基于卷积神经网络的重录语音检测算法
2020-04-15赵雅珺张梦鸽
赵雅珺,王 泳,张梦鸽
(广东技术师范大学,广东 广州 510665)
1 概 述
已有研究证明,语音转换(voice conversion,VC)、语音合成(speech synthesis,SS)及重录语音等欺骗性语音能有效地欺骗说话人识别(automatic speaker recognition,ASV)系统,从而冒充他人登入系统[1-5],对社会安全产生严重威胁。其中,VC及SS需要目标说话人较多的语音信息及特征,再加上现有算法尚未完全成熟,实现成本及难度相对较高;而重录语音利用低廉的录音设备即可轻松获得,且重录语音基本包含目标人物语音的所有特征,因此,相对VC及SS更具威胁。为此,文中对重录语音的检测算法进行研究。
在已有的研究中,针对欺骗性语音安全性的研究主要集中在对VC及SS的检测算法上。Hanilci C等提出了利用语音信号的线性预测残差提取相位特征进行欺骗检测的方法[6];Kamble M等提出了基于能量分离算法的瞬时频率余弦系数,用于检测真假语音[7];Muckenhirn H等通过计算一阶和二阶频谱统计量并将它们提供给分类器来检测攻击[8];Janicki A等提出了利用线性预测(linear prediction)残差信号提取基于音频质量特征的算法[9];Alam J提出了一种基于无限脉冲响应常数q变换特征表示的欺骗检测算法[10]。此外还有运用卷积神经网络的检测算法[11-12],以及运用高斯混合模型(GMM)、动态时间规整(DTW)模型、深度学习等其他方法的检测算法[13-20]。
然而,针对重录语音检测的报道相对较少。文献[21]提出了一种利用频域线性预测框架提取时间包络特征的方法,用于检测重播欺骗攻击。采用高斯混合模型(GMM)和卷积神经网络(CNN)两种建模方法,对真实和伪造数据的GMM进行训练,CNN子系统用来区分真实和重放语音。其融合系统结果的误差率为9.7%,有待提高。文献[22]则应用了线性预测(linear prediction)残差信号。该文指出线性预测残差信号是一种准周期脉冲序列,如果样本被改变,感知到的线性预测残差信号将是不同的,由此,将RMFCC(residual mel frequency cepstral co-efficient)作为线性预测残差信号的代表特征,应用在重播攻击检测系统中。