基于密集层和注意力机制的快速语义分割
2020-04-20程晓悦赵龙章史家鹏
程晓悦,赵龙章,胡 穹,史家鹏
(南京工业大学 电气工程与控制科学学院,南京 211816)
0 概述
随着图像语义识别技术的发展,语义分割越来越广泛地被应用到日常生活及工业生产中,如地质检测、无人驾驶汽车、面部分割等。研究者将其与深度学习相结合,提出了一系列新的语义分割方法。
文献[1]提出了基于深度学习的全卷积网络(FCN)语义分割方法,文献[2-4]使用该方法对AlexNet、VGG16、GoogleNet等网络进行了修改,并将网络后端的全连接层移除,改用反卷积层进行上采样,并引入跳跃连接改善了上采样的粗糙像素定位。文献[5-6]将池化结果应用到译码过程,在网络中引入了更多的编码信息,发现激活层越多,取得的图像语义分割效果越好。文献[7]将U-Net的编码器的每层结果拼接到译码器中,改善了语义分割结果。文献[8]在扩张卷积网络中提出了“上下文模块”用来聚合多尺度信息,避免了池化导致的信息损失,同时扩大了感受野。文献[9]在RefineNet网络中采用ResNet-101作为网络编码模块,并使用RefineNet block作为译码模块,该模块融合了编码模块的高分辨率特征及前一RefineNet block的抽象特征,所有模块遵循残余连接设计。基于可分离残差的网络,将残差连接与深度可分离卷积相结合,在保持分割精度的同时降低了参数量[10]。文献[11]提出了Large Kernel Matters网络,即使用大卷积核的编码-译码网络架构,将ResNet[12]作为编码器,GCN及反卷积作为译码器。文献[13]在Deeplab v3网络中提出了暗黑(即空洞卷积)空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP),融合了不同尺度的信息。Deeplab v3网络对ASPP模块进行串行部署,将不同膨胀率的空洞卷积结果拼接起来,并使用了批量归一化(BN)。它与扩张卷积网络的不同之处在于,Deeplab v3直接对中间的特征而非最后的特征进行膨胀卷积,在轻量级网络架构中,对前后文进行特征自适应加权融合,有效提高了分割精度[14]。同时,为提高小类物体的预测精度,DeepLab v3基于FCN的模型采用了加权交叉熵损失函数和自适应阈值方法[15]。DeepLab v3 plus[16]网络对DeepLab v3网络进行了扩展,加入了简单而有效的解码器模块来细化分割结果,特别是在对象边界上。此外,这种编码器-解码器结构可以通过无卷积的方法任意控制提取的编码器特征的分辨率,从而在精度和运行时间之间进行权衡。虽然目前已出现了许多图像语义分割网络,但在分割复杂的场景中难以兼顾分割速度与精度。有些网络在精度上满足分割要求,但是网络庞大的参数量与过多的冗余降低了分割速度,还有些网络分割速度较快,但是精度往往难以满足应用要求。
1 网络模块设计
1.1 全卷积神经网络
全卷积神经网络(FCN)将卷积神经网络应用于语义分割,将卷积神经网络最后的全连接层替换成卷积层,对图像进行像素级分类,解决了语义层面上的分割问题,并且可以接受任意大小的输入。将分类网络AlexNet、VGG、GoogleNet进行调整,去掉网络中的全连接层,使其变为FCN,并定义了skip结构,该结构将深层、粗糙层的语义信息与浅层、精细层的外观信息相结合,进行准确详细的分割[1]。FCN为后续以卷积神经网络为基础的语义分割模型奠定了重要基础。
1.2 分组卷积
传统分割网络难以兼顾速度与精度。例如,Deeplab网络在数据集Cityscapes上的分割精度MIOU为63.1%,用时为400 ms,速度远未达到实时分割的要求。ENet[17]分割网络用时仅13 ms,但分割精度MIOU只有58.3%。本文的分组卷积将传统卷积的通道分组[18],如传统卷积通道数为6,卷积核为7×7,则复杂度为6×7×7×6=1 764,而分组卷积的复杂度为3×(2×7×7×2)=588,将复杂度降低了2/3,并且没有特征损失。由此可见,相比传统网络,分组卷积有效降低了参数复杂度,同时大幅提高了分割速度,可实现实时分割,如图1所示。

图1 传统卷积与分组卷积示意图
图2为本文特征提取网络的初级网络结构,在1×1和3×3卷积处将原来的常规卷积替换为分组卷积。在网络中,输入通道分组为N,那么卷积核也需要分为N组,每组卷积核只与对应的特征映射做卷积,得到输出。

