基于信息增益和粗糙集的入侵检测方法
2020-04-18任学臻
任学臻 张 永
(辽宁师范大学计算机与信息技术学院 辽宁 大连 116081)
0 引 言
随着网络的迅速发展,网络环境都很依赖网络信息的安全性。如果网络环境不安全,会导致许多问题,诸如隐私泄露,资源盗用等,这将给人们的工作生活带来许多的损失,因此提高互联网的网络信息安全是当务之急,网络入侵检测系统应运而生,它是维护网络信息安全的有效手段。
网络入侵通常分为非法访问信息、修改信息和破坏用户系统[1]。而当下保护计算机使之不受到网络攻击的最安全的方法就是进行网络入侵检测。网络入侵检测分为误用检测和异常检测两种,误用检测对攻击的突变无法较好地识别,只能去检测已知攻击,没有实际应用价值;而异常检测不需要先验知识,虽然检测率略低,但是可以检测到一些全新的或者突变的入侵攻击行为,已成为目前该领域的主要研究方向[2-3]。
此外,入侵检测的数据集太大,这些数据往往是高维的,每个属性和属性之间都有相关性和冗余性。这将对入侵检测的效率产生很大影响,导致精度降低,因此大多数研究工作都对数据进行了预优化。文献[4]提出了一种使用深度神经网络(DNN)的新型入侵检测系统,构建DNN结构的参数用于概率的特征向量训练,再利用深度置信网络(DBN)的无监督预训练来初始化参数,提高了检测的精度。文献[5]提出了一种基于改进量子粒子群算法(IQPSO)和改进差分算法(IDE)相融合的算法,将该算法应用于支持向量机的参数优化,设计了对应网络入侵检测的算法和模型。文献[6]提出了一种适应大样本集的网络入侵检测算法,该算法分成离线和在线两个阶段,离线阶段构建样本集的聚簇索引,在线阶段采用聚簇索引搜索得到最近邻,再利用KNN算法对大样本集分类。文献[7]提出了基于改进的进化神经网络建立的混合入侵检测模型,采用改进的进化神经网络作为检测引擎,弥补了遗传算法中实数编码全局寻优能力差的缺陷,进而提高了神经网络的分类能力。文献[8]介绍了一种使用深度置信网络(DBN)和概率神经网络(PNN)的入侵检测方法,先利用DBN的非线性学习能力将高维数据转化成低维数据,再利用粒子群优化算法优化每层隐藏节点数量,最后使用PNN分类。