文献[23]利用分层散射分解系数和逆梅尔倒谱系数(IMFCC)分析频谱在低端和高端存在的差异,然后采用2级GMM后端来获得真实语音和重放语音之间的逻辑似然比,再使用HTK[24]和VLfeat工具包[25]对GMM进行训练。文献[26]提出基于卷积神经网络检测重录语音的算法,该算法利用电网频率(ENF)及其谐波组成的组合作为CNN的输入,此算法要求录音设备必须插入电网,以从语音信号中提取ENF;若录音设备自带电源,则无法使用此方法。在涉及安全问题时,更大的可能性是录音设备为自带电源的设备,因此该算法在实际应用中具有明显的局限性。
上述研究尚存在一些问题:传统算法提取特征过程比较复杂;算法均缺乏通用性,对训练和测试环境或设备不同时比较脆弱。这些工作具有启发性,但是也反映出此类语音取证面临的困境,包括在没有标准化的情况下如何设定取证场景、取证场景是否与真实世界相符、录音数量是否不足等问题。为此,文中提出了一种基于新的卷积神经网络且对不同场景鲁棒的重录语音检测算法。网络的数据输入形式采用语音信号经过分帧的时频图,网络结构层包括若干卷积层、池化层,在实验中先分别对不同录制语音设备、距离及环境等重录语音影响因子进行研究分析,然后提出最终的训练方法,并对所有的不同条件下的重录语音进行检测。实验结果表明,在不同的实验条件下,该算法均达到了较高的检测率,因此具有通用性。
2 数据预处理和网络结构
构建的卷积神经网络模型结构如图1所示。网络结构中每一层的参数情况如表1所示。
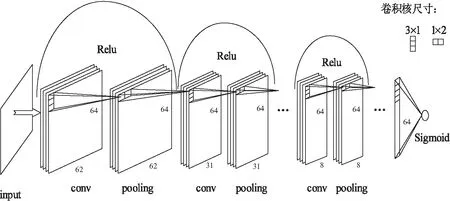
图1 网络结构
表1 网络结构的参数情况

结构层输出尺寸卷积核参数量Conv164×623×1,3296Pooling164×311×2Conv264×313×1,323 072Pooling264×161×2Conv364×163×1,646 144Pooling364×81×2Conv464×83×1,12824 576Pooling464×41×2
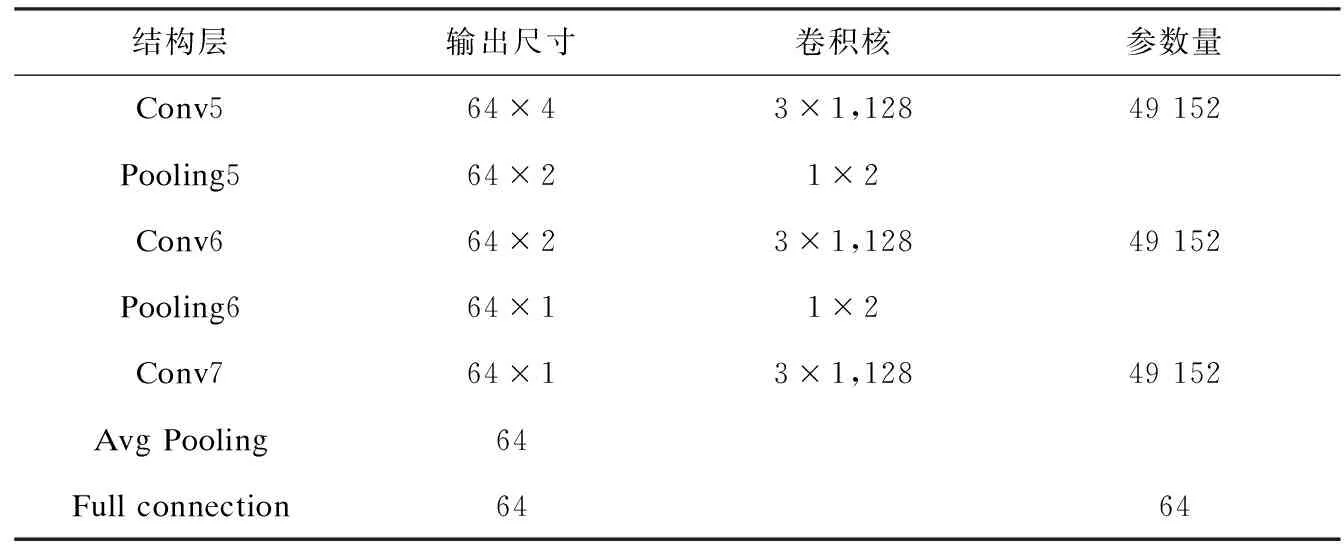
