基于统计特征和熵特征融合的心肌梗死辅助诊断方法
2020-04-09王治忠钱龙龙
王治忠,钱龙龙,韩 闯,师 丽
(1.郑州大学电气工程学院,郑州450000;2.清华大学自动化系,北京100000)
0 引言
心肌梗死是由于血液无法正常流向心肌的某些区域,造成心肌细胞缺血性坏死的结果[1]。心肌梗死因其突发性和高死亡率引起人们的关注。结合中国国情,我国心脏疾病患者众多和有限的医疗资源之间的矛盾越来越激烈,随着人工智能的发展,通过人工智能辅助医生诊断成为了缓解矛盾的有效方法。心电图(ElectroCardioGram,ECG)是心脏电活动在体表的反映,鉴于其非侵入性、低成本、方便获取和能够较为全面地反映心脏活动的特性,心电图成为医生进行心脏疾病诊断的一个重要工具。心肌细胞缺血性坏死程度和范围的不同,在心电图上的反映也不相同,因此心电图对心肌梗死诊断具有很大的意义。心肌梗死在心电图上的表现为:坏死区出现病理性Q 波,损伤区ST 段弓背向上抬高和缺血型T 波倒置[2]等。
目前很多研究团队对心肌梗死的智能诊断进行了研究,通常步骤是信号预处理、特征提取和分类。针对信号预处理,数字滤波器和均值滤波去除噪声[3-5]、基于小波变换进行心电信号的去噪处理[6-9]等方法较为常用。在特征点提取方面,PT(Pan-Tompkins)[5,10-12]算法、阈值法[13]和小波变换方法[14]通常被用于R 波峰值点检测。在信号的分类方面,传统的分类器有神经网络[3,7,15]、K 最近邻(K-Nearest Neighbors,KNN)[11,14]、高 斯 混 合 模 型[16]、支 持 向 量 机(Support Vector Machine,SVM)[5,13,15]和 阈 值 法 分 类[9]用 于 心 肌 梗 死(Myocardial Infarction,MI)的检测,还有一些学者提出使用深度学习方法中的卷积神经网络(Convolutional Neural Network,CNN)[3,17]。在特征提取方面,心电信号归一化后所计算的多尺度小波能量特征和模式n 奇异值特征[5]、多尺度小波能量特征[8]、时域特征[14]、弹性分析小波变换系数和样本熵特征[18]、相位特征[19]、拟合心电信号的多项式系数特征[4]、医学特征[20]和多特征融合[21]等方式都曾被用于心肌梗死的辅助诊断。
