基于轻量网络的近红外光和可见光融合的异质人脸识别
2020-04-10汪海涛
张 典,汪海涛,姜 瑛,陈 星
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
近年来,人脸识别在公共安全领域得到了广泛的应用.由于近红外成像技术提供了一种有效且直接的解决方案来改善极端光照条件下的人脸识别性能,因此它被认为是异质人脸识别中最突出的替代传感模式之一.此外,已证明近红外成像对可见光照射变化不太敏感,因此适用于远距离甚至夜间的人脸识别.它已被广泛用于面部识别或授权应用,例如安全监视和电子护照.然而,由于可见光传感器的大规模部署,大多数面部图像仅由可见光图像组成,而探测图像通常以近红外模式进行.因此,对近红外和可见光人脸图像之间的鲁棒匹配的需求,也称为近红外与可见光异质人脸识别问题,已经引起了很大关注.
首先,由于近红外光和可见光图像是从不同的光谱域捕获的,因此它们具有较大的外观差异.因此,在可见光图像数据上训练的深度卷积网络不包含近红外光图像光谱信息,因此基于可见光图像训练的深度网络模型不能很好地处理近红外光图像.如何利用百万级别的大规模可见光图像人脸数据来增强近红外光和可见光人脸图像的跨域识别[1,2],这是一个值得深究的问题.其次,受益于网络数据,我们可以轻松收集数百万张可见光脸部图像.但是通常在互联网上几乎无法找到配对的近红外光脸部图像.大规模收集和配对近红外光和可见光人脸图像的数据仍然很昂贵.如何在近红外与可见光的小型数据集上应用深度学习仍然是一个核心问题.
本文提出了一种深度卷积网络方法来学习不同光谱域中面部不变的特征,其中包含近红外光和可见光人脸图像的身份信息.我们的方法是使用单个网络将近红外光和可见光图像映射到紧凑的欧几里德空间,使得嵌入空间中的近红外光和可见光图像直接对应于面部相似性,再通过跨光谱的拟合函数,让网络更多的关注面部身份个体间的差异,从而减少跨域带来的影响,使同一个面部身份的特征更加收敛,不同面部身份的特征保持距离.
卷积神经网络在图像分类领域有着强大的优势,目前已有很多公司如旷视、商汤、海康威视等在人脸检测和识别中使用卷积神经网络.然而由于卷积神经网络的参数和计算量大问题,使得主流的做法是在云平台上部署高性能的计算服务,再在前端采集数据后传回云平台进行计算.虽然这个方法可行,但是由于需要网络传输来实现异步处理,这给实际应用带了不稳定因素.与此同时因为半导体的发展,现在的嵌入式设备和移动端设备也有了不错的性能.在这样的背景下研究轻量级深度卷积网络的跨域人脸识别算法,使移动设备可以直接运行深度学习算法,有着很好的工业应用价值和研究意义.
2 原理与方法
本文属于研究基于轻量级深度卷积网络的近红外光和可见光图像融合的人脸识别算法.
传统的卷积网络参数量计算量庞大,无法在嵌入式平台部署,针对这个问题本文研发了一种轻量级网络[3-6],通过修改卷积结构,使得在大幅度减少参数的同时,又能保持传统卷积网络的性能.
与可见光不同之处在于近红外光图像数据集稀少,如何在小样本数据集上训练出一个红外光与和可见光图像都可以使用的人脸识别模型,使近红外光人脸识别达到可见光人脸识别的效果,是本文的主要研究点.
在夜间监视摄像头的应用中,多用近红外光捕获个体的探测图像,并且必须从可见光谱图像库中识别出个体.虽然可见光人脸识别是一个广泛研究的主题,但近红外光图像中的人脸识别仍然是一个相对未开发的领域.近红外光图像既拥有可见光图像的鲁棒性点又拥有比可见光图像更好的灰度对比度信息,因此近红外光图像更适合做人脸识别.