表1 网络结构的参数情况
该模型结构共有7层,每层包含一个卷积层与一个池化层,卷积层的输出通过ReLU函数进行激活,并在层与层之间加入残差连接[27],最后通过全局池化提取最终特征,并通过sigmoid预测检测结果。该结构最大的特点是采用在频率维度卷积及时间维度池化,具体设置为采用3×1卷积核和1×2池化。如此设置一方面最大化降低模型容量,极大减少过拟合的风险,降低模型对数据量的依赖性,另一方面,又与时频图的特征分布特点高度契合,将训练参数分配到更合理的地方,从而用更有效的特征来训练更紧凑的参数。
深度学习模型的性能对数据有极高的依赖性,以原始音频信号作为网络的输入数据,其特征分布过于稀疏,极大地提高了神经网络提取有效特征的难度。另一方面,重录设备会在原语音信号的频域上引入变化[21,23,26,28],此种变化可以作为区分重录语音及原始语音的重要依据。为此,文中的网络输入数据采用语音的时频图。时频图由短时傅里叶变换(short-time Fourier transform,STFT)生成,相对于直接输入语音数据,时频图对于重录设备引入的特征信息有相对密集的分布,更有利于神经网络特征提取,从而加快训练,提高精度。
语音重录包含三个过程:语音经过播放器播放,经过空气传播,再由录音设备录制。重录导致语音数据一定程度的失真,此失真包括幅度失真和时间轴上的线性伸缩,主要由播放时的DA变换与录制时的AD变换采用的设备、录制环境及录制距离等因素造成。幅度失真可以表示为能量变化和一个叠加噪声,线性伸缩的程度与使用的硬件如声卡性能及所采用的采样率有关。失真模型可表示为:
(1)
其中,y(t)是重录语音;x(t)是原始语音;λ是幅值变换因子;η是叠加噪声。
对应的频域变化如式2所示。
Y(jω)=λ∂X(jαω)+N(jω)
(2)
其中,∂是时间轴线性伸缩因子;Y(jω)、X(jω)、N(jω)分别为y(t)、x(t)、η的频域表示。
对于固定的录音设备,其特征是非常稳定的,即λ、α是常数,而叠加噪声与录制环境、录制距离及录制设备AD转换有关。