图2 初级网络结构示意图
1.3 密集层
语义分割网络的性能提升主要依赖于网络深度的增加,即增加特征提取网络的层数,但这种做法在小幅提升精度的同时,却延长了分割时间。本文特征提取网络受到GoogleNet启发,将一路网络传播改为两路传播[19]。为了提升分割效果,网络需要获得多尺度信息,因此网络的卷积核大小也设置为两种。密集层分为两路:一路为获得小尺度目标,使用一个3×3卷积;另一路为获得大尺度目标,采用两个3×3卷积,通道数为K。密集层结构如图3所示。

图3 密集层结构示意图
结合1.2节分组卷积,得到网络结构,如图4所示。

图4 加入密集层的网络结构
1.4 注意力模块
为了提高网络的分割速度,本文使用轻量级网络作为特征提取网络,但是在精度上有一定损失。为了减少精度损失,在本文网络中加入了注意力模块[20]。注意力特征有助于增强模型的特征表达[21],综合不同信息,提高模型的理解能力[22]。这与人类视觉的注意力机制类似。人类视觉注意力机制分为两种:自下而上的基于数据驱动的注意力机制,自上而下的基于任务驱动的目标注意力机制。两种机制都可以从大量的数据中学习到任务需要的部分。本文采用的是自下而上的基于数据驱动的注意力机制,注意力模块从特征通道之间的关系出发,考虑特征通道间的相互依赖因素,通过网络的自学习,有效抑制对当前分割作用影响不大的特征,增强有益特征的权重[23]。注意力模块首先对每个通道的特征映射进行全局平均池化,得到1×1×K的向量,再进行两次FC层转换,为抑制模型复杂度分别在两次FC层转换间进行降维和升维,类似于一个“瓶颈”,并使用Sigmoid与ReLU激活函数,添加了注意力模块的特征提取网络如图5所示。