现有研究中所用特征很少能够反映心电信号的形态特征和波形的变化特点,且很少有研究关注病人间模式的心电信号识别,仅病人内模式很难用于临床诊断。在心肌梗死辅助诊断的方法中有基于心拍识别和心电记录的识别两种方式。心拍识别和部分导联记录识别不能较为全面地反映心脏电活动,现有针对常规12 导联心电信号记录识别心肌梗死的研究很少。针对现有研究的不足,本文在特征提取方面采用常规12 导联心电信号的统计特征和熵特征来分别反映心电信号的形态特征和波形变化特点,并在病人间和病人内两种模式下验证算法的有效性。本文研究工作流程如图1所示。
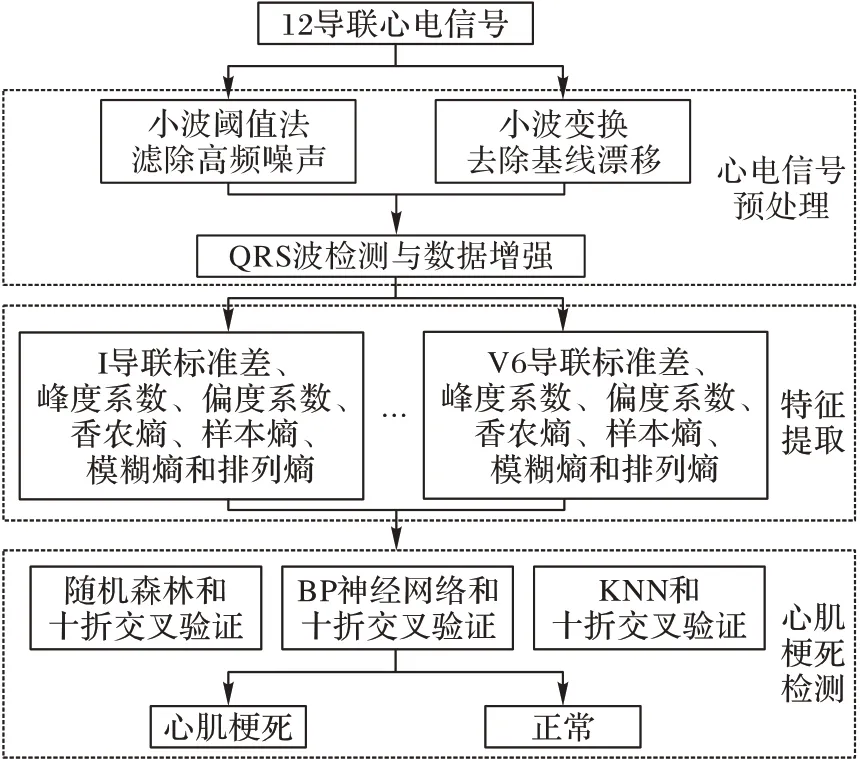
图1 心肌梗死检测流程Fig.1 Flowchart of myocardial infarction detection
对于第一部分心电信号预处理是通过小波滤波滤除高频干扰和基线漂移,通过R 波检测实现数据增强。在第二部分的特征提取中,本文融合12 导联的统计特征与熵特征,分别使用基于十折交叉验证的随机森林(Random Forest,RF)、反向传播神经网络(Back Propagation Neural Network,BPNN)和KNN 算法,在病人间和病人内两种模式下进行心肌梗死的检测。本文主要工作如下:
1)提出一种包含标准差、峰度系数、偏度系数的统计特征与包含香农熵、样本熵、模糊熵、近似熵和排列熵的熵特征融合的方法表征12导联心电信号信息。
2)基于随机森林算法在病人内模式下进行分析和验证,与已发表文献中的方法进行对比的结果显示,本文方法取得了较好的结果;同时在病人间模式下验证了特征的有效性,具有临床实用性。
3)通过12导联心电记录诊断心肌梗死,诊断过程更符合临床诊断逻辑。
4)通过数据增强和十折交叉验证避免过拟合的问题。
1 心电信号预处理
1.1 数据来源
本次研究使用的是由德国国家计量署提供的PTB(Physikalisch-Technische Bundesanstalt)数据库[22]。该数据库中包含148 个心肌梗死病人的数据共346 条记录,52 个健康人数据共80 条记录。整个数据库患者年龄在17 到87 岁之间,其中:男性209 名,平均年龄为55.5 岁;女性共81 名,平均年龄为61.6 岁。每个病人的数据中包含.dat(ECG 数据)、.hea(病人详细信息)和.xyz(Frank 导联数据)三种格式文件,采样频率为1 000 Hz,含有常规12 导联数据和vx、vy、vz三个Frank导联,共15个导联。
