基于多尺度卷积特征融合的肺结节图像检索方法
2020-04-09顾军华戚永军孙哲然田泽培张亚娟
顾军华,王 锋,戚永军,孙哲然,田泽培,张亚娟
(1.电工设备可靠性与智能化国家重点实验室(河北工业大学),天津300401;2.河北省大数据计算重点实验室(河北工业大学),天津300401;3.河北工业大学人工智能与数据科学学院,天津300401;4.北华航天工业学院信息技术中心,河北廊坊065000)
0 引言
肺癌作为全球发病率和死亡率最高的癌症[1],正在严重威胁着人类的健康,能够在肺癌早期发现并诊断肺结节对于肺癌的治疗乃至治愈都能起到至关重要的作用。低剂量螺旋CT 扫描是早期发现肺癌的有效手段,一项对于55~74 岁的重度吸烟人群的筛查研究表明,接受低剂量CT扫描筛查人群的肺癌死亡率较接受X 线平片扫描筛查人群的肺癌死亡率低20%[2]。我国医学图像调查显示,放射科医生的数量增长远不及图像增长,因此,放射科医生工作压力巨大,并且在长时间的CT图像诊断过程中容易出现效率低、主观性大以及因生理疲劳出现的漏诊、误诊等问题。基于内容的图像检索(Content Based Image Retrieval,CBIR)为上述问题提出了决策支持,其过程主要分为特征提取模型构建、图像特征提取、相似度计算和相似度排序四个过程,最终返回相似度最高的检索结果。医务工作者通过检索可疑结节,并对检索结果进行分析,给出辅助诊断的意见,从而降低误诊率。
图像的特征提取是影响图像检索准确率的重要因素,而肺结节图像特征难以提取的主要原因是其大小不一的外在形态,如图1所示。近20年来,无数研究者为肺结节的图像特征提取方法付出了巨大努力:2000 年,Schnorrenberg 等[3]在活检分析支持系统中增加了图像检索功能,能检索活检切片图像,并利用包含57 个乳腺癌病例的数据进行了评估;Song 等[4]融合方向梯度直方图(Histogram of Oriented Gradients,HOG)[5]和局部二值模式(Local Binary Pattern,LBP)[5]特征发现肺部病变;2009年,Zhi等[6]采用尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[7]特征对医学图像进行特征提取,进而进行图像检索。近年来,由于深度学习方法的广泛研究使得计算机视觉领域各研究方向取得了长足进步,使用深度学习方法提取特征进行检索使得检索精度大大提高。2017 年,Ibanez 等[8]等 采 用 卷 积 神 经 网 络(Convolutional Neural Network,CNN)的特征提取方法,使用相对浅层的网络结构进行肺结节特征提取,并取得了69.22%的准确率;2018 年,Nishio 等[9]使用加入迁移学习方法的VGG[10]网络模型完成肺结节特征提取再进行分类;2018 年,Zhang 等[11]通过使用残差块堆叠的网络模型对提取的特征进行特征融合的方法提取肺结节图像特征,但是其准确率仍然不能满足现实需求。