对于训练数据,该实验均为安静环境下录制,避免引入无关的环境噪声,因为环境噪声有很大的随机性,且深度学习作为数据驱动的技术,在数据中加入环境噪声会使模型在训练过程中将是否含有环境噪声作为检测的依据。这对于实验是非常不利的,模型检测的依据应该是与设备相关的、稳定存在的特征。在实验中叠加噪声η主要与不同的录制环境,以及不同的录制设备有关,因此对于特定录制设备、特定录制距离下H(jω)的分布也是特定的。为了验证模型对含有环境噪声的录制语音检测的鲁棒性,文中也对含有环境噪声的录制语音进行了检测。
综上分析,对于文中采用的时频图,作为检测是否为重录语音的特征,其分布特点在相邻语音帧之间具有独立性并且在特定频段又具有一致性。
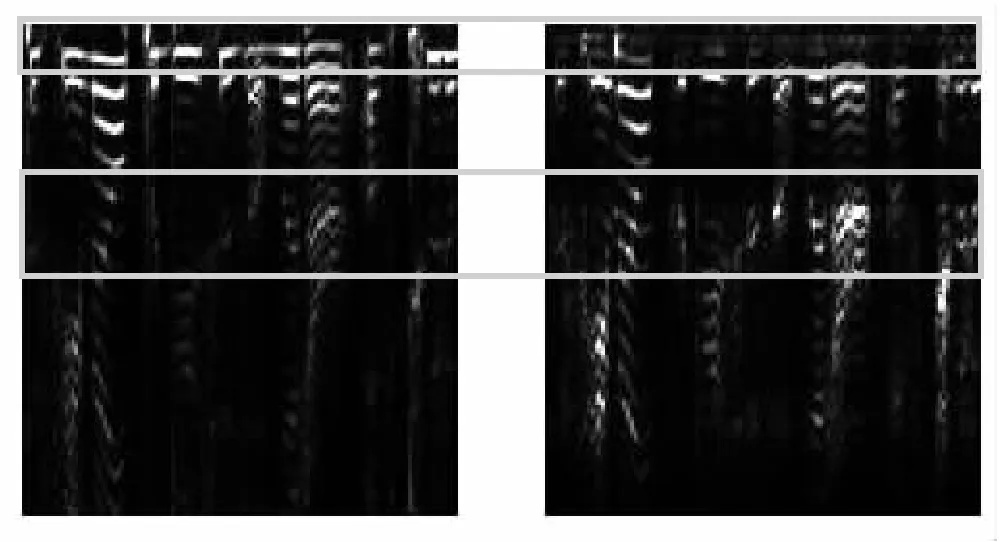
原始语音 重录语音
如图2所示,左侧为原始语音时频图,右侧为一种场景下的重录语音时频图,方框内区域可以直观地看出,重录语音引入的变化在某些频段较为明显。频率分辨率的大小是影响特征提取的最关键因素,这是由短时傅里叶变换中窗函数长度决定的,窗长度越大,频率分辨率越高,特征表现越明显。因此,在传统信号处理方法检测重录语音特征时,为了提取充分的特征,往往需要很长的语音段,这极大地限制了其适用范围。文中采用0.2秒语音段作为实验数据,短时傅里叶变换采用126长度汉宁(Hanning)窗,步长为50,时频图的尺寸为(64×62)。模型适用于绝大多数应用场景,并且实验结果证明具有很好的效果。
文中在频率维度进行卷积,同时在时间维度进行池化。只在频率维度进行卷积(3×1),不考虑时间维度的相关性,能极大地减少卷积核参数量,使得模型有更强的抗过拟合能力,减少对数据量的过度依赖,同时在训练过程中由于卷积核的参数共享,时间维度具有同分布设备的特征信息重复训练卷积核参数,可以使训练更加充分。池化层采用时间维度的池化(1×2),频率维度不进行池化。池化能减少特征的维度,加快网络的计算,并且使网络结构对数据特征的伸缩、变形有更强的鲁棒性,但池化在减少数据维度的同时也会丢失很多的特征信息,对于时频图,特征分布不存在伸缩与变形,只在时间维度池化,既减少了特征维度,同时又不会导致频率维度特征的丢失,这在文中卷积神经网络训练过程中极为重要。通过多层卷积与池化计算,特征维度最终变为一维,长度与时频图频率相同。
3 实验结果
3.1 实验设置