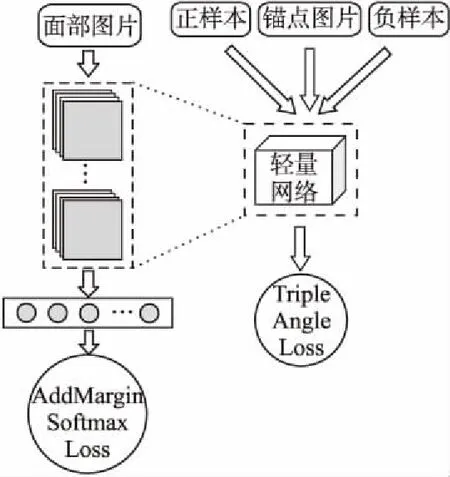
图1 轻量网络训练与迁移学习流程图Fig.1 Lightweight network training and transferlearning flow chart
鉴于卷积神经网络在可见光图像人脸识别、物体分类等方面有很好的表现,因此本文试图通过构建大量的三元组来扩充我们的训练数据.通过使用MS-Celeb-1M数据集进行预训练轻量网络,为网络提供先验知识.再使用特定的可见光与近红外光数据集微调网络模型,以学习到深度不变的特征[14].如图1所示.
2.1 轻量级神经网络
当前主流的卷积神经网络层数多,参数量大,其计算量也十分庞大,使得在网络在嵌入式平台上的部署比较困难.本文提出一种轻量型的lightfacenet卷积网络,通过将传统卷积用深度可分卷积和1×1的逐点卷积代替.
传统卷积使用h1*w1*di*dj,如图2所示,应用卷积来生成一个H*W*dj维的图时,其计算的代价为h1·w2·di·dj·H·W.
深度可分卷积用来实现单层通道的滤波,1×1的逐点卷积用来实现通道间的线性组合,如图所示,这样两种卷积的组合就可以几乎完成传统卷积的工作.但是其成本为h1·w2·di·H·W+di·dj·H·W.
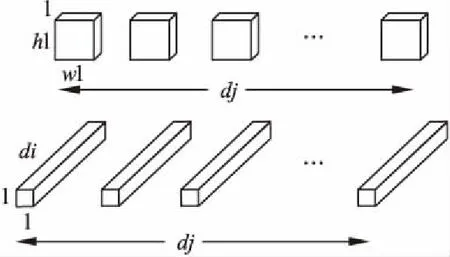
图3 深度可分卷积与1×1的逐点卷积结构图Fig.3 Depth-separable convolution and 1×1point-by-point convolutional structure map
(1)
如当卷积核为h1=w1=3时,N为128时,其计算的成本会比传统的卷积网络小8到9倍,因此深度可分卷积和逐点卷积的组合在输出维度较高的时可以有效的将计算量减少.
为了进一步减少参数量,减少算法对硬件资源的需求,本文将逐点卷积更改为通道稀疏链接的方式,让每一次卷积操作仅在对应的通道组中,再通过通道混洗的方式让不同的卷积组能够学习到不同组的输入数据,使得卷积层的输入和输出全关联.这样使网络的计算量和模型的表达能力有了很好的平衡.
2.2 改进softmax函数
softmax(交叉熵损失函数)是深度学习中使用最广泛的损失函数之一,并且已经被证明在人脸识别任务中对异常值的抑制是十分有效的.但是因为softmax函数是由逻辑回归推广到多分类的方法,在其计算的过程中只考虑多分类任务是否分类正确,这并不是像SVM(支持向量机)那样寻找一个最佳的分类决策面.在传统的方法中,通常使用欧式距离来判断身份相似度存在很大的局限性.通过softmax函数划分的人物,会存在两个不同身份的人,比同一身份的人的距离更近,从而达不到分类效果.
