大数据采集与存储技术生态及方案选型的探讨
2020-04-12吴超
吴 超
江苏省通信管理局
0 引言
大数据时代,如何才能从丰富的数据矿藏中开采出更多价值?以石油开采来类比大数据分析,首先考虑的不是如何炼油(分析数据),而是如何获取优质原油(高效地采集与存储数据)。
本文围绕三个问题展开:在大数据环境下,传统的数据采集、存储方式还适用吗?现有哪些优质高效有前途的技术方案?我们该如何选择?
1 大数据的挑战
数据采集方面,传统工具有ftp、scp、rsync、wget、curl等,它们通常源于少量主机之间的文件传输或同步的业务需求,虽然在断点续传、压缩传输或者自动同步等方面有一定造诣,但这些基于抽样分析的方法采集海量数据时如同“在汽车时代骑马一样”,效率、性能低下,不能满足业务需求。
数据存储方面,传统文件系统适应不了纷繁的数据类型,同时关系型数据库执迷于精确的ACID属性,导致大量非结构化、混杂的数据被丢弃,无法利用。
综上,传统的以技术为中心的数据处理方式已不能满足业务需求。为了实现对海量数据的分布采集、高效存储、交互查询、实时分析、深度挖掘等功能,需要采取以数据为中心的新方案。
2 新技术的应用
根据信息通信行业咨询翘楚Gartner公司近年来发布的新兴技术成熟度曲线,业界对大数据概念的炒作已进入尾声,大数据技术正在走向“成熟”阶段。
开源社区、商业公司、学术界、极客们围绕着数据处理提出了种类繁多的解决方案,并站在自己立场上,对技术方案发表了各种声音的争论。基于软硬件投资、学习成本的考量,我们希望采用“廉价的”“有前途”的技术方案;根据开源“圣经”《大教堂与集市》中经典理论,“如果有足够多的beta测试者和合作开发者,几乎所有问题都会很快显现,然后自然有人会把它解决”;参考业界实践派专家的观点,新技术兴衰是社区、企业、用户之间“战略、利益、技术、实践”综合较量的结果。
基于以上三点,为了全面、发展地看待各方案,首先站在用户、开发者、外围支持者的视角,从用户规模、技术水平、兼容性三个维度,对备选技术进行生态评估;然后筛选出使用广泛、开发活跃、兼容性好的方案进行技术介绍;最后在方案对比的基础上,结合应用场景提出相关建议。