本文提出一种信息增益和粗糙集相结合的属性简约算法,并将其应用到入侵检测的特征提取阶段[9]。该算法首先使用信息增益技术对数据进行第一次的简约,简单地删除冗余属性,然后再利用粗糙集理论(Rough Set Theory,RST)从数据中提取分明函数,求得简约后的属性。该方法可以避免生成过多的分明矩阵,这样不仅可以保证各属性相互独立且不会陷入局部最优的情况,更好地避免数据中存在过多的冗余属性,同时可有效减少信息损失,加快收敛速度。
1 模型架构设计
本文设计了一种将信息增益和粗糙集相结合的属性简约算法,并将其应用于基于随机森林的网络入侵检测模型中,可以较好地检测到系统中的每一类恶意入侵行为。该模型采用信息增益算法和粗糙集理论来进行属性简约,最后使用相应分类器进行分类,得出结果,检测模型架构如图1所示。
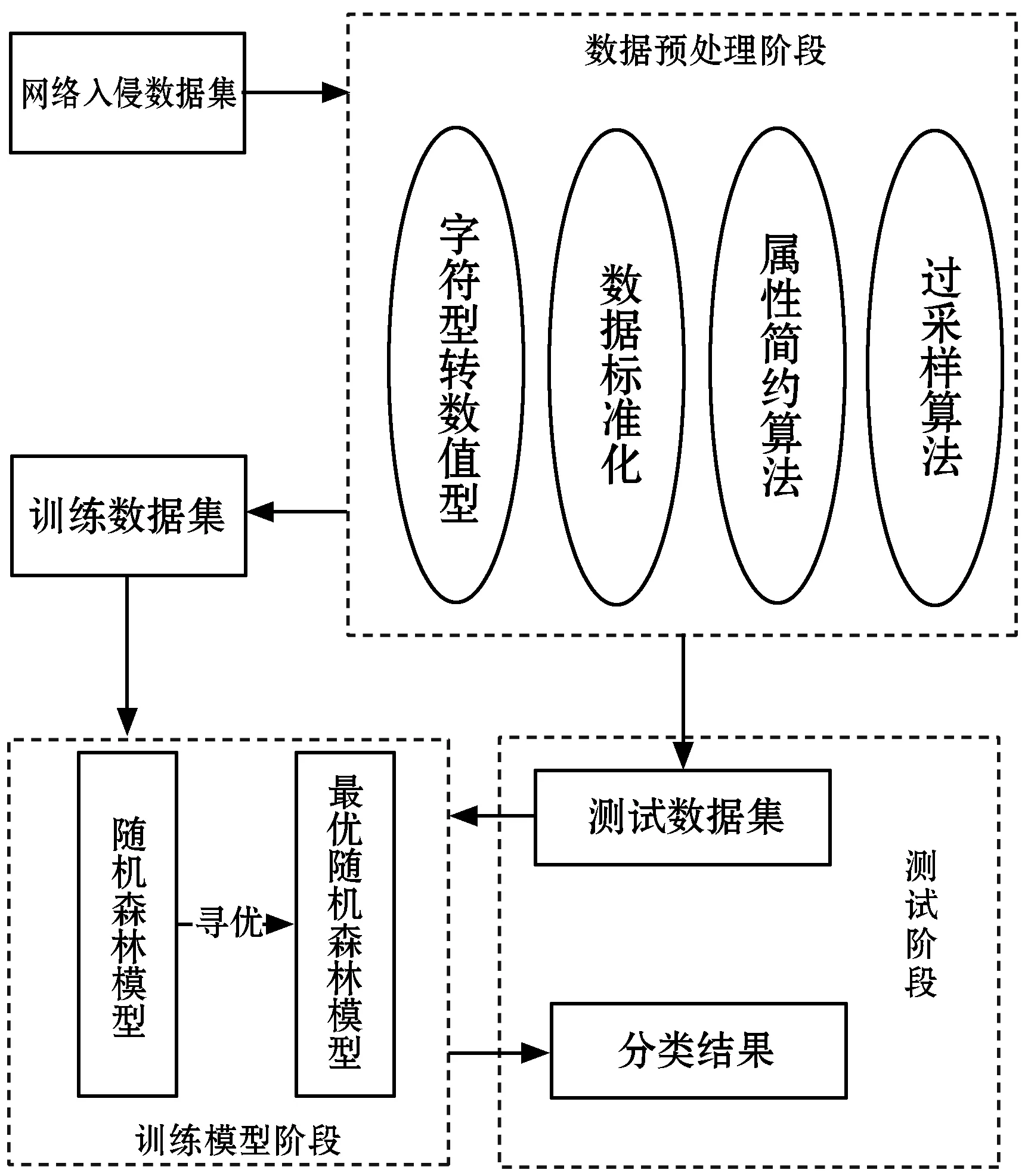
图1 入侵检测系统架构
主要模块如下:
(1) 预处理模块。因为收集到的原始数据过于复杂,所以要对原始数据进行数字化和离散化的处理,然后再将离散化后的数据传输到属性简约模块。离散化主要是因为粗糙集不能处理连续的数据。本文采用数据归一化来实现对数据的预处理,使数据和数据之间不会存在较大的差值,使所有数据的均值更接近于0。
(2) 属性简约模块。信息增益能通过统计每个属性在每个类别中出现的个数,计算每个属性对每个类别的信息增益,简单地筛选掉一些冗余属性。粗糙集理论能处理不精确、非完整的信息,可以对大量、无规律的数据进行分析、推理,并能在过程中挖掘出潜在规则,对属性进行简约,得到最终的数据集。两者结合后获取最优的数据子集。
(3) 分析检测模块。分析检测过程分为训练阶段和测试阶段。在训练阶段,对随机森林分类器进行参数寻优,找到最优参数,得到效率更高的分类器。在测试阶段,对数据进行检测,得到结果。
2 算法设计
2.1 熵与信息增益
熵(Entropy)是信息论中的一个重要概念。熵代表能量在空间中的分布是否均匀,能量分布越不均匀,熵就越小,反之熵越大。Shannon最早将熵应用到信息处理研究中,提出了"信息熵”的概念。信息熵其实就是将信息量化,是衡量一个随机变量取值的不确定性程度[10]。
信息增益(Information Gain,IG)是信息论中的一个重要概念,被广泛应用于机器学习领域。对于数据分类来说,信息增益是通过统计每个属性在各个类别中是否出现的数量来计算该属性对每个类别的信息增益。
