煤矸石图像分类方法
2020-04-13饶中钰吴景涛李明
饶中钰,吴景涛 ,2,李明
(1.中国矿业大学 信息与控制工程学院,江苏 徐州 221116;2.冀中能源股份有限公司 章村煤矿,河北 邢台 054000)
0 引言
煤炭是我国的主导能源,约占能源生产、消费总量的68%和60%[1]。在煤炭开采和加工过程中,矸石含碳量较低,色泽与煤炭相近,是伴随产生的废弃物,占原煤生产总量的15%~20%[2]。矸石在燃烧时会产生以SO2为主的大量有害气体,加重大气环境污染,大幅降低煤炭品质。在煤炭利用前,必须对矸石与煤进行分选。传统的煤矸石分选方法主要包括人工排矸法、机械湿选法和γ射线分选法[3-7],在快速高效性、安全无害性、简单操作性等方面无法兼顾。
随着人工智能技术的发展,机器视觉技术越来越多地应用于图像识别领域。虽然煤和矸石外表都是黑色,但二者灰度分布与纹理特征不同。基于此,许多学者将机器视觉技术引入煤矸石分选,其中大多数采用特征提取与分类算法相结合的图像处理算法,如余乐[8]通过改进的灰度共生矩阵进行煤矸石纹理特征分析,何敏等[9]基于支持向量机分类方法结合煤矸石纹理及灰度特征进行煤矸石分类,张勇[10]采用多特征融合并结合K近邻算法、支持向量机进行煤矸石分选。上述方法在煤矸石识别方面具有较高准确率,但存在鲁棒性不强、易受光照影响等问题。
卷积神经网络基于卷积特征提取方法构建,具有快速方便、鲁棒性强等优点,越来越多地应用于图像分类。本文基于机器视觉技术,研究煤矸石图像分类方法。采用基于距离变换的分水岭算法,完成对煤矸石图像的分割提取;分别采用传统基于特征提取与基于卷积神经网络的图像分类方法,对煤矸石图像进行分类识别,验证了基于卷积神经网络的方法具有更高的准确率。
1 煤矸石图像分割
1.1 图像预处理
采集河南某矿区矸石与煤若干块。为模拟传输带上煤矸石分类场景,以黑色背景拍摄煤矸石图像,如图1所示。
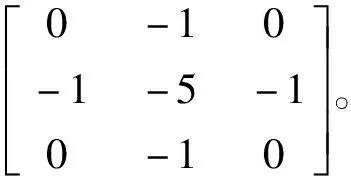

图1 煤矸石图像
煤矸石增强图像如图2(a)所示。可看出增强图像对比度较原图显著提高,但图像中的噪声同时得到增强。因此,采用高斯卷积核为(3,3)、标准差为0的高斯平滑滤波方法对增强图像进行平滑去噪处理,结果如图2(b)所示。

(a)增强图像

(b)滤波图像
1.2 图像分割
对预处理后的煤矸石图像进行分割。采用自适应阈值分割方法中的最大类间方差(OSTU)算法及K均值算法分割图像,结果如图3所示。可看出受光照及阴影影响,OSTU算法与K均值算法分割图像时均存在一定程度的误分割情况。

(a)OSTU算法分割结果

(b)K均值算法分割结果
采用基于距离变换的分水岭算法[11]进行图像分割。为了防止图像过度分割,通过标记前景图像和背景图像来优化分割效果。标记前景图像过程:对预处理后的图像进行基于开运算及闭运算的重建,以清理图像中不必要的小块区域;求取图像中的极大值,并将极大值标记为前景图像,如图4(a)所示。标记背景图像过程:采用OSTU算法得到分割图像;计算分割图像中白色区域与前景图像边缘的距离,将距离前景图像较远的部分标记为背景。对标记出背景图像和前景图像的掩膜图像进行分水岭分割,结果如图4(b)所示。可看出采用基于距离变换的分水岭算法分割煤矸石图像时,矸石与煤的前景图像和背景图像被很好地分割出来,效果优于OSTU算法及K均值算法。