2.1 分布采集方案
目前常见的大数据采集技术包括Flume、Kafka、Splunk Forwarder、Logstash、Fluentd、Chukwa、Scribe等,我们该如何取舍?
(1)生态评估
对上述技术生态进行评估如表1所示。
(2)技术对比
根据上述评估,我们选取Flume、Kafka两种优秀的方案,在技术分析的基础上,对适用场景及优缺点进行深入分析。
Flume是Apache社区中一款可高效收集、聚合、移动海量日志数据的工具。不同数据源的数据“原油”流经Flume这个“水槽”(Flume单词的原义),最后汇入数据存储系统中。Flume工具部署、维护简单,可根据业务需求进行灵活扩展。
Kafka是一个分布式的消息“发布—订阅”系统,它作为消息生产者与消费者之间的代理人(broker)解耦了这两个角色,实现了消息的高效“按需供给”。Kafka 被广泛用于采集网页访问量、网页内容等活动数据以及服务器CPU 使用率、服务日志等运营数据。
功能方面,上述两种方案都比较成熟,详细比较见表2。

表2 备选采集方案功能对比
性能方面,数据采集属于“I/O密集型”业务,即相比与CPU、内存、网络流量等因素,系统I/O受限于低效的磁盘随机读写物理性能,更易成为整个采集系统吞吐率的性能瓶颈。Kafka、Flume均支持在内存中进行数据传输,此时两者性能都极高。下面仅讨论当数据规模超过集群内存容量,需要进行大量磁盘读写操作时的场景:(A)Kafka精妙的设计保证其进行高效的顺序读写操作,在到达磁盘物理性能瓶颈之前,写磁盘平均速率随着输入数据吞吐率的增加线性增长;(B)Flume在实时性、吞吐率上比Kafka逊色不少,但可通过调整批量处理参数(Batch Size),以增加时延的代价,一定程度上提高吞吐率;(C)两者都支持通过增加硬件数量的横向扩展方式,提高系统吞吐率。
(3)应用建议