令向量X和Y分别表示样本属性(X1,X2,…,Xm)以及类别属性(Y1,Y2,…,Yn)。对于给定的属性X与相关联的类别属性Y之间的信息增益。相关公式如下:
IG(Y,X)=H(Y)-H(Y|X)
(1)
(2)
(3)
式中:IG(Y,X)表示属性X对类别Y的信息增益,H(Y)是Y的熵,H(Y|X)是条件熵。在本实验中X为数据的特征项,而Y值表示类别。
2.2 粗糙集理论
粗糙集理论是Pawlak[11]最早提出的,这是一种应用在数学领域的方法。其具有强大的数据分析及推理能力,可以用来删除冗余属性,因此也广泛应用于数据简约、决策规则或知识提取等问题上。属性约简是粗糙集理论的核心问题之一。粗糙集的描述方法有两种:一种是代数描述,一种是信息描述。粗糙集的代数描述是通过引入上近似集和下近似集来进行的[12]。
粗糙集的信息描述则是假定一个信息系统,可表示为一个四元组S=(U,A,V,f)。设U为论域,代表元素的非空有限集合;A为属性集合,A=(C∪D),C称为条件属性集,D称为决策属性集;V=∪Va(a∈A)是信息系统中所有属性值的集合,Va则是属性a的值域;f:U×A→V是一个函数,它为每个元素的每个属性进行赋值,即∀a∈A,x∈U,f(x,a)∈Va。
2.3 IG和RST相结合的属性简约方法
网络入侵检测数据过于庞大,其中冗余属性过多会对分类产生影响,会耗费大量的时间和精力,不仅影响准确性,还会影响分类的有效性。而且,在使用粗糙集对数据进行属性简约时会产生分明矩阵,这必然会造成时间和空间上大量的开销。因此,本文提出了信息增益和粗糙集相结合的属性简约算法,可以减少检测系统时间复杂度,提高检测效率。首先,通过信息增益技术,先将属性中重要性较小的部分属性删除,即先求出网络入侵数据中各个属性的信息增益,此时需要设置一个阈值,将每一个属性所求出的信息增益与阈值相比较,如果其信息增益大于最先设定的阈值,则保留该属性。这里使用信息增益对入侵数据的属性进行相关分析,可减小属性简约的复杂度。利用粗糙集理论进行特征选择时,中间环节会产生分明矩阵,这会造成时间和空间上的大量开销。
