基于编辑距离的汉语中介语语音计算分类
2020-04-12于爽冉启斌史晴琳
于爽 冉启斌 史晴琳

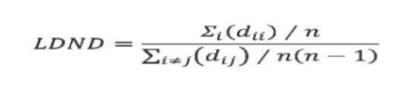
摘 要:借鉴ASJP模式的语档距离计算方法,对25个母语背景的汉语学习者的中介语语音表现进行分类,并借助统计学和系统发生学方法,绘制汉语普通话与25种中介语距离关系树图。这些树图均显示出,母语在同一语系的中介语基本分布在同一总分支上,反映出母语对中介语的形成产生主导影响。同时,树图中也存在母语属于同一语系的中介语分开、或是与其他语系中介语归入同一小分支的现象。由此看出,不同语系的母语影响大小有一定区别,偏误共性对距离关系的形成也会产生较大影响。
关键词:汉语中介语;编辑距离;计算分类;ASJP
一、引言
就目前的研究现状来看,国内学界对汉语作为第二语言学习者的中介语语音研究,方法多种多样,并取得了丰硕的成果。施光亨通过记录语音资料的方法,统计出阿拉伯学生在习得汉语时的语音偏误[1](P106-112)。傅氏梅、张维佳采用对比听辨的方法,从听感和发音能力两个方面,考察了越南学生中介语中的声母偏误[2](P69-80)。李红印在研究泰国学生学习汉语的语音偏误时,借助了实验语音学的声学分析方法[3](P66-71)。梅丽利用一至两年的跟踪实验,对日本学习者学习汉语卷舌声母的语音变异情况进行了探讨[4](P97-105)。张林军从感知的角度,采用实验手段,阐释了日本留学生的声调习得情况[5](P9-15)。冉启斌、于爽的《汉语语音偏误的特点与模式——基于25种母语背景学习者的偏误条目数据的分析》一文,利用528条偏误条目数据,归纳了第二语言学习者中介语语音中的偏误特点,如学习者声母、韵母、声调在汉语学习中发生偏误的情形并不是均衡的,学习者个别语音表现受母语影响,会呈现出不同于其他学习者的个性偏误表现等[6](P417-432)。
本文以冉啟斌、于爽整理出的各母语背景的偏误条目为依据[6],借鉴ASJP模式的语档距离计算方法,分析不同母语背景学习者的中介语语音之间的距离关系,并对25种母语背景带有偏误的汉语中介语语音进行分类,探讨影响中介语分类的各种因素。
“相似性自动判断程序数据库(Automated Similarity Judgment Program,网址是https://asjp.clld.org/)”,简称“ASJP”,是马普研究院建立的“跨语言关联(Cross Linguistic Linked Database)”在线数据库之一。该数据库收集了庞大的数据量,其第19版数据库收录了世界语言中的9788个语档,语档涉及到世界范围的5499种语言。同时,项目团队在该数据库基础上,发展出一套完备的相似度计算方法,并开放提供计算所需的软件程序。ASJP模式的语言距离及相似度计算,在世界语言研究中产生了广泛影响。其中,Wichmann et al探究了不同语系语言的发源地[7](P50-60);Holman et al考察了不同语言的分化年代[8](P841-875);Müller et al通过对第16版数据库资源进行距离计算,制作了6895个语档的世界语言分类树图[9](P1-67);江荻采用莱文斯坦编辑距离计算的方法,以斯瓦迪士100核心词为材料,对195种藏缅语族语言或方言进行了自动分类[10](P62-80)。在汉藏语系研究领域,维希曼、冉启斌对65个汉语方言语档做了系统发生学分析[11](P4-13);赵志靖、江荻通过计算元、辅音间的距离,再计算编辑距离,从而对数种藏语方言进行了分类[12](P43-48)。在第二语言习得领域,崔萌等以汉语水平考试(HSK)作为研究对象,通过引入汉语与学习者母语的距离计算,分析了学习者的母语差异对汉语作为第二语言习得的影响,指出语言距离与汉语习得呈负相关关系[13](P280-288)。总的来说,在目前以多个母语背景学习者的中介语研究中,借助距离计算方法对中介语语音表现进行的分析,还较少有人涉及。