(a)前景图像

(b)分割图像
2 基于特征提取的煤矸石图像分类
2.1 特征提取
采用方向梯度直方图(Histogram of Oriented Gradient, HOG)特征及灰度共生矩阵作为图像特征。HOG特征选取单元格大小为8×8,单独区域块大小为2×2,输入图像大小为128×128,每个单元格选取9维特征,1个block里有4×9个特征向量,选取8个像素长度作为步长,由此计算得水平、垂直方向各有15个扫描窗口,最终可得4×9×15×15=8 100维特征。
灰度共生矩阵通过分割图像中2个像素点的联合概率密度来定义,即从灰度为i的像素点开始,与这些像素点距离为d、角度为α处灰度为j的概率。灰度共生矩阵维度过高,通常选取部分特征作为特征向量。本文选取能量、熵、对比度及反差分矩阵作为图像纹理特征。
2.2 煤矸石图像分类
采用应用广泛的支持向量机、随机森林及K近邻算法进行煤矸石分类。支持向量机基本思想是通过寻找一个超平面来分割样本,分割过程中依据支持向量间隔最大化原则进行分类。实际存在的样本大多是高维且线性不可分的,因此需要引入核函数来实现数据线性可分。本文采用常见的径向基函数作为核函数。随机森林是由众多决策树模型组合构成的监督学习算法,基本思想是将所有决策树结果汇总,以投票形式生成最终结果,算法步骤:随机抽样生成训练子集,构造决策树并对其组合生成随机森林,对随机森林进行投票产生最终结果。K近邻算法基本思想为通过寻找样本集中与待测样本最相近的k个相似点,并统计k个相似点所属类别来划分待测样本类别。本文采用常见的欧式距离计算公式,近邻个数k=10。
针对煤矸石图像的HOG特征和灰度共生矩阵,分别选取支持向量机、随机森林、K近邻算法作为分类器进行分类,准确率见表1。可看出基于HOG特征和支持向量机的煤矸石图像分类方法的准确率最高,为91.9%。
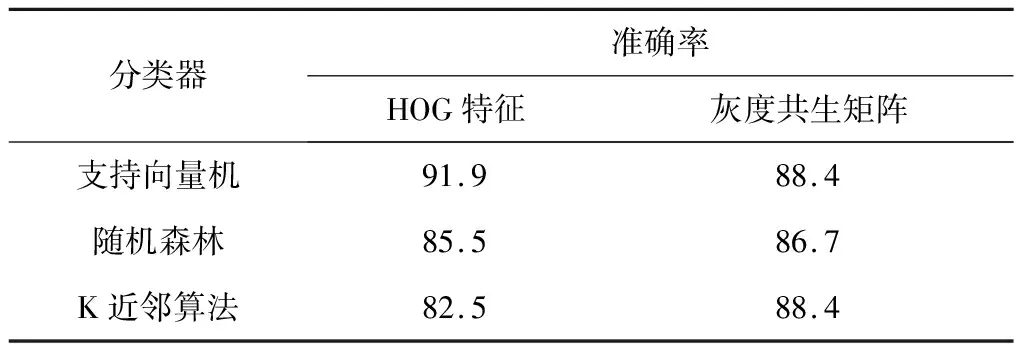
表1 基于特征提取的煤矸石图像分类方法准确率
3 基于卷积神经网络的煤矸石图像分类
3.1 数据扩充
共拍摄863张煤矸石图像,选取690张图像作为训练集、173张图像作为测试集。从训练集中随机选取部分图像,采用旋转、缩放、添加噪声、随机裁剪方法对样本进行扩充。本文直接调用Keras内部集成的ImageDataGenerator函数扩充图像样本,扩充参数设置:旋转角度为40°,水平、垂直平移距离均为0.2倍图像长度,图像缩放比例为0.2。扩充后训练集中样本为3 200张,然后将扩充样本与其标签一一对应。
3.2 基于浅层卷积神经网络的煤矸石图像分类
搭建基于Keras深度学习框架的浅层卷积神经网络模型,如图5所示。该模型为4个卷积层、4个池化层、2个全连接层的网络结构,4个卷积层与4个池化层交替连接,每个卷积层均采用ReLU激活函数。输入图像大小为150×150,卷积核大小为3×3,4个卷积层卷积核数分别为32,32,64,64,卷积核步长为1。选取最大池化方式,池化的邻域大小为2×2。在卷积层和池化层提取完图像特征后,连接2个全连接层,全连接层输出大小依次为64,1。采用Sigmoid激活函数实现图像输出。
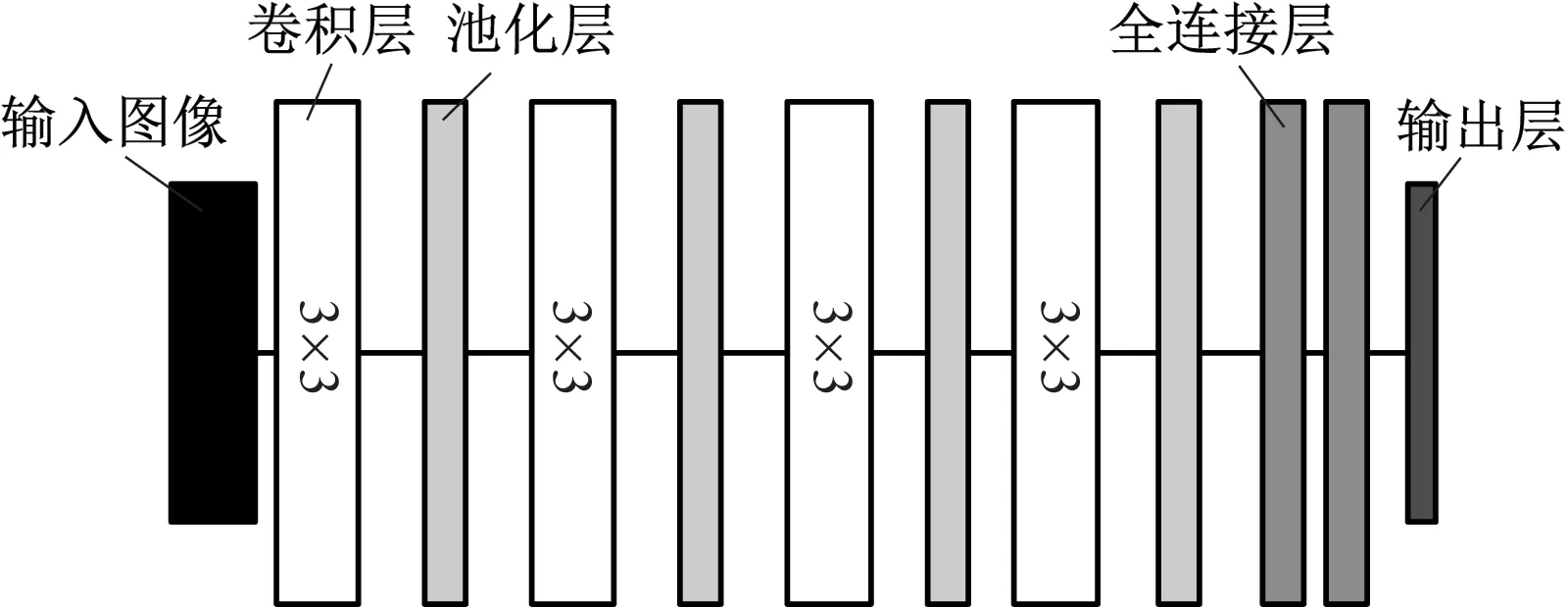
图5 浅层卷积神经网络结构
卷积神经网络采用按批次训练的方法,训练批次为16,采用交叉熵损失函数及rmsprop优化器,训练迭代50次。浅层卷积神经网络在煤矸石分类过程中的损失函数及分类准确率如图6所示。可看出模型在训练集上拟合效果较好,随着迭代次数增加,损失函数逐渐收敛,准确率最高达98.44%;在测试集上准确率最高达92.5%,但分类效果不稳定,损失函数震荡较大,分析认为可能是由于样本扩充后相关度太高而导致出现一定程度的过拟合现象。可见浅层卷积神经网络不能很好地实现煤矸石分类,需引入更深层的神经网络结构。

