基于改进Apriori算法的肺癌致病因素研究
2020-04-15冯云霞
张 润,冯云霞
(青岛科技大学 信息科学技术学院,山东 青岛 266000)
0 引 言
肺癌是全球亟待解决的危害生命的最常见的癌症之一。2017年,世界卫生组织的最新数据表示,仅仅2015年肺癌导致了约170万人死亡[1]。研究表明,肺癌早期患者的治愈率较高,而肺癌晚期患者的存活率仅为15%[2]。主要原因是由于肺癌早期症状不明显,而中后期发病速度快,临床诊断时大多为中晚期[3]。
关联规则是反映出一个事务与其他事务之间相互关联或依赖的关系,看似不相关的事件的逻辑关系的知识,并运用于对同一事件中不同的特征之间的依存关系[4]。一份某种疾病的电子病历包含太多数据,若拿来直接用作预测或分类,会有多项不相关的因素干扰,因此,通过关联分析能寻找某类与该疾病存在密切相关的特征。其中,Apriori算法是关联规则中经典的算法。关联规则的运用最早追溯到20世纪90年代,Agrawal首次提出关联规则问题,并将其运用在分析顾客交易数据中的关联因素[5]。此后,为了提高该算法的运行速率,不断有改进算法提出,如Feng等将MapReduce与Apriori算法相结合,设计了一种适用于大数据量的MH-ACT方法,把频繁项集分成几个互不相交的块,只对每个分块扫描一次,将结果合并到一起再计算所有项集的支持度[6]。Almaolegi等为了降低数据库的规模,选用部分数据库中部分采样计算频繁项集,用数据库中剩余的数据来验证这些结果是否正确,这样大大降低了算法的时间复杂度[7]。Shah等将哈希函数引入Apriori算法中,从而降低候选集的数量,提高了运算速率[8]。越来越多的改进算法,通过降低数据库的规模、分布式处理频繁项集、减少候选项集数目、引入MapReduce架构等方法,能够弥补传统Apriori算法的缺点。
1 Hadoop平台与Apriori算法
1.1 Hadoop平台
Hadoop分布式广泛应用于多个软硬件平台,能够高速处理大规模数据的并行运算和存储问题,使用Java解决PB级的数据[9]。Hadoop平台主要由并行编程模型MapReduce、分布块HDFS和开源数据库HBase构成[10]。Hadoop实现分布式并行数据处理时,若客户端想访问数据块,名称节点(NameNode)负责数据块的具体路径映射,并找到对应的数据节点(DateNode),计算出数据的具体位置节点信息[11]。整个过程中,NameDode作为Hadoop的主服务器节点,处理数据块到Name Node的映射关系,文件不通过其进行发送[12]。DataNode完成对数据块进行创建、复制和删除的任务。工作流程如图1所示。