实验采用0.2秒时长语音段,原始语音库由300个说话人共100分钟的语音,每人语音时长为20秒,均是经过裁剪处理,不包含明显的静音片段,抽样频率16 kHz,量化精度16 bits。已有的研究报道均不考虑训练样本和测试样本在不同场景下的录制,而这不符合实际场景。为此,该实验语音库用不同的录音设备及在不同的录音距离下重录,以测试算法的通用性。随机抽选50位发言人的语音作为测试数据,其余250人的语音用于训练,避免同一位发言者的录音出现在不同数据集,保证训练数据与测试数据的独立性。
具体录制过程如下:对于训练集,在安静环境下由不同距离和设备组合对原始语音库重录4次,由此获得4个重录语音库,它们分别包含25 000段语音。原始语音通过手提电脑联想Y40-70AT-IFI播放;重录设备是手提电脑戴尔(Inspiron)灵越14(Ins14VD-258)和智能手机小米2S。4次录制的情况如表2中编号为t的数据。
对于测试数据,采用与训练集相同的录制设置。为了验证模型对具有环境随机噪声干扰的语音的鲁棒性,分别在室内安静环境与有一定随机噪声的室内环境下录制,测试集共包含8个语音库,每个语音库包含该库录制模式下共25 000条测试语音,如表2中编号为s的数据。
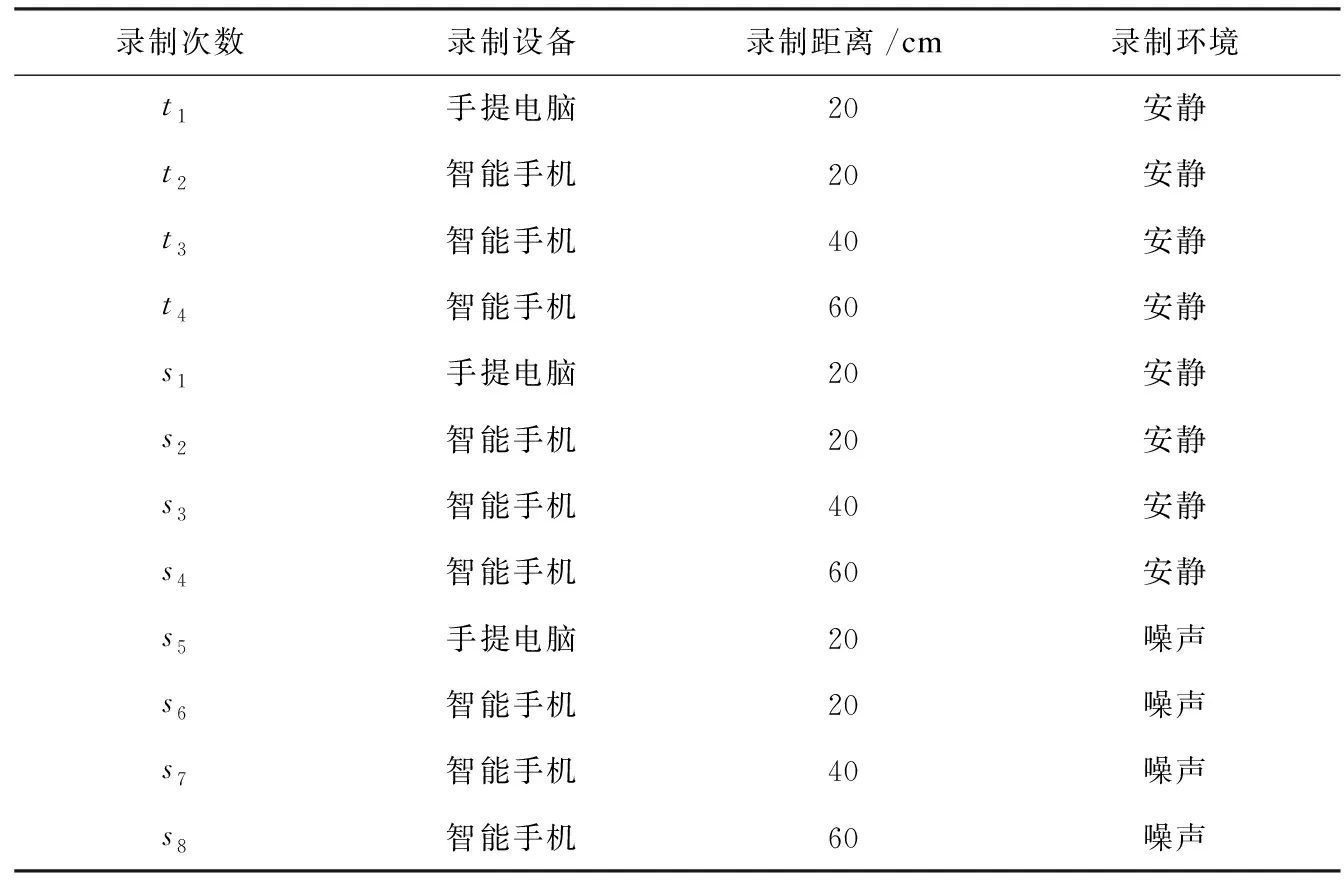
表2 语音录制情况
数据输入网络之前需要进行预处理,过程如下:对每个语音段进行短时傅里叶变换,语音采样率为16 kHz,量化精度16 bit,采用126长度汉宁(Hanning)窗,步长为50。全部数据在输入网络前要经过归一化处理,先计算整个训练集数据的均值μ与标准差σ,然后对数据样本x'进行减均值,除以标准差来进行归一化,最后得到经过预处理的数据x。
(3)
3.2 训练网络
文中网络误差函数为交叉熵损失函数,采用Adam优化算法进行训练,初始学习率设置为0.001,并在训练过程中动态调整学习率,每训练10 000次将学习率减小一倍,每次训练批量大小为32。为了在训练过程中监督训练效果,从训练数据中随机选取2 000条数据用于验证,通过对比训练数据损失函数与验证数据损失函数,为损失函数加入正则化项并设置正则化系数为0.000 1能有效防止过拟合。
