机器学习算法在反窃电分析中的应用
2020-04-15浩马迅刘安磊贾旭超纪书军骆云娟徐冬冬
王 浩马 迅刘安磊贾旭超纪书军骆云娟徐冬冬
(国网河北省电力有限公司电力科学研究院,石家庄 050021)
随着科学技术的不断发展,利用高科技进行窃电的手段越来越普遍[1],比如强磁窃电、无线干扰窃电、更改电能表编程器窃电等。这些技术手段不但隐蔽性强,而且不容易控制,用户的窃电量大,查处难度非常大。
针对高科技窃电现象,有学者提出采用时域和频域的曲线相似性分析方法,通过判断用户负荷曲线与异常馈线线损曲线之间的相似性来识别窃电行为;有学者提出根据“在一个数据集中,会出现偏离集群中其他数据的数据点,若数据点的偏离程度较大,则怀疑形成这种偏离的原因不属于集群内部因素导致,而是外界干扰因素导致的这种不正常的现象”建立基于距离的离群点检测方法检测电压、电流异常,进而判断用户是否存在窃电行为;有的学者提出通过获取智能电表数据和配电变压器的数据,构建数据模型,进而判断用户是否窃电[2]。上述判断方法,主要根据用户用电数据进行异常判断,判断方式单调,构建的数据特征较少,导致数据挖掘的效率不高,数据价值没有得到充分利用,所以分析效果并不理想。而基于机器学习算法构建反窃电模型,从用户用电数据、计量异常事件以及线损3个角度切入,多方位侦测用户窃电行为,能够有效地提高窃电检测率,对构建基于大数据的反窃电稽查监控系统具有重要的社会和经济意义。
1 模型简介
模型选用随机森林算法是利用多棵树对样本进行训练并预测的一种分类器。其反复二分数据进行分类或回归,计算量大大降低。在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。目前反窃电的特征中多数的特征无共同性,因窃电的形式可能多种,窃电用户的数据不具备一定的共同性,随机森林算法可以根据这些窃电用户的特征以及非窃电用户的特征,在子树中对每一个分裂过程选择部分特征,从所有特征中随机选取一定的特征,之后再在随机选取的特征中选取特征,每棵树重复上述过程,最后投票选择出最正确的分类。此模型可提升反窃电稽查监控系统的多样性,从而提升数据的可利用性和结果预测的正确性,同时防止过拟合。随机森林算法可以在运算量没有显著提高的前提下提高了预测精度,其原理如图1所示。

图1 随机森林算法的原理
随机森林算法是机器学习中的重要算法,在许多领域应用[4]。随机森林模型[5]是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
在决策树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,每个叶结点则对应从根节点到该叶节点所经历的路径所表示对象的值。随机森林由多个决策树构成,每个决策树都表述了一种树型结构,由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试,这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程完成。随机森林分类器将许多决策树结合起来可以提升分类的正确率[6]。具体的决策树与随机森林的算法介绍见参考文献[7]。
2 模型框架
2.1 设计理念
随机森林算法的基本思路是基于历史的用电信息数据,构建特征向量用来表征窃电行为和正常用电行为的差异性,进而训练二分类机器学习模型,基于过去一段时间的用电信息,自动判断用户在该时间段内是否发生了窃电,如图2所示。
2.2 特征选择

图2 随机森林模型算法设计框架
特征所使用的基础表如图3所示。其中历史用电信息,是指用户在一段时间区间内(1个月/季度/年)所产生用电行为信息和用户基本属性信息。具体而言,可以分为三类:时间序列类型信息、事件类信息、静态类信息。其中时序类信息包含了用户每天用电量的时序数据和台区每天线损量的时序数据;事件类信息,主要记录了不同异常类型用电事件的发生时刻信息;静态类信息,指用户的基本信息,例如地址、职业、爱好、性别等。