图5 加入注意力模块的特征提取网络
在注意力模块中,首先使用全局平均池化,将从密集层输出的数据由W×H×K收缩为1×1×K,具体公式如下:
在“互联网+”新时代,高校固定资产管理工作正在实现与时俱进的自我突破,正如本文所言,它已经在积极主动融入“互联网+功能包图”模式以及“互联网+功能数据”统计管理模式,希望以此来提高高校在新时代的固定资产的管理与统计水平,迎合当前教育改革机制发展变化,实现长期稳定办校。
(1)
其中,Fsq表示全局平均池化函数。
接下来对网络进行两次FC操作,C代表降维系数,可以根据具体网络调整,本文实验C=16时获得最佳性能,公式如下。
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(2)
其中,σ、δ分别代表Sigmoid、ReLU激活函数。
然后进行scale操作,基于通道数不变,将数据变为W×H×K。
Xc=Fscale(uc,sc)=sc·uc
(3)
网络在加入注意力模块前,对于batch为256、224×224的输入图片,一次前向传播需要42 ms,加入注意力模块后,则需要47 ms,通过降维-升维降低复杂度后仍有时间增加,但相比分割精度的提升而言可以忽略。
最后,网络的每层通过跳跃连接[24]相连,本文跳跃连接有两点和DenesNet不同。一是DenesNet只在下采样之间的block中有连接,本文则所有层中都存在连接;二是在池化方式上,本文采用了空洞空间金字塔池化(ASPP),ASPP提供了多尺度信息的模型,是在空间金字塔池化(SPP)的基础上添加了具有不同扩张率的空洞卷积,用来捕获大范围语境,通过全局平均池化(GAP)结合图像特征增加全局语境。共包括4个并行操作、一个1×1的卷积和3个3×3的卷积,并加入了批量归一化。本文网络跳跃连接示意图如图6所示。
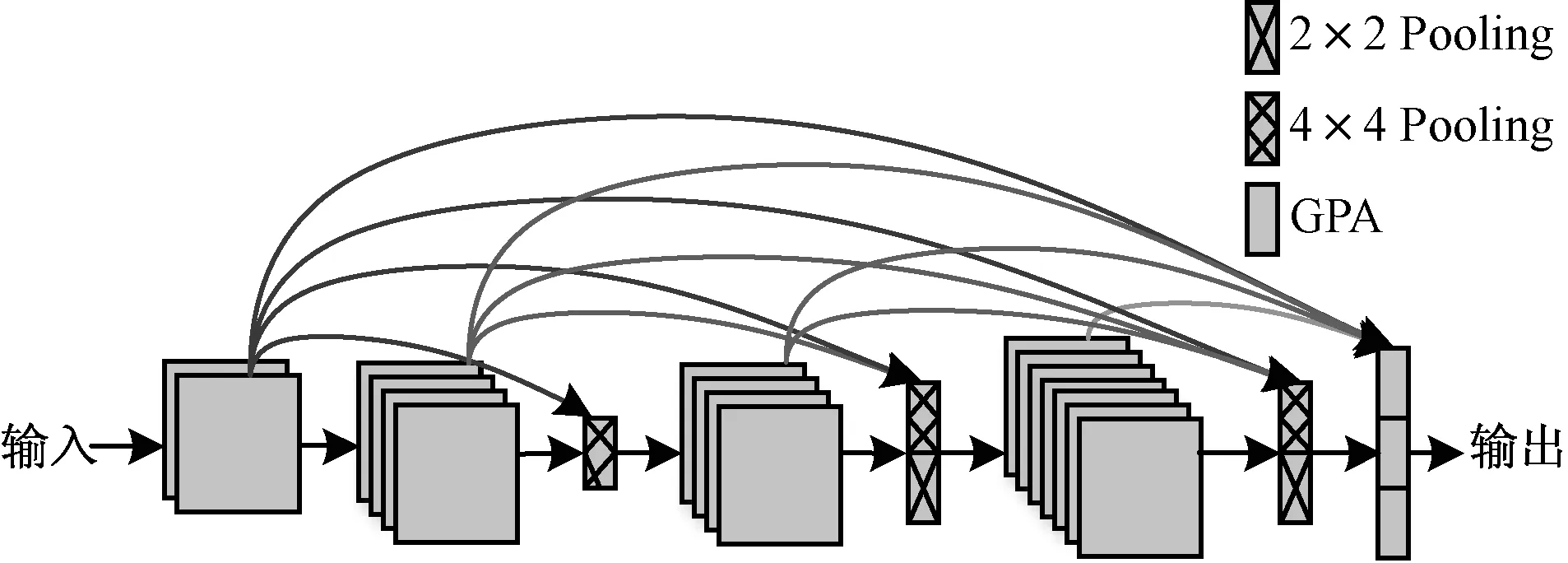
图6 本文网络跳跃连接示意图
2 实验结果与分析
本文实验数据采用图像分割的基准测试数据集Cityscapes[25]和ADE20K[26]。Cityscapes数据集由奔驰公司发布,包括25 000张图像,其中5 000张精细标注,20 000张粗略标注,包含50个城市的背景、街景、人、车辆、地面、交通标志等30类物体的标注。ADE20K是MIT推出的可以用于分割、识别、场景感知及语义理解的数据集。有较为丰富的场景种类和详细的标记,共含有150个对象和类别。其中20 210张图片用于训练,2 000张图片用于验证,测试集有3 000张图片。数据库部分图片如图7所示。

图7 数据库部分图片
2.1 评价标准
pii表示分割正确的数量(称为真正);pij表示本来像素是属于i类,但是被分割为j类的数量(称为假正);pji表示本来像素是属于j类,但是被分割为i类的数量(称为假负)。共有k+1个类别(包括k类及一个空类或背景类)。
像素精度(PA)是语义分割最简单的精确度度量,表示标记正确的像素占总像素的比例。
(4)
均像素精度(MPA)是PA的简单提升,计算在每个类内被正确分割的像素比例,再求所有类别的平均值。
(5)
平均像素交并比(MIOU)是语义分割技术的度量标准,计算两集合的交集与并集之比。在每个像素类别内计算IOU,然后再计算平均值。
(6)
直观理解MIOU的评定方式如图8所示,图中深色部分代表真实像素值,浅色区域代表分割像素值,交集处代表像素分割正确的部分。

图8 MIOU评定方式直观图
鉴于MIOU的简洁、代表性强,因此本文研究性能评定根据MIOU来衡量。
2.2 结果分析
本文所有实验在TensorFlow1.9框架下搭建,使用cuDNN7.5内核计算,工作站配置Intel®Core TM i7-6800K CPU@3.4 GHz,GTX 1080Ti显卡,内存128 GB,8张GTX1070显卡。训练时batch大小为256,设置初始学习率为0.01,学习率衰减为10-6,使用Nesterov动量[27]。初始化方法为VarianceScaling[28],能根据权值尺寸调整规模,激活函数使用softplus。图9为在Cityscapes数据集上的分割效果图。

