高分辨率波阻抗贝叶斯序贯随机反演
2020-04-09李祺鑫罗亚能杨亚迪黄捍东
李祺鑫 罗亚能 张 生 张 璐 杨亚迪 黄捍东
(①中海油研究总院,北京 100028; ②东方地球物理公司物探技术研究中心,河北涿州 072751;③太原理工大学矿业工程学院,山西太原 030024; ④中国石油勘探开发研究院,北京 100083;⑤中国石油大学(北京)地球物理学院,北京 102249)
0 引言
地震波阻抗反演作为储层描述的工具之一,在储层预测方面具有重要作用[1-5]。地震波阻抗反演方法众多,可以分为确定性反演与统计学反演两大类[6-8]。确定性反演是一类成熟的方法,这类方法的共性是构建一个目标函数,求取使目标函数取得极小值的解作为反演结果[9-10]。确定性反演常见的方法包括模型法反演[11]和稀疏脉冲反演[12],在特定的解约束条件下,只能进行单一的最优解估计,无法评价反演结果的不确定性。实际上,地震反演是一个多解性问题,相比于确定性反演只给出一个某种范数意义下的最优解,统计学反演则尝试用概率语言完整地表达解空间及其每个解的可能性。因此,统计学反演给出的是一簇满足约束条件的解,而非一个唯一解[13]。对于统计学反演输出的多个结果,利用概率统计的手段评价反演结果的不确定性,是分析勘探风险的一个重要方面[14-15],这是统计学反演的优势之一。为了完全探索反演解空间的结构,统计学反演利用采样求解的策略,反演结果的分辨率高于确定性反演,在薄层刻画方面取得了很好的效果[16-18],这是统计学反演的优势之二。
作为统计学反演方法的一个分支,Haas等[19]首次将地质统计学应用于地震反演,将地震资料作为约束条件,控制测井资料序贯模拟结果的取舍,构成了传统地质统计学反演的基本思想。随着研究的深入,地质统计学由两点地质统计学向多点地质统计学发展,地质统计学反演相应地也由两点地质统计学反演转向多点地质统计学反演[20-22]。González等[22]首次将多点地质统计学算法与地震反演结合反演河道砂波阻抗,探讨了多点地质统计学反演的可行性与优越性。目前,多点地质统计学反演的难点在于如何合理建立训练图像以及提高计算效率,这两方面制约着多点地质统计学反演的实际应用效果[23-24]。
