改进的YOLOv3算法在道路环境目标检测中的应用
2020-04-10胡贵桂
胡贵桂


摘 要:近年来,社会经济持续高速的发展,人均汽车占有量迅速增加。为了避免车辆追尾等事故发生,结合道路环境下目标检测的难点及要求,文章选择基于卷积神经网络的YOLOv3算法,并针对YOLOv3中使用的k-means聚类算法初始时随机选择质心这一不稳定性以及原本的darknet53网络层数较低导致精度不是很高的问题,引用k-means++聚类算法对k-means聚类算法进行优化,并将darknet53替换成特征提取能力更强的resnet101,进行算法优化。实验结果显示优化后的算法mAP提高了12.2%,基本符合实际应用检测的精度要求。
关键词:道路环境;目标检测;YOLOv3
中图分类号:TP301.6 文献标识码:B 文章编号:1671-7988(2020)05-117-05
Abstract: In recent years, with the rapid development of social economy, the per capita car ownership has increased rapidly. In order to avoid accident, such as rear-end collision, combined with the difficulties and requirements of target detection in road environment, this paper choose YOLOv3 algorithm based on convolution neural network. Aiming at the problem of the accuracy is not very high caused by the instability of K-means clustering algorithm which selects the center of mass in the initial randomly and the low layers of darknet53 network.referencing k-means++ clustering algorithm to optimize k-means clustering algorithm, and using resnet101 whose feature extraction capability is stronger to replace darknet53, optimize algorithm. Experimental results show that the optimized algorithm mAP improves 12.2%, which basically meets the accuracy requirements of practical application.
Keywords: Road environmental; Target detection; YOLOv3
引言
随着社会经济持续高速的发展,人均汽车占有量迅速上升,传统交通行业存在的缺陷日益突出,包括交通事故频发、道路交通拥挤、环境污染严重等问题,因此,车辆智能化迫在眉睫。而车辆智能化首要任务是让车辆理解周围的场景,知道周围的目标“是什么”,即实现道路环境下的目标检测。
由于道路环境复杂,且车辆是在运动中实时采集场景图片。因此,道路环境下的目标检测存在以下三大难点:1)由于行车过程中光照条件和相对角度等因素变化,使目标的特征发生一定变化,导致目标检测产生漏检和误检;2)由于目标姿态改变(如人站立、行走骑行时的姿态不同)、局部遮挡(如前车被后车部分遮挡)等非刚性形变,导致目标检测产生漏检;3)存在同类目标的特征差别较大(如山地自行车和共享单车都属于自行车,但特征差别较大),不同类目标的特征差别较小的情况(如电瓶车和自行车),导致目标检测产生误检[1]。
传统的目标检测技术使用手工设计的特征,提取方法泛化性能较差,难以提取到更抽象的特征,所以在道路环境中,使用传统的目标检测技术,难以达到检测精度的要求。近年来,研究者们发现卷积神经网络可以自动提取图像更深层次的特征,克服了手工设計特征的缺点,具有更强大的特征表达能力,泛化能力强、鲁棒性较好。因此,卷积神经网络很好的解决了复杂的道路环境下采集的相同目标一致性较差的问题,非常适用于道路环境下的目标检测。
1 目标检测算法
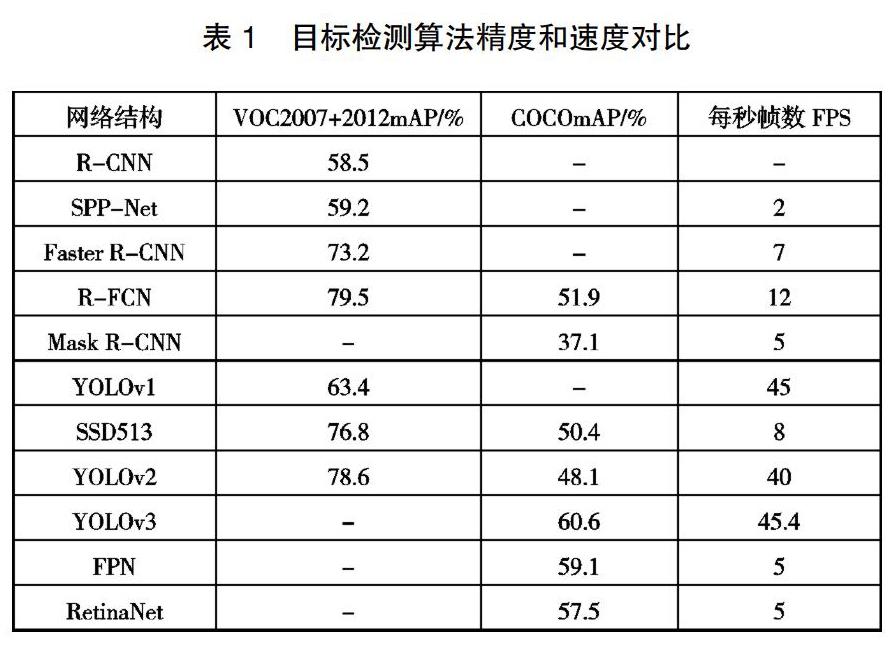
根据检测思想的不同,基于卷积神经网络的目标检测算法主要分为两类:基于候选区域的Two-stage(两步检测)目标检测算法和基于回归的One-stage(单步检测)目标检测算法[2]。基于候选区域的目标检测算法包括R-CNN[3]、SPP- Net[4]、Fast R-CNN[5]、Faster R-CNN[6]、R-FCN[7]、Mask R-CNN[8]等,该算法从R-CNN到Mask R-CNN,都采用了“候选区域+CNN+分类回归”这一基本思路,不断在检测精度和速度上进行改进。但整体而言,这些网络的实时性较差,很难满足实际需求。基于回归的目标检测算法包括YOLO系列[9]~[11]、SSD[12]、FPN[13]以及RetinaNet[14],该算法基本思路是给定输入图像,将特征提取、目标分类以及目标回归的所有过程都整合到一个卷积神经网络中完成,很好地改善了目标检测算法的实时性,使目标检测在实际中的应用成为可能。目标检测算法在VOC2007、VOC2012和COCO数据集的性能如表1所示。
从表中可以看出YOLO系列的检测速度远高于其他网络框架,这对于神经网络应用于实际生活有重要的意义,并且YOLOv3相比YOLOv1、YOLOv2等精度有了较高提升。而道路环境下的目标检测对实时性要求较高,因此,YOLOv3是综合性能较好,最适合本文的一种方法。
