基于IOWA算子的我国社会消费品零售总额的组合预测
2020-04-20江艳婷
江艳婷


摘要:为了准确判断我国的消费形势,选取我国2000-2018年的经济月度数据,首先基于机器学习的方法分别构建随机森林、支持向量机和BP神经网络三个单项预测评价模型对我国社会消费品零售总额进行预测,由于单项预测方法存在自身的优势与限制条件,于是引入了基于误差平方和最小的诱导有序加权算术平均(IOWA)组合预测模型,结果表明:组合预测模型各种预测误差均小于单项预测模型,说明文中构建的IOWA组合预测模型预测性能优越,具有较好的运用前景。
Abstract: In order to well and truly estimate the consumption situation in China, the economic monthly data of China from 2000 to 2018 was selected. In the first place, based on machine learning methods, three separate forecasting evaluation models of random forest, support vector machine, and BP neural network were used to forecast the total retail sales of social consumer goods in China. Due to the advantages and limitations of the single prediction method, an induced ordered weighted arithmetic average (IOWA) combined prediction model based on the squared error and the smallest error is introduced. The results indicated that: the various prediction errors of the combined prediction model are all smaller than the single prediction model,indicating that the IOWA combined prediction model has predominant forecast performance and good application future that built in this paper.
關键词:机器学习;IOWA算子;组合预测
0 引言
随着我国经济逐渐进入高质量发展阶段,消费需求已然成为经济增长的强劲动力,由消费需求引发的实际购买行为称之为消费力,消费力本质上是生产力的一种,没有消费行为,生产也就无法实现,而社会消费品零售总额是国内消费需求的最直接体现,是反映经济景气程度的重要指标,如何基于现实发展的要求,高效准确的预测社会消费品零售总额,对于挖掘消费潜力并进一步加强对经济增长的推动作用极具现实意义。
对于变量的单项预测方法较多,由于机器学习算法具有较强的学习能力,预测精度相对较高,因此文中的单项预测方法均运用机器学习去实现,机器学习源于McCulloch、pitts(1943)[1]开始研究的神经网络模型,到1986年,Rumelhart等(1986)[2]提出的BP神经网络成为了神经网络的最基本算法,在二十世纪90年代后支持向量机(SVM)衍生出了一系列改进和扩展算法,并得到了迅速发展,随后Leo Breiman(2001)[3]提出了随机森林算法,之后在预测研究中得到广泛运用。