1.2 信号滤波
心电信号的主要频率分布在1~45 Hz,对于大于45 Hz 的部分主要为肌电干扰和其他信号干扰,小于1 Hz 的部分主要由电极滑动等原因造成的基线漂移。本文采用小波软阈值法完成高频去噪。鉴于信号的最高频率是500 Hz,本文对信号进行9 层小波分解,将第9 层近似系数(0~0.98 Hz)置零完成滤除基线漂移。滤波前后的效果如图2 和图3 所示。图2 和图3分别为MI和正常(Healthy Control,HC)信号的滤波过程。
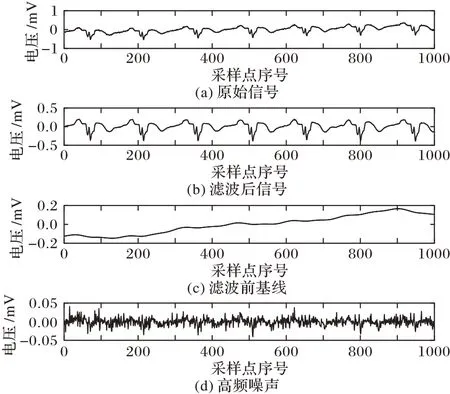
图2 心肌梗死心电信号II导联滤波前后对比Fig.2 Comparison of lead II MI ECG signal before and after filtering process
1.3 数据增强
在PTB 数据库中共有心肌梗死病人数据148 个,正常人心电数据52 个,为了增加心电样本数量、增强分类器性能,要对数据进行增强。在数据截取时信号过长,造成数据维度过大,不仅产生数据冗余,而且造成后期计算复杂度过大,过短则不能较为完整地反映一定周期的心脏电活动。数据增强的形式如图4所示。
图4是利用I导联作为数据扩充的示例,其他导联在分别进行预处理、下采样后在I导联相同位置进行数据截取。
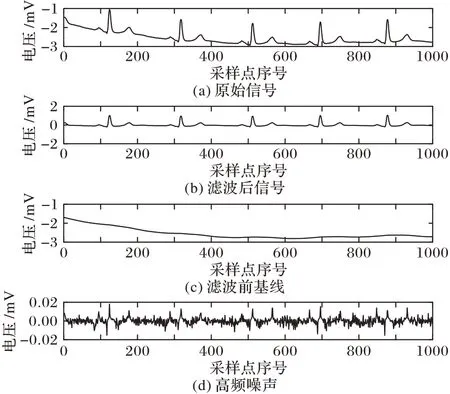
图3 正常心电信号II导联滤波前后对比Fig.3 Comparison of lead II HC ECG signal before and after filtering process
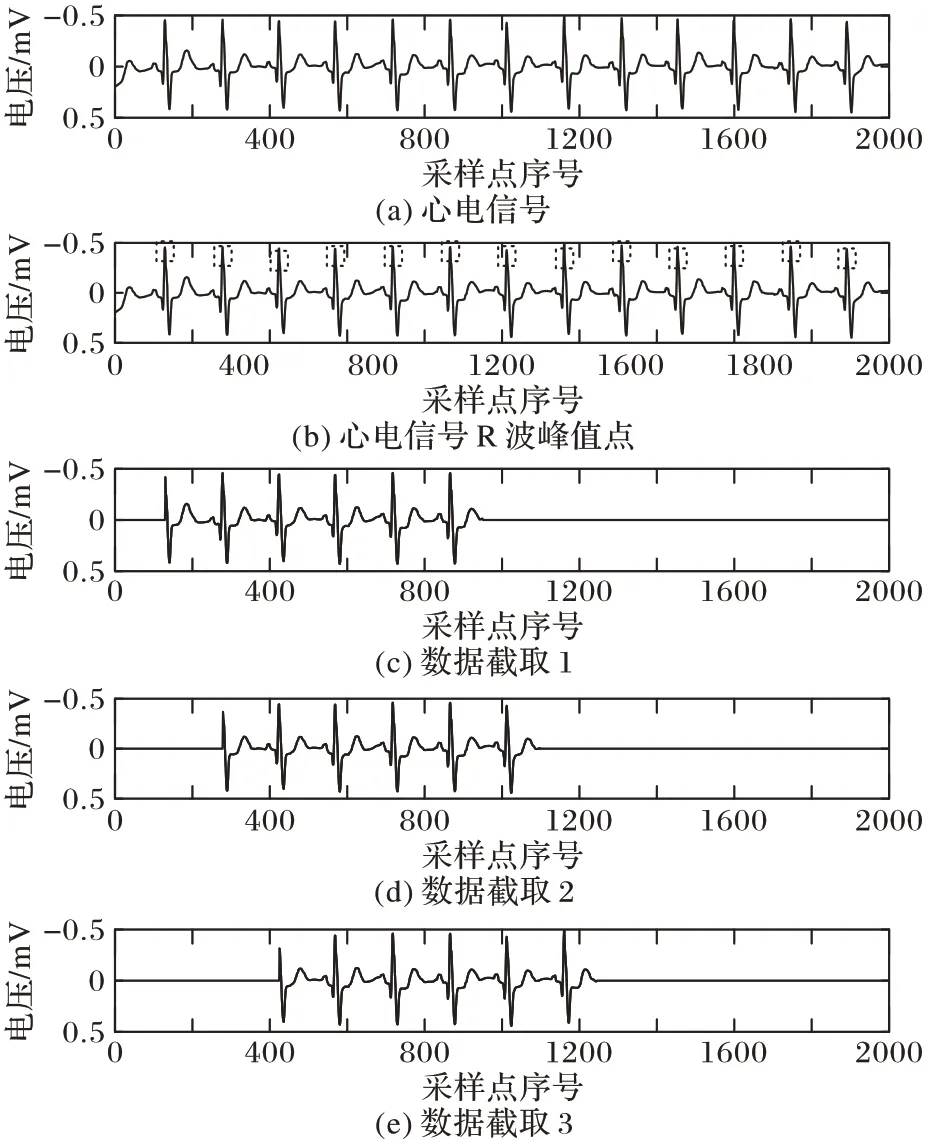
图4 数据增强示意图Fig.4 Schematic diagram of data enhancement
图4 中,图(a)为对原始数据进行预处理和下采样后的数据,图(b)是对心电信号采取PT 算法进行R 波峰值点标注结果,图(c)~(e)是对心电信号截取的方式,非置零区域为截取的部分。在数据增强过程中通过截取心电信号的R波峰值点及向后的4.1 s 的12 导联数据作为新的心电记录。表1 为数据增强前后心电记录总数。