目前地质统计学反演主流算法均为地质统计学随机模拟方法与马尔科夫链—蒙特卡洛方法的某种结合[25-28],并没有将地震反演、测井数据约束、随机模拟方法统一在一个理论框架下。为此,本文首先在贝叶斯理论框架下,将地震反演理论、测井数据约束、地质统计信息统一在波阻抗求解这个问题中,推导了基于对数波阻抗的地震数据与测井数据联合方程,然后通过序贯高斯随机模拟算法对反演方程进行高效采样求解,最后通过理论模型试算和实际资料应用验证了方法的可行性和有效性。
1 方法原理
1.1 地震正演模型
假设地层界面两侧为各向同性、弹性介质,当地震波垂直入射时,反射系数r(t)和波阻抗z(t)的关系可表达为[29]
(1)
式中t为时间。在小反射系数假设条件下,将式(1)改写为矩阵形式[30]
(2)
式中:r=[r1,r2,…,rN-1]T代表一道反射系数序列,下标N代表地震道的时间采样点数;z=[z1,z2,…,zN]T代表声波阻抗;而
(3)
代表差分矩阵。根据褶积模型,观测地震数据dobs为
dobs=Wr+e=WDm+e=Gm+e
(4)
式中:W为N×(N-1)维子波褶积矩阵;e为误差项;m=(1/2)lnz为波阻抗中间变量(模型参数);而
G=WD
为N×N维正演算子矩阵。
1.2 贝叶斯空间结构约束后验模型
地震反演的目的为从dobs中估计m,但由于地震资料的带限特征,存在无数解满足式(4)。传统确定性反演直接对解空间添加约束条件[31],如最小长度解、最光滑解、或者最稀疏解等,从而获得单一的解估计。在此类方法中,正则化参数的选择过于主观,反演结果受人为因素影响大,而且不能评估反演结果的不确定性。
贝叶斯反演方法能够综合观测数据中的多种先验信息,通过概率统计理论获得完备的后验解空间,并且能够表征反演结果的不确定性[9,13,32]。在贝叶斯反演中,反演结果由后验概率密度函数σ(m)表示,其为先验概率密度函数ρ(m)与地震似然函数L(m)的乘积,即
σ(m)=cρ(m)L(m)
(5)
式中c为归一化常数。
假设m服从多维高斯分布,即m~NN(mprior,Cm),则
(6)
式中:mprior=lnz0为N维列向量,表示波阻抗的先验低频背景模型,z0为初始波阻抗模型;c1为归一化常数;Cm为N×N维模型先验协方差矩阵
Cm(p,q)=C0[1-v(h)]
(7)
