端到端的深度卷积神经网络语音识别
2020-04-19刘娟宏黄鹤宇
刘娟宏 胡 彧 黄鹤宇
(太原理工大学物理与光电工程学院 山西 晋中 030600)
0 引 言
随着深度学习(Deep Learning,DL)的发展,浅层的隐马尔科夫-高斯混合模型(Hidden Markov Model-Gaussian Mixture Model,HMM-GMM)无法很好地处理海量的语音数据,性能受到显著影响,识别精度已经不能满足人们的要求[1]。深度神经网络(Deep Neural Networks,DNN)[2]和HMM结合形成DNN-HMM,能够进一步加强语音帧与帧之间的联系,在识别过程中取得不错的效果。但是DNN受限于网络层数,过多的网络层数反而会降低识别效果。2014年,IBM的沃森研究中心Sainath通过实验证明,CNN相比于DNN具有更强的适应能力。
CNN具有数据平移不变性,能够使网络复杂程度降低,更便于训练。CNN被应用于不同的语音识别任务之中。例如,Cai等[3]引入maxout激活函数;梁玉龙等[4]提出将maxout和dropout算法应用在CNN中,均取得不错的识别效果。CNN结构的改进和优化也受到研究人员的关注[5-6]。
随着深度卷积神经网络(Deep Convolution Neural Network,DCNN)的发展,残差网络(ResNet)得以提出并在图像处理领域获得巨大成功[7-8]。残差网络结构可以避免网络层数加深导致的梯度爆炸现象。但是在语音识别领域,对残差网络的研究并不多见。Graves等[9]提出CTC结构,并将其与神经网络相结合。目前,CTC更多的被应用在RNN以及LSTM[10-12]网络中。但是RNN的计算代价比较高,会出现难以训练的情况。
因此,本文将CTC应用在卷积神经网络中,构建端到端卷积神经网络(CTC-CNN)模型。此外,引入残差块结构,进一步构建一种新的端到端深度卷积神经网络(CTC-DCNN)模型。通过maxout函数对该模型进行优化,进一步提高CTC-DCNN模型在语音中的识别准确率。在TIMIT和Thchs-30数据库下,验证得到本文提出的CTC-DCNN模型能够获得更低的词错率。
1 端到端卷积神经网络模型
1.1 卷积神经网络模型
CNN是第一个真正的多层神经网络结构学习的算法。它由输入层、卷积层、池化层、全连接层以及输出层构成[13-14]。
CNN卷积层具有权值共享、局部连接的特性。假设使用Wa(i)c(j)代表输入第a个特征面上的第i个神经元,输出第c个特征面上的第j个神经元之间的连接权值,则有:
Wa(i)c(j)=Wa(i+1)c(j+1)=Wa(i+2)c(j+2)
(1)