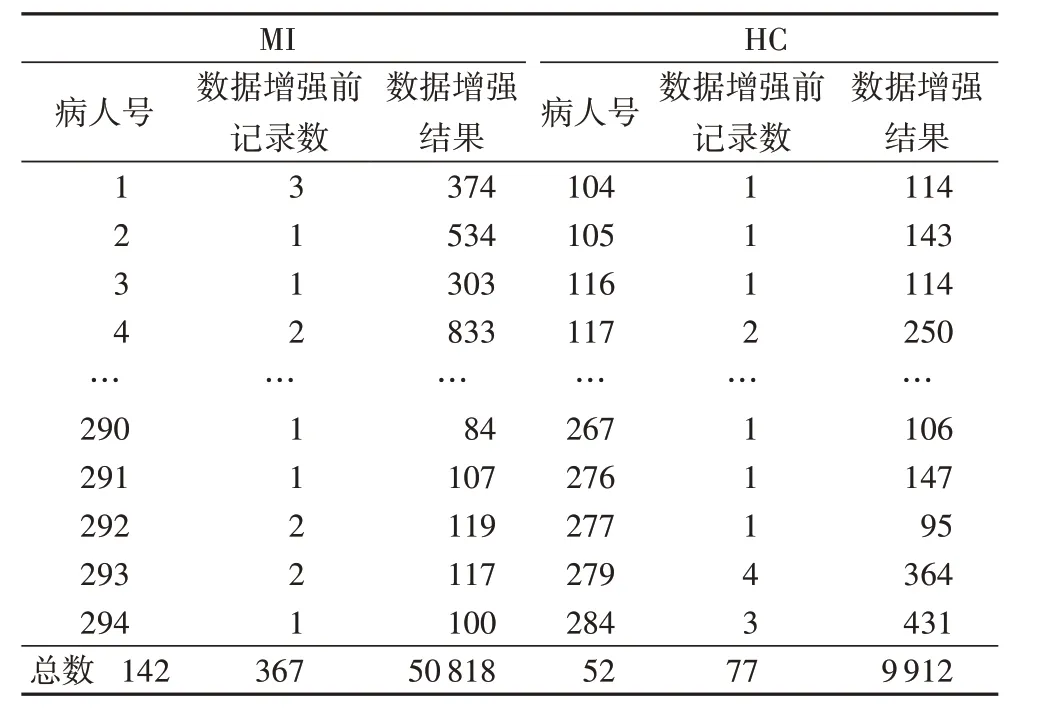
表1 数据增强前后心电记录数量Tab.1 Number of ECG recordings before and after data enhancement
每个病人数据增强后的数量为NUM:

其中:i为病人在数据增强前的第i条记录,N 为数据增强前某病人的记录数,mi为病人的第i 条记录舍去最后4.1 s 的心拍数。
2 特征提取
特征提取是心电信号识别中最关键的步骤之一,在本文中通过实验发现融合12 导联心电信号的统计特征和熵值特征,在最终心肌梗死检测时具有很好的效果。本文研究使用的统计特征有标准差、峰度系数和偏度系数,使用的熵值特征有香农熵、样本熵、模糊熵、近似熵和排列熵。
2.1 统计特征
在本文中使用的统计特征包含标准差、峰度系数和偏度系数,主要反映心电信号的离散程度、波形的尖峭程度和分布的对称程度。这些统计特征反映了信号的形态特征,对心肌梗死的智能诊断具有一定的意义。
标准差(σ)是方差的算术平方根,其意义在于心电信号数据间的离散程度。
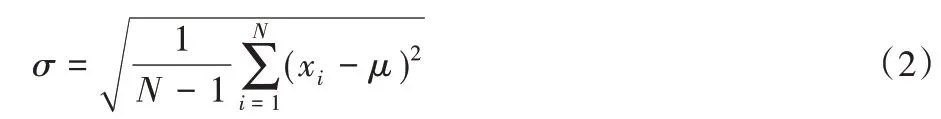
其中:N 代表数据总数,xi代表第i 个数据,μ 表示N 个数据的均值。
峰度系数(Kurt)是用来反映心电信号频数分布曲线顶端尖峭或扁平程度的指标,是随机变量的四阶中心矩与方差平方的比值。
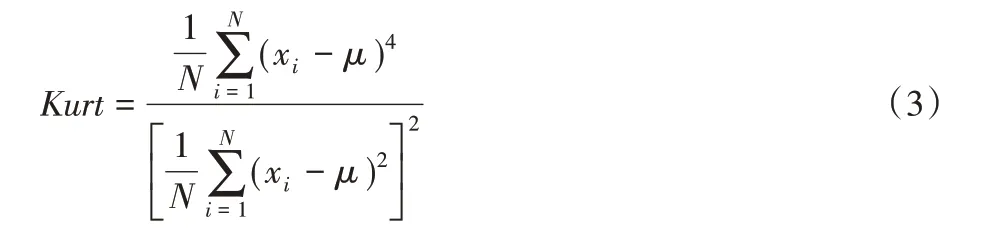
其中:N 代表数据总数,xi代表第i 个数据,μ 表示N 个数据的均值。
偏度系数SK 是描述心电信号分布偏离对称性程度的一个特征值:当偏度系数为0 时,该分布左右对称;当偏度系数大于0时,该分布右偏;当偏度系数小于0时,该分布左偏。
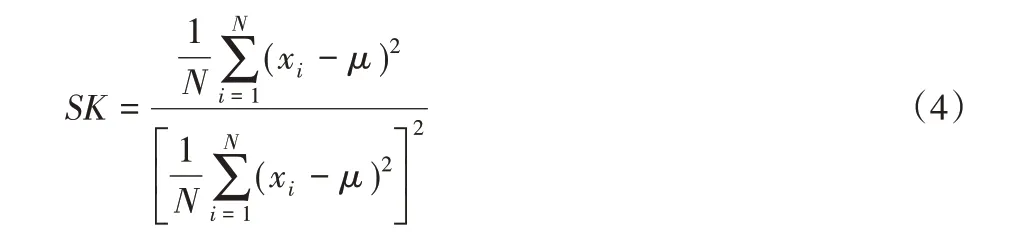
其中:N 代表数据总数,xi代表第i 个数据,μ 表示N 个数据的均值。
2.2 熵特征
本文使用信号的香农熵、样本熵、模糊熵、近似熵和排列熵特征来反映信号的序列的时间与频谱复杂性、新模式产生的概率、规律性和不可预测性以及检测信号微小变化。本文研究使用的熵值特征能够较为完备地反映了心电信号的动态变化,对心电信号的类别判定具有很大的意义。

其中:ai代表ECG信号的概率分布。