但每一种算法都有自身的优势与不足,如BP神经网络预测能够提取合理的计算规则,深入解决内部机制复杂的问题,但同时很有可能因局部极值问题,使训练失效;随机森林运行非常稳定,泛化能力强,但有时在噪音较大的分类或回归问题中上会出现过拟合现象;支持向量机小集群分类效率高,且可以通过核函数将线性不可分问题转化为线性可分,但难以确定最优核函数,鉴于此,组合预测方法则成为了研究的新方向,因为其能够结合单项预测方法的优势并缩小劣势,降低预测误差。而基于诱导有序加权算术平均(IOWA)算子的组合预测方法正是其中一种,区别于传统的组合预测方法,基于预测精度诱导的各单项预测方法在各时点的权重会发生变化[4-5-6],康义等(2016)[7]基于IOWA算子对我国省份的电力发展水平进行了一个综合评价,验证了该方法的有效性;孙丽、牟海波(2018)[8]构建IOWA算子的组合预测模型对我国高速铁路的客运量进行预测研究,发现IOWA算子的组合预测模型能够降低预测误差,提高预测精度。由于学者们对于消费预测的研究较少,且存在可以深化的空间,因此本文分别建立随机森林、支持向量机、BP神经网络和基于IOWA算子的三者组合预测模型,来寻求对于社会消费品零售总额最合适、高效的预测方法。
1 研究方法
1.1 随机森林
随机森林是由多颗决策树组合而成的分类器,即由N颗决策树构成,基于原始数据训练完成再进行预测,其中X是研究对象的影响因素,即输入变量,θk表示服从独立同分布的随机项,h(X,θk)为第K颗数的输出值,决策树可以用来分类和回归,当进行分类时,随机森林会基于投票制的原则,给予每颗决策树投票权,然后采用投票最高的那一类作为最终结果;当进行回归时,随机森林回归值为所有决策树输出值的平均值。
1.2 支持向量机
支持向量机是基于统计学习理论建立起的一种机器学习方法,其原理是将输入样本映射到一个高维空间,在此高维空间将复杂的非线性问题进行线性回归或分类。设定样本集,回归方程如下:
1.3 BP神经网络模型
BP神经网络由输入层、隐含层和输出层组成,在进行训练时,信号是从正向传播的,而误差是从反向传播的,为了减少误差,会由输出层出发并向前修正,文中建立三层的BP神经网络预测模型,输入层为7个神经元,分别为居民消费价格指数(CPI)、货币供应量(M1)、消费者满意指数、消费者预期指数、消费者信心指数、国家财政支出和货运量这7个影响因素,隐含层用来进行信息的处理,隐含层设计的确定是根据经验公式h=+a,其中h为隐含层神经元个数,m为输入层神经元个数,n为输出层神经元个数,a为调节参数,取值为[1,10]之间,文中隐含层神经元个数取值为[3.8,12.8]之间,文中设为10个神经元,输出层为1个神经元,代表社会消费品零售总额。
1.4 IOWA算子
1.5 评价准则
由xt为t时刻的实际值,设为各预测模型的预测值,文中选择平均相对误差(MRE)和均方百分比误差(MSPE)两种误差表现形式来评价各单项预测模型和组合预测模型,评价指标体系如下:
2 变量的选取与数据来源
由于我国社会消费品零售总额受到多种因素的影响,本文基于理论与现实基础,选取影响较大的七个影响因子,分别为居民消费价格指数(CPI)、货币供应量(M1/亿元)、消费者满意指数、消费者预期指数、消费者信心指数、国家财政支出(亿元)和货运量(亿吨)。样本区间为2000年1月至2018年12月,选取2000年1月至2017年12月总计216条数据为训练样本,分别建立随机森林、支持向量机、BP神经网络和组合预测模型,而2018年1月至2018年12月总计12条数据为测试集,用来验证预测模型的精度。居民消费价格指数的原始数据是上年同月环比指数,将其转化为以2000年为基期的定基指数。社会消费品零售总额共有228个月份数据,其中有10个月份数据缺失,于是基于原始数据采用指数平滑的方式进行预测。由于各变量量纲相差较大,为提高机器学习的收敛速度和精度,将数据进行归一化,归一至[0.1,1]区间内,归一化公式如下:
3 单项预测与组合预测结果比较
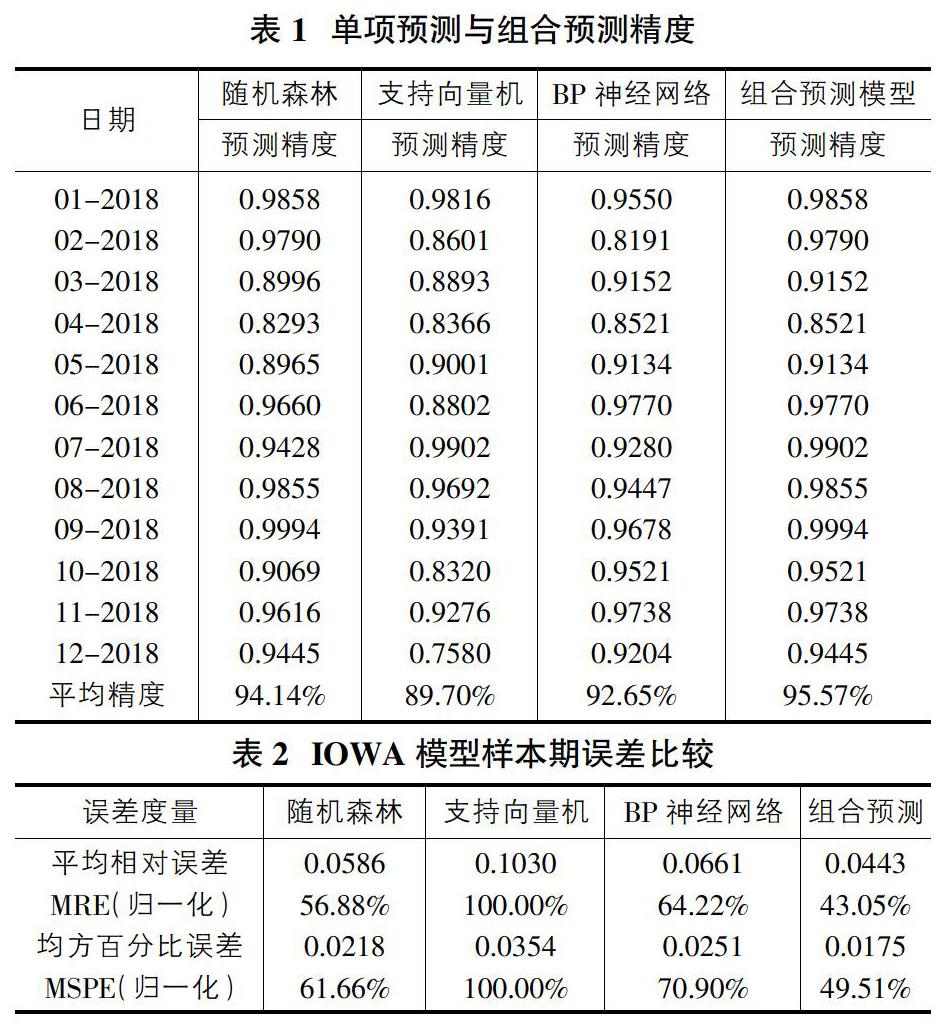
基于样本数据分别建立随机森林模型、支持向量机模型、BP神经网络模型及基于误差平方和最小的诱导有序加权算术平均(IOWA)组合预测模型,将测试集得出的预测值与实际值进行比较分析,并驗证模型精度如表1所示,样本期误差比较如表2所示。