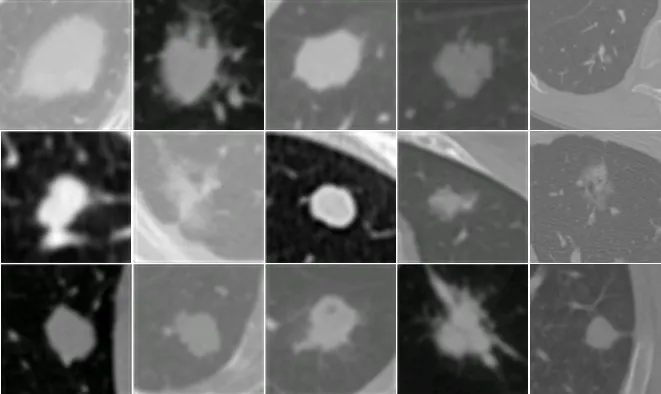
图1 不同尺寸的肺结节Fig.1 Pulmonary nodules of different sizes
针对肺结节高级语义特征难以提取、检索精度低的问题,本文提出了一种基于卷积特征融合的网络模型LMSCRnet 用于提取肺结节图像特征。由于肺结节尺寸大小不一,传统的串行单一尺寸卷积滤波器在对肺结节图像进行特征提取时效果不佳,因此本文采用多种尺度的卷积滤波器对肺结节图像同时卷积再进行特征融合的方法以获得完整的图像语义信息;随着网络层次的加深,能够获得更高级的语义特征,但是同时会伴随出现网络退化现象,为此,本文引入了SE-ResNeXt 块很好地解决了上述问题。最后,为满足现实对于在海量数据中完成检索任务的需求,本文将距离计算、排序过程部署到分布式平台上。
1 特征提取模型LMSCRnet
图像的特征提取对于提升图像检索的准确率至关重要,最大限度保留图像的信息是保障图像检索准确率的重要前提。针对肺结节尺寸大小不一的特性,本文提出了一种多尺度卷积特征融合的深度网络模型LMSCRnet 用于提取肺结节图像特征。网络模型总体结构如图2所示,其中:Conv代表卷积层,Concatenate 代表图像特征拼接操作,Avg-pooling 代表池化层。
肺结节大小范围为4~64,具有尺度多样的特点,针对这一特点,将输入的图像同时通过4 种不同尺寸的卷积核,大小依次为1×1、3×3、5×5、7×7,步长设为2,经过卷积之后,将得到的图像特征图通过Concatenate 操作进行特征融合。相对于传统的串行网络模型,本文提出的多尺度卷积、特征拼接方法可以从肺结节图像中更好地提取复杂特征,保证了特征的全面性、多样性。进行Concatenate 操作之后,选用深度为64、尺寸为3×3的卷积核进行卷积,步长设为1。在卷积层之后,为了提取更深层的特征,采用了3个SE-ResNeXt[12]块进行堆叠。为了充分利用全局空间和高度紧凑的特征以达到提高结节识别和分类性能的目的,将最后一个SE-ResNeXt 块和平均池化层的输入端连接起来。在池化层之后,将特征进行扁平化处理,然后再使用一个全连接层将所有的局部卷积特征连接成一个全局特征。softmax 激活函数可以将多个神经元的输出映射到(0,1)区间内,表示结节属于某一类的概率,从而得到分类的结果。函数定义为式(1),其中j=1,2,…,K,K为softmax 层输入输出元素个数,zj为输入向量的第j 个元素值,σ(z )j代表通过softmax层后对应位置的值。