图1 HDFS的工作流程
1.2 Apriori算法
作为数据挖掘中的重要工具,关联规则最早运用在分析顾客交易数据中的关联因素中[13]。最经典的算法即Apriori算法,首先按照最小支持度找到所有的频繁项集,然后产生强关联规则。Apriori算法的挖掘过程包括挖掘频繁项集和关联规则的产生。
(1)频繁项集的挖掘。
设置最小支持度阈值(SUP_min),在所有的候选项集中找出大于或等于SUP_min的项集,即频繁项集。
(2)强关联规则的产生。
根据第一步得出的频繁项集中,给定最小置信度(CONF_min),若满足CONF_min的规则,称之为强关联规则。若存在项集{I3,I4,I5},则规则为{I3→I4,I5},{I4→I3,I5},{I5→I3,I4},{I3,I4→I5},{I3,I5→I4},{I4,I5→I3}。
Apriori算法是频繁挖掘项集中最重要的算法,是通过逐层迭代的候选生成方法[14]。核心是通过K-项集挖掘(K+1)-项集[15]。衡量Apriori算法的两个重要标准:
(1)支持度(support):描述关联样本中某个特征出现的频率。指对存在的项集X、Y和B(X、Y均属于项目集B),事物集B均包含事物集X、Y的百分比。存在如下关系:
(2)置信度(confidence):描述两个特征之间相互关联的强度,指在事物B中包含X、Y事物数的百分比,关系如下:
支持度和置信度是Apriori算法中两个最重要的概念,两者通过0%~100%的概率来衡量事务之间的紧密联系程度。最小支持度和最小置信度由人为设定,只有同时满足最小支持度和最小置信度才能称为两者具有强关联度。
2 基于Hadoop平台的Apriori算法并行化改进
基于Hadoop平台改进Apriori算法有两种主要方法:一种是数据集均匀分布在每个节点上,对局部并行挖掘频繁项集,收集全局频繁项集;第二种是使用MapReduce迭代挖掘频繁项集[16]。
本实验中,由于传统的Apriori算法的执行效率低、频繁扫描数据库,利用Hadoop平台结合Apriori算法迭代挖掘频繁项集,多次扫描数据库寻找候选项集。利用MapReduce将输入数据进行Map分块,在每次Apriori算法循环迭代时,对分布在每台计算机上的数据块进行累积求和,累计候选项集Ck的次数。在每个分块数据中,通过求和运算计算候选项集Ck中属性的支持度,找出频繁项集Lk。基于Hadoop平台的Apriori算法的并行化优化方法如下:
(1)执行Apriori算法得到候选-1项集C1,将C1与原始数据集对比,得到候选项集C1中每个属性的支持度,通过MapReduce框架程序处理获得频繁项集L1。
(2)在分布于每个计算机上的Map块中,通过频繁项集L1,产生候选-2项集C2,并逐次产生候选-k项集Ck。
(3)在MapReduce框架的Reduce进程中,通过求和运算对每个分布在Map节点上的k项候选项集的支持度累计,得到在k项时的全局支持度计数。比较全局支持度计数与最小支持度阈值,获得频繁项集Lk。
(4)当前一台计算机计算出频繁项集后,后一台计算机启动Map进程并计算出频繁项集,以此步骤循环迭代,直到集合Lk为空,结束进程;否则继续执行步骤(2)。
(5)对处理完的数据块保存于HDFS中,并挖掘出相应的强关联规则。
图2为改进的算法流程。
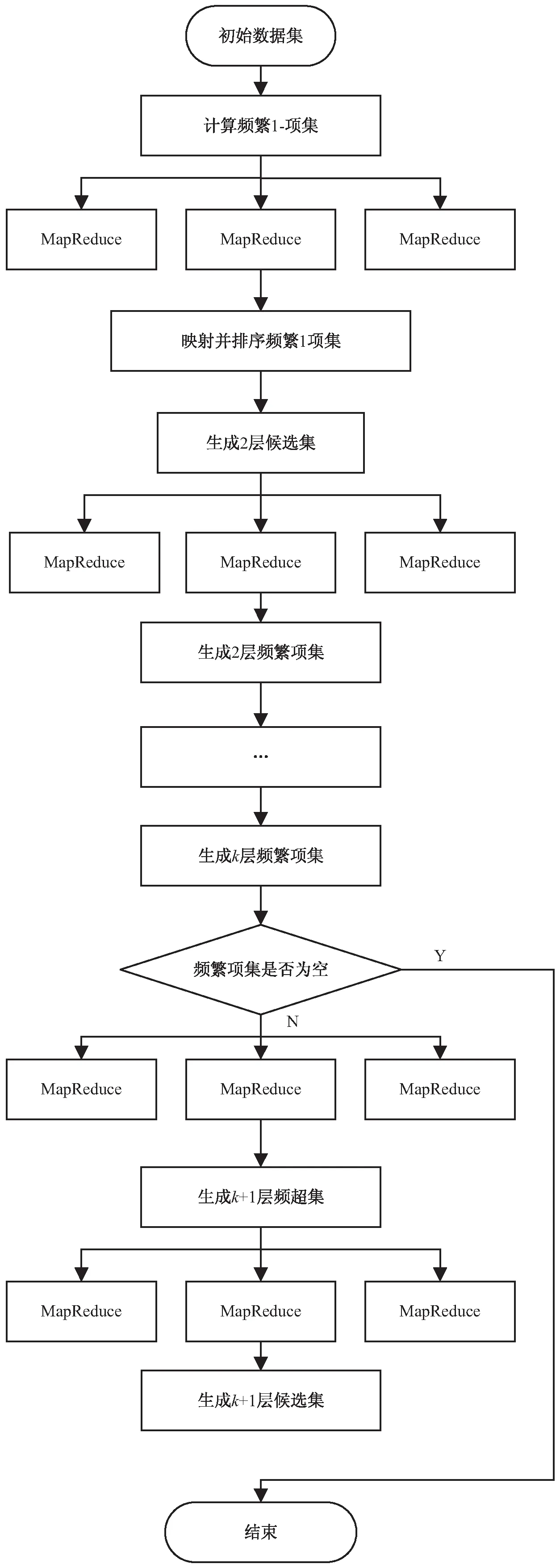
图2 改进Apriori算法流程
3 改进Apriori算法在肺癌电子病历中的应用
3.1 实验环境
实验选用的5台PC机,包括一台名称节点NameNode和4台数据节点DataNode,选取的计算机配置如表1所示。

表1 计算机配置
Hadoop平台的一台计算器作为服务节点NameNode Master,另外4台计算机作为服务节点DataNode Slave,IP分配如表2所示。