图3 随机森林模型算法特征
2.2.1 基础表说明
a.日用电量:日冻结有功电能示值、测量点日冻结电能量。
b.日台区线损:台区线损率明细。
c.用电异常事件:电能表的潮流反向、电流不平衡、电压逆相序、电源异常、断相、辅助电源掉电、负荷开关误动拒动、过流、恒定磁场干扰、开表盖、开端钮盖、欠压、全失压、失流、失压、校时、电能事件清零、飞走、倒走等事件。
d.用户基本信息表:用户档案。
2.2.2 主要特征数据提取
根据上述基础表,以窃电手段判别,根据短接偷电、电能表停转、电能表反转、欠电压法窃电,欠电流法窃电、移相法窃电,扩差法窃电、无表法窃电等,可得出异常事件行为记录表记录的信息将是本模型数据权重较大部分,根据此表判断窃电用户的行为,取异常事件发生时间点,以此用户、发生时间,关联出其对应时间的用电量、台区线损,观察其突变度,并取突变度最大值,主要特征如下:
a.异常事件发生次数(对取出的所有异常事件进行计数);
b.异常事件时刻用电突变度(异常事件发生的时间节点所对应的用电量的突变度);
c.异常事件时刻线损突变度(异常事件发生的时间节点所对应的台区线损的突变度);
d.用户用电突变点个数(所有时间下的用电量突变点的计数);
e.用电突变时刻线损突变度(所有时间下的用电量突变点的时间所对应的线损突变度)。
2.2.3 其他特征
根据用户日用电量的均值、方差、异常值、突变点、工作日、休息日用电量等,统计如下信息:时间序列的空值占比、时间序列0值占比、时间序列异常电占比、时间序列中位数、时间序列方差、时间序列标准化中位数(<=>中位数/时间序列最大值)、时间序列标准化方差(<=>方差/时间序列最大值)、突变点个数、突变点跃迁最大值、工作日平均用电量、休息日平均用电量、工作日平均用电比例、休息日平均用电比例、星期用电比例的信息熵。此部分特征为预想可能存在影响该样本是否为窃电用户,因而选用部分。
3 模型训练
模型输入数据部分选择了360天的数据(包含窃电以及非窃电用户),从基础表提取出主要的5个特征,训练数据2W正样本+5W普通窃电用户,交叉验证准确率为80%,随机抽取模型中1个树的过程,如图4所示。
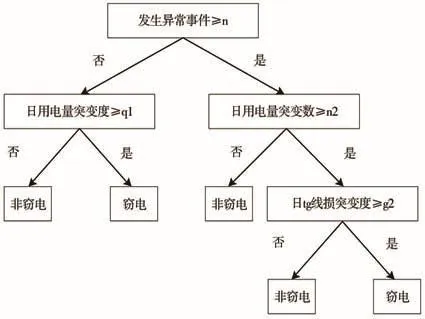
图4 随机森林模型树的预测过程
由100多棵树随机抽取特征,根据训练数据拟合模型后,将新样本输入,执行上述过程,得到结果。
训练模型:第一步将要提取特征,但在进入特征提取前,需要抽取一定比列的训练样本(窃电用户和未发现窃电的用户),此部分需手动设置,提取完训练样本后,数据将交给feature_extract抽取数据,后续将会调用feature_util中的方法对数据进行转换,于feature_combine中整合成用来训练的数据(特征),于model_train_script中训练模型,训练完成后将导出一份训练完后的文件,内含训练完毕的模型,后续预测时将直接调用该文件。
4 模型应用
4.1 模型预测
模型预测嫌疑用户流程如下:
a.提取预测数据;
b.执行preprocess脚本创建临时表;
c.临时表中提取预测数据,通过feature_extract抽取数据(调用feature_util中的方法对数据进行转换);
d.在feature_combine中整合成预测的数据;
e.通过model_predict_util打开训练完成的模型文件;
f.将数据导入模型进行预测,并输出结果;
g.调用output_database导出txt文件;
h.使用hadoop命令将文件导入hive的临时表;
i.住址姓名通过表内ID信息关联,导入Oracle完成。
4.2 模型结果
模型选取沧州某县进行验证测试工作,对部分嫌疑用户的部分特征进行分析,根据输出结果进行嫌疑度排名,选取其中嫌疑度较高的嫌疑用户,将其用电采集数据绘制成图,见图5、图6,其中虚线部分代表用户日用电量,实线部分代表台区日线损。
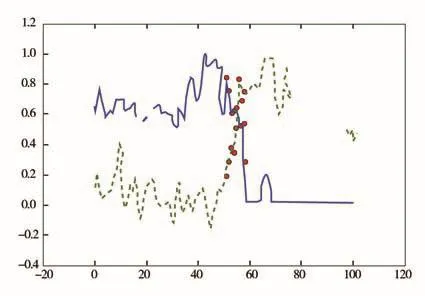
图5 随机森林模型嫌疑用户1台区线损与日用电量相关性
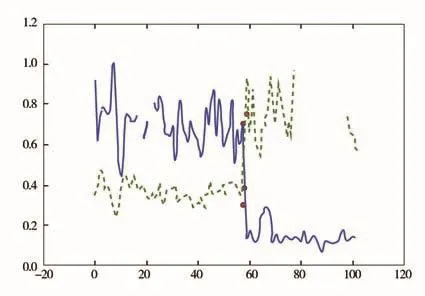
图6 随机森林模型嫌疑用户2台区线损与日用电量相关性
2019年5月,选取图5、图6对应的嫌疑用户,在沧州某县城进行现场稽查工作。最终,确定2户均为窃电用户,其中一户嫌疑用户存在绕越计量窃电,表内计量电流为0 A,实际流入电流为4.97 A,属窃电行为;另外一户嫌疑用户存在动表窃电,使计量不准确,达到窃电目的。
2019年4月起至8月,根据文本模型得出的嫌疑用户,于石家庄、保定、沧州3个地市开展试点工作,共51户派发进行现场核查,查实用户10户,准确率19.6%。
5 结束语
由此可见,随机森林算法可以有效快速地实现窃电嫌疑用户的追踪。随机森林采用了集成算法,本身精度比大多数单个算法要好。在测试集上表现良好,由于2个随机性的引入,使得随机森林不容易陷入过拟合(样本随机,特征随机),训练速度快,可以运用在大规模数据集上。利用机器学习算法对窃电嫌疑用户的追踪,实现了快速有效的反窃电目标,为国家以及社会反窃电领域创造了应用价值。
