结合地理和社交因素影响的兴趣点推荐
2020-04-14毕波
毕 波
(马鞍山师范高等专科学校,安徽 马鞍山 243041)
0 引 言
近几年来,具有签到功能且基于位置的社交网络,如Brightkite、Gowalla和Jiepang等,都运作失败.失败的主要原因之一是个性化服务的质量,尽管用户能够被推送他们朋友访问喜欢的空间地点,但推荐的质量不足以满足用户的需求[1].这些地点称为兴趣点,可以包括餐馆、博物馆和商店.Foursquare是最早基于位置的社交网络之一,最近推出一款名为Marsbot的新应用,向用户推荐个性化兴趣点.Marsbot可以在任何给定地点自动推荐首选的个性化兴趣点.Foursquare不仅能让用户分享签到体验,还能为用户提供个性化服务,尤其是基于位置的推荐.单纯的签到已经不能满足用户的需求.而孟祥福等[2]研究了位置兴趣推荐所带来的两者与用户之间的耦合问题,利用分类算法及关联集成算法,在yelp数据集测试得到了良好的实验结果.康来松等[3]提出了奇异值和因子等分解对异构数据的兴趣点推荐算法改进,并且在Gowalla和Foursquare数据集测试得到了优化效果,未来可以为服务推荐等场景提供依据.因此,提供智能化且个性化的推荐,是基于位置的社交网络成功的关键.
1 传统兴趣点推荐算法
个性化兴趣点推荐的主要算法是协同过滤,依赖于用户-个性化兴趣点检查.这种算法又可分为基于记忆的推荐算法和基于模型的推荐算法[4].
1.1 基于记忆的推荐算法
基于记忆的推荐算法包括基于用户和基于项目的协同过滤.这些算法基于相似性或某种特定关系,通过聚合相似用户或个性化兴趣点的得分来预测目标用户的偏好[5-7].个性化兴趣点通常根据地理信息进行关联.例如,Ye等[6]利用2个个性化兴趣点之间距离的幂律分布来模拟个性兴趣点之间的关系.Zhang等[7]估计核密度来探索个性化兴趣点与二维地理坐标的关系.Sarwat等[5]应用基于项目的协同过滤计算项目的空间相似度,并考虑了距离惩罚.
1.2 基于模型的推荐算法
基于模型的推荐算法通过计算表示访问不同个性化兴趣点可能性的偏好,向用户推荐某些个性化兴趣点.这些偏好是通过推导出建立在整个数据集上的模型来计算的[8].基于模型算法的典型例子包括矩阵因子化和贝叶斯概率模型.矩阵因子化已经应用于融合地理信息和社会信息方面[9-11].Liu等[12]利用概率因子模型预测用户对个性化兴趣点的偏好,该模型融合了概率矩阵因子化和泊松因子模型.Yin等[13]提出了基于潜伏Dirichlet分配的用户评分特征的概率生成模型.
无论是基于记忆还是基于模型的推荐算法,在协同过滤中都会给每个用户和个性化的兴趣点分配低层次的特征,因此,探索用户偏好的深层特征和学习特征之间的高阶交互是不可能的.深度学习是具有多层次表示的学习算法,通过组成简单的非线性模块获得,将某个层次的表示转化为更高且更抽象层次的表示.这种算法非常善于发现高维数据中的复杂结构,从签到数据中发现有效的特征或表示是个性化的兴趣点推荐的关键.因此,深度学习模型非常适用于发现内在的高级特征,这对个性化的兴趣点推荐任务非常有用.
2 结合地理和社交因素影响的兴趣点推荐算法
对于个性化兴趣点推荐来说,用户偏好最重要的信息是地理和社会影响因素[9-11].根据Tobler第一定律[12],用户签到行为呈现出地理聚类的特点.例如,研究者利用模式分解对个性化兴趣点之间的距离及对用户签到行为进行建模[13-15].Cheng等[10]发现用户倾向于在几个中心附近签到,并将地理相似度建模为多中心高斯模型.Zhang等[7]通过估计内核密度来捕捉二维地理坐标.因此,本研究提出了深度学习模型来探索个性化兴趣点之间的地理相似性.
关于社交影响的大量研究[16-17]表明,用户行为受在线社交好友的影响很大.大多数研究从社交链接中得出相似性,并将其放入传统的协作过滤器[18]中.与以往算法相比,此算法采用深度学习的方式来推导用户之间的社交影响因素,并考虑社交好友的签到数据.
与以往研究不同,此算法尝试对地理相似性和社会影响进行建模,而不是时间和顺序上下文.许多深度学习模型都可以使用,然而卷积神经网络(Convolutional neural networks,CNN)被设计为处理多个数组形式的数据,最好使用循环神经网络(Recurrent neural networks,RNN)和门控循环单元(Gate recurrent unit,GRU)对顺序上下文进行建模[19].上述模型都利用了监督学习进行训练,但是人类的学习基本上是无监督的,因此此算法使用无监督深度学习的算法.