本文首先确定40个能够典型体现汉语语音特点的词语,按照冉启斌、于爽归纳的偏误条目,对25种母语背景的中介语进行转写;然后,利用ASJP工具计算不同中介语之间的距离和相似度,并采用聚类分析、系统发生学分类方法对中介语进行分类。在此基础上,探讨学习者中介语受其母语影响的程度、不同母语背景学习者中介语语音之间的关系。
二、研究设计
(一)研究对象
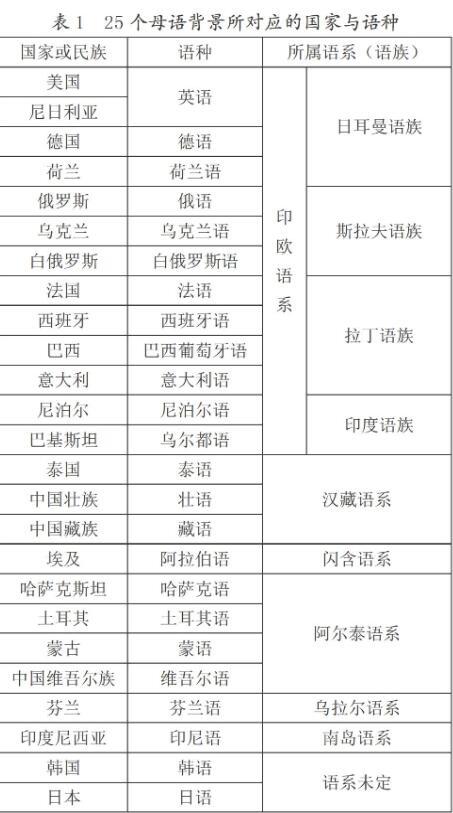
本文以美国、俄罗斯、韩国、泰国、西班牙、德国、荷兰、法国、日本、埃及、乌克兰、哈萨克斯坦、巴西、意大利、土耳其、蒙古、白俄罗斯、芬兰、尼泊尔、巴基斯坦、尼日利亚、印度尼西亚等22个国家和中国壮族、藏族、维吾尔族3个少数民族的学习者为研究对象,对以上25个母语背景的学习者的中介语语音表现与汉语普通话进行相似度和距离计算。这25个国家或民族的母语语种相应为:英语、俄语、韩语、泰语、西班牙语、德语、荷兰语、法语、日语、阿拉伯语、乌克兰语、哈萨克语、巴西葡萄牙语、意大利语、土耳其语、蒙语、白俄罗斯语、芬兰语、尼泊尔语、乌尔都语、尼日利亚(英语)①、印度尼西亚语、壮语、藏语、维吾尔语等。以上25种语言与语种的情况如表1所示:
以上25个国家或民族分布于世界七大洲中的五个大洲、所涉及母语语种涵盖了九个主要语系中的六个语系,研究对象的覆盖范围较为均匀。以上25种母语背景所形成的汉语中介语,不仅能够很好地体现出世界汉语学习者中介语的特点,而且对探究学习者母语与中介语的关系也具有较高的学术价值。
(二)中介语语档的构建
ASJP数据库以“斯瓦迪士100核心词”为内容,尽可能多地收集世界上各种语言或方言中不少于斯瓦迪士核心词表中40个词的语音形式。这40个词均是经过检测和论证得到的、用于距离和相似度计算的最稳定的词。以往的研究表明,在第二语言学习中,汉语的22个声母(含零声母)、39个韵母发生偏误的情况并不均衡,如声母和韵母中最易产生偏误的前5种语音类型是:舌尖后声母r,舌尖后声母zh、ch、sh,舌尖元音(-?、-?),复韵母,鼻音韵尾-n、-ng等。因此,根据汉语语音的实际情况,本文单独设计了能够典型体现汉语语音特点的中介语词表。该词表共包含40个词语,具体如表2所示:
该词表的设计主要遵循两个原则。一是词表对汉语普通话单念和语流中的语音音位(音素)进行了全方位的覆盖,它既包括普通话单念时的22个声母(含零声母)、39个韵母和4个声调,也包括语流中的三声变调、轻声、儿化、“一、不”的变调等音变现象。二是词表着重凸显了二语学习中容易发生的语音偏误。根据冉启斌、于爽的研究结论[6],该词表包含了更多的舌尖后音声母、舌尖元音、[er]韵母、前后鼻音、送气音等,目的是为了更充分地展现学习者中介语之间的特点和差异。
为了构建25个母语背景学习者学习汉语的中介语语档,本文将上述40个词语按照冉启斌、于爽研究中的偏误条目描述进行国际音标转写,使之成为带有偏误特征的语音表现。比如,泰国学习者的常见偏误主要有将舌面擦音x[?]发为[s]、将舌尖后音发为舌尖前音、将送气塞擦音发为同部位的擦音等,因此,可以将泰国学习者“大学”一词的国际音标转写为[ta su?],“中秋”一词的国际音标转写为[tsu? ?i?u]。之后,再将带有学习者偏误发音的中介语和汉语普通话的国际音标标音形式转换为ASJP码的标写形式,最终形成汉语普通话和25个中介语共26个语档。