2 YOLOv3算法改进
本文针对YOLOv3中使用的k-means聚类算法初始时随机选择质心这一不稳定性以及原本的darknet53网络层数较低导致精度不是很高的问题,对k-means聚类方法进行优化,并将原本的darknet53替换成特征提取能力更强的resnet101,进行算法优化提高检测精度。
2.1 k-means优化改进
在YOLOv3中使用k-means聚类算法,统计anchors的参数,对bbox的初始位置进行确定。而k-means聚类算法随机选取k个数据点作为初始的聚类质心,这种随机的方式只能找到局部最优化类,而不是全局最优化类,影响了算法的聚类效果。
为了避免简单k-means聚类造成的影响,本文引用k- means++聚类算法,让初始质心尽可能的远而不是随机产生,对原算法进行优化。具体步骤如下:
首先确定k值,即数据集经过聚类最终得到的集合数,从数据集中随机选取1个数据点作为第一个聚类质心。接着,对于数据集中的每一个点计算其与第一个质点的距离,选取最远的点作为第二个质点,依此类推,假设已经选取了n个初始聚类质心(0 2.2 基于残差网络特征提取的YOLOv3 加深卷积神经网络,能加强特征提取能力,但同时梯度消失的现象也会更明显,网络的训练效果反而下降,而残差网络[15]允许网络尽可能的加深,其结构如图1。因此,本文使用resnet101替换原本的darknet53,以此来提升yolov3的检测性能。 残差模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该输出和卷积的输出做算术相加得到最终的输出,如式(1)所示,x是所示结构的输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。残差结构人为制造了恒等映射,让整个结构朝着恒等映射的方向收敛,确保最终的错误率不会因为深度的变大而越来越差。 每个残差单元通常由几个叠加的卷积层Conv、批量正则化层BN、以及ReLU激活组成。在式(3)中F(x,wi)代表残差学习映射,其中σ代表ReLU激活函数,在这里省略了偏置项,在式(2)中当F和x维度不同时,添加偏置Wx,其好处是不会增加训练参数。 如表2所示,为残差网络典型的三个堆叠层数,残差网络将整个卷积层分为5个部分,每个部分输出的特征图大小以及通道数相同,只是在每个部分的堆叠方式卷积堆叠数量有区别。考虑到网络堆叠层数过多对检测速度的影响,在改进YOLOv3时,残差网络层数的选取上做了最优的选取,选用特征提取能力较强,且又不失检测速度的ResNet101,改进后的网络结构如图2所示。 由于YOLOv3对小目标检测的能力较弱,在改进的过程中也对此做出了相应的调整。经深层卷积之后的表征较强,但容易丢失细节信息,如果能结合深层特征与浅层特征,那么特征图的对于小目标的特征描述将会得到提升。从此思想出发,本论文采用特征金字塔的方式融合浅层特征与深层特征,将残差网络中深层输出作为全局语义信息的引导,使用双线性插值得到与低层特征图相同尺度的特征映射,通过级联的方式,融合了多尺度的上下文信息。在经过1×1的卷积降维之后,进行对融合之后的特征图的检测识别操作。 3 目标检测实验及结果分析 本文所有实验在windows 10系统,Intel i9-9900k处理器,Nvidia 2080ti GPU,在Anaconda的开发环境上,配置Tensor Flow的深度学习开源框架。 3.1 数据集制作 3.1.1 图像采集 本文数据采集的第一个思路,就是有效利用网络公共资源,从公开的数据库采集图像。本文的目标主要为道路环境中常见的行人person、自行车bicycle、电动车(摩托车)motorcycle、汽车car、客车bus、货车trucks、交通灯traffic light。训练集图片主要是在Pascal VOC、MS COCO和网络图片下载,制作生成15600张图像的数据集。具体数量如表3所示。 3.1.2 图像标注 图像标注的基本目标是根据图像的视觉内容和获得的指导信息来确定对应的文本语义描述[16]。本论文中的部分数据未标注,需要使用LabelImg工具对图片进行标注。标注如图3所示,将图像中出现的7类目标都尽可能的标注出来,其他类别不做标注。 3.2 模型训练 模型训练就是模型中的参数拟合的过程。本文产用监督学习,通过损失函数来计算网络输出分数和期望分数之间的误差,利用得到的误差不断修改网络内部的参数来减小这种误差。 训练数据大约15600张图片,总共训练了200000 batches,每个batches有64张图片,在英伟达Titan V服务器上大约训练了18小时。图4为每个batches训练的平均损失统计图,可见在训练达到200000 batches,平均损失趋近于0,说明训练达到了收敛。 3.3 检测结果及分析 本文选用的评价指标为目前主流的mAP(mean Average Precision)指标。mAP指标为所有目标类别AP(平均精度)的平均值,而每个目标类别的AP是在该目标类别的每一个不同查全率值(包括0和1)下,选取其大于等于这些查全率值时的查准率最大值,以查全率(recall)为自变量,该查全率下的最大查准率(precision)为因变量,绘制曲线,曲线下的面积作为该目标的AP,如图5所示。 式中,TruePositives为被正确识别为目标类的数目,FalsePositives为被错误识别为目标类的数目,FalseNagatives为目标类被错误识别或为被识别的数目。 为了测试优化后的YOLOv3目标检测方案的效果,分割训练数据制作成测试集,并用同一测试集测试改进前后的算法精度。对7种类别中的每一类分别统计平均精度(AP),7类目标检测的AP结果如图6所示,改进前的mAP为54.87%,与YOLOv3在COCO数据集下的mAP基本吻合;改进后的mAP为67.07%,比改进前提升了12.2%。 