在本文的算法中,信息增益先对数据集进行特征提取,构造属性的分明函数,中间没有矩阵的生成,也避免了数组元素的存取,这样就会节省很多时间和空间,提高了算法的效率。在该算法进行属性简约的过程中,首先计算网络入侵数据集中每个属性的信息增益,设置阈值T,如果属性得到的信息增益大于阈值T,则保留该属性,否则删除该属性。从而获取删除后的新的数据子集,然后再提取分明函数f(x)=(1,2,3,…,n),最后求得Λf(x)最小析取范式,得到属性简约。本文提出的属性简约算法描述如算法1所示。
算法1IG-RST属性简约
输入:入侵检测数据集S=(U,A,V,f),其中A=C∪D,C和D分别为条件属性集和决策属性集,信息增益阈值T。
输出:数据集S=(U,A,V,f)的属性约简f′。
1.Pro=C;
//这里C是条件属性集
2. For eacht∈Pro
计算条件属性t的信息增益IG(t)
3. 把t∈C按IG(t)值从小到大排序,并记为{ti};
//属性个数为n,i=1,2,…,n
4. Fori←1 ton
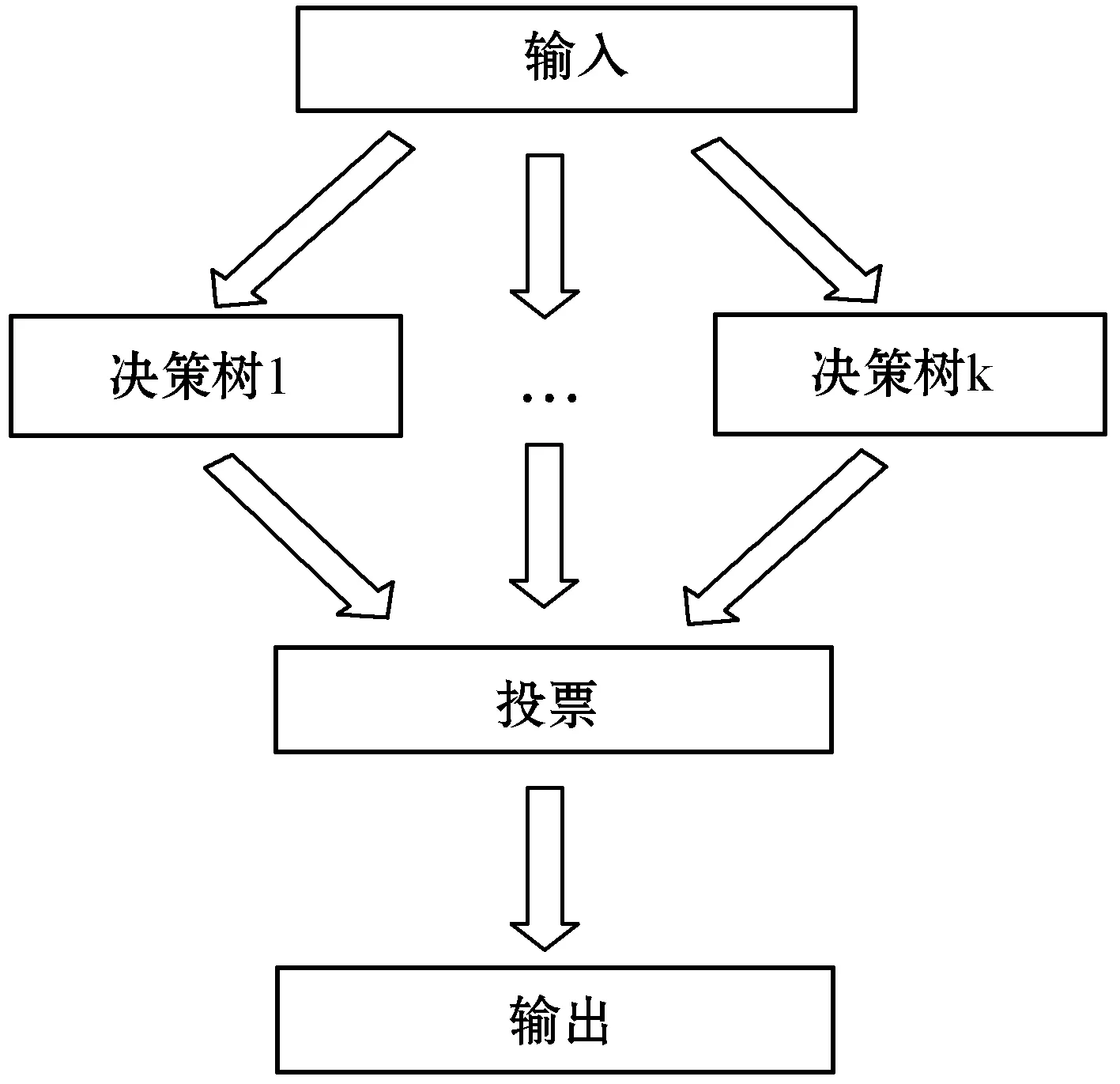
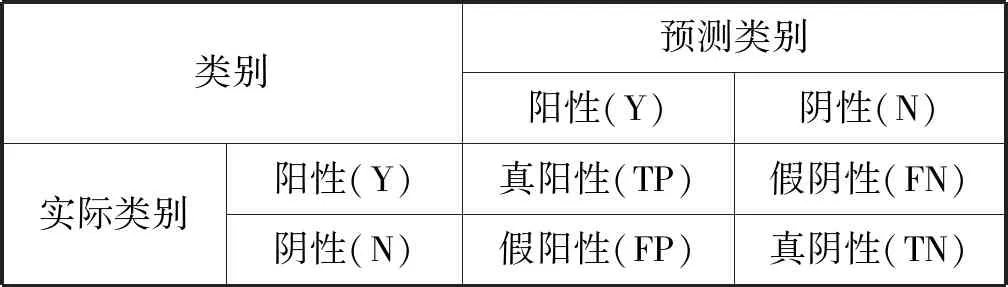
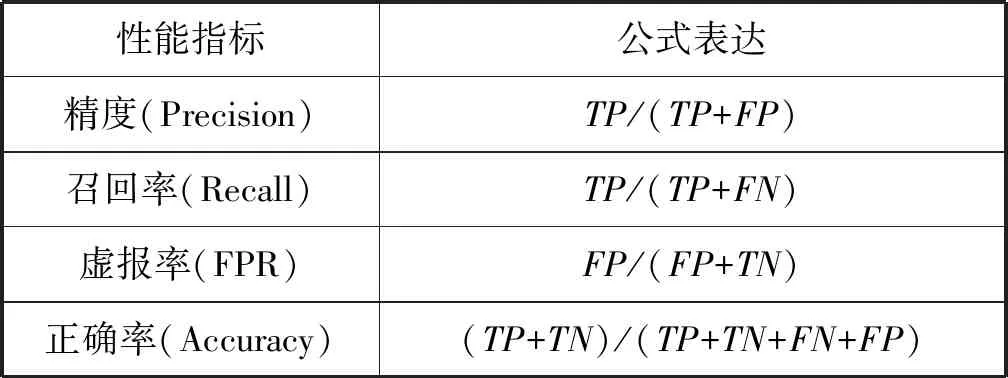
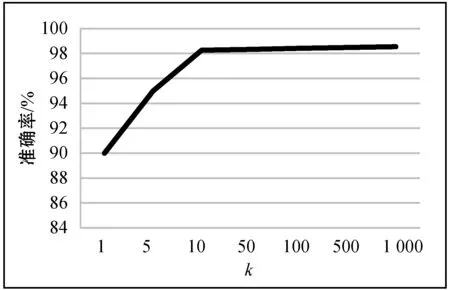
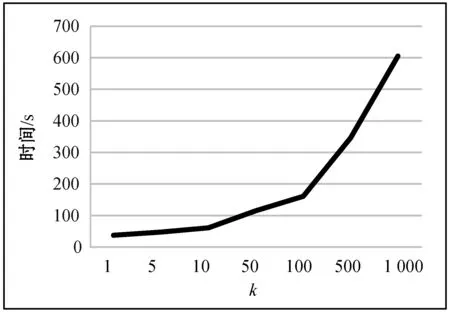
5. IfIG(ti) 6.Pro←Pro-{ti}; //Pro中为信息增益处理后留下的属性集 7. End If 8. End For 9. 从Pro中提取分明函数f(k); //k为对象个数,k=1,2,…,m 10.f′=Λf(k); 11. 输出f′ //f′为该决策表的属性约简 随机森林[13]是由Leo Breiman提出的基于决策树的一种集成学习算法,因不像别的集成由多种不同分类器构成,其集成的基分类器为决策树,随机森林因此得名。决策树本身就是一种分类器,在各个领域里应用广泛,决策树进行分类时要进行剪枝处理,直到无法剪枝,则就建立好了一个决策树分类器。 随机森林是一个集成学习模型,但它的基分类器都是决策树,如图2所示,当输入网络入侵检测数据时,最终的分类结果是集成学习算法常规投票决定的。