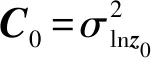
(8)
式中:c2为归一化常数;Cd为N×N维地震数据协方差矩阵,通过测井合成记录与实际井旁地震道资料估算得到。

(9)
(10)
1.3 井震联合贝叶斯序贯随机反演
当建立了后验期望(式(9))和后验协方差矩阵(式(10))表达式后,一般通过两种传统方法获得反演结果: ①直接代入相应矩阵求解[34]; ②采用蒙特卡洛方法实现随机采样[35]。在第一种方法中,由于Cm和Cd非常庞大,需要很大的物理存储空间存储。如一个二维剖面包含200个时间采样点、300道数据点,在地震反演中仅存储Cm所需的物理存储空间为(200×300)2×8B≈26.8GB,因此在实际三维地震资料反演中,对所有点进行一次性直接求解几乎不太现实。在第二种方法中,尽管蒙特卡洛方法能较好地对高维数据降维处理,但是此类方法通常需要经过一系列的“拒绝—接受”重复迭代采样过程,计算效率低[36]。
不同于以上两种方法,地质统计学中序贯高斯模拟能够充分利用求解问题的线性和高斯分布特性,是一种非迭代的高效采样方法。此方法并非一次性求解式(9)和式(10)中庞大线性矩阵的所有点,而是在模型空间中随机访问单个点,并且采用“邻域”思想将大型矩阵求解问题转换为许多小型线性矩阵求解问题,适用于任意高维问题。
序贯模拟的基本思想为将已模拟点作为条件数据,同原始已知点一起,在给定邻域内参与下一个点的计算,直至模拟完成随机路径中所有节点。借鉴这种思想,本文采用井震联合的贝叶斯序贯随机反演方法,为了求解方便,在邻域内将观测数据划分为A、B两类数据。A类数据为模型参数的直接测量值,包括测井数据和先前模拟的点,也称为“硬数据”或者“点数据”; B类数据为模型参数的线性平均观测值,即通过线性正演算子获得的测量数据,也称为“软数据”或者“体数据”,这里指地震数据。联合两类观测数据,式(4)可改写为
(11)
dobs(A+B)=GA+BmA+B+eA+B
(12)
式中:dobsA、GA、mA和eA分别代表A类观测数据、正演算子、模型参数和误差项;dobsB、GB、mB和eB分别代表B类观测数据、正演算子、模型参数和误差项;dobs(A+B)、GA+B、mA+B和eA+B代表A、B两类数据的联合参数。这里需要注意的是,与地震正演算子GB不同,直接观测的A类数据正演算子GA为简单的单位矩阵,不依赖于任何物理规律。