为了在网络退化较小的前提下尽可能地加深网络以便学习更高级的特征,在网络中加入了3 个SE-ResNeXt Block,每个块的输出通道数分别设置为64、125 和256,每个SEResNeXt Block 由3 个单位块串联而成,单位块结构如图3(a)所示:Global avgpooling 代表全局池化,FC 代表全连接层,ReLU 代 表ReLU 激 活 函 数,Sigmoid 代 表Sigmoid 激 活 函 数,Scale 代表通道权重与通道特征之间的乘法加权。SEResNeXt 是在ResNeXt 的基础之上加入了SEnet[12]的思想,考虑特征通道之间的关联,能够有效地在增加不多的计算量的基础之上提取更多的图像特征。ResNeXt[13]是基于Resnet[14]与Inception[15]的产物,结构简单、易懂又足够强大,所传递的信息也不会因为层数的增加而有太多丢失,其网络结构如图3(b)所示,n 代表n 通道输入输出,layer 以(输入通道,卷积核尺寸,输出通道)的形式表述。
本文通过使用多尺度卷积核进行卷积,在面对大小尺度不一的肺结节图像时能够更好地提取图像特征,同时SEResNeXt 块的引入使得加深网络模型学习高级特征的同时,网络退化较小,显著提高了网络的性能。
为了确定网络中哪一层对图像进行特征表示能够最大限度完整地保留图像信息以进行图像检索,使用网络中的相关层提取的特征进行检索实验,实验结果显示,使用全局平均池化层提取的特征作为图像的特征表示进行检索的准确率最高。
1.1 图像特征匹配过程
随着肺部图像数据的日益增长,为满足海量肺结节图像数据检索需求,本文将相似度匹配过程部署到Spark分布式平台[16]上。相对于Hadoop 平台[17],基于内存的Spark 分布式并行计算平台在继承了Hadoop 平台优点的同时,由于其在运算时的中间结果存储在内存中,在处理迭代问题时拥有更高的性能,处理能力更强。因此,基于Spark分布式计算平台,将图像检索的相似度计算、排序过程并行设计,建立了并行检索模式。
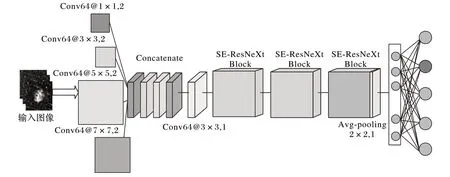
图2 总体网络结构Fig.2 Overall network structure
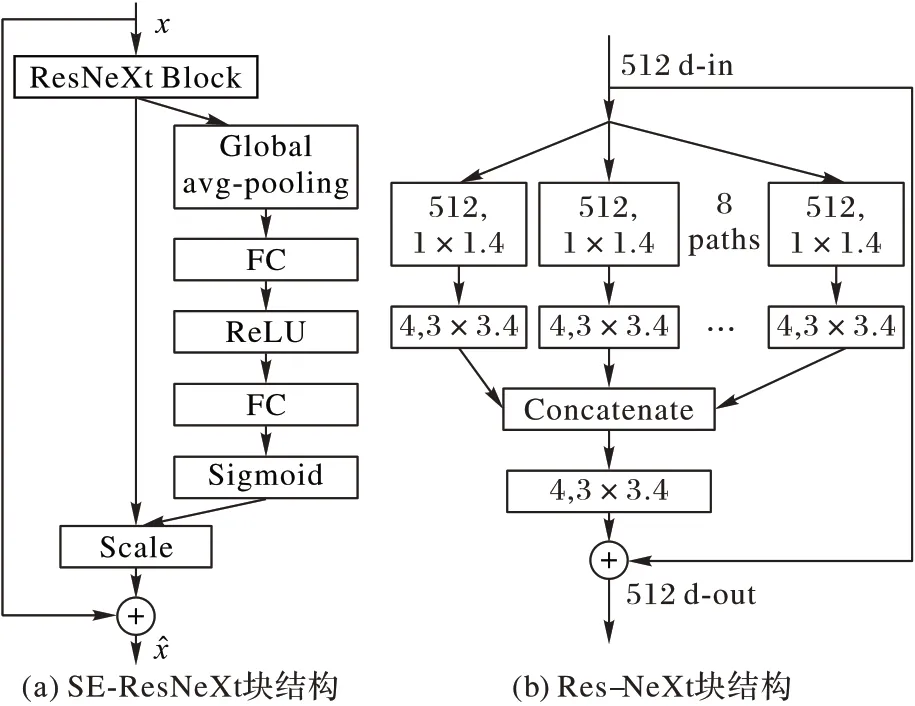
图3 SE-ResNeXt和ResNeXt的结构Fig.3 Structures of SE-ResNeXt and ResNeXt