其基本原理是对参与分类的每一个决策树分类器进行投票。因此,随机森林分类器就出现了一个参数的设定,就是选择决策树分类器的多少。随机森林在降噪处理上体现出了杰出的性能,异常值处理上具有不错的容忍性,可以对高维数据分类有着较好的延展性和并行性,优于其他集成分类器。 图2 随机森林的算法图解 本实验仿真环境为MATLAB 7.12.0(R2011a),内存为4 GB,处理器为Intel(R)Core(TM) i3-4160 CPU 3.60 GHz,系统为Windows 7。本文实验数据集采用美国Lincoln实验室的KDD CUP 99数据集[14],该数据集包括了网络中的5 209 460条入侵数据,每条数据包括42个属性。数据共分为5大类:Normal,DoS,Porbe,U2R,R2L,其中Normal为正常数据,其他4种为攻击数据。本文仅采用的KDD Cup 99的10%的训练数据集进行实验,其分布以及标识类型如表1所示。 表1 KDDup99的10%入侵检测数据集中的 五大攻击的标识类型及分布 如表1所示,Normal为1类,其余四种攻击类型分别为2、3、4、5类。本文的评价标准为混淆矩阵、精度(Precision)、召回率(Recall)、虚报率(FPR)、准确率(Accuracy),其中混淆矩阵如表2所示,其他性能指标也可以通过混淆矩阵求得,公式详见表3。 表2 混淆矩阵 表3 相关公式 实验先对数据进行离散化处理和归一化处理,然后进行属性简约,最后利用随机森林进行分类检测。经过对随机森林分类器的参数k进行寻优分析,实验结果如图3和图4所示,本文选择k=10为最终实验参数。 图3 不同参数k下的准确率 图4 不同参数k下的随机森林的运行时间 在本文的实验中,先利用信息增益将属性简约,设置阈值T=1.2,获得子集,再利用粗糙集的可分明矩阵对子集进行简约获得最终的子集。子集简约后得到如下12个特征:2,4,6,10,24,25,29,31,35,36,39,40。由于数据集中U2R和R2L数据较少,我们首先将数据分为少数类和多数类,再运用本文提出的算法进行验证。结果表明,属性12、23和32对少数类有一定的影响,因此实验最终采用了15个特征:2,4,6,10,12,23,24,25,29,31,32,35,36,39,40。