表2 各个节点的IP分配
3.2 实验数据预处理
实验所使用的数据均来自本市某三甲级医院的肿瘤科电子病历,该电子病历记录患者从入院的身份数据、主诉、医嘱、检验数据到出院的各项数据。实验数据选取2017年3月至2018年9月的患者病历,以分析肺癌与吸烟、肺部疾病史、职业致病因子、咳嗽胸痛等信息之间的关联信息,以及症状之间的潜在规律。在进行关联分析之前,首先要对数据进行预处理,包括对数据合并、数据结构化、数据清洗以及数据转换等步骤。本次实验共选取肺部肿瘤患者共18个属性(包括性别、年龄、吸烟史、肺部疾病等信息)进行分析。
(1)数据合并:从医院his系统导出来的电子病历分为医嘱、诊断、检验等模块,需要根据患者唯一的PID标识进行关联,将患者的诊断、主诉、既往史、检验数据同步,所以运用excel表格对数据集成合并处理。
(2)数据结构化:使用ICTCLAS作为分词工具,建立医学用户词典,提取按词频分类结果的结构化属性表。
(3)数据清洗:提取特征属性的结构化电子病历存在异常数据、缺失值数据[17]。缺失值处理中,对数值型数据,选择均值代替;对字符型数据,选择众数代替。存在大量缺失值的数据,选择直接删除。异常值处理中,计算出每类数据所占比例,并画出正态分布,对于所占比例过低的数据判断为异常值[18]。异常值的处理方式与缺失值相同。
(4)数据转换:由于Apriori算法只能对离散化数据进行处理,所以在进行数据挖掘前,要对连续性数值进行离散化处理。以吸烟史为例,从未吸烟为0,1至10年为1,10至20年为2等。
3.3 改进算法对比分析
在本实验中,由于涉及的患者病历数据量较大,为了获得更加有价值的信息,将最小值支持度和最小置信度不断改进。在最小置信度固定为0.6的情况下,最小支持度为0.06时,挖掘的强关联规则太多,这种情况下的规则是无意义的。直到最小支持度提高到0.1时,挖掘的关联规则数量产生了明显的变化。通过多次实验对比,选定最小支持度为0.1,最小置信度为0.6,这是肺癌数据挖掘较为合适的参数设置。
Apriori串行算法与改进并行算法在处理相同规模数据时所用时间的对比如表3所示。当数据规模不断增大时,串行算法所用的时间明显增多,直到提示内存不足。而改进的并行算法在处理大规模数据时完成能力较好。因此,在处理小规模数据量时,传统的串行算法比改进的并行算法效果好,这是因为Hadoop平台的节点启动运行需要一定的时间;在处理大规模数据量时,改进的并行算法的效率远远高于传统的串行算法。

表3 改进算法与传统算法的比较
节点数选取1、2、3、4,电子病历数据量大小分别为1 G、2 G、3 G。每次实验进行3轮取平均值,最终的运行时间结果如图3所示。

图3 改进算法实验结果
从图3中可以看出,从下到上的折线分别为1 G、2 G、3 G大小数据量的运行结果,随着数据规模的不断增大,运行所用时间随着节点数的增加而减少。因此,增加Hadoop集群的节点数可以显著提高数据处理能力,基于Hadoop平台改进的Apriori算法具有良好的性能,在处理肺癌电子病历具有较高的执行效率。
3.4 实验结果
最终得到强关联规则,部分如表4所示.从表中的关联结果,得到以下结论:
(1)在性别对比上,患肺癌男性远远高于女性,这与男性为吸烟主要群体有一定关系。在年龄对比上,60至70岁的老年人患肺癌最多,但由于吸烟人数的增多,肺癌患者也呈现低龄化趋势,尤其是在年轻的男性中,患肺癌人数逐年增加。
(2)有胸闷憋气、胸痛、咳嗽、咳血等症状与肺癌有着密切的关系,对化验数据的关联规则挖掘,基于CT影像数据能够及时发现早期肺癌。
(3)吸烟对肺癌有着严重的影响,吸烟史与肺癌的发病率有极大的关系。
(4)肺癌与职业治病因子之间有一定关联规则,从事石油、粉末、煤炭等职业人群患肺癌的概率较大。
(5)肺部疾病患者中,有肺结核等疾病的患者癌变的可能性比较大。
改进的算法与临床医学结论相符合,能够挖掘疾病与病因之间的潜在规律和规则,这对肺癌疾病的分析与研究具有重要的意义。

表4 关联规则结果
4 结束语
基于Hadoop平台改进的Apriori算法可以协助临床医生快速、准确、高效地做出判断,对肺癌早期预防、早期治疗具有重要的意义。通过实验结果可以看出,在处理大规模电子病历数据时,基于Hadoop平台改进的Apriori算法的执行效率远远高于传统Apriori算法。并且改进后的算法具有良好的可移植性,能够适用于肺癌电子病历的数据挖掘,及时有效地挖掘出肺部肿瘤疾病与症状之间的潜在规律,具有一定可行性。