本文的检索方法在Spark 上的并行实现主要分为五个步骤:1)将图像库通过训练好的网络模型形成相应的图像特征库,并存储到Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)[18]中;2)从HDFS 上读取特征库数据,并将数据划分到不同的分区中;3)对分区上的特征数据与待检图像特征进行相似度计算;4)对分区度量结果进行升序排序计算;5)合并所有分区排序结果,生成特征库中图像根据与待检图像的相似度作为排序依据的有序序列。算法并行实现过程如图4所示。
1.2 相似度度量方法
欧氏距离作为一种图像检索领域常用的相似度度量方法,以其简单的计算、易于理解的物理意义等优点在图像检索领域被广泛使用。本文使用欧氏距离作为两个特征之间的相似度度量方法,取值越小表明两个特征表示的两张肺结节图像的相似度越高。欧氏距离定义如式(2)所示:
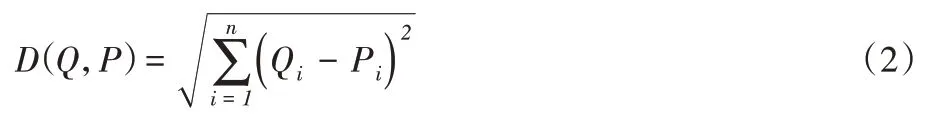
其中:Qi代表待检目标图像特征的第i 个分量,Pi代表图像特征库中单张图像特征的第i个分量。
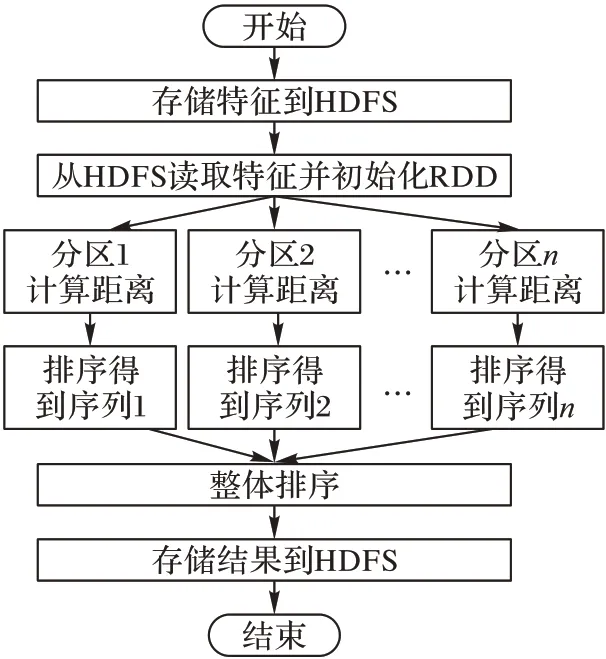
图4 本文算法并行实现过程Fig.4 Parallel implementation process of the proposed algorithm
2 实验与分析
2.1 数据集
具有大规模标注信息的数据集对于模型的学习和推广至关重要[19],如COCO[20]、ImageNet[21]等。LIDC-IDRI 数据集[22]是由美国国家癌症研究所发起收集的,是目前应用最多的肺部CT 图像数据集。该数据集中共收录了1 018 个实例,244 527 张肺部切片图像,数据集大小为124 GB,对于每个研究实例都由4 位经验丰富的医生进行标注。但是相对于肺结节大小,肺实质占据整张图像的大部分面积,对于整张肺部切片图像来说有研究价值的部分比较小。因此,对数据集进行预处理,根据数据集的标注信息将肺结节图像提取出来,只保留有研究价值的部分。
数据集中最大的结节大小为63 个像素,所以提取肺结节图像尺寸定为64×64。在提取肺结节图像之后,以数据集标注信息中的良恶性等级标签为标准将图像分为五类,标签信息为1~5。分类之后出现类间数据量不平衡的情况,采用旋转、增加高斯、椒盐噪声的方式生成更多的肺结节图像,以在解决类间不平衡问题的同时避免网络模型过拟合,旋转角度为θ ∈[-10°,10°]。
最后,本文采用的数据集类别为5 类,每类3 277 张,共计16 385 张。在训练网络模型时取每类的2 950 张(共计14 750张)作为训练集,剩余的每类327 张(共计1 635 张)作为测试集;在测试检索性能时将训练集作为图像库,测试集的每张图像作为待检目标图像;在验证是否能够处理海量图像检索任务时从每类中随机抽取5 000张、10 000张、15 000张作为图像库,在剩余图像中随机抽取一张作为待检目标图像。
2.2 实验环境
