。对于当前数据集D的每一次划分,我们都希望根据某特征划分之后的各个子集的纯度更高,不确定性更小。这里我们选择CART方法进行分类,对特征重要性排序,从而选出有研究价值的特征。
CART二分每个特征(包括标签特征、连续特征,即分类型与数值型数据均可),经过最优二分特征及其最优二分特征值的选择、切分、二叉树生成、剪枝来实现CART算法。与其他决策树算法不同的是,CART选择使得基尼系数最小的剪枝方法。图1所示为CART算法与其他决策树算法的对比,决策树的ID3算法和C4.5算法利用熵来度量,生成了相对较为复杂的多叉树,且只能处理分类问题。CART算法使用基尼系数来代替信息增益比,基尼指数Gini(D)表示表示在样本集合中一个随机选中的样本被分错的概率。如图2所示,基尼指数越大,样本的不确定性也就越大,可以作为熵模型的一个近似替代,由此避免大量对数运算,简化模型同时也不至于完全丢失熵模型的优点。
其中:
基尼指数(基尼不纯度)= 样本被选中的概率 ×样本被分错的概率(1)
在分类问题中,假设有K类,样本点属于第k类的概率为pk,则基尼系数表达式为:
Gini(p)=∑Kk=1pk(1-pk)=1-∑Kk=1p2k(2)
对于分类问题:设Ck为D中属于第k类的样本子集,则基尼指数为:
Gini(D)=1-∑Kk=1|Ck||D|2(3)
对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为:
Gini(D,A)=|D1||D|Gini(D1)+|D2||D|Gini(D2)(4)
(2)支持向量机模型
SVM(Support Vector Machine,支持向量机)的分类思想本质上和线性回归LR分类方法类似,即求出一组权重系数,通过线性表示进行分类。先使用一组训练集来训练SVM中的权重系数,得到分割超平面,该平面即为分类的决策边界,分在平面两边的就是两类。进而找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能远,最大化支持向量到分隔面的距离。显然,经典的SVM算法(图3)只适用于两类分类问题。
但经过改进之后,SVM也可以适用于多类分类问题。实际上,低维非线性的分界线在高维是线性可分的。由于从输入空间到特征空间的这种映射会使得维度发生爆炸式的增长,因此上述约束问题中的内积运算会非常大以至于计算机无法承受。通常需要构造一个kernel函数。通过kernel核函数,将低维函数转化为高维函数,只需要在输入空间内就可以进行特征空间的内积运算。
常用的核函数包括线性核函数、多项式核函数、高斯(RBF)核函数、sigmoid核函数等,每种核函数均具有自己的特征和使用情形。
三、计算与结果分析
1.模型预处理
在模型建立之前,首先要进行数据的预处理。数据的预处理主要包含以下几个方面:
第一,对数据集进行了切分处理,在切分过程保持正负样本比例。以下是数据集切分结果(表2),切割中训练集和测试集的比例是8∶2。
第二,通过欠采样和过采样处理正负样本分布不均的问题。为了解决类别不平衡对模型输出的影响,通过采用欠采样和过采样的方式,来调整数据的不平衡。为了保证结果的可比性,要始终保持同一测试集对效果进行检验,通过采样的方式来调整数据的不平衡。欠采样是从不违约的人数中随机抽取,进而使不违约人数数量减小,与为违约人数相同。过采样是从违约的数据集中有放回抽样,进而使违约人数数量增加,与未违约人数相同。表3是在核函数为RBF函数的时候,样本未处理与欠采样、过采样的模型效果对比,可见采样的方式可以显著提高模型效果。