样本熵通过度量ECG 信号中产生新模式的概率大小来衡量时间序列复杂性,新模式产生的概率越大,序列的复杂性就越大。样本熵的值越低,序列自我相似性就越高;样本熵的值越大,样本序列就越复杂。

其中:r=0.2×std,std 为标准差;Am和Bm分别表示在容限r 下匹配m+1个和m个点的概率。
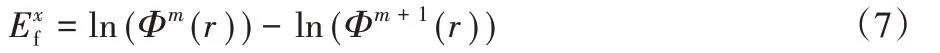
其中:相空间维数m取2,相似容度r为0.2*std。

其中:SL(k)代表信号模型L 的平均长度,SL+1(k)代表信号模型L+1的平均长度。
其中:嵌入维度m 取3,时间延时t 取2,K ≤m!,Pj指相空间j的下标符号序列概率。
2.3 熵特征
对数据增强后的12 导联心电信号,每个导联(Di)分别获取标准差、峰度系数、偏度系数、香农熵、样本熵、模糊熵、近似熵和排列熵8个特征值。

其中:i代表不同导联。
通过融合12 导联的这8 个特征得到特征向量FN,一个心电记录就由原来的12 导联、每导联821 维的矩阵简化为最终用于检测的96 维特征。特征融合得到的96 维特征反映了12导联的心电信号较为全面的波形信息。图5 和图6 分别是心肌梗死和正常人12 导联特征的glyph 图。图7 是心肌梗死和正常12导联心电信号最终用于疾病检测的96维特征图。
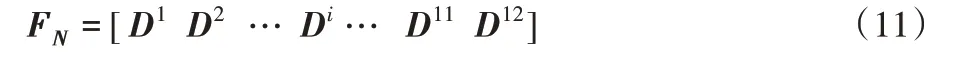
其中:N代表不同的记录,Di为导联i的特征集合。
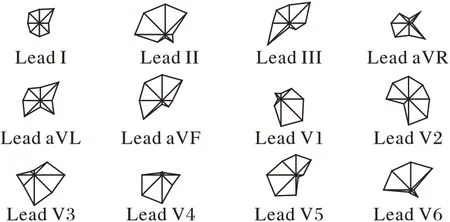
图5 心肌梗死12导联特征的glyph图Fig.5 Glyph map of 12-lead features of MI subjects
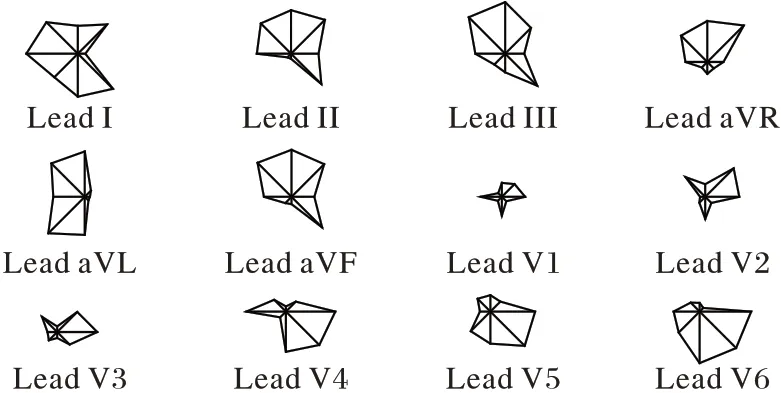
图6 正常人12导联特征的glyph图Fig.6 Glyph map of 12-lead features of HC subjects
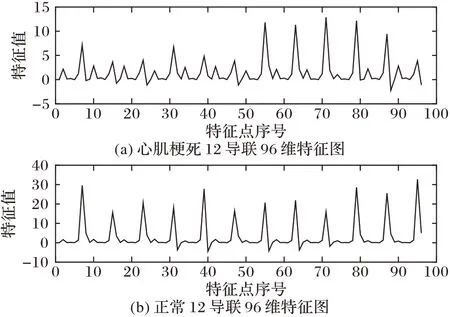
图7 心肌梗死和正常12导联心电信号96维特征图Fig.7 Ninety-six dimensional feature map of 12-lead MI and HC ECG signals
3 心肌梗死检测
3.1 分类器及其参数介绍
对于心电信号的最终检测识别模型的稳定可靠性,本文分别采用了基于十折交叉验证的BPNN、RF和KNN分类器。