2.1 结合地理和社交因素的特征设计
在传统的推荐任务中,偏好可以通过评分来明确获得,但此算法没有明确的评分数据,只有访问个性化兴趣点的用户签到数据[20].此外,不同类别的签到频率尺度也不具有可比性.显然,单凭签到频率数据不能完全代表用户对个性化兴趣点的偏好程度.词频-逆文档频率(Term frequency-inverse document frequency,TF-IDF)是当今信息检索及文本挖掘系统中最常用加权技术之一[21].根据TF-IDF的设计,c类对于用户签到的重要性也同样可以设计为:
(1)
式中,Nik是用户i签入的属于类别k的不同个性化兴趣点的数量,而所有类别都在集合Cat中.Nuser为用户总数,Nc为已打卡属于c类兴趣点的用户数.βic由两部分的乘积计算而来:左边部分代表c类在用户i的签到中的频率,右边部分表示c类在所有用户签到中的稀有度.因此,该产品可以衡量类别c在用户i的签到中的重要性.例如,如果c在用户i中的出现频率较高,而在其他用户中较为罕见,那么c对于用户i来说更为重要.
众所周知,签到次数遵循高度偏态分布,所以对数转换是文献中的标准作法[22].因此,结合以上所有内容,可以得出特定用户i及其对位置j的偏好变换:
(2)
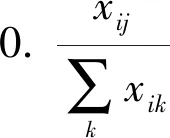
基于文献[15]中的数据可知,兴趣点之间的距离与签到频率的关系大致遵循幂律分布.大多数用户的朋友数量少于10个,但尽管大多数用户的朋友数量相对较少,但与朋友共同签到的比例明显高于与陌生人签到的比例.因此,社会影响力对用户的签到行为有一定的影响,在个性化兴趣点推荐任务中应被考虑到.
本研究使用幂律分布来计算个性化兴趣点之间的地理相似性:
s=α×Dβ
(3)
式中,α和β为幂律分布的参数,D为同一用户访问的个性化兴趣点之间的距离,s指个性化兴趣点之间的地理相似度.用户的签到行为受到其移动性的影响,移动性用所访问的个性化兴趣点的地理分布来表示.
2.2 基于半限制性玻尔兹曼机的深度学习模型
本研究提出的深度学习模型不仅要考虑地理和社会影响因素,还要发现隐性因素特征,比如偏好.整体框架有4部分,如图1所示.首先,从用户个性化兴趣点的签到历史中得出用户对个性化兴趣点的偏好.其次,利用半限制性玻尔兹曼机对个性化兴趣点的地理相似性进行建模,而用限制性玻尔兹曼机对用户在个性化兴趣点的偏好进行建模.基于半限制性玻尔兹曼机和限制性玻尔兹曼机来逐层构建多层结构.具体来说,第1层由半限制性玻尔兹曼机组成,表示个性化兴趣点和它们之间的相似性.然后,利用限制性玻尔兹曼机来构建其余各层.需要注意的是,当前的限制性玻尔兹曼机的隐藏层是下层的限制性玻尔兹曼机的可见层.多层限制性玻尔兹曼机用于预训练模型的参数.第三,将模型展开,产生基于半限制性玻尔兹曼机的深度自动编码器.第四,基于用户之间的社交链接,在模型中加入条件层,建立了深度学习模型.考虑到好友的签到行为,本研究将社交影响融入到提出的深度模型中.
在深度学习中,学习表示和转换输入特征通常是无监督的任务.因此,本研究选择了深度自动编码器.受Salakhutdinov等[23]使用条件层获取额外信息的启发,本研究对朋友的签到信息使用了条件层,并将其连接到第1个隐藏层,以学习更高层的特征.在深度自动编码器中,输入层和输出层代表个性化兴趣点.半限制性玻尔兹曼机捕获了个性化兴趣点之间的地理接近性,因此,它被连接到深度自动编码器的第1层和最后层.
3 结合地理和社交因素影响的兴趣点推荐算法实现
本研究在深度学习模型的预训练过程中使用了半限制性玻尔兹曼机来模拟地理相似性[24].限制性玻尔兹曼机是层内无连接的二元连接图,通常用于预训练深度学习模型.与限制性玻尔兹曼机不同,半限制性玻尔兹曼机的可见单元之间是完全或部分连接.本研究中,半限制性玻尔兹曼机的可见单元代表个性化兴趣点,可见单元之间的连接可以模拟个性化兴趣点之间的地理相似性.半限制性玻尔兹曼机很少用于现有的工作中,由于可见单元之间存在联系,却适合于模拟个性化兴趣点之间的地理近似性.
在此算法的模型中,每个半限制性玻尔兹曼机代表1个用户,每个可见单元代表用户访问过的个性化兴趣点.所有的半限制性玻尔兹曼机都有相同数量的隐藏单元,但每个用户的可见单元数量不同,因为不同的用户访问过不同的个性化兴趣点.然而,所有的半限制性玻尔兹曼机都共享相同的权重和偏差集.即,当数据被输入到模型的可见单元时,每个用户都有缺失值,因为用户没有检查到一些个性化兴趣点.本研究中,此算法没有将缺失值设置为0,而是在所有计算中忽略这些值,而对于其余值,将更新连接的权重.