(2)
实验表明在传统的交叉熵损失函数存在很大的类内距离,通过交叉熵损失函数增加类内约束,可以使网络有更好的分类效果.在本方案中对交叉熵损失函数进行了修改,从原来对向量距离的计算转变为向量角度计算,提出了AddMargin softmax Loss损失函数,由WTx=‖W‖·‖x‖·cosθ可以得出向量的相乘是包含角度信息的.将softmax函数中的权重限制为‖W‖=1,b设为0,使得网络从对权重W的学习转变为权重与特征角度θ的学习.之后再通过L2归一化将‖x‖的特征为s,通过权重和特征的归一化,使得网络的预测只取决于权重与特征角度θ的学习,所有的特征都会分布在半径为s的超球面上.在交叉熵损失函数中增加一个超参数,用做权重与特征角度θ的边缘惩罚,从而做到增加类别间的的边缘角度的同时,也使得类别内部更加的紧凑,使得面部识别有更优的性能.
(3)
2.3 微调网络模型
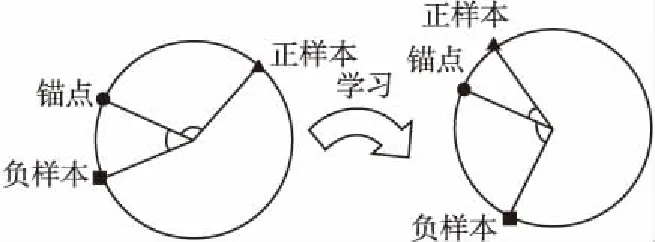
图4 三元组通过三重角度损失优化图Fig.4 Triad through triple angle loss optimization map
通过使用神经网络的学习,使描点与正样本的距离变小,描点与负样本的距离变大.因此本文提出三重角度损失函数,可以表示为如下公式:
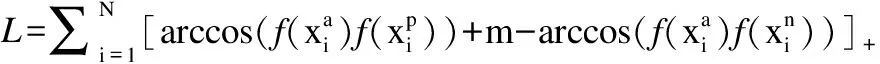
(4)
Triple Angle Loss函数可以分为两个部分,第一部分表示锚点与正样本太远的惩罚,第二部分表示锚点与负样本太近的惩罚,m为阈值,当锚点与负样本小于m时,会在loss函数优化的时候逐渐拉大.通过这样的损失函数,可以在全连接层提取人脸特征后,将特征值输入到三重角度损失层,就可以用SGD来拟合可见光与近红外光的人脸图像域的间隙.
经过测试,通过单一类型锚点的三元组,会使得可见光图像与近红外光图像的相对关系失衡,并不适用于跨域的数据学习[9].本文通过使用跨域的两种类型的三元组,将近红外人脸图像做为锚点,再把与锚点是相同ID的可见光图像做为正样本,与锚点不同Id的可见光图像做为负样本.为了使可见光与近红外光域的相对关系平衡,本文采用类似的方法,将可见光图像做为锚点,而正样本与负样本用近红外光图像.在两种类型跨域的三元组约束下,神经网络会更多的关注个体间的差异,从而减少跨域带来的影响.因此在高维空间中,无论人脸图像是来自与哪种光谱域,面部图像都会与其身份相同的人脸ID更接近而远离身份不同的人脸ID.
为了训练图像三元组,本文将训练好的可见光人脸识别网络设置为三通道的网络结构,三通道共享网络中每一层结构和参数.本文使用全连接层输出128维的特征,在最后的全连接层输出层之后,将三个通道的输出都输入到三重损失层中.在三重损失函数的约束下,网络可以学习区分不同的身份类别的权重[17,18],无论它们是属于近红外图像还是可见光图像.