Cd(A+B)]-1[dobs(A+B)-Gmprior(A+B)]
(13)
Cd(A+B)]-1GA+BCm(A+B)
(14)
式中:mprior(A+B)和dobs(A+B)均为(NA+NB)维列向量,NA、NB分别为邻域内A、B类数据的采样点数;Cm(A+B)和Cd(A+B)分别为(NA+NB)2维模型协方差矩阵和数据协方差矩阵,表达式为
(15)
式中:CmAA、CmBB分别为A、B类数据的模型协方差矩阵;CmAB为A、B类数据的互协方差矩阵;CdBB为B类数据的数据协方差矩阵。在Cd(A+B)中,假设A类数据为准确值,并假设A、B两类数据的误差不相关,因此A类数据的协方差矩阵和两类数据的互协方差矩阵都为0。
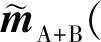
为了专心准备金腰带,邹推掉了很多品牌代言。他现在每年要负担200万元~300万元人民币训练费用,他靠比赛奖金维持收入,当然,这离一名真正的明星职业拳手依然相差甚远。
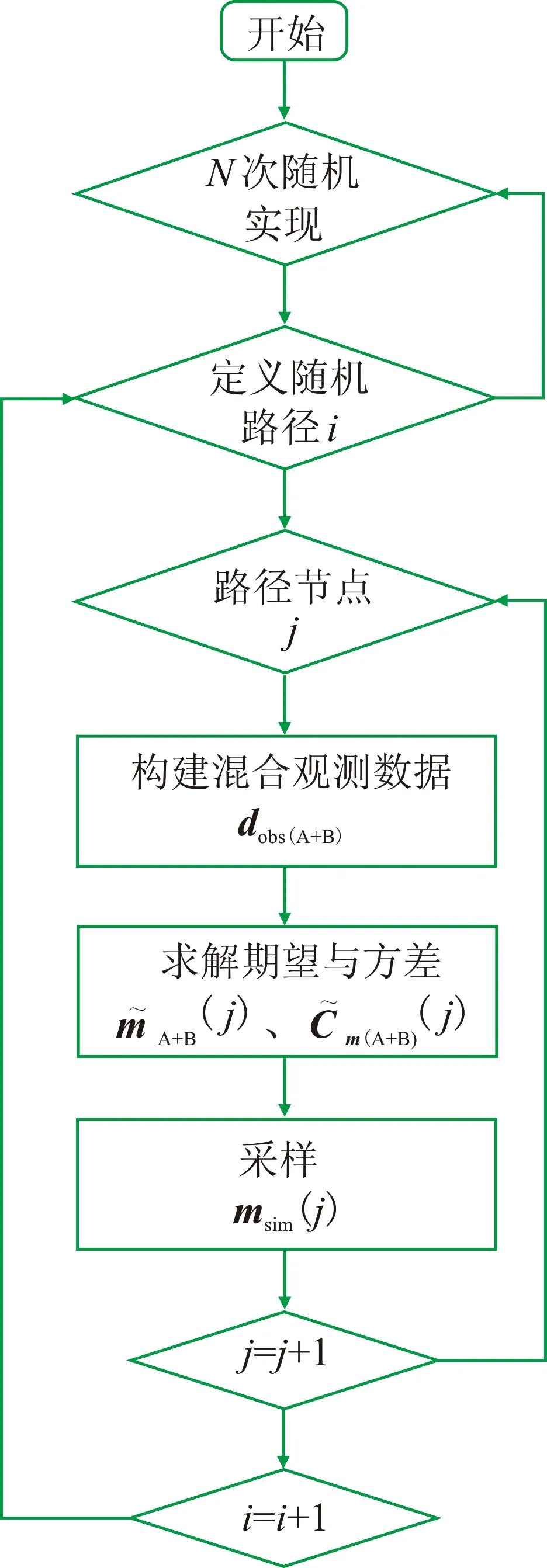
图1 算法流程
2 数值算例
为了验证贝叶斯序贯随机反演算法的有效性,利用无条件序贯高斯随机模拟算法生成一个二维薄互层波阻抗模型,作为实际地下地层的参考模型,并且从二维模型中抽取一道作为测井数据,即A类数据(图2)。
图3为根据图2生成的合成地震记录与常数背景初始模型,其中合成地震记录(图3a)作为B类数据,常数背景模型(图3b)在地质统计学模拟中作为全局期望,在地震反演中作为反演初始模型。以合成地震记录(图3a)中的测井数据(A类)和地震数据(B类)作为观测数据,分别进行B类数据最小二乘法确定性反演、A类数据序贯高斯模拟及A、B两类数据联合贝叶斯序贯反演测试,分析贝叶斯序贯反演方法的优势。图4为地震数据(B类)最小二乘法反演结果,反演输入数据只有地震数据dobsB和地震数据协方差矩阵Cd,此时的最小二乘解为
mLSI=m0+GT(GGT+Cd)-1(dobsB-Gm0)
(16)