CNN中,每一卷积层的输出特征面唯一对应池化层的一个输出特征面。常用的激活函数为Sigmoid函数。通过池化操作,进一步提取语音特征。常用的池化方法有均值池化和最大池化。经过卷积池化,得到的特征进入全连接层。全连接层内的每一个神经元都与之前层每一个神经元相连,全连接层可以接收到之前层所有的局部信息。
CNN的优势之一在于能够通过权值共享有效减少模型的复杂程度,使得模型更容易被训练。
1.2 端到端卷积神经网络结构
1.2.1链接时序分类技术
在语音识别过程中,语音在训练时产生一个训练的真实值,与语音模型中的预测值比对。输出层中损失函数(Loss function)就是用来估计预测值和真实值之间的不一致的程度。损失函数代表着所建立模型的鲁棒性能,损失函数越小,模型的鲁棒性能越好。
CTC引入了空节点(blank),不需要完全对齐语音帧。将CTC应用在本文语音识别系统中,作为softmax层的目标函数,CTC对输入序列和输出的目标序列之间的似然度进行优化。
CTC采用最大似然函数,公式如下:
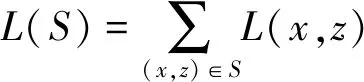
(2)
式中:
L(x,z)=-lnp(z|x)
(3)
设:
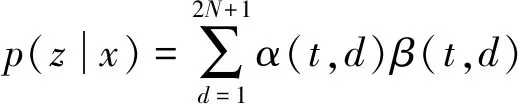
(4)
因此,可以定义CTC损失函数为:
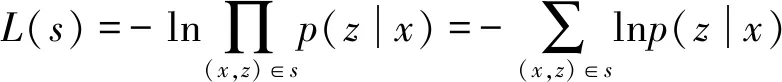
(5)
式中:p(z|x)代表给定输入x,输出序列z的概率;s为训练集。当给定输入之后,CTC的作用就是从中找到概率最大的输出序列。
1.2.2CTC-CNN模型
端到端结构,本质上对语音序列进行分类。CTC作为端到端结构的一种方法,可以解决语音在识别过程中序列不对齐的情况。
图1为CTC-CNN模型结构图。输入特征通过卷积层提取语音特征;池化层均采用最大池化的方法;Softmax层采用CTC损失函数。

图1 CTC-CNN模型
2 端到端深度卷积神经网络模型
CNN的卷积层和池化层交替连接,容易导致训练规模较大,不能够进行较深层的神经网络训练。而且卷积层和全连接层均有卷积结构,因此这两层的激活函数直接决定了整个CNN网络的性能。目前,卷积层常用Sigmoid激活函数,全连接层采用ReLU激活函数。但是,Sigmoid收敛速度不够快,存在梯度消失的现象以及过拟合的现象。ReLU函数会使某些参数得不到激活,产生死机现象。因此,本文提出将残差结构引入前文构建的CTC-CNN中,设计一种新的6层的CTC-DCNN模型,并通过maxout进行优化,改善模型中的梯度消失现象,提高识别准确率。
2.1 CTC-DCNN模型