(a)损失函数

(b)准确率
3.3 基于VGG16网络的煤矸石图像分类
由于样本采集和图像拍摄需耗费大量时间和精力,所以引入迁移学习方法来解决样本不足问题。迁移学习可通过加载之前训练完成的模型,结合样本库进行再次训练,从而优化分类效果。基于ImageNet数据集预训练得到的网络权重中包含对多种图像的特征表达,可用于不同的识别任务[12]。因此本文采用基于ImageNet数据集预训练的VGG16网络[13-15],如图7所示。网络模型在1 000个类别的ImageNet数据集中进行预训练。采用预训练后的VGG16网络模型权重(不包括全连接层)作为初始权重。

图7 VGG16网络结构
为了进一步提高VGG16网络进行煤矸石分类时的稳定性和准确率,对最后一个卷积块进行微调,在保留预训练中提取特征表达的同时,结合煤矸石图像样本库进一步拟合所提取的特征。微调过程中设置学习率为10-4,选用随机梯度下降方法进行优化,网络Dropout设置比例为0.5,训练50次,测试集与训练集样本比例为4∶1。
VGG16网络在煤矸石分类过程中的损失函数及分类准确率如图8所示。可见VGG16网络收敛速度快,稳定性好;随着迭代次数增加,损失函数逐渐收敛,分类准确率逐渐提高,对测试集的分类准确率最高可达99.7%,明显优于浅层卷积神经网络。
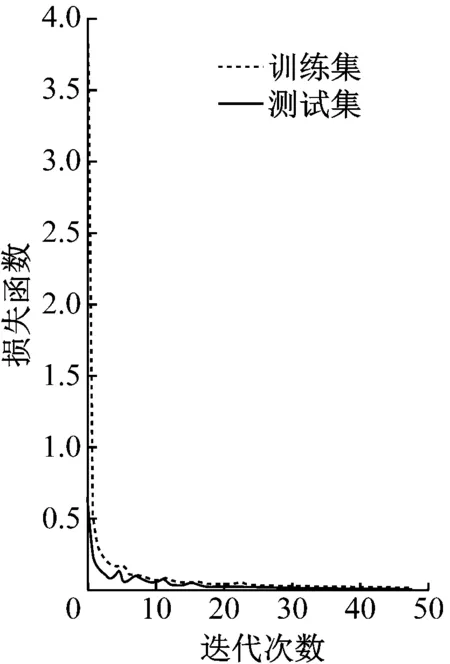
(a)损失函数

(b)准确率
4 结语
针对煤炭开采中混入大量矸石的情况,提出了基于机器视觉的煤矸石图像分类方法。模拟带式输送机运输煤炭场景,拍摄了黑色背景下的煤矸石图像,采用基于距离变换的分水岭算法将煤与矸石从黑色背景中分割出来,再分别采用基于特征提取和基于神经网络的分类方法,对图像中煤与矸石进行分类识别。研究结果验证了基于VGG16网络的煤矸石图像分类方法准确率高于基于特征提取或浅层卷积神经网络的方法。