由图4可见,与实际波阻抗参考模型(图2)相比,最小二乘反演结果的纵向分辨率与地震资料相当,只能反映参考模型中参数的变化趋势,不能刻画测井曲线的细节。事实上,最小二乘反演为一种过度光滑的估计方法,而且没有添加先验信息约束,反演结果仅依赖地震资料,因此反演结果分辨率低。

图2 合成波阻抗参考模型
模型共301道,道间距为10m,纵向采样点数为150,采样间隔为1ms。对数波阻抗均值为16.15kg·m-2·s-1,方差为0.01(kg·m-2·s-1)2,水平变差函数变程为1000m(或100道),垂直变差函数变程为10ms(或10个采样点),设置变差函数为球状变差函数
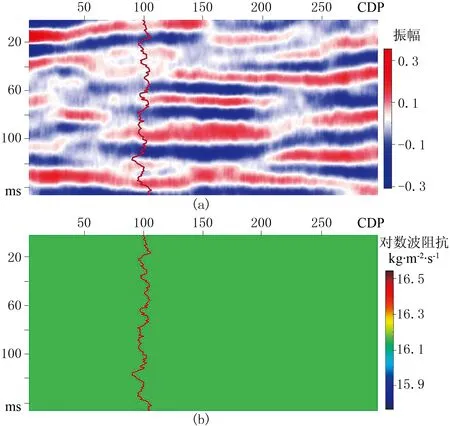
图3 根据图2生成的合成地震记录(a)与常数背景初始模型(b)
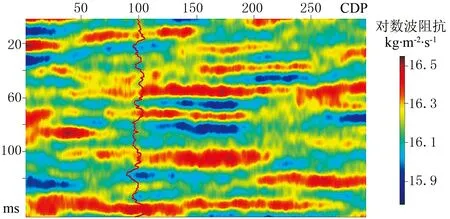
图4 地震数据(B类)最小二乘法反演结果
图5为测井数据(A类)序贯高斯模拟2次实现结果,反演输入数据只有测井数据dobsA和模型协方差矩阵Cm。由图5可见:模拟结果的分辨率与参考模型(图2)相当,且在井点处的结果与测井资料完全吻合;由于缺乏地震数据约束,模拟结果的不确定性高(图5箭头处),2次实现结果的差别非常大。因此在缺乏井资料时,传统的地质统计学方法不适用于井间模型参数预测。
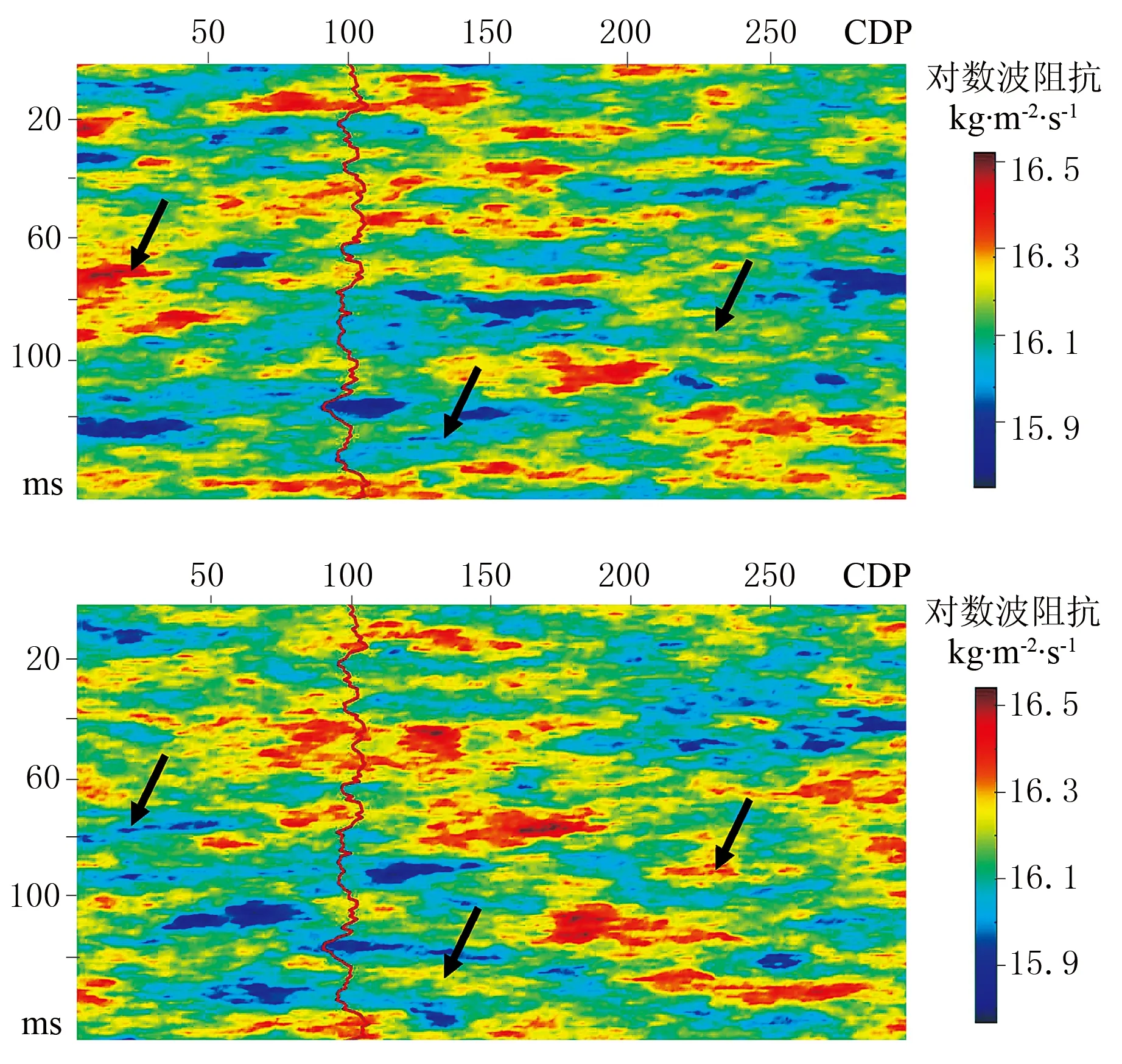
图5 测井数据(A类)序贯高斯模拟2次实现结果
图6为井震联合(A+B类)数据贝叶斯序贯反演3次实现结果,输入数据为模型协方差矩阵Cm和数据协方差矩阵Cd。由图6可见,3次实现的分辨率与参考模型(图2)相当,不仅在井点处与测井曲线完全吻合,且降低了实现结果的不确定性(图6箭头处),3次实现结果整体特征相似,反映了地震数据约束的一致性;在小尺度条件下,3次反演结果间具有微小的差异,这种差异反映了不确定的地下介质非均质性。
图7为不同结果合成地震记录与实际地震记录残差。由图可见:最小二乘反演结果(图7b)和序贯高斯模拟(图7c)的残差均与实际噪声(图7a)相差较大,其中后者与实际噪声的差异更大,而前者逐道反演的痕迹明显,反映了没有利用模型参数横向相关性的缺点;贝叶斯序贯反演结果的残差(图7d)与实际地震噪声(图7a)在幅度和形态上较接近(图7a和图7d箭头处)。上述结果表明,井震联合数据贝叶斯序贯反演方法得到的模型参数精度最高。