本文提出了一个新的6层的CTC-DCNN模型作为语音识别系统的声学模型,如图2所示。

图2 CTC-DCNN模型
2.2 maxout优化CTC-DCNN
2.2.1maxout激活函数
maxout是一种简单的前馈神经结构,采用的是maxout激活函数,它是一种非线性变换函数:
(6)

(7)
式中:tT是输入的特征向量;W…im是一个关于输入和输出节点的三维矩阵;bim是偏置量。
(8)
式(8)为maxout神经元的梯度。maxout函数具有很强的拟合能力,当一个神经元得到它的若干个激活量时,maxout函数下取其中最大输出值的激活量为1,其余设置为0,也就是说,maxout给了一个恒定的梯度。
maxout函数不仅能够学习到隐藏单元彼此之间的相关性,还能够学习到隐藏单元内的激活函数。此外,在局部域内,maxout函数几乎都是线性的,还具有良好的鲁棒性。因此,将maxout应用在CNN整个神经网络中作为激活函数,可以有效改善神经网络中存在的梯度消失现象,从而提高语音的识别效果。
2.2.2maxout优化残差结构
残差块结构中,通过shortcut连接,能够将原始的输入值直接传输到后面的层,减少过深的卷积层数带来的训练误差。残差块中,通常采用的激活函数是ReLU函数,本文提出通过maxout函数优化残差网络中,改善原本激活函数可能存在的死机现象,具体改进结构如图3所示。
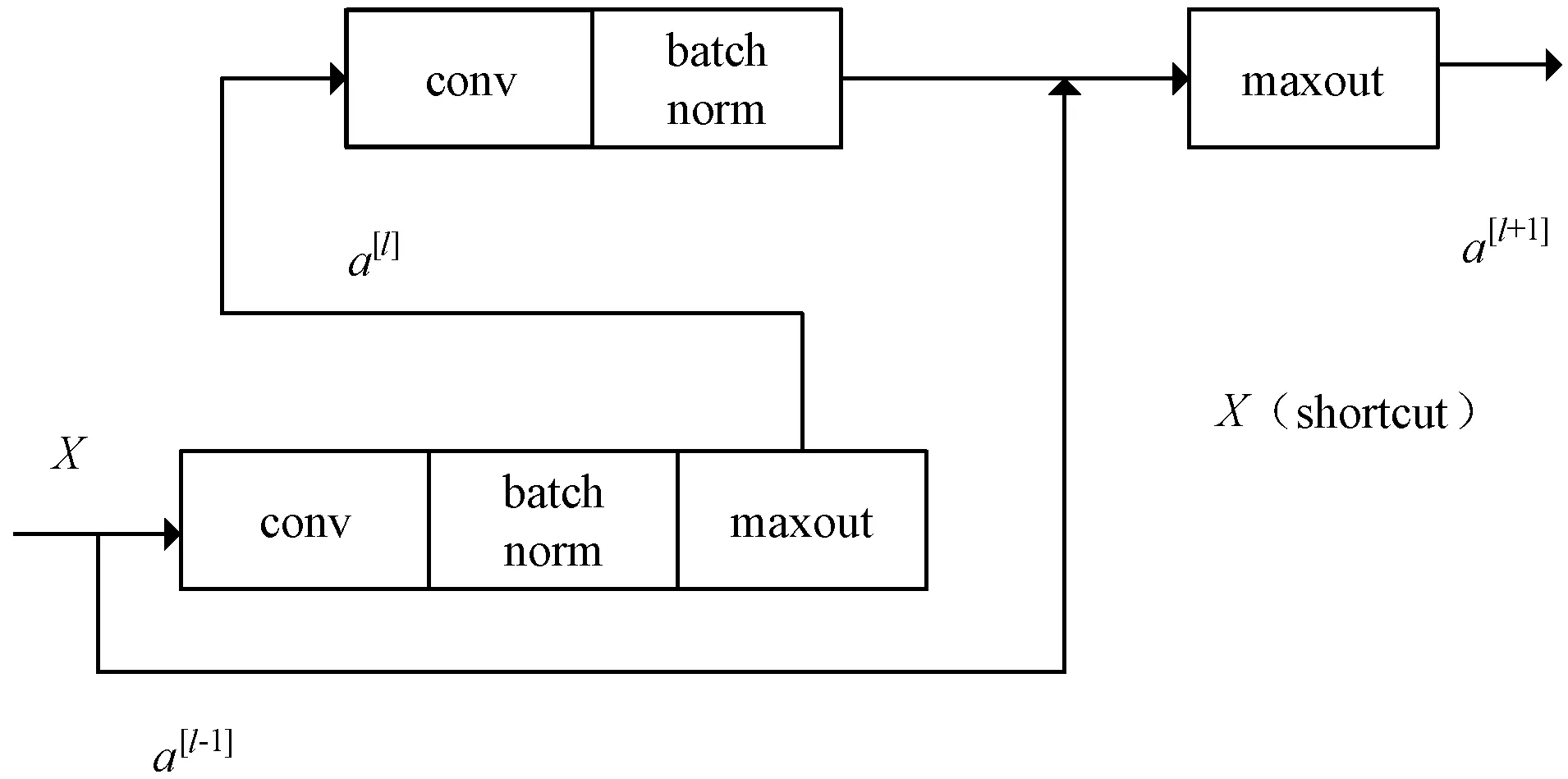
图3 maxout优化残差结构块
其中:X是a[l-1]层的输入,经过卷积和激活函数后输出特征进入a[l]层。这些层的表示如下:
z[l]=W[l]a[l-1]+b[l]
(9)
a[l]=f(z[l])
(10)
z[l+1]=W[l+1]a[l]+b[l+1]
(11)
a[l+1]=f(z[l+1]+a[l-1])
(12)
式中:z[l]、z[l+1]为a[l-1]层和a[l]分别经过卷积加权的特征;W[l]、W[l+1]为该层对应的权重;b[l]、b[l+1]为偏置量;maxout函数用f(x)表示。将本层的加权和输入激活函数,得到本层的输出为a[l]。在残差网络结构中,第二个卷积层在激活函数计算的过程中,将第一层的原始输入和本层的卷积核结果作为maxout的输入,得到a[l+1]为经过残差处理后的特征。
残差块通过添加shortcut,使得输出发生变化,再经过激活函数可以得到最终的输出。残差块的存在,使得构建较深层次的卷积神经网络成为可能。
图4为本文提出的CTC-DCNN语音识别系统。在该模型中,DCNN采用了残差结构,能够减轻训练过程中网络层数较多引起的训练误差。同时,通过maxout对网络进一步优化,改善梯度消失现象。