图9 在Cityscapes数据集上的测试结果
确定本文模型的过程如下:首先在18层特征提取网络中加入密集层,发现网络分割性能相比原始18层网络有一定提升,继而又加入了注意力模块,得到了较好的分割效果,但速度还不能满足实时要求。为了获得更好的分割性能,并得到较快的分割速度,逐层添加特征提取网络,观察特征提取网络层数对精度和速度的影响,最终确定采用5层特征提取网络结构,能将分割性能与速度均维持在较高水平。在实验中首先用数据集Cityscapes进行分割,得到如表1所示结果,为了验证表1结果的有效性,在ADE20K数据集上再次进行验证,发现表1中5层特征提取网络的结果较佳,于是最终确定了本文网络模型。

表1 本文实验网络层数与分割性能
在分割精度上,选取多类物体的分割精度结果进行对比,如图10所示,实线为本文方法。其对建筑物、柱子、植被、人、小汽车、火车的分割精度分别达到了93.5%、67.9%、93.9%、87.3%、96.2%、86.5%,明显高于其他分割网络。为了公平进行实验对比,在相同的实验配置下,使用不同的分割模型对Cityscapes数据集及ADE20K数据集进行分割,得到的对比数据见表2与表3。表2为在Cityscapes数据集下的分割结果,可以看到本文网络的分割精度达到81.5%,优于其他网络,分割时间为47 ms,仅次于ENet的13 ms,但分割精度远高于ENet。表3为在ADE20K数据集下分割结果的数据对比,可以看到,在相同的实验环境下,本文网络将输入图片剪裁为576×576,相比其他模型在分割速度上有很大优势,在分割精度上也不低于其他网络。

图10 各种网络分割精确度对比Fig.10 Comparison of segmentation accuracy of variousnetworks

表2 各方法在Cityscapes数据集下精度与速度对比
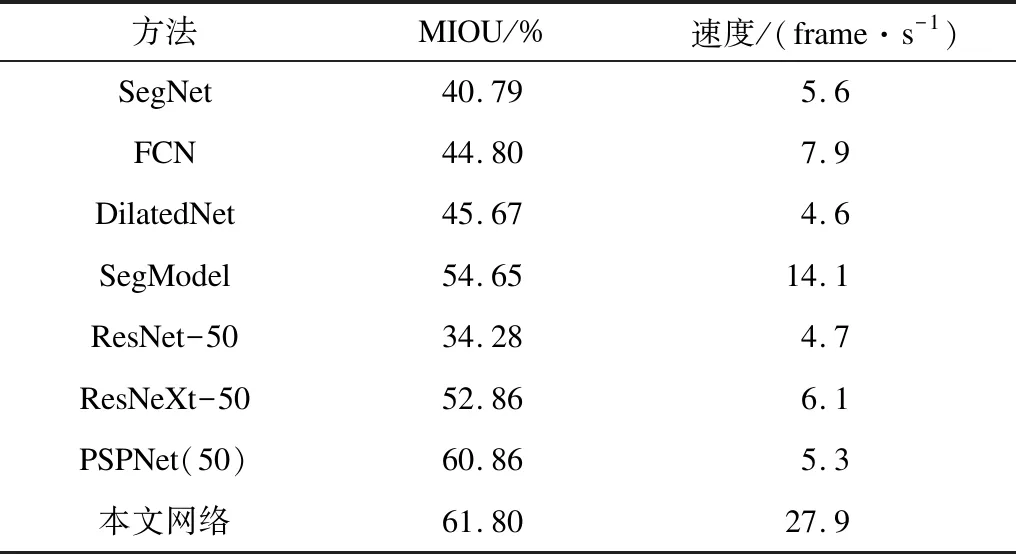
表3 ADE20K数据集下分割精度与速度对比
图11为在数据集ADE20K上,采用ResNet-50、ResNeXt-50、PSPNet(50)及本文方法进行的实验对比结果,可以看到本文模型相比其他3种模型,训练损失较少。

图11 不同方法的训练损失
3 结束语
本文提出一种基于密集层和注意力机制的网络层,并作为快速语义分割的特征提取网络。通过分组卷积减少网络参数,并加入注意力模块,在保证不损失分割精度的前提下,大幅提高网络的分割速度,满足快速语义分割的应用要求。今后将尝试在不同尺度上进行语义分割,提高对细小物体的分割精度。