(三)语档相似度与距离计算方法
我们之所以将26个语档由国际音标转换为ASJP码的标写方式,是因为它可以使计算得到的语档距离和相似度更加符合语言之间的实际距离和相似度。语档转写后,使用ASJP的工具软件,计算各语档的LDND距离,形成距离矩阵。具体的距离计算方法为“莱文斯坦编辑距离(Levenshtein Distance)”,简称“LD”。所谓的“莱文斯坦编辑距离”,就是由一个字符串转换为另一个字符串所需的最少操作次数。这一计算方法只允许插入、删除、替换三种操作。ASJP模式的距离计算有不同的方法,如“归一化莱文斯坦距离(Levenshtein Distance Normalized)”、“归一化莱文斯坦距离商(Levenshtein Distance Normalized Divided)”等,前者简称“LDN”,后者简称“LDND”。本文计算语档之间的距离均采用LDND这一方法。LDND距离计算的公式是:
最后,依据距离矩阵进行计算分类,形成统计学系统聚类树图和系统发生学树图等。
三、汉语中介语语音的计算和分类
(一)汉语中介语语音的距离与相似度
在形成距离矩阵后,本文首先将25种中介语与汉语普通话的LDND距离数据单独提取出来,并计算出各中介语与普通话之间的相似度。具体数据如表3所示(为便于观察,将汉语普通话放在第1行):
如表3所示,在25种中介语中,藏族学习者的中介语与汉语普通话距离最近,为23.65,两者的相似度达到了76.35%;而日本学习者的中介语与汉语普通话距离最远,为63.96,两者的相似度最低,仅有36.04%。维希曼、冉启斌曾根据世界语言语档中语言变体之间的关系层级问题,给出了不同关系层级的参考指标:如果两种语言的相似度大于50.90%,则属于相同方言;相似度在50.90%~18.64%之间的,属于相同语族之间的语言;相似度在18.64%~2.37%之间的,属于相同语系不同语族之间的语言;低于2.37%的,则属于不同语系[14](P126-135)。根据这一参考指标可以看出,藏族、白俄罗斯、尼日利亚等12个民族或国家的学习者的中介语相似度均大于50.90%,若将中介语视作是一种独立的世界语言,它们的语音表现都接近汉语方言;这其中就包括了母语与汉语在同一语系的藏族、泰国、壮族学习者。而其余13个民族或国家的学习者的中介语相似度,均在50.90% ~18.64%之间,若将中介语视作是一种独立的世界语言,它们的语音表现都接近于汉语同一语族的语言。同时,从表3还可看出,同样为英语背景,尼日利亚跟美国学习者的中介语与汉语相似度差别较大,其原因可能是在于我们所收集到的尼日利亚偏误条目较少、不够完备,因此,没有完全体现出尼日利亚学习者的特点。
我们还将以上相似度的数据绘制为折线图,具体如图1所示:
从图1可以看出,25种中介语的下降较为平缓,仅在白俄罗斯、泰国和蒙古处有轻微的陡坡;大部分中介语相似度紧密集中在40%~60%之间。由此可以得知,汉语学习者的语音发音表现较为集中和一致。
(二)汉语中介语语音的聚类分析
我们又采用了SPSS软件,对26个语档的距离数据进行分析。这里采取平均联接(组间)的方法进行系统聚类,其度量标准为平方欧氏距离,从而得到Ward联接的分类树状图。具体如图2所示:
从图2可以看出,该树状图可以分为四大分支。在第一大分支中,汉语普通话正好位于最上端,藏语中介语与汉语普通话处于同一末端节点上,其次是泰语与壮语中介语。与之较近的第二大分支为意大利语、乌尔都语、俄语、法语、白俄罗斯语与尼泊尔语中介语,其中,意大利语与乌尔都语中介语、俄语与法语、白俄罗斯语与尼泊尔语中介语分别在同一末端节点上。其次较远的第三大分支又被分成两个分支:一个为土耳其语、蒙语、芬兰语中介语分支;另一个则为乌克兰语、巴西葡萄牙语、西班牙语等印欧语系中介语主导(其中的哈薩克语为阿尔泰语系、印尼语为南岛语系)的分支。最远的第四大分支里包括了韩语、日语、美国英语、维吾尔语、阿拉伯语、荷兰语中介语,它们形成了一个非常特别的组合。
在图2的基础上,我们可以对汉语学习者的中介语语音表现进行一个初步分析。
第一,学习者的中介语的语音形成受到自身母语的影响,而且其影响程度较强。总体来看,中介语总的分支分布基本符合其对应母语在世界语言中的语系分布。与汉语普通话在同一末端节点的为母语同是汉藏语系的藏语中介语,而壮语、泰语也同属汉藏语系,以其为母语背景的中介语也与它们在同一分支。土耳其语与蒙语的中介语分属在同一末端。同时,第三大分支中除哈萨克和印尼语外,其他中介语均为印欧语系中介语的集合。而日语、韩语语系未定,以其母语为背景的中介语则处于距汉语最远的一个大的分支中;虽然在地缘上中、日、韩距离非常接近,但并没有拉近汉语与二者中介语的距离。
第二,虽然学习者中介语语音的形成受到了自身母语的影响,但并未成为影响其语音表现的充分条件。冉启斌、于爽指出,在学习者中介语中,某些音素会产生一致的偏误表现,如舌尖后音最易产生的偏误是发为舌叶音等[6]。因此,汉语学习者的偏误共性对于中介语的形成也产生了较大影响,母语背景原本属于不同语系的中介语,可能会由此突破母语的语系分类而归属于同一分支内。从图2可以看出,部分中介语并没有按照其母语的规律归入相应语系的分支中,甚至有些语系的中介语散落在不同的分支中,从而形成了与汉语普通话距离远近不一的情况;或者是虽同属一个语系、但属于不同语族的语言,其中介语却被重组到了同一个末端内。比如,母语同属于印欧语系,意大利语、法语、乌尔都语等的中介语,就位于汉语最近的一个大分支内;而乌克兰语、西班牙语、德语等的中介语,位于更远的分支上;美国英语、荷兰语则距离汉语最远。再如,母语同属于阿尔泰语系,哈萨克语中介语与土耳其语中介语并未进入同一个末端;维吾尔语中介语则更是处在距汉语最远处的分支中。此外,印欧语系中各语族的语言,其形成的中介语也并未能进入同一个末端,反而是进行了重新组合,如拉丁语族中的意大利语与印度语族中的乌尔都语的中介语位于同一末端,而拉丁語族的另一语言法语则与斯拉夫语族的俄语的中介语位于同一末端等。
四、汉语中介语语音的系统发生学分析
上文主要运用了统计分析的方法,对26个语档进行了聚类分析;下面,我们将采用分子生物学中的发生学分类法,对汉语中介语语档进行分类。通常情况下,学习者的中介语之间彼此独立,不具有发生学关系,不过,本文主要是借鉴发生学的分类方法,为其提供一个分类的参照。笔者使用分子生物学软件MEGA7(Molecular Evolutionary Genetics Analysis),采用邻接树法(Neighbor-Joining Tree),构建26个语档的分类关系,从而得到有根分类树图。具体如图3所示:
经过发生学分类法绘制的树形图,与聚类分析得到的结果大体一致,同时也有一定的区别。最外围的是美国英语和韩语中介语分支,维吾尔语中介语单独在一个分支。其次,是日语中介语与荷兰语中介语相连的分支,这一点与聚类分析的结果有所不同。再次,是含有汉语普通话的一个大分支,这一分支中汉语与藏语中介语仍然在同一分支,与之相接近的是泰语与壮语中介语分支,这些均与聚类分析的结果一致;不过,白俄罗斯语中介语成为单独一个分支,同归在这一分支之内,这一点又与聚类分析不同。芬兰语单独成为一个分支。接下来的一个分支被分为两个大组。靠上的一组基本与聚类分析一致:乌克兰语和巴西葡萄牙语中介语、西班牙语与德语中介语在同一分支,不同的是哈萨克语中介语与蒙语中介语成为了单独的分支。靠下的一组是与聚类分析分歧最大的部分。这一分支中,最外部的土耳其语成为单独一个分支,其次是乌尔都语分支,意大利语与其分开成为下一层单独一个分支,内部是俄语和法语、阿拉伯语与尼泊尔语两个小分支。
为了能更清晰地显示26个语档的分支关系,本文又在MEGA中绘制了放射状的无根分类树图。具体如图4所示(见下页):
在放射状模式中,各语档的分支关系更为明显。图4中,芬兰语中介语处在单独的分支,其余语档则分为三簇:以汉语为代表的汉藏语系中介语分支(其中也出现了非汉藏语系的白俄罗斯语的中介语),韩语、日语、美国英语等中介语的分支,剩下的语档则组成的一个大的分支。最后这一大的分支以印欧语系中介语为主导,阿尔泰语系的中介语亦夹杂其间。
由系统发生学邻接法形成的两种树状图,再次印证了上文的分析;同时,我们还可以从其与聚类分析的不同之处,发现一些新的特点。
第一,系统发生学树图再次印证了学习者的中介语的语音形成受自身母语的影响,但不同语系的影响强弱有一定区别。维吾尔语、蒙语、哈萨克语、土耳其语同属于阿尔泰语系,但以它们作为母语背景的中介语分别进入了不同分支中,而且它们之间相距较远。印欧语系中的斯拉夫语族——俄语、乌克兰语、白俄罗斯语,以其母语为背景的汉语中介语也出现了同样的状况。而接近汉语的汉藏语系其他语言、印欧语系除斯拉夫语族的其他语言的中介语,则较为集中。这种现象也可以归结为印欧语系的语言自身的影响力较大,在一定程度上更容易影响汉语习得。
第二,与母语负迁移相比,地理上的位置远近对中介语的形成影响较小。虽然藏语、壮语中介语与汉语普通话距离较近,但同样属于中国少数民族的维吾尔语中介语则距离汉语较远,蒙语中介语甚至位于距离汉语最远的一个大分支内。地缘、文化相近的乌克兰、白俄罗斯、俄罗斯也有相同的情况。反观各小分支中,乌克兰与巴西、尼日利亚与印度尼西亚、荷兰与日本、美国与韩国,它们甚至不在一个大洲内,但它们学习者的中介语则位于同一分支下。至于出现这一现象的原因,上文亦曾提及,主要是在于这些学习者的中介语内部存在着一定的偏误共性,如美国与韩国学习者的声母zh、ch、sh均产生了偏误,而且其偏误表现均为“舌叶音[?]、[?]、[?]”。由系统发生学邻接法形成的两种树状图也再次印证了这一分析。
五、结语
本文采用ASJP的计算模式和方法,并结合汉语普通话,对25个母语背景的汉语中介语语档进行了距离计算。通过对统计系统聚类和系统发生学分类进行的分析,进一步深化了对汉语中介语的认识。首先,大部分学习者的中介语水平较为集中,如果将之视作一种独立的世界语言,可以达到接近汉语方言或与汉语同语族的水平。其次,汉语学习者的自身母语的影响在中介语的形成中起到了主导作用,但不同语系的影响大小有一定区别,如印欧语系母语的影响就比较大。除母语影响之外,汉语学习者的偏误共性也对中介语的形成产生了一定影响。当然,本文的研究也存在不足之处,部分国家或民族(如尼日利亚)的偏误条目收集不够完备,或许会对分析的结果产生一定影响。今后将针对这些国家集中收集学习者实际的语音表现,并通过实验语音学方法测量,获得更为完备的偏误条目,以期完善距离分析计算研究。
参考文献:
[1]施光亨.对阿拉伯学生进行汉语语音教学的几个问题[J].语言教学与研究,1980,(2).