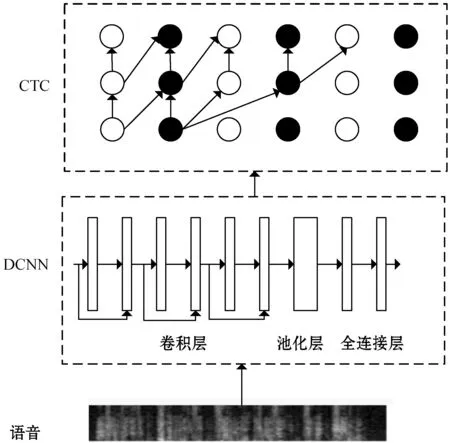
图4 CTC-DCNN识别系统
3 实验结果与分析
3.1 数据集和实验系统搭建
本文选择实验仿真平台为:VMware虚拟机+ubuntu 16.04操作系统+tensorflow+spyder3。Python版本选择2.7和3.5.2两个版本,满足测试过程中对语言版本的要求。
为了验证本文提出的新的CTC-DCNN模型的性能,在英文语料库TIMIT和中文语料库Thchs-30下分别进行实验。
中文语音识别中,选取清华大学30小时中文语音库(Thchs-30)作为语音识别的数据库。Thchs-30数据库中,训练集标注为A、B、C组,每组250句语音,测试集为D组。
英文语音识别系统中,选取TIMIT数据库。TIMIT数据库中462人的语音作为训练集,24人所讲的192条语音作为核心测试集,各个说话人之间无语音重叠,并搭建英文语音识别系统。
在本文识别过程中,通过词错率WER来表征语音识别效果。
3.2 中文语音识别系统设计及实验
3.2.1参数设计
在中文语音识别系统中,首先对中文语音信号处理。相关参数为:语音信号经过预处理和分帧加窗操作,设定帧长为20,帧移为10,帧长不足20的在其后补0。窗函数为汉明窗。进行MFCC特征提取,得到39维语音特征。
本文的声学模型采用CTC-DCNN网络。具体结构为:DCNN采用6层的卷积层后连接池化层,再连接2层的全连接层,最后输出。首先对中文语音信号和特征进行降维,1×1的卷积层,卷积核大小为128,然后经过激活后输入3×3的卷积层,卷积核数目为128。C3层的参数设置为:卷积核大小为1×1,卷积器个数为256,步进设置为1×1。C4层的参数设置为:卷积核大小为3×3,卷积器个数为256,步进设置为1×1。C5层的参数设置为:卷积核大小为1×1,卷积器个数为512。C6层的参数设置为:卷积核大小为3×3,卷积器个数为512,步进设置为1×1。之后输入池化层,池化层采用3×3的最大池化方法。池化之后连接全连接层,为2层,每层有1 024个节点。输出层为CTC损失函数。
本文选择参照的中文语音识别系统采用卷积神经网络声学模型,结构为:2层卷积层后连接池化层,得到的特征经过2层全连接层进入输出层。CNN中,第一层卷积核大小为10×10,步进为1×1。第二层为4×3,卷积核数目为256,步进为1×1。卷积层后连接池化层,采用3×3的最大池化的方法。全连接层设置2层,节点数为1 024个。
本文选择的语言模型为N-gram模型。初始学习速率learning rate=0.001,迭代次数设定为16。