半限制性玻尔兹曼机不仅是此算法深度学习模型的组成部分,而且还用于预训练此算法的模型[24].对于每个用户,此算法可以获得1个包含用户访问过的个性化兴趣点签到数据集合.
如图2所示,基于半限制性玻尔兹曼机的自动编码器是通过展开多层半限制性玻尔兹曼机和限制性玻尔兹曼机得到的.因此,第1层(输入层)有可见单元之间的连接,最后层(输出层)有代表个性化兴趣点的隐藏单元之间的连接.此算法的自动编码器中,第1层的可见输入是个性化兴趣点的偏好,输出是模型预测的用户对个性化兴趣点的偏好.
由于通过传统反向传播训练难于优化参数,预训练程序[25]已经成为一种流行的初始化参数算法.此算法使用半限制性玻尔兹曼机和限制性玻尔兹曼机对自动编码器进行预训练.对于第1层(输入层),此算法使用半限制性玻尔兹曼机来预训练相应的参数,但对于其余层,此算法使用限制性玻尔兹曼机来预训练参数.对于每个限制性玻尔兹曼机,将上层的隐藏单元视为当前层的可见单元.
训练过程使用链式规则的反向传播算法,此外通过最小化平方误差函数优化参数.具体来说,对于包含用户访问过的个性化兴趣点集Lt的训练案例t(用户特定),此算法将成本定义为总的瞬时方差函数:
(4)
式中,yi是输入层中单位i的输入值,oi⊂Output是输出层中单位i的输出值.
给定由N个训练案例(用户)组成的训练集T,则此算法定义整体损失函数如下:
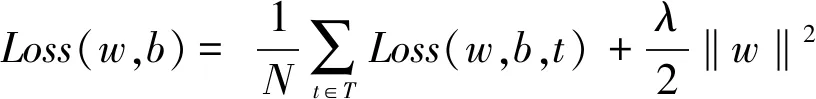
(5)
式(5)中的第1项是训练案例的总误差平均值,加入正则化项(即第2项),以防止问题的过度拟合.
此算法的模型输出了用户对所有个性化兴趣点的偏好.所有个性化兴趣点都按总体偏好降序排列,其中前K个候选者被推荐给用户.此外,即使用户已经访问了某个特定的个性化兴趣点,基于位置的社交网络仍然需要向用户推荐该个性化兴趣点,并通知用户相关的折扣或促销活动.因此,此算法模型考虑了所有个性化兴趣点,包括在推荐之前用户已经访问过的个性化兴趣点.
4 实验结果与性能分析
本研究建立了3种模型进行对比,第1种模型为Semi-DAE,是去除社交层后的深度学习模型;第2种模型为CDAE,是具有社会影响力层但去除了半限制波尔曼层的深度学习模型,第3种模型为Semi-CDAE,综合了地域相似性和社会影响力两者.本研究比较了Semi-DAE、CDAE和Semi-CDAE在3个数据集上的推荐精度,以证明半限制性玻尔兹曼机层和社交层的有效性及模型管理额外隐含信息的能力.
实验硬件平台配置为:Intel Core i9-9900K CPU@3.60 GHz处理器;TITAN RTX型号GPU,32 GiB内存;64-bit Ubuntu 18.04操作系统.数据收集自基于位置的流行社交网络Foursquare,其包括3个数据集:纽约、布鲁克林与旧金山.基于位置的社交网络提供了用户对个性化兴趣点的签到次数及经纬度等地理信息,此外也提供了用户直接的在线社交链接,这些链接是没有加权的原始数据.
对于此3个数据集,Semi-CDAE的性能优于Semi-DAE.与CDAE相比,Semi-CDAE在3个数据集上的表现也要优越得多.实验结果表明,该算法有效地处理了社会和地理因素的影响,提高了精度.
这些结果不仅证明了社会和地理因素实际影响到用户访问个性化兴趣点的决定,而且也显示了此算法在模拟这些影响和学习用户偏好方面的潜力.
5 结 语
地理和社会影响对个性化兴趣点推荐服务非常重要,社会影响是个性化兴趣点建议的有效预测因子.从数据科学的角度,本研究提出了一种利用深度学习技术结合地理和社会影响信息的新算法.传统的技术需要仔细的工程设计和扎实的领域专业知识来为每个因素设计特征提取器.
因此,几乎不可能明确地包含个性化兴趣点推荐的所有因素.然而,深度学习模型非常擅长自动发现内隐特征.本研究的实验结果表明,深度学习模式在抽象的高水平上学习这些因素是非常有效的.因此,基于位置的社交网络中,深度学习是一种更好的推荐选择,特别是当存在多个未知特征时,因为它能够隐式地发现特征.
本研究证明了在基于位置的社交网络中使用半限制性玻尔兹曼机模型来模拟地理相似性的实用价值.实验也表明,半限制性玻尔兹曼机模型和提出的Semi-CDAE算法能够很好地学习地理相似性.这些模型最显著的特点是在某些层中存在内部联系,可以用来表示个性化兴趣点之间的地理相似性.