[2]傅氏梅,张维佳.越南留学生的汉语声母偏误分析[J].世界汉语教学,2004,(2).
[3]李红印.泰国学生汉语学习的语音偏误[J].世界汉语教学,1995,(2).
[4]梅丽.日本学习者习得普通话卷舌声母的语音变异研究[J].世界汉语教学,2005,(1).
[5]张林军.日本留学生汉语声调的范畴化知觉[J].语言教学与研究,2010,(3).
[6]冉启斌,于爽.汉语语音偏误的特点与模式——基于25种母语背景学习者的偏误条目数据的分析[J].世界汉语教学,2019,(3).
[7]冉启斌.基于词汇声学距离的语言计算分类实验[J].民族语文,2020,(3).
[8]Holman,E.W.,Brown,C.H.,Wichmann,S.et al.Automated Dating of the Worlds Language Families Based on Lexical Similarity[J].Current Anthropology,2011,(6).
[9]Müller,A.,Velupillai,V.,Wichmann,S.et al.ASJP world language tree of lexical similarity:Version 4 (October 2013).
[10]江荻.藏緬语谱系的自动分类实验[A].《中国民族语言学报》编委会.中国民族语言学报(第一辑)[C].北京:商务印书馆,2017.
[11]索伦·维希曼,冉启斌.ASJP模式的汉语方言计算分析——以65个汉语方言语档为例[J].现代语文,2019,(5).
[12]赵志靖,江荻.基于编辑距离的语言分类研究[J].语言研究,2020,(6).
[13]崔萌,张卫国,孙涛.语言距离、母语差异与汉语习得:基于语言经济学的实证研究[J].世界汉语教学, 2018,(2).
[14]索伦·维希曼,冉启斌.语言与方言的区分层级——ASJP模式的核心词汇距离计算再分析[J].南开语言学刊,2019,(2).
基金项目:国家社会科学基金重大项目“中国境内语言核心词汇声学数据库及计算研究”(19ZDA300);南开大学中央高校基本科研业务费项目“数字中文实验室建设启动项目”(63202924)
Quantitative Classification on Phonological Transcriptions for Interlanguages:
with Mandarin as Target Language
Yu Shuang1,Ran Qibin2,Shi Qinglin3
(1.School of Foreign Languages, Tian University of Technology and Educaion, Tianjin 300222;
2.School of Literature, Nankai University, Tianjin 300071;
3.School of Foreign Languages, Tianshi College, Tianjin 301700)
Abstract:Drawing on the pholonogical distance calculation method of the ASJP, with the speech performance in the interlanguages of 25 learners with native language backgrounds classified, tree diagrams of the distance relationship between Chinese Mandarin and 25 interlanguages above mentioned are drawn in this paper, using statistical and phylogenetic methods. Several tree diagrams indicate that the interlanguages whose native languages belong to the same language family are largely distributed over the same general branch, reflecting the dominant influence of the native language on the formation of the interlanguage. However, there are also the cases that the interlanguages of the same language family are grouped into the same sub-branch with those of other language families. The analysis reveals that the degree of the native languages influence on the interlanguage differs across language families, and that the commonality of speech errors can have a large impact on the formation of distance relations.
Key words:Chinese interlanguage;edit distance;quantitative classification;ASJP
作者简介:1.于 爽,女,天津职业技术师范大学外国语学院助教,汉语国际教育硕士。
2.冉启斌,男,南开大学文学院教授,博士生导师,文学博士。
3.史晴琳,女,天津天狮学院外国语学院讲师,文学硕士。