首先由表1预测精度可知,在三种单项预测模型中,随机森林的预测平均精度最高,为94.14%,其次是BP神经网络模型,为92.65%,最后是支持向量机模型,仅有89.70%,说明在预测社会消费品零售总额方面,随机森林算法预测稳定,拟合较好,具有较优的预测性能,BP神经网络模型模型次于随机森林,可能是由于BP神经网络的结构选择没有统一、标准的理论支撑,文中BP神经网络的结构选择是由经验确定的,结构选择并没有达到最优,所以预测精度不是很高,支持向量机预测精度最差,可能没有确定最优的核函数。但总体来说,三种单项预测模型的预测性能还是较好的,最后,由三种单项预测模型构建的诱导有序加权算术平均(IOWA)组合预测模型在样本期间内的平均精度达到了95.57%,且高于各种单项预测方法,说明组合预测模型预测最优。在误差度量方面,我们选择了平均相对误差和均方百分比误差这两种误差表现形式,由表2可知,在三种单项预测模型中支持向量机模型的误差最高,次高是BP神经网络模型,再是随机森林模型,误差最低的是组合预测模型,将各预测方法的误差归一化(各单项预测方法的预测误差与最大预测误差的占比),发现组合预测模型的平均相对误差只相当于最大平均相对误差的43.05%,均方百分比误差只相当于最大均方百分比误差的49.51%,说明文中的组合预测模型能够有效降低预测误差,体现了组合预测模型的优越性。
4 总结
本文首先基于机器学习算法,分别构建了随机森林、支持向量机和BP神经网络三个单项预测评价模型,发现随机森林预测性能最优,表明了随机森林的学习效率高,可以被运用于日常的单项模型预测中,其次BP神经网络模型的预测效果也较优,但我们要积极结合理论与实践确定最优的网络结构选择。对于支持向量机预测模型,只有确定了最优的核函数,才能提高模型的预测精度。由于单一预测方法都有自身的优势与不足,而且对数据信息掌握不够透彻会影响预测结果,于是基于三种单项预测方法,构建了诱导有序加权算术平均(IOWA)组合预测模型,克服了单一预测方法的预测权重在时序上不变的限制,将三个预测模型的优势结合起来,大幅度提高了预测精度,能够有效的预测消费新变化,为社会消费品零售总额提供了一种预测新思路,对于正确把握宏观经济发展新形势,推动经济高质量增长极具现实意义。
参考文献:
[1]McClloch W S, pitts W. A logical calculus of the ideas immanentin nervous activity [J]. The Bulletin of Mathematical Biophysics,1943, 5(4):115-133.
[2]Rumelhart D E, Hinton G E, Williams R J. Learning internal representations by error propagation [J]. Nature, 1986,323(99):533-536.
[3]BREIMAN L. Random Forests[J]. Machine Learning, 2001,45(1):5-32.
[4]陈华友,李翔,金磊,等.基于相关系数及IOWA算子的区间组合预测方法[J].方法应用,2012,22(6):83-86.
[5]王晓,刘兮,陈华友,等.基于IOWA算子的区间组合预测方法[J].武汉理工大学学报(信息与管理过程版),2010,32(2):221-225.
[6]陈华友,陈启明,李洪岩.一类基于0WA算子的组合预测模型及性质[J].运筹与管理,2006,15(6):34-39.
[7]康义,周一凡,邴焕帅,胡伟,郭健.基于IOWA算子的自主式电力发展水平综合评价[J].中国电力,2016,49(08):110-115.
[8]孙丽,牟海波.基于IOWA组合模型的高速铁路客运量预测研究[J].铁道运输与经济,2018,40(09):74-79.