方案选型时,需综合考虑业务需求、预算经费、自身技术等因素:(A)当仅需要对服务器访问记录、网络设备告警等运维数据进行采集、分析时,预算充裕的用户推荐Splunk、Datadog等一站式商业解决方案;有一定技术基础、想节约预算的用户可考虑Flume、Logstash;(B)当数据源既有日志数据又有流数据,从方便运维、扩容的角度,建议使用Flume;(C)如果采集数据将被多个业务系统使用、业务实时性要求很高或者需要错峰、流控时,建议使用Kafka;(D)Kafka与Flume也常常“强强联合”:一种典型应用将Kafka作为数据源,Flume作为采集代理;此外也可以先部署Flume1.6.0版本采集数据,今后业务有实时性要求时,将Kafka作为一种传输渠道(channel),把采集后数据汇入下游存储系统;此外还可以将Flume采集的数据存入Kafka主题中供业务程序拉取。
具体部署时,需要权衡高吞吐与低时延、容错性与冗余性这两对矛盾。例如,通过数据压缩传输、分批次传输的方法,以增加时延的代价,降低对系统网络、I/O等资源的消耗。此外,数据采集过程中也可以尝试发挥人的作用,例如为准确、及时地采集宏观经济数据,Premise公司采用线上线下相结合的方式。其中线下部分鼓励大众贡献各种价格数据,这种众包方式受到资本青睐。
2.2 高效存储方案
对海量数据采集、清洗后,我们既要确定采用什么方式将数据长期保存起来,又要考虑以哪种方案组织管理数据以及供业务查询使用,还得权衡是否需要以内存存储、管理来提高性能。下文将分别对大数据存储系统、数据库技术方案进行评估比较。
(1)生态评估
大数据存储系统多得令人眼花缭乱,既有云服务商Amazon的 S3、老牌存储服务商EMC的系列产品和解决方案,又含开源社区的HDFS、Swift、Ceph,还包括高校孵化出的Alluxio。对这些技术生态进行评估如表3所示。

表3 大数据存储系统生态评估
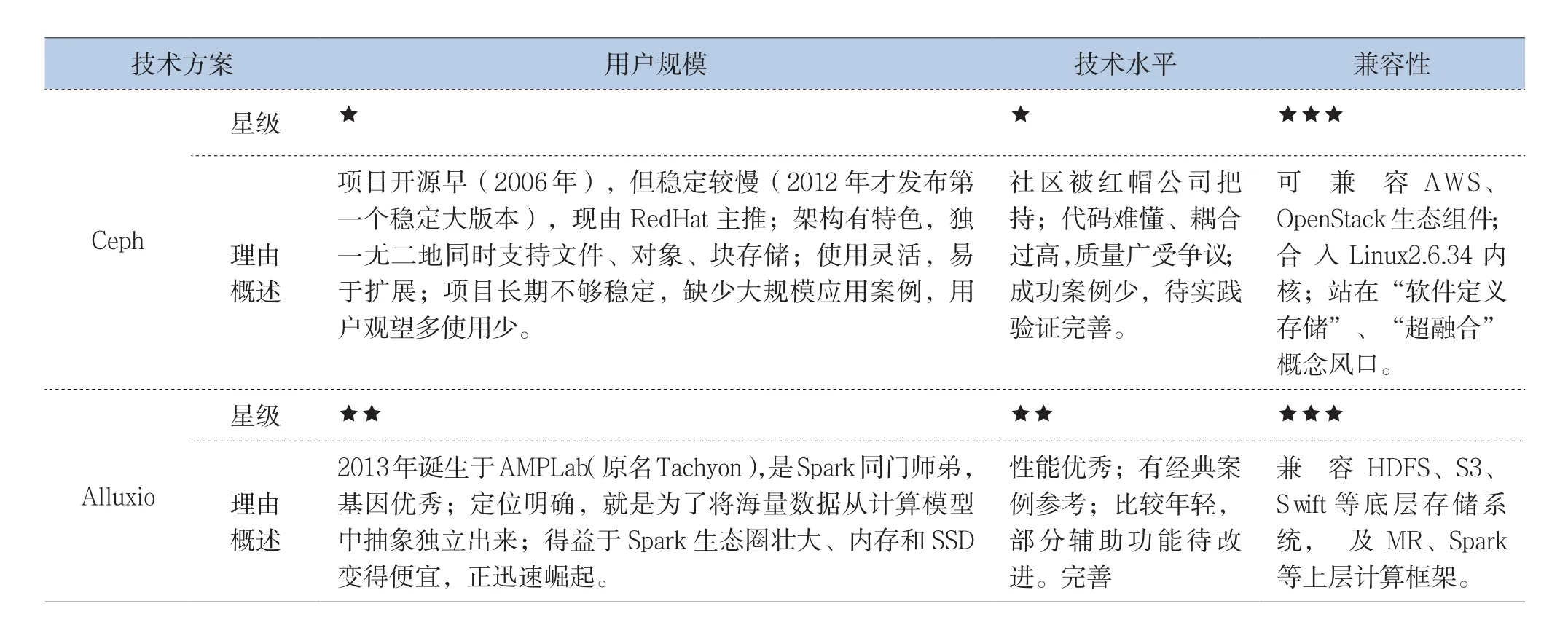