本实验采用了十则交叉验证的方法对数据集进行10次验证,最后取10次交叉验证的均值,求得最终结果,以保证实验评估的准确性。 首先,将本文提出的方法与传统的随机森林方法进行了实验对比,结果如表4所示。由表4可知,本文提出的模型不仅对于准确率有所提高,而且召回率也有不错的提升,尤其是对于少数类(U2R),召回率从原来的0.649增加到0.976。相对于传统的随机森林方法,本文提出的方法建立模型的时间更短。 表4 性能对比表 续表4 由于本文实验采用的是KDD CUP 99数据集的10%作为训练数据集,少数类U2R占总体仅有0.01%,这可能会导致U2R召回率过低。 为了解决数据集分布不平衡的问题,本文实验使用了SMOTE过采样算法来增加少数类,把少数类提高整数倍。本实验将少数类U2R样本增至9倍,达到468条,此时该数据集分布如表5所示,U2R占总体比例接近0.1%。此时,再次实验表明,本文提出方法在U2R类的召回率达到了97.58%。由此可见,只要少数类所占总数比例稍微提高接近于0.1%时,召回率就会有明显的改善。 表5 改变数据后各类型数据的分布 其次,为了进一步体现本文算法的优越性,我们与文献[15]和文献[16]的实验结果进行了对比,如图5和图6所示。 图5 不同算法的召回率比较 图6 不同算法的准确率比较 由图5和图6可以看出,本文提出算法的召回率和准确率都持平或略优于文献[15]和文献[16]的召回率和准确率。这表明本文方法可以紧跟当前的入侵检测领域研究,也为当前网络入侵检测提供了一个新的方法和思路。 本文利用随机森林分类器构建了一个有效的入侵检测系统。对于原始数据集中冗余过多、数据集类别不平衡等问题进行了改善,实验结果表明本文的方法节约了模型构建所需的时间,数据集中少数类(R2L和U2R)的召回率和精度也得到了较明显的提升。本文只对于静态已知的入侵数据进行了实验,而现实中网络入侵是实时未知的,下一步的研究计划是将本文的方法与其他机器学习技术相结合来开发一个对于实时数据入侵的检测系统,在面对未知的数据流时,能够对未知攻击和流动数据达到自适应,这样就可以有效地应用到当下的网络环境中,来检测出新的攻击类别。2.4 随机森林
3 实验结果与分析






4 结 语