BPNN 是一种模仿动物神经网络行为特征进行分布式并行信息处理的算法数学模型。在神经网络的应用中本文使用50层神经网络,设置迭代步长为0.001,最小误差为0.001。
随机森林分类器是一种集成学习算法,它内部的弱分类器为决策树,本文使用了50 棵决策树,采用Bagging 算法集成。
决策树是一种依靠信息增益决定根节点的分类器,在训练过程中,计算属性对样本集进行划分所获得的信息增益,信息增益大的作为根节点,进而完成决策树的构造。算法中还有防止过拟合的剪枝处理。
最邻近算法的思想是,距离目标数据最近的K 个样本大多数属于某一类,那么这个目标数据很大可能属于这一类。在本文实验中K取50。
3.2 结果分析
本文研究从病人内和病人间两种模式进行分析,病人内模式指的是在训练集和测试集中会出现相同病人不同记录的心电信号,而病人间模式指在训练集和测试集中不会出现相同病人的数据。
病人内的实验数据如表2 所示,病人间实验在进行十折交叉验证时,将142 个心肌梗死病人的293 和294 号病人数据与剩余140 人的心电数据在十折交叉验证时每次的训练集联合作为训练集。52 个正常人的心电信号取其中任意12 个人的数据与剩余40 人的心电数据在十折交叉验证时每次的训练集联合作为训练集,联合MI 和HC 的训练集数据作为十折交叉验证时的训练集。
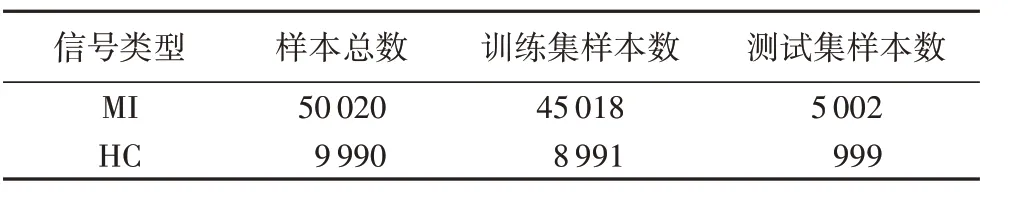
表2 病人内每折验证数据集分布Tab.2 Distribution of validation datasets per fold in intra-patient mode
通过使用十折交叉验证与分类器的结合完成了心肌梗死的检测,为了评价模型的性能和分类特征的有效性,通过混淆矩阵计算测试准确率、敏感度、特异性和F1 值进行分析。混淆矩阵形式如表3所示。

表3 混淆矩阵Tab.3 Confusion matrix
在表3 中,真正例(True Positive,TP)代表心肌梗死信号被预测正确的部分,假反例(False Negative,FN)代表心梗信号被预测为正常的部分,假正例(False Positive,FP)代表正常信号预测为心梗的部分,真反例(True Negetive,TN)代表正常信号被预测正确的部分。
准确率(Accuracy,acc)计算公式为:

敏感度(Sensitivity,sen)计算公式为:

特异性(Specificity,spe)计算公式为:

F1值计算公式为:

其中N代表数据总量。
三类分类器在十折交叉验证下每折的分类性能如表4 所示,在表4中:0代表心肌梗死,1代表正常;准确率、敏感度、特异性和F1值结果的上下两行中上方的是病人内的结果,下方的是病人间的结果;黑色加粗部分结果是病人内和病人间分类最优结果。反向传播神经网络在病人内的准确率、敏感度、特异性和F1 值最高均为100%,病人间的准确率、敏感度、特异性和F1 值最高分别为98.42%、99.96%、80.93%和99.14%。随机森林在病人内的准确率、敏感度、特异性和F1值最高均为100%,病人间的准确率、敏感度、特异性和F1 值最高分别为99.93%、100%、99.22%和99.96%。KNN 在病人内的准确率、敏感度、特异性和F1 值最高分别为99.63%、99.74%、99.09%和99.78%,病人间的准确率、敏感度、特异性和F1值最高分别为92.13%、100%、69.14%和94.98%。在病人内结果中,BPNN 和随机森林有着同样好的检测效果,但是在病人间的结果中,随机森林有着更好的检测性能。
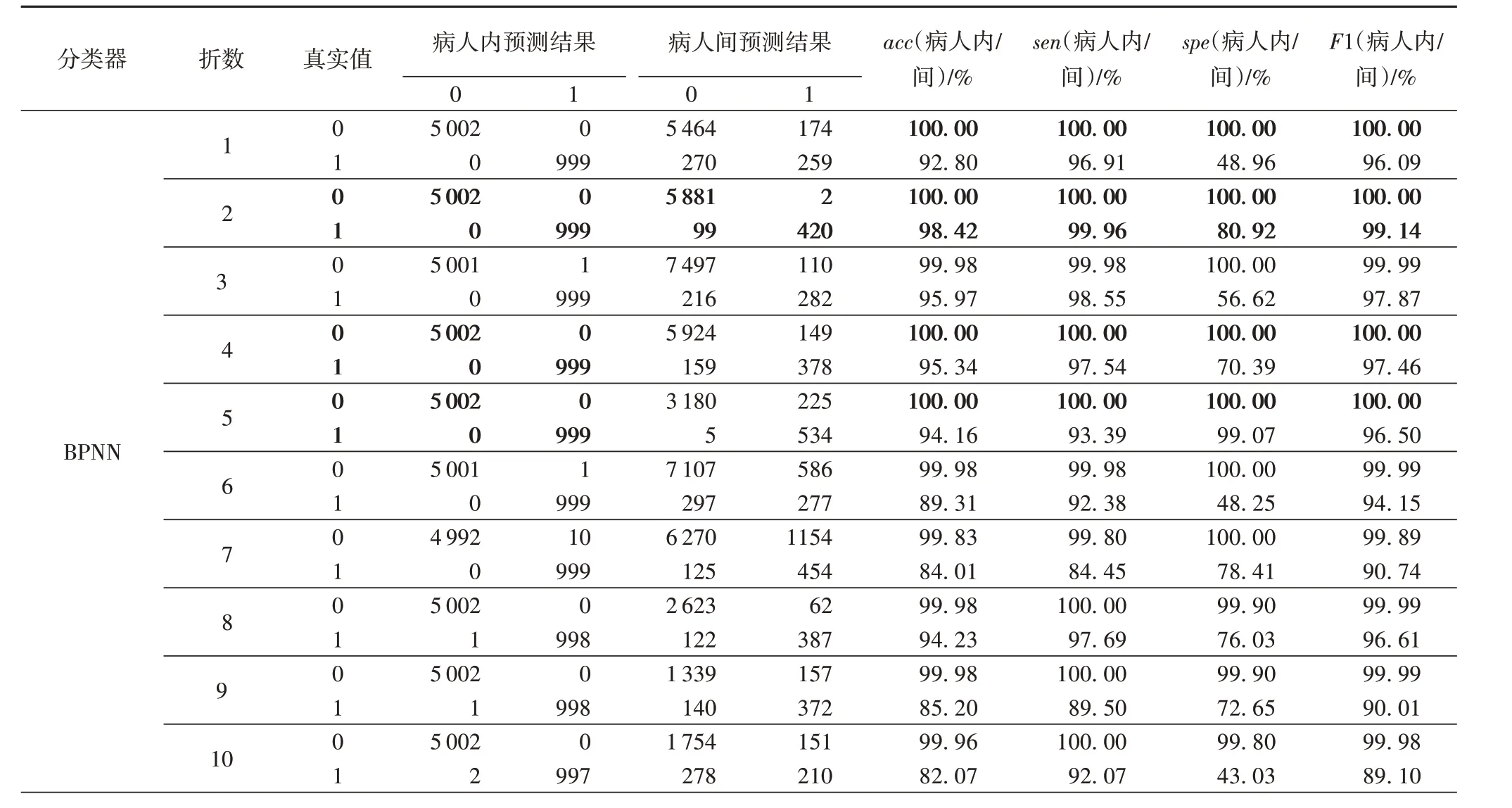
表4 性能分析Tab.4 Performance analysis
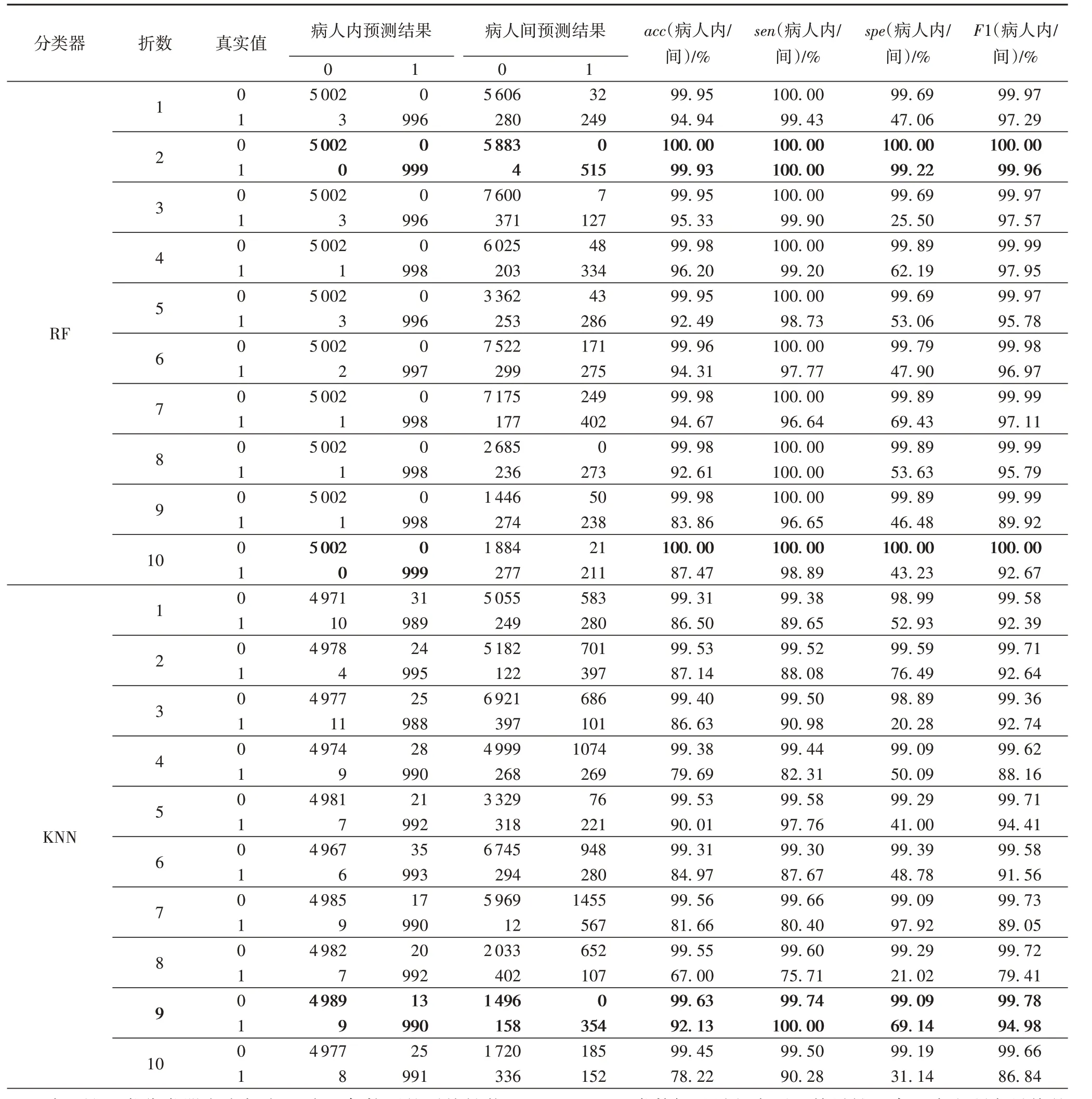
续表
表5 是三类分类器在十折交叉验证条件下的平均性能。分析表5 可知,随机森林分类器在病人内和病人间的相对检测效果均优于其他分类器。但是在病人间的分类中,三种分类器的心肌梗死检测特异性均较低,通过对实验数据进行分析,发现心肌梗死和正常心电数据的数据量比为49 909:5 284,两类数据差异很大因而特异性不高。本文研究最终的分类在使用主成分分析的方法进行降维进而完成分类操作时发现不能提高检测效果。
本文方法与其他学者的研究方法的对比结果如表6所示。

表5 各分类器在十折交叉验证下的平均性能Tab.5 Average performance of each classifier under ten-fold cross-validation