图6 井震联合(A+B类)数据贝叶斯序贯反演3次实现结果
图8为水平、垂直方向反演结果变差函数。由图可见:由于A+B类数据贝叶斯序贯反演过程使用了模型的空间结构信息Cm,因此所得水平、垂直变差函数均与参考模型变差函数匹配较好,其中水平方向变程约为1000m(图8a),垂直方向变程约为10ms(图8b);最小二乘反演结果(B类)由于没有利用模型参数的空间结构信息,反演结果的水平(图8a)、垂直(图8b)变差函数与参考模型变差函数差别较大。
模型测试分析结果表明,贝叶斯序贯随机反演方法采用邻域思想将高维数据降维处理,适用于任意的高维数据反演,同时能够克服最小二乘法反演的光滑效应以及序贯高斯模拟不确定性大的问题,可获得高分辨率且相对稳定的反演结果。

图7 不同结果合成地震记录与实际地震记录残差

图8 水平(a)、垂直(b)方向反演结果变差函数
3 实际应用
为了进一步检验贝叶斯序贯随机反演方法的实际应用效果,以中国东海盆地西湖凹陷N井区进行试验,试验数据来自一条过井三维地震剖面(图9),其中测井合成地震记录与实际井旁道对应较好(图9箭头处)。图10为W1井对数域弹性参数正态分布检验Q-Q图。由图可见,数据点基本位于正态分布参考线之上,表明贝叶斯序贯随机反演方法对于研究区的适用性。

图9 实际地震剖面与测井合成记录标定
纵向时间采样间隔为1 ms,采样点数为620个,道间距为25 m,共400道,地震资料主频为32 Hz。黑色曲线为井震标定后的测井合成地震记录,测井合成记录选用主频为32 Hz的雷克子波

图10 W1井对数域弹性参数正态分布检验Q-Q图
图11为模型法、稀疏脉冲法对图9的反演结果,图12为贝叶斯序贯随机反演3次实现结果。由图可见,3种反演方法得到的波阻抗剖面在整体上具有相似性,但模型法反演结果在纵向上更光滑(图11a黑色箭头处),稀疏脉冲法反演结果则展示了一个更“块状”化的结果(图11b黑色箭头处),贝叶斯序贯随机反演方法则提供了多个与井曲线分辨率相当的反演结果(图12)。