表3列出了训练过程中的一些重要的超参数设置,在训练过程中不断监测训练损失与验证损失,并挑选训练损失小并且与验证损失较为接近时的模型作为测试模型。在该超参数设置下网络在训练过程中能够快速收敛,并且最终取模型得到相当高的精确度。
3.3 测试结果
重录语音检测涉及多个影响因子,包括录制设备、录制距离以及录制环境等。为了验证不同的影响因子对于网络的影响,分别对不同的录制语音进行实验,训练多个模型并分别对测试数据进行测试,以此来分析各因素对网络检测率的影响,并通过实验结果的分析,从而提出最终的训练模型。具体内容如下:分别以原始语音t为正样本与不同重录语音作为负样本的组合来训练网络,以t1为负样本训练得到模型M1,以t2为负样本训练得到模型M2,以t3为负样本训练得到模型M3,以t4为负样本训练得到模型M4,分别从t1、t2、t3、t4数据集中等比例采样组成训练集负样本训练得到模型M5作为最终的模型。测试结果如下:
(1)验证录制设备对网络的影响。
分别以模型M1、M2对测试数据s、s1、s2进行测试,其中s为原始语音的测试数据。在录制环境与录制距离相同条件下研究录制设备对模型的影响,测试结果如表4所示。
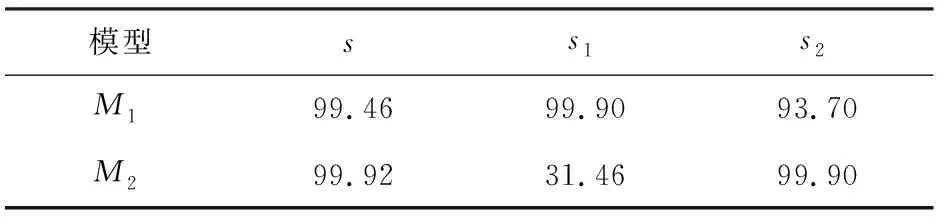
表4 不同录制设备的测试结果
测试结果表明,在录制距离与录制环境条件相同时,重录设备对于模型的影响较大,相同设备的重录语音训练的模型对同设备下的重录语音有较高的检测率,而对其他设备的重录语音检测率不理想。如表4所示,使用t1数据训练的模型对于s2数据检测率为93.7%,低于其相同录制条件下的测试数据,而对于t2数据训练的模型对s1数据的检测率低至31.4%,甚至低于随机猜测。并且,不同设备对于模型的影响大小也不相同,由表4中可知采用电脑重录语音训练的模型比手机重录语音训练的模型有更好的鲁棒性。
(2)验证录制距离对网络的影响。
以模型M2、M3、M4分别对测试数据s、s2、s3进行测试,在录制设备与录制环境相同条件下研究录制距离对模型的影响,测试结果如表5所示。
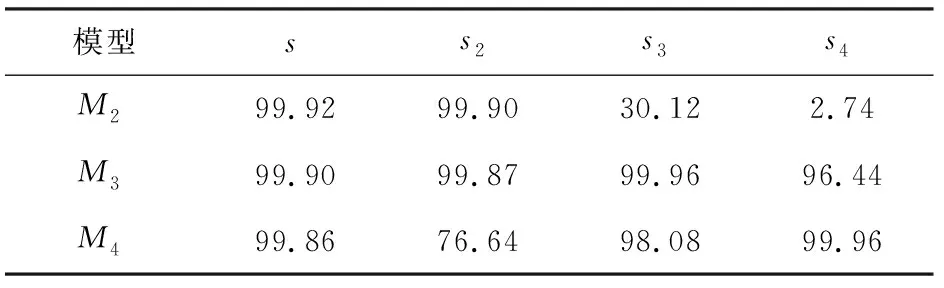
表5 不同录制距离的测试结果