3 实验方法
3.1 数据集
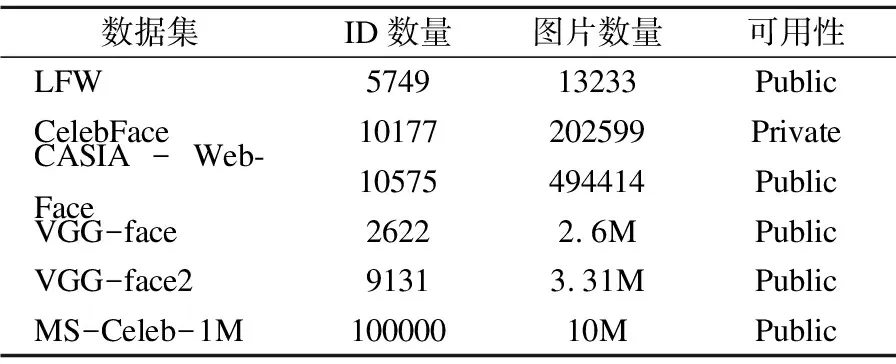
本文实验中主要使用vggface2和MS-Celeb-1M数据集[11,12]作为网络的预训练集.vggface2包含3百多万图片,9131个类别,平均每个类别有360张图片,这个数据集覆盖大范围的姿态、年龄和种族,用于训练身份识别不同姿态、年龄有很好的鲁棒性.MS-Celeb-1M包含1千多万张图,10万个类别,平均每个类别有100张图片,这是目前类别数量最大的数据集.通过这两个数据集,可以充分的发挥深度神经网络的优势.拟合到比较合适权重模型,也为后面的迁移学习提供了良好的基础.表1为目前常用可见光人脸数据集.
表1 可见光人脸数据集表
Table 1 Visible face data set table
数据集ID数量图片数量可用性LFW574913233PublicCelebFace10177202599PrivateCASIA-Web-Face10575494414PublicVGG-face26222.6MPublicVGG-face291313.31MPublicMS-Celeb-1M10000010MPublic
本文实验中主要使用vggface2和MS-Celeb-1M数据集作为网络的预训练集.vggface2包含3百多万图片,9131个类别,平均每个类别有360张图片,这个数据集覆盖大范围的姿态、年龄和种族,用于训练身份识别不同姿态、年龄有很好的鲁棒性.MS-Celeb-1M包含1千多万张图,10万个类别,平均每个类别有100张图片,这是目前类别数量最大的数据集.通过这两个数据集,可以充分的发挥深度神经网络的优势.拟合到比较合适权重模型,也为后面的迁移学习提供了良好的基础.
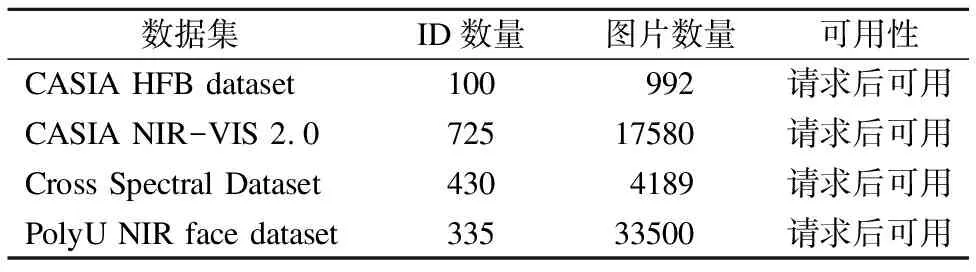
在迁移学习中,需要使用异质人脸数据集,表2为现有的异质人脸数据集,本文主要使用CASIA NIR-VIS 2.0 Face数据集[13],数据集主要包含近红外图像与可见光图像的异质数据集,其中包含725个类别,每个类别有1~22个可见光图像和5~50个近红外光图像.图像之间没有一对一的相关性,其中包含了相同身份的人的各种变化,如光照、表情、距离、姿态,是否戴眼镜,这对异质人脸识别带来了挑战[15].
3.2 数据预处理
数据集中每个身份的图片有几十到几百张,图片的品质参差不齐包含了很多干扰项.如果不对数据集做预处理就直接将图像输入到网络中训练,会导致网络学习不充分,不能准确的对人脸特征进行辨别.再者因为图像的人脸姿态各异,角度不同,如果不对图片进行姿态矫正,就会给网络学习与收敛提高难度.因此对数据做归一化处理是必要的.