事实上,之所以产生上述反演结果是由采用的反演方法决定的。模型法反演直接对低频初始模型进行迭代扰动,当正演模拟数据与观测数据达到一定的匹配标准时停止迭代;稀疏脉冲反演是在反射系数稀疏准则的约束下,对地震资料反褶积获得宽带反射系数,然后再通过递推等算法获得绝对阻抗;贝叶斯序贯随机反演将测井数据和已模拟点作为硬数据,在地质统计信息和地震数据的共同约束下,参与计算下一个点,因此测井信息在遍历随机路径的过程中得到传播,从而使反演结果具有高分辨率特征,且横向变化特征清晰、自然。
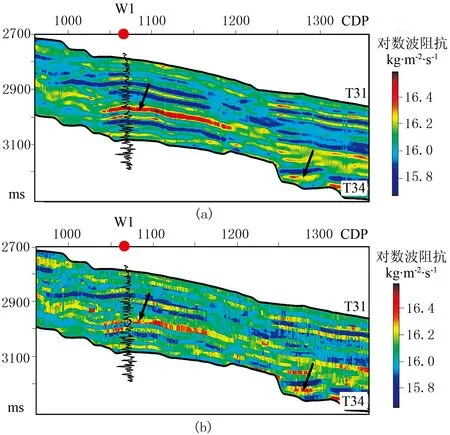
图11 模型法(a)、稀疏脉冲法(b)对图9的反演结果
图13为盲井反演结果、序贯随机反演概率解。由图可见:在恢复井曲线波阻抗的中低频相对变化时,3种方法给出了等价结果,而序贯随机反演方法则展示了更高频的阻抗变化细节(图13a);对比概率分布与真实井曲线,能够获得在当前数据条件下反演结果的不确定性程度(图13b)。模型法反演与稀疏脉冲反演这类确定性反演方法,由于只能给出一个唯一解,无法评价反演结果的不确定性与风险,而风险评估在勘探决策中具有重要作用,这是利用贝叶斯序贯随机反演方法进行地质解释的另一优势。图14为三维贝叶斯序贯随机反演最大后验解。由图可见,沿目的层顶界切片明显展示了两条河道特征(图中箭头处),与研究区三角洲前缘水下分流河道沉积背景相符合。
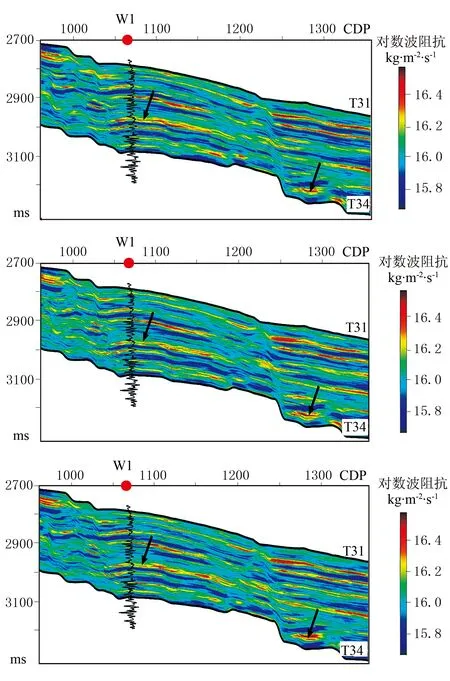
图12 贝叶斯序贯随机反演3次实现结果

图13 盲井反演结果(a)、序贯随机反演概率解(b)
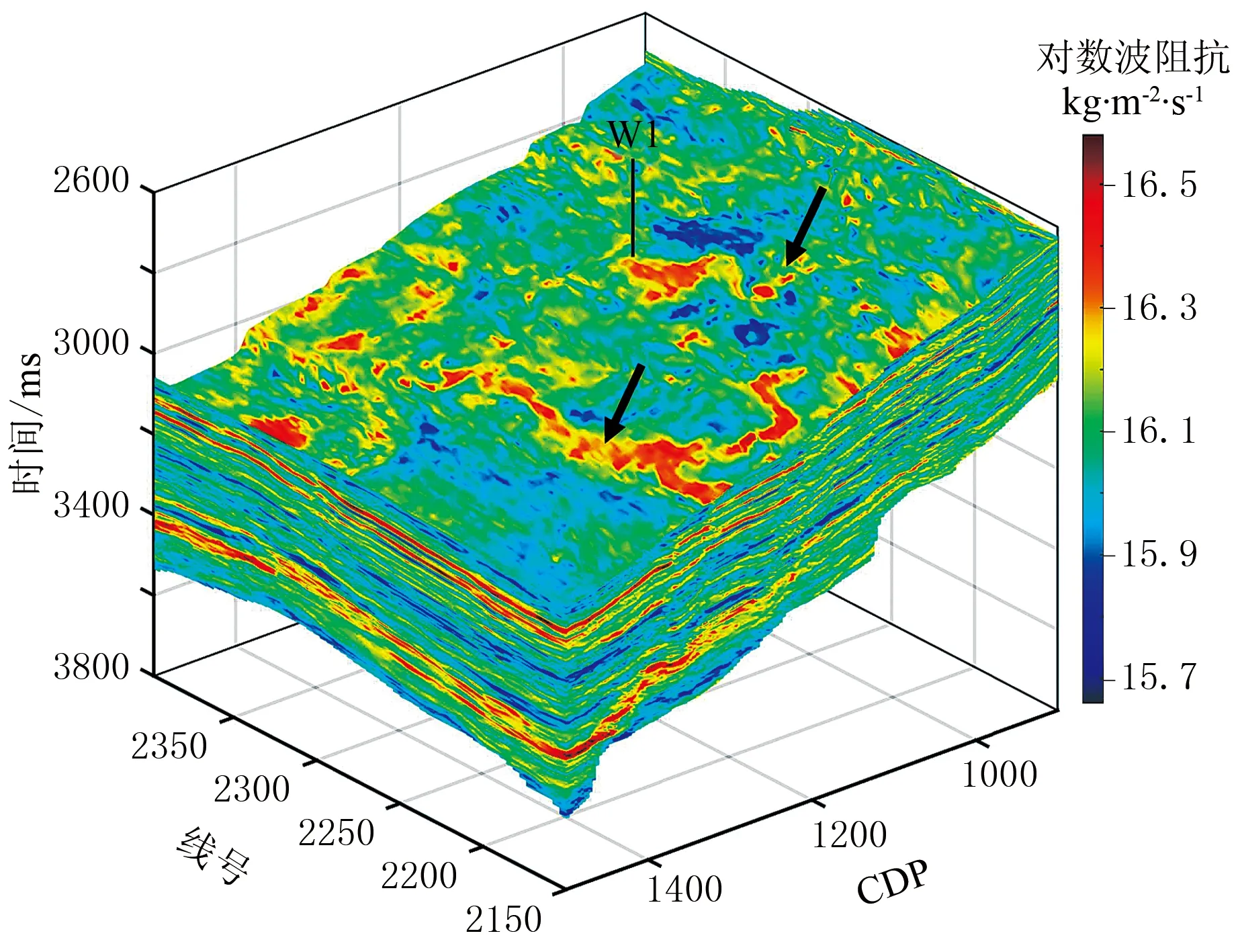
图14 三维贝叶斯序贯随机反演最大后验解
4 结束语
本文采用高分辨率贝叶斯波阻抗序贯随机反演方法,在贝叶斯理论框架下整合地震数据、测井数据和地质空间结构先验信息,并且将线性反演理论与克里金算法相联系,采用序贯模拟方法高效随机实现后验概率分布。数值算例表明:与常规波阻抗最小二乘法反演相比,该方法分辨率高、反演结果受先验统计学参数约束,且输出的多个波阻抗反演实现可用于不确定性评价;与纯粹基于测井数据的序贯高斯随机模拟方法相比,该方法最大的优点就是考虑了地震数据约束,降低了反演结果的不确定性。针对实际数据,对比、分析了模型法反演、稀疏脉冲法反演、贝叶斯序贯随机反演结果,表明贝叶斯序贯随机反演方法在提高反演纵向分辨率与不确定性评价方面具有良好的应用前景。