测试结果表明,不同的录制距离对网络影响较大,相同录制距离的重录语音训练的模型对相同录制距离的重录语音检测率较高,均能达到99.9%以上,而录制距离不同的情况下检测率则较低,并且随着距离的差距增加检测率不断下降,20 cm的重录语音训练的模型,对于40 cm的重录语音检测率仅为30.12%,对于60 cm的重录语音检测几乎全部错误。对于60 cm的重录语音训练的模型也有相似的结果。由表5实验结果可知,40 cm距离的重录语音对于20 cm、60 cm的重录语音有不错的检测率,原因是其特征与这两种录制距离的重录语音有更多的相似性,因此模型能够通过这些特征来进行判定,而随着距离差距的增大,特征变化更大,对应的模型只能识别该距离下的重录语音特征。
(3)验证录制环境对网络的影响。
分别以模型M1、M2、M3、M4测试其对应录制条件下安静与有噪声的重录语音,测试结果如表6所示。
测试结果表明,模型对于有少量随机噪声的重录语音检测率略低于安静环境下重录语音,但是影响有限。随机噪声会为重录语音引入新的特征,这对模型的检测会有一定的干扰,但同时,无论是否含有噪声,重录语音对设备和录制距离的特征是比较稳定的,并且占据极大的比例,这些特征是区分原始语音与重录语音更重要、更稳定的特征。由表6测试结果可知,文中提出的网络结构对于不同录制环境下的重录语音都有较好的检测率,高达99.8%以上,表明该网络结构对重录语音中的随机环境噪声有良好的鲁棒性。
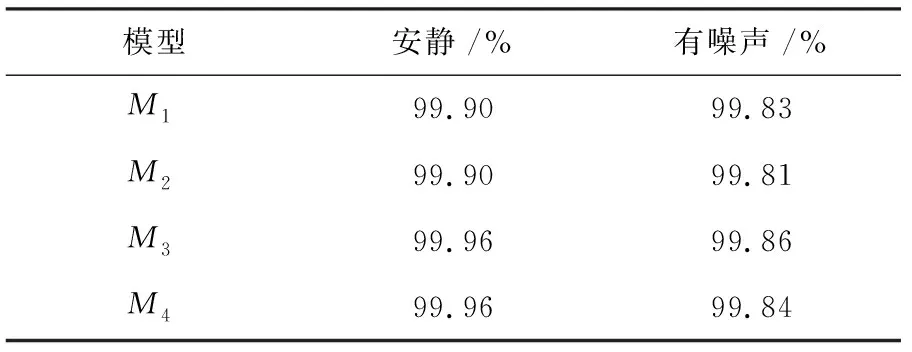
表6 不同录制环境的测试结果
以上实验表明,录制设备、录制距离、录制环境等影响因素对于模型都有不同程度的影响,单一条件下的重录语音所训练的模型对不同条件下的重录语音鲁棒性较低。因此为了提高模型对不同录制设备、录制距离以及录制环境下的重录语音的检测能力,需要对训练数据数据集进行合理的设置,训练集应更多地包含各种不同条件下的重录语音数据,这样网络结构才能学习更多不同录制设备、录制距离以及录制环境下的重录语音特征,从而提高模型的识别能力,提高对于各种场景下的重录语音的鲁棒性。
(4)多场景训练数据组合训练模型。
为了提高模型对不同场景下的重录语音的检测能力,采取多录音条件下的数据组成训练集,对模型进行训练,具体内容如下:分别从t1、t2、t3、t4数据库中等比例各随机抽取四分之一数据并与原始语音共同组成训练集,然后使用该训练集对模型进行训练得到模型M5,并分别对测试集数据进行测试。测试结果如表7所示。