3.2.2识别结果
表1为不同声学模型下中文语音识别系统错误率。可以看出,相同的迭代次数下,CTC-DCNN模型的识别效果要优于CTC-CNN模型和CNN模型。迭代次数为16次时,本文提出的maxout优化后的CTC-DCNN模型的词错率为20.1%,相比于未优化的CTC-DCNN降低了0.7%,比CTC-CNN模型降低3.5%。同时,随着迭代次数的增加,发现语音识别词错率随之降低。实验结果表明,本文提出的CTC-DCNN模型鲁棒性更好。其中:maxout有效缓解了深度卷积神经网络训练过程中存在的梯度消失现象;CTC结构加强了建模过程中语音分布关系,更接近真实情况下的语音识别过程,从而提高语音识别准确率。
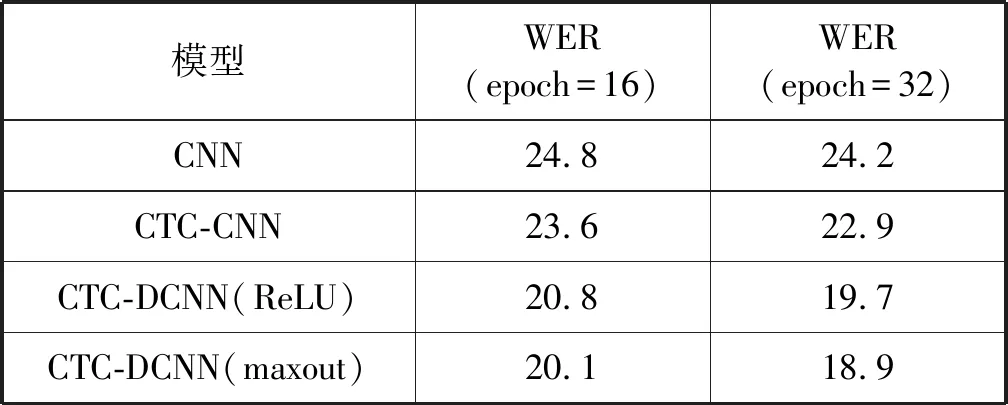
表1 中文语音识别结果 %
3.3 英文语音识别系统设计及实验
3.3.1参数设计
在英文语音识别系统中,将40维的梅尔域滤波带系数作为语音特征输入,同时选取上下文相关的5帧,构成11帧长时串联特征。
选择CNN作为声学模型,其结构参数为:一层卷积层后连接池化层,全连接层最后输出。其中,卷积层卷积核大小为9×9,数目为256。池化层采用最大池化方法,全连接层节点个数为1 024。输出层为softmax层。
3.3.2识别结果
表2为不同声学模型下英文语音识别结果。可以看出,本文提出的CTC-DCNN模型相比其他声学模型,词错率最低,为17.4%。相比于CNN和CTC-CNN模型,准确率提高了6.3%和2.8%。因此,CTC-DCNN模型能够提高语音识别效果。
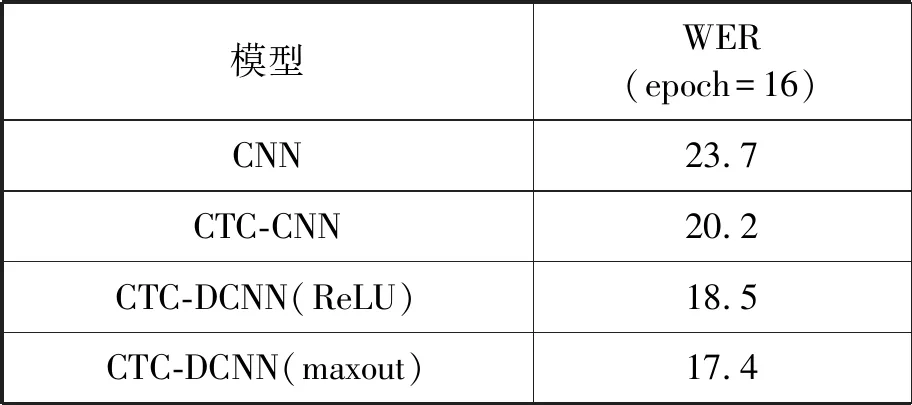
表2 英文语音识别结果 %
对比表1和表2,CTC-DCNN模型不仅在中文语音识别过程中表现良好,在英文语音识别中也有不错的表现。这是因为CNN结构在处理语音信号的过程中,能够克服语音的多变性,将语音信号的时频域当做图像进行处理,有效提高语音识别效果。本文提出的CTC-DCNN模型,兼具CNN和CTC的优势,在不同语言的语音识别过程中,词错率均有所降低。
在Thchs-30中文语音库下,本文将CTC-CNN模型和CTC-DCNN模型在不同的迭代次数下的语音识别结果进行了对比,如图5所示。

图5 不同迭代次数下语音识别结果
4 结 语
本文提出了一种新的CTC-DCNN模型。在语音识别过程中,通过端到端和卷积神经网络构建CTC-CNN模型,并引入残差结构,设计深层的CTC-DCNN模型,通过maxout激活函数对模型进行优化。分别在TIMIT和Thchs-30数据库下进行实验,结果表明本文提出的CTC-DCNN模型能够有效提高语音识别准确率。