技术方案 用户规模 技术水平 兼容性星级 ★★★★★C e p h 理由概述项目开源早(2006年),但稳定较慢(2012年才发布第一个稳定大版本),现由R e d H a t主推;架构有特色,独一无二地同时支持文件、对象、块存储;使用灵活,易于扩展;项目长期不够稳定,缺少大规模应用案例,用户观望多使用少。社区被红帽公司把持;代码难懂、耦合过高,质量广受争议;成功案例少,待实践验证完善。可 兼 容A W S、O p e n S t a c k生态组件;合入L i n u x 2.6.34内核;站在“软件定义存储”、“超融合”概念风口。星级 ★★★★ ★★★A l l u x i o 理由概述2013年诞生于A M P L a b(原名T a c h y o n),是S p a r k同门师弟,基因优秀;定位明确,就是为了将海量数据从计算模型中抽象独立出来;得益于S p a r k生态圈壮大、内存和S S D变得便宜,正迅速崛起。性能优秀;有经典案例参考;比较年轻,部分辅助功能待改进。完善兼 容 H D F S、S 3、S w i f t等底层存储系统, 及 M R、S p a r k等上层计算框架。
大数据数据库技术外延更广。按适用业务场景分为事务型(追求高效读写的事务处理能力)、分析型(追求高吞吐、高扩展能力)、兼顾型;按数据存储模型主要包含关系型、键值对型、面向列的、面向文档、图形数据库;按设计原则又分为ACID、C/A/P三选二、兼顾型。典型的大数据数据库演进及分类如表4所示。
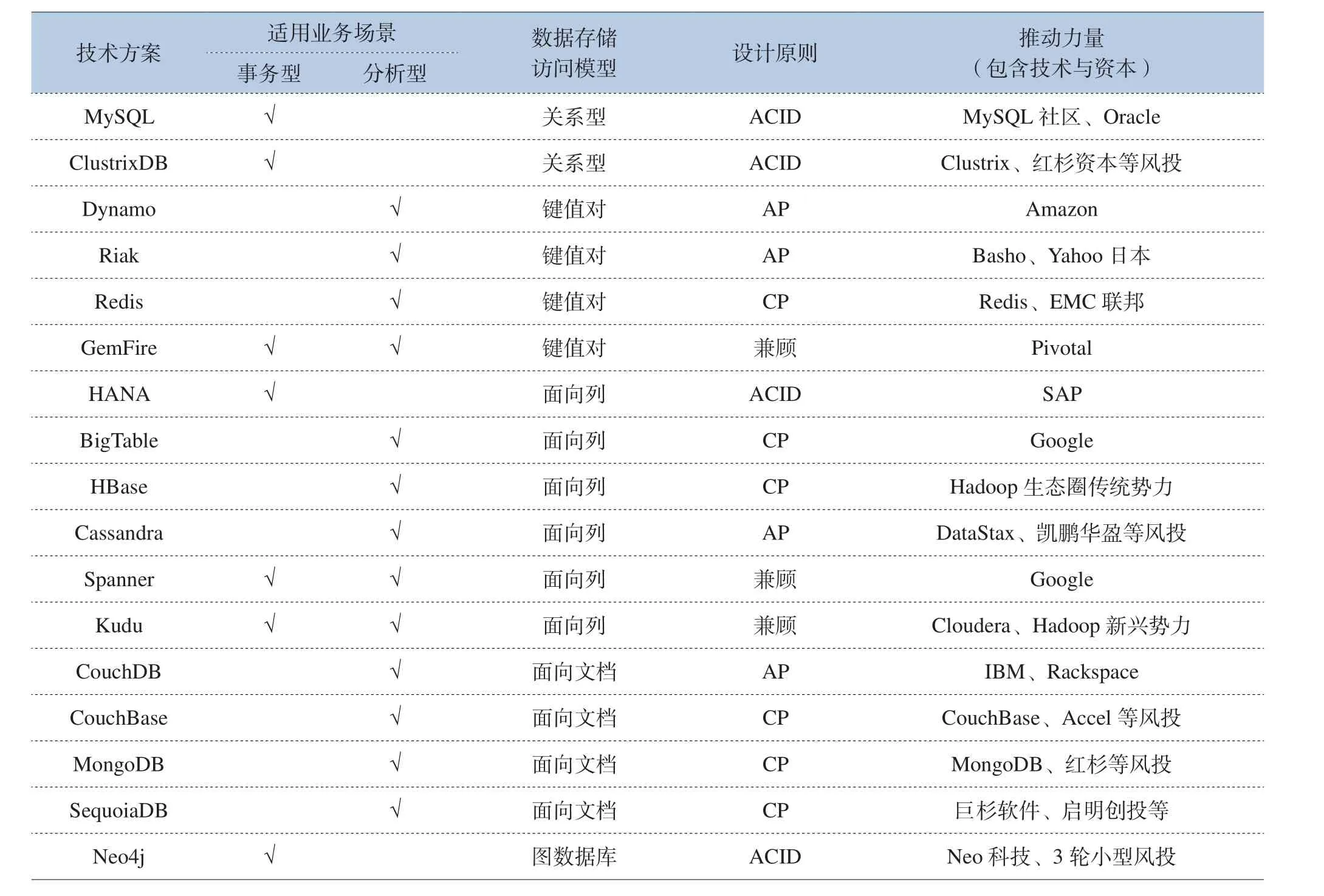
表4 常见大数据数据库分类
根据上表分类,将选择具有代表性的扩展MySQL、HBase、Cassandra、MongoDB、Redis、Kudu进行生态进行评估,详见表5。
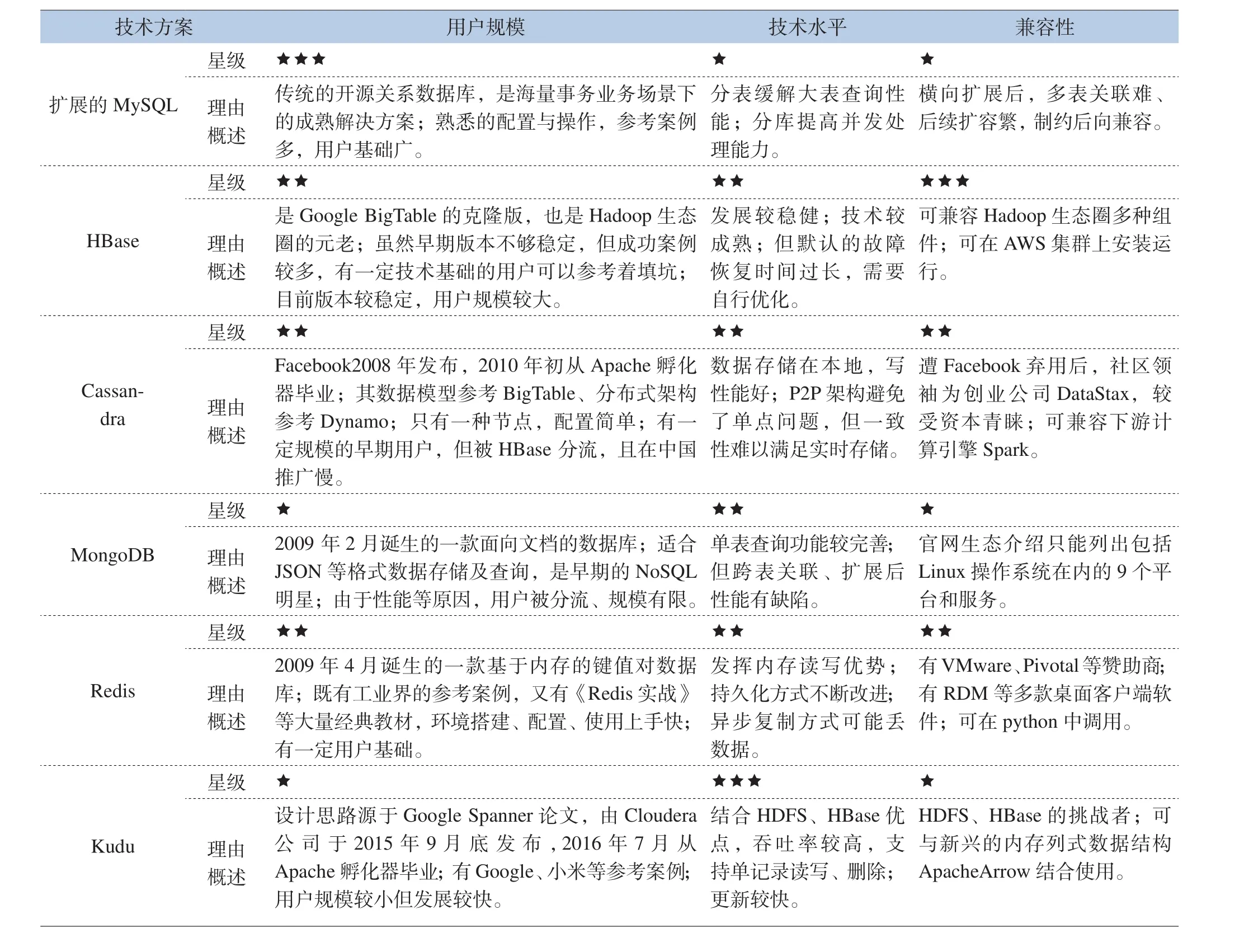
表5 大数据数据库技术生态评估
(2)技术对比
根据上述评估,将选取S3、HDFS、Alluxio、HBase几种优秀的方案进行详述。
S3是Amazon公司AWS云存储服务的重要组成部分,是对象存储的典型代表。S3采用扁平的数据组织结构,将对象数据保存在“存储桶”(Bucket)中,并给用户提供基于HTTP的REST风格数据访问、操作接口。该存储形态能够方便地进行横向扩展,以适应大量用户高并发访问的场景;但是不支持随机位置读写操作,只能读取、写入或覆盖整个文件。