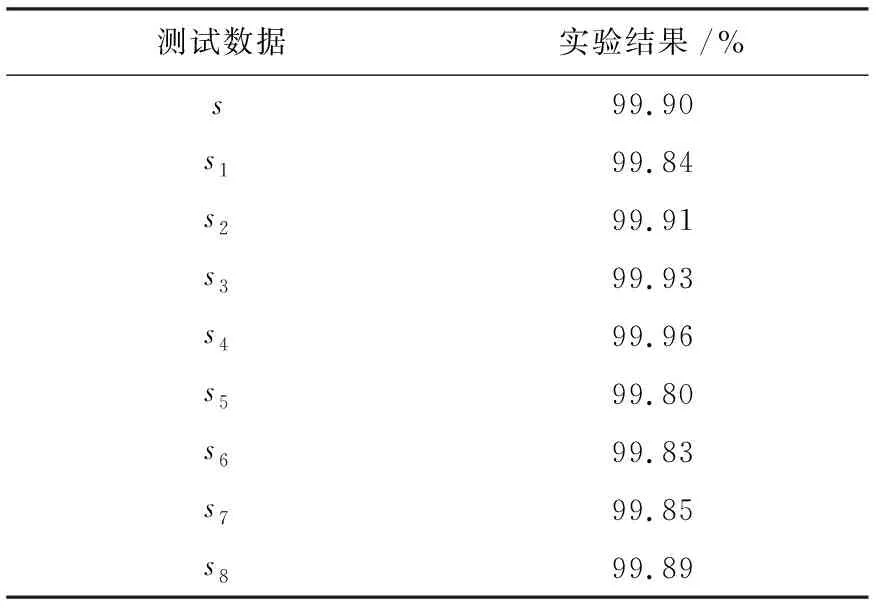
表7 三种录制条件综合下的测试结果
由测试结果可知,采用多条件重录语音所组成的训练集能极大提高模型的鲁棒性,对不同情况下的重录语音测试精确度都比较高,均能达到99.8%以上。采用多条件下的重录语音组成训练集,极大地丰富了训练数据的特征信息,通过充分训练,模型能够提取不同录制设备、录制距离等特征信息,同时也使原始语音与重录语音的特征更有分辨性。测试结果表明,在采用多条件下重录语音进行训练的模型对各种不同录制设备、录制距离以及录制环境下的重录语音都有良好的检测率,此条件下训练的模型具有更好的鲁棒性。
综上所述,不同的录制设备、录制距离以及录制环境都会对模型的检测造成不同程度的影响,采用单一条件下的重录语音训练的模型不具有通用性,泛化能力不足。因此文中网络结构采用不同录制条件下的重录语音的组合数据集进行训练,结果表明该网络结构有良好的鲁棒性,对于不同录制设备、录制距离以及录制环境下重录语音都具有极高的检测性能,表明提出的卷积神经网络能很好地解决重录语音攻击的检测问题,并且具有对较短语音段的检测能力。
4 结束语
之前对于重录语音的检测,更多集中于传统的信号处理方法,特征提取的算法有很大的局限性,算法复杂,同时为了提取充分的特征,对语音段的长度有较大的要求,这对算法的实用性是很大的限制。文中提出的卷积神经网络结构可以在极短语音段上提取充分的特征信息,依据语音信号的时频特征进行特殊设计,运用特殊的卷积核设置,与时频图的特征分布特点高度契合,并且模型参数量较少,大大降低了模型过拟合风险。同时对录制设备、录制距离以及录制环境等影响因子进行了实验研究,结果表明通过增加训练集数据的丰富性能极大地提高模型的鲁棒性,通过采用多场景下的重录语音混合数据进行训练,模型取得了最好的效果。为了验证该算法地性能以及通用性,网络分别对不同录制设备、不同录制距离及不同录制环境下的重录语音进行测试,其结果的精确度可达99.8%以上。实验结果表明,该网络能够有效地学习到标准信号处理无法解决的强大的特征表示,并能获得较高的识别精度;该卷积神经网络模型对于不同录制场景和设备的重录语音检测具有通用性。