如上图所示,YOLOv3的性能得到了很大的提升,原始的网络结构能适应常规的检测目标,而重新使用新的聚类方法以及优化网络结构后,提高了模型的泛化性能和检测精度,随着网络层数较原始的网络有所加深,使得特征提取能力加强,改进后的YOLOv3在测试数据中的检测效果,对于一些比较小的特征以及叠加严重的目标,检测效果都比较突出,基本符合实际应用的检测精度要求,实现了道路环境下的目标准确分类。 4 结论 本文针对道路环境下目标检测的难点及要求,选择YOLOv3算法作为本文的算法,并针对YOLOv3中使用的k-means聚类算法初始时随机选择质心这一不稳定性以及原本的darknet53网络层数较低导致精度不是很高的问题,引用k-means++聚类算法对k-means聚类方法进行优化,并将darknet53替换成特征提取能力更强的resnet101,进行算法优化,优化后的算法mAP提高了12.2%,基本符合实际应用检测的精度要求。 参考文献 [1] 李旭冬.基于卷积神经网络的目标检测若干问题研究[D].电子科技大学, 2017. [2] 谢娟英, 刘然. 基于深度学习的目标检测算法研究进展[J/OL]. 陕西师范大学学报(自然科学版), https://doi.org/10.15983/j.cnki. jsnu.2019(05): 1-9/2019-09-26. [3] Girshick R, Donahue J, Darrell T, Malik J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[P]. Computer Vision and Pattern Recognition(CVPR),2014 IEEE Confe -rence on, 2014. [4] He Kaiming, Zhang Xiangyu, Ren Shaoqing, Sun Jian. Spatial Pyra -mid Pooling in Deep Convolutional Networks for Visual Recogni -tion[J]. IEEE transactions on pattern analysis and machine intelli -gence, 2015, 37(9). [5] Girshick R. Fast R-CNN[A].IEEE International Conference on Computer Visio[C]. Santiago: IEEE, 2015, 1440-1448. [6] Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transac -tions on Pattern Analysis & Machine Intelligence, 2015, 39(6): 1137-1149. [7] Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks [J]. 2016, 379-387. [8] He K, Gkioxari G, Dollar P, et al. Mask r-cnn[A]. Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017: 2980- 2988. [9] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[A]. 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE Computer Society, 2016: 429-442. [10] Redmon J, Farhadi A. YOLO9000: better, faster, stronger [A]. IEEE Conference on Computer Vision and Pattern Recognition[C]. Hono -lulu: IEEE, 2017, 6517-6525. [11] Redmon J, Farhadi A. Yolov3: An incremental improvement [DB/ OL]. https://arxiv.org/abs/1804.02767. 2018-4. [12] Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector [A]. European Conference on Computer Vision [C]. Sprin -ger, 2016, 21-37. [13] Lin T Y, Doll R P, Girshick R, et al. Feature Pyramid Networks for Object Detection[A].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2117-2125. [14] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detec -tion [A] Proceedings of the IEE EInternational Conference on Computer Vision, 2017: 2980-2988. [15] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition [A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition [C]. Las Vegas: IEEE, 2016, 770- 778. [16] 盧汉清,刘静.基于图学习的自动图像标注[J].计算机学报,2008, (9):1629-1639.