HDFS起源于Google的GFS论文,是一种易于扩展的分布式文件系统。HDFS基于“移动计算比移动数据更经济”的设计理念,可构建在大量廉价机器上,节约大量建设扩容投资;另一方面,其具备可靠数据容错能力,有效减少运营维护成本。HDFS伴随着Hadoop生态圈的壮大不断完善,目前已支持Parquet存储格式,可对嵌套数据进行高效列式存储,即将合入ErasureCoding纠错编码使冷数据冗余成本大幅减少。
HBase起源于Google的BigTable论文,是构建在HDFS之上高性能、高可靠、易扩展的大数据列族式存储数据库。其适合存储海量稀疏数据,可以通过版本检索到历史数据,解决了HDFS不支持数据随机查找、不适合增量数据处理、不支持数据更新等问题。常用于存储超大规模的实时随机读写数据,如存储互联网搜索引擎数据。
Alluxio原名Tachyon,是以内存为中心的虚拟分布式存储系统。其核心思想是将存储与计算分离。Alluxio介于底层存储系统(如HDFS、Amazon S3、OpenStackSwift)与上层计算框架(如Spark、MapReduce、Apache Flink)分离,使Spark等框架更专注于计算,从而达到更高的执行效率。
上述四种大数据存储方案详细比较如表6所示。

表6 数据存储方案比较
(3)应用建议
方案选型时,首先需要综合考虑业务需求变化、原始数据规模、实时分析需求、存储周期、软硬件开发及运维成本等因素,再进一步明确存储方案:(A)对业务中断时间、业务恢复时长、数据一致性要求都极高的金融等行业,可根据业务量考虑购买EMC、IBM等厂商的存储软硬件产品,在此基础上选择Teradata、IBM的方案做进一步数据挖掘;(B)对于启动资金有限、需求灵活多变、规模可能激增的创业公司,建议以“轻资产”的方式运营。