表6 中:QRS 为QRS 波群,LS-SVM 表示最小二乘支持向量机(Least Squares Support Vector Machine),MFB-CNN 表示多特征分支卷积神经网络(Multiple-Feature-Branch Convolutional Neural Network)。表6 中所列的其他学者的研究均没有使用十折交叉验证,交叉验证在防止过拟合方面有较为优异的性能。部分研究采用了单导联或者部分导联的心电信号实现心肌梗死的检测,在临床应用中采用部分导联进行心脏疾病诊断不符合医生诊断逻辑,诊断结果可信度不高。病人间诊断更具有临床实用性且更符合临床应用场景,但是很多学者都欠缺对病人间分类模式的验证。本文采用12 导联的熵值特征和统计特征进行检测,病人内和病人间两种模式下心梗检测结果均相比其他学者的研究均有所提高。
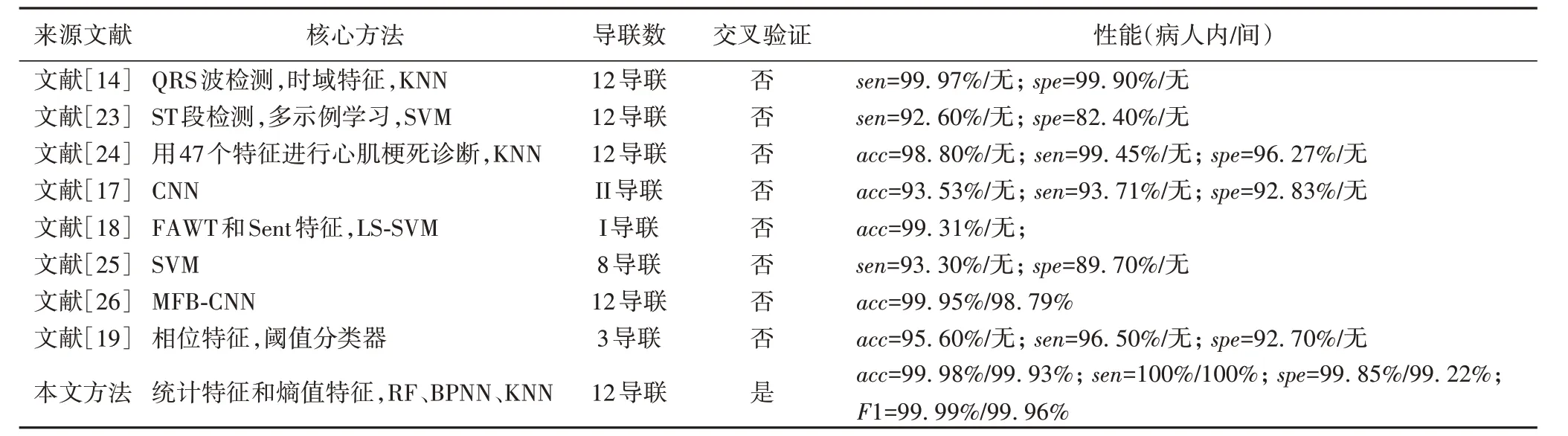
表6 本文方法与不同文献方法的结果对比Tab.6 Result comparison of the proposed method with different methods in references
4 结语
本文应用了PTB 数据库中的常规12 导联数据进行算法检验。在心肌梗死检测过程中,本文首先对12 导联数据进行预处理,在这个过程里包含数据高频滤波、去除基线漂移和数据增强。数据增强弥补了数据量过少的缺点。在特征提取方面,本文采取12 导联的统计特征(标准差、峰度系数和偏度系数)和熵值特征(香农熵、样本熵、模糊熵、近似熵和排列熵)融合的方法。在心电信号识别中,本文使用十折交叉验证结合神经网络算法、随机森林算法和KNN 算法的方法,十折交叉验证在防止模型过拟合方面有较好的效果。在病人内和病人间的实验中,随机森林分类器均取得了较好的检测性能,在病人内的检测中取得了准确率、敏感度、特异性和F1 值分别为99.98%、100%、99.85%和99.99%,在病人间检测中取得了准确率、敏感度、特异性和F1 值分别为94.56%、98.75%、55.07%、97.05%。通过对比其他研究者的方法,本文面向临床实际提出的基于病人间模式下的检测方法能够辅助诊断心肌梗死,具有较好的鲁棒性,能够辅助医生提高诊断效率,且对心梗患者实施心电监护具有重要意义。进一步地,基于心电图的心肌梗死辅助诊断技术的提升依赖于高质量且经医生标注的心电数据和高效的特征提取方法,后续的工作将致力于搜集心电数据和构建基于深度神经网络的辅助诊断模型。