表2 异质人脸数据集表
Table2 Heterogeneous face data set table
数据集ID数量图片数量可用性CASIA HFB dataset100992请求后可用CASIA NIR-VIS 2.072517580请求后可用Cross Spectral Dataset4304189请求后可用PolyU NIR face dataset33533500请求后可用
本文针对数据集中人脸姿态角度不同的问题,在数据预处理阶段使用通过级联人脸检测网络[16]获取图像中的人脸区域和面部关键点,再利用面部关键点和仿射变换对人脸区域进行姿态矫正[10],之后截取出人脸区域图像,并将图像调整为112×112像素做为人脸识别的训练样本.
3.3 实验结果分析
本文主要研究基于轻量级深度卷积网络的近红外光和可见光图像融合的人脸识别算法,在训练阶段分别从网络结构、损失函数、数据集几个方面做对比实验.网络主要是使用Resnet50[8]和本文lightfacenet轻量级神经网络.在测试集上本文使用LFW、AgeDB、CASIA NIR-VIS 2.0 Face、PolyU NIR Face(PNF)等数据集做测试.
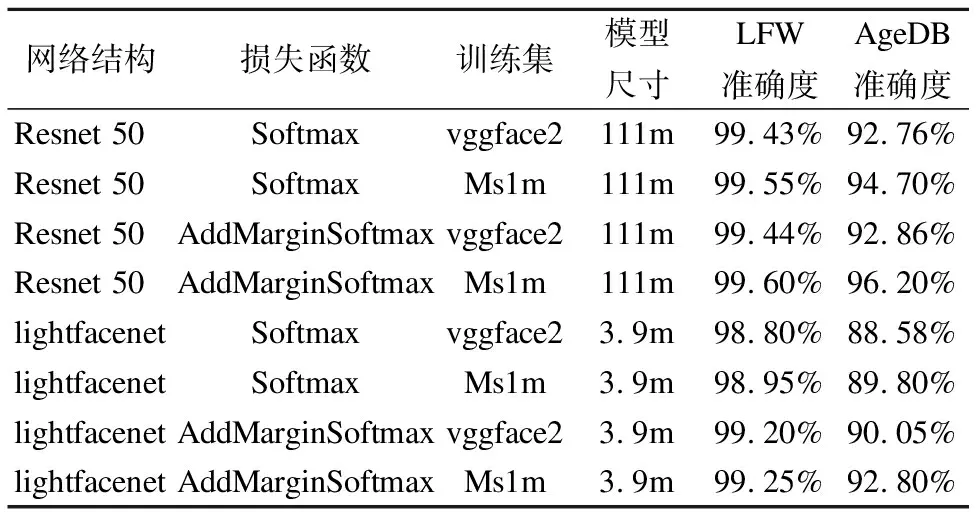
在实验前,对实验的训练样本按9:1划分,生成实验的训练集和测试集采用随机梯度下降法进行训练,批处理大小设置为256,学习率为0.1,在12k次,14k次将学习率下降到原来的0.1倍.实验结果对比如表3所示.
表3 轻量网络预训练实验数据表
Table 3 Lightweight network pre-training experimental data table
网络结构损失函数训练集模型尺寸LFW准确度AgeDB准确度Resnet 50Softmaxvggface2111m99.43%92.76%Resnet 50SoftmaxMs1m111m99.55%94.70%Resnet 50AddMarginSoftmaxvggface2111m99.44%92.86%Resnet 50AddMarginSoftmaxMs1m111m99.60%96.20%lightfacenetSoftmaxvggface23.9m98.80%88.58%lightfacenetSoftmaxMs1m3.9m98.95%89.80%lightfacenetAddMarginSoftmaxvggface23.9m99.20%90.05%lightfacenetAddMarginSoftmaxMs1m3.9m99.25%92.80%
从表3中可以看出ms1m相比vggface2数据集的训练结果更好,AddMarginSoftmax相比与soft max都有一定的提升,同时 lightfacenet网络在训练中学习参数较缓慢,但是还是具有优异的表现的,在人脸识别的准确率上基本达到了Resnet50的效果,同时其模型尺寸只有3.9m,这对于后期在移动设备上移植算法打下了基础.