可购买Amazon、微软、阿里等的云服务,集中精力进行业务开发和市场推广;(C)对于TB数据级别数据,一致性要求不高并且需要进行实时查询的场景可考虑Redis,一致性高且追求高吞吐量的场景可考虑GemFire。不建议用低性能的CouchBase、Memcached;(D)对于PB数量级存储、计算、虚拟化服务提供商,建议搭建自己的OpenStack环境,采用Swift、Cinder等存储方案,以快速满足定制化需求;(E)对于PB—ZB级别历史数据、需要进行关联查询、批量计算的业务场景,建议搭建Hadoop环境,采用HDFS存储方案;(F)对于PB级别数据、追求低延迟随机读写的场景,例如对海量网页数据做进一步提取、修改的,建议采用HBase数据库。非专家级用户不推荐在生产环境使用Kudu、Kylin等新兴方案。
在此基础上,根据业务场景进一步选择合适的存储模式:(A)如果业务首要考虑数据完整性与可靠性,行存储具备了天然的优势,列存储只有增加磁盘并改进软件后才能接近该目标;(B)以长期保存数据为主的应用,可考虑写入性能较高的行存储模式;(C)需要对大数据做深入挖掘分析的场景,特别是数据源为扁平的关系型数据或者复杂的嵌套数据时,建议使用读取性能优秀的列式存储。
具体部署时,可根据自身预算水平、技术能力,选择服务商一揽子解决方案,集成商负责建设维保,利用开源框架自建自维,在开源代码基础上自主开发等建设与维护模式。
3 小结与展望
本文回顾了主流的大数据采集与存储技术诞生、发展、对抗、衰落的历史,梳理了其中老牌的商业公司、初创的明星企业、大小的开源社区、学术界、极客之间的纠葛与合作,从生态角度进行了宏观对比与评估;同时本文选取优秀、通用的方案进行了较详尽的介绍,并结合具体应用场景给出了技术选型及应用部署的相关建议。
展望未来,物联网、智能制造等新兴产业的崛起,将提供更大规模、更多类型的海量数据源,大数据采集方案将结合更廉价的采集设备、更灵活的组网部署、更有效的数据清洗;同时随着内存、SSD等高效存储介质的性能提升,内存存储技术将进一步发展与普及;业务形态方面,大数据技术将与商业智能、机器学习等新兴技术更紧密地结合,采集、存储等底层技术将随之进一步演进。