第三,对数据进行归一化处理。常见的数据归一化的方法有两种,第一种方法是利用min-max标准化的离差标准化方法,max为样本数据的最大值,min为最小值。该方法是对原始数据的线性变换,使结果落到[0,1]区间。第二种方法是z-score的标准差标准化方法。该方法下经过处理的数据符合标准正态分布。将数据进行归一化,便于不同单位或量级的指标能够进行比较和加权,也能显著提高模型的训练速度。
第四,对分类型数据进行离散化处理。对于数值型数据来说,不同数据之间的差值是有意义的,较小的差值可以反映变量的相似情况。但是对于分类型数据来说,不同代码数字之间的差值是无意义的,因此采用one-hot的编码方法进行二元化处理。表4是利用该编码处理的一个例子,从中可以更清晰地看到编码方法。
第五,利用CART进行特征选择。利用Salford System公司的软件CATR 4.0和MART 2.0进行特征选取。这样不仅能很好地解决分类与回归问题,而且可以对变量的重要程度进行排名,是很好的特征选取工具。得到的结果如图5所示。
2.模型调参
模型调参主要分为三个部分:利用不同的核函数进行处理,进行特征选择和对原始数据进行采样。在核函数调参过程中,主要使用了线性核(linear)、多项式核(poly)、径向基函数(rbf)函数进行模型调整;在数据的特征选择中,主要使用CART方法,选择了重要程度更高的特征;在于原始数据采样中,采用了不处理、欠采样和过采样三种方法对数据进行处理。
3.模型评估
对于模型效果的评价,主要选择以下指标来说明模型效果。
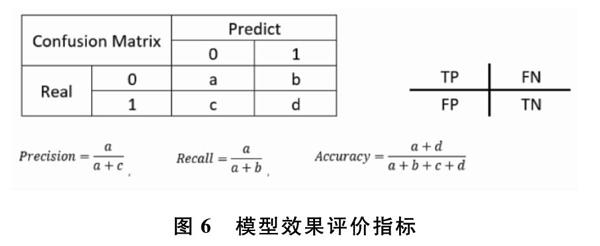
根据混淆矩阵可以得到TP、FN、FP、TN四个值,TP即为预测正确的违约用户的个数,FN为预测错误(预测为不违约)的违约用户个数,根据这四个值即可计算精确率、召回率和F1。
精确率(Precision)为TP/(TP+FP),即为在预测为违约的用户中,预测正确(实际为违约)的人占比。
召回率(Recall)为TP/(TP+FN),即为在实际为违约的用户中,预测正确(预測也为违约)的用户占比。
F1值是精确率和召回率的调和均值,即F1=2PR/(P+R),相当于精确率和召回率的综合评价指标。在输出结果不平衡的模型中,F1值是对模型结果的综合考量。
第一类错误,为FN/(TP+FN)。即在预测违约的用户中,实际是不违约的用户。
第二类错误,为FP/(FP+TN)。即在预测不违约的用户中,实际是违约的用户的占比。
在商业信贷模型中,用户违约带来的损失是更大的,因此,第二类错误是重点关注的指标。
表5为不同模型下的计算结果,可以看出,CART1+SVM(RBF)能够产生最好的分类效果。并且在该方法在欠采样的情况下,第二类错误也可以得到很好的控制。
四、结论
准确的信用评分模型和对用户是否违约的判断,对银行业务来说是至关重要的,因为用户违约对银行带来的损失是非常大的。这也要求模型要做到对违约用户的有效甄别。
就建模过程来讲,本研究的意义在于建模过程和方法的指导。研究表明,CART1+SVM(RBF)能够产生最好的分类效果。因此,在利用SVM建模的时候,推荐使用CART1先进行变量选择,利用重要的变量进行SVM,能够取得更好的效果。CART1+SVM(RBF)的方法,不仅具有较好的召回率和精确度,而且犯第二类错误的概率也更小。
参考文献:
[1]Herzog,I.P.,&Earley,J.S.Home Mortgage Delinquency and Foreclosure[J].New York:National Bureau of Economic Research,1970,34~41.
[2]孙大利.个人信用评分模型综述与应用分析[J].中国信用卡,2006,(9):27~34.
[3]王春峰,万海晖,张维.基于神经网络技术的商业银行信用风险评估[J].系统工程理论与实践,1999,(9):24~32.
作者简介:聂纪予,唐山市第二中学学生。