本文实验分为线上和线下部分,线下部分完成特征提取及索引,线上部分完成图像检索。线下部分实验操作系统为Ubuntu 16.04,GPU 为Nvidia Quadro P5000,GPU 显存32 GB,内存256 GB;线上部分为Spark 计算机集群,集群为Spark2.0.0,集群环境包含6 个节点,其中1 个Master 节点,5个Worker 节点,每个节点的配置相同,且处在同一个局域网内,操作系统为CentOs 6.5,CPU 为E5-2620 v4,核心频率2.10 GHz,节点内存32 GB。
2.3 实验方法
在对模型进行训练过程中,将初始学习率设置为0.1,衰减率设为5×10-4,batch_size 设为32,损失函数使用交叉熵。为了防止出现过拟合现象,使用了L2 正则化和dropout[23],dropout 率设为0.5,dropout 的机制使模型训练时随机让网络某些隐含层神经元的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重需保留下来暂时不更新,到下次样本输入时可能再次工作。选择Momentum优化器对模型进行优化,同时加入了Batch Normalization[24],有效地解决了梯度消失问题。epoch 设为500,在153 个epoch之后达到最优解。在模型训练完成之后使用测试集对网络进行验证,测试模型在分类能力上的表现。然后按照第1 章所述方法进行检索实验,同时计算检索平均准确率。
2.4 实验结果
2.4.1 肺结节分类
肺结节图像分类效果的好坏直接影响肺结节图像的检索结果,因此使用LMSCRnet 对肺结节分类,查看模型在分类上的表现。本文将提出的网络模型与传统机器学习方法SIFT、深度学习方法VGG网络模型、文献[8]提出的CNN方法、文献[11]提出的基于残差块的网络模型以及改进之前的SEResNeXt 网络模型进行了对比实验。采用准确率作为评价指标,如式(3)所示,其中:P为正确分类样本数量,N为错误分类样本数量,P+N代表样本总数。

将文献[8]所提方法记为CNNs,文献[9]所提方法记为M_resnet,表1中的实验结果显示本文提出的特征提取模型在分类上的表现准确率为86.78%,高于其他对比方法。这说明本文提出的特征提取模型能够更好地提取图像高级语义信息、完成图像分类。
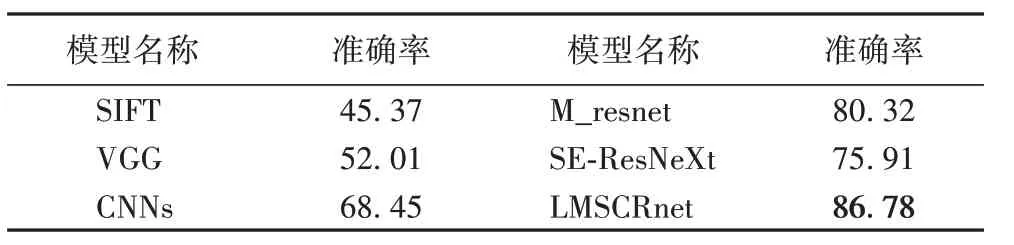
表1 肺结节分类实验结果 单位:%Tab.1 Experimental results on pulmonary nodule classification unit:%
2.4.2 特征选择对于检索结果的影响
为了确定使用网络中的哪一层提取的图像作为图像的特征表示才能获得最好的检索效果,将3 个SE-ResNeXt 块提取的特征和全局平均池化层提取的特征进行检索实验,并计算其检索查准率。查准率计算公式如式(4)所示,其中:Nm为返回正确的图像结果个数,K为返回检索结果总数。