基于可见光训练的网络做迁移学习,本实验会生成训练用的三元组,方法是随机均匀地覆盖更多的组合,锚点可以为近红外图像或可见光图像.正样本具有与锚点相同的id,副样本具有与锚点不同的id,根据这种方式可以得到大约16万组训练数据.使用这些数据,将训练好的可见光人脸识别网络设置为三通道的网络结构,通过三重损失函数训练网络,将batch size设置为128,进去训练.表中包含了本文方案与其他几种方法的性能比较,其中包含rank-1准确度和误识别率在0.1%时的验证率(VR@FAR=0.1%).
表4 异质人脸识别实验数据表
Table 4 Heterogeneous face recognition experimental data table
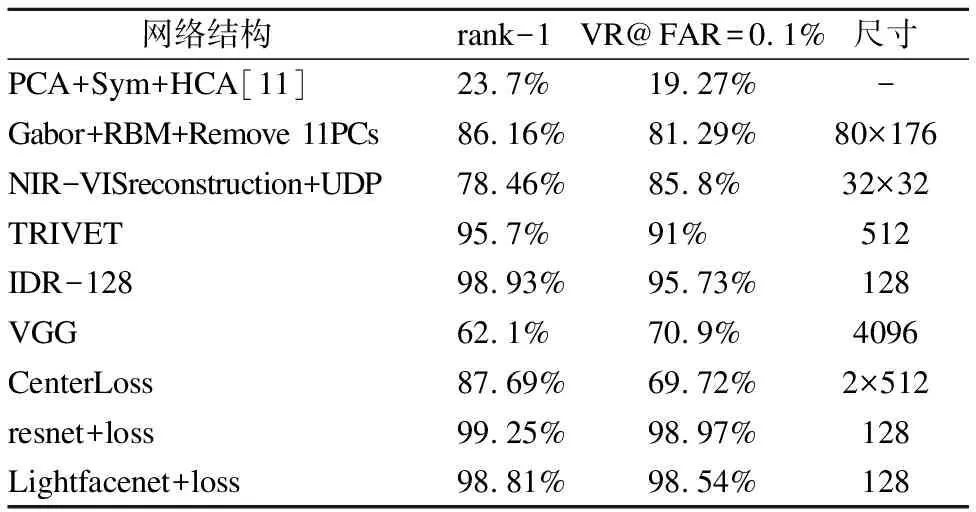
网络结构rank-1VR@FAR=0.1%尺寸PCA+Sym+HCA[11]23.7%19.27%-Gabor+RBM+Remove 11PCs86.16%81.29%80×176NIR-VISreconstruction+UDP78.46%85.8%32×32TRIVET95.7%91%512IDR-12898.93%95.73%128VGG62.1%70.9%4096CenterLoss87.69%69.72%2×512resnet+loss99.25%98.97%128Lightfacenet+loss98.81%98.54%128
从表4中可以看出,三重损失函数与其他结构相比,对于小规模的数据集学习有个不错的效果.
4 结果与讨论
本文从实用角度出发,提出一种基于轻量级深度卷积网络的近红外光和可见光图像融合的人脸识别算法.主要从网络的轻量化设计,通过使用改进的深度可分卷积和1×1的逐点卷积,以及组卷积的方式,使神经网络在轻量化的、计算量减少、速度加快的同时,又可以在准确率上可以媲美传统卷积网络.再者结合改进的softmax函数,使网络在可见光的人脸识别中达到目前顶尖的水平.再者使用三元组数据,通过三重角度损失函数,让网络跨域学习到身份类别个体间的差异,从而减少甚至消除光谱跨域带来的影响,以实现近红外光和可见光图像融合的人脸识别的效果.