实验结果如图4 所示,横轴代表网络层名称,纵轴为查准率,全局池化层的查准率相较于其他三层最高,能够最好地提取图像特征。因此,采用全局池化层对图像进行特征提取。
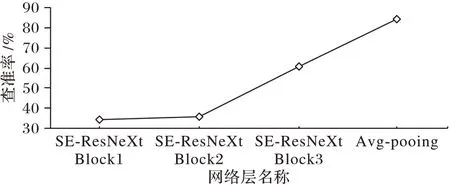
图5 特征选择对于检索结果的影响Fig.5 Influence of feature selection on retrieval result
2.4.3 肺结节检索
选取每张测试图像检索结果序列的前100 张图像,查看每张检索结果图像的类别是否与测试图像的类别相同,相同则为检索正确,反之为错误,并计算查准率,最后计算整个测试集的平均查准率。
表2 所示的实验结果中,本文提出的基于多尺度卷积特征融合的特征提取模型的平均查准率为84.48%,高于其他的特征提取模型,表明本文的特征提取模型能够更好地提取图像高级语义信息。
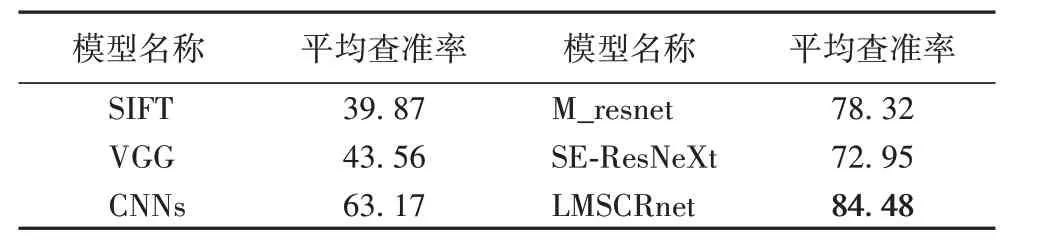
表2 肺结节检索实验结果 单位:%Tab.2 Experimental results of pulmonary nodule retrieval unit:%
2.4.4 并行优化
实验通过改变图像库的数据量大小,分析算法在Spark平台上不同节点数目计算所需时间,进而通过计算加速比来评价算法的并行效果。加速比Sp计算如式(5)所示,其中:t为使用1个节点实验所需时间,tp为使用p个节点实验所需时间。

图像库中图像分别取5 000 张、10 000 张、15 000 张时,实验结果如图6所示。通过图6可知,算法的加速比与节点数目的关系近似线性正比关系,因此,本文算法在并行框架上拥有较好的并行效果,能够处理海量图像数据检索任务。
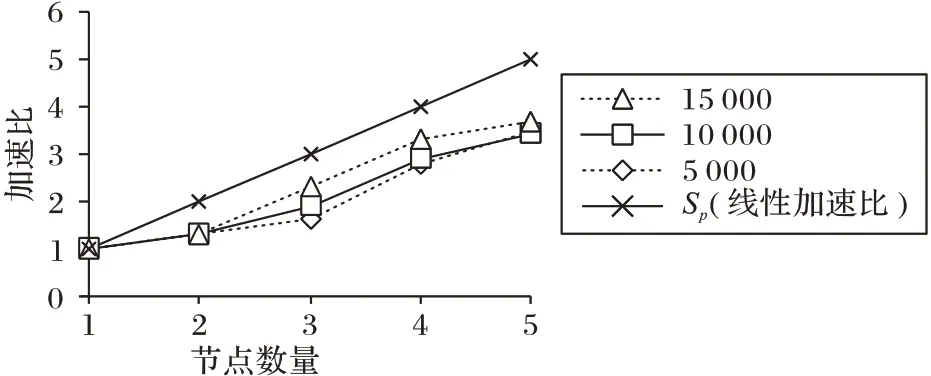
图6 所提算法在不同节点数目下的加速比Fig.6 Speedup of the proposed algorithm with different number of nodes
3 结语
肺结节图像检索对于医生来说能够起到辅助诊断的作用,但大数据量的图像检索存在准确率不高、检索速度慢的问题。基于上述问题,本文提出了一种多尺度卷积特征融合网络模型LMSCRnet 提取图像特征,再将距离计算相似度匹配等过程部署到Spark并行平台上。实验结果表明,本文提出的网络模型能够有效提高肺结节图像检索的准确率,并且通过将特征距离计算及排序过程部署到Spark平台上,随着集群节点数目增加,执行效率不断提高,算法加速比近似于线性增长,说明该算法拥有良好的扩展性和并行性,能够满足现实对于海量图像数据检索的需求。
