目标依赖的作者身份识别方法
2020-04-09李扬,张伟*,彭晨
李 扬,张 伟*,彭 晨
(1.华东师范大学计算机科学与技术学院,上海200062;2.中国科学院电子学研究所苏州研究院,江苏苏州215123)
0 引言
作者身份识别(Authorship Attribution)的主要思路是将文档中隐含的作者无意识的写作习惯通过某些特征表示出来,凸显作品的文学特征及写作风格,以确定匿名文本的作者。作者身份识别可以在许多实际问题中发挥作用,比如,可以帮助历史学家从一些候选的作者中推测出文献中的一段话的作者,可以帮助网络执法者鉴别出发布不良信息的用户等。
目前现有的许多方法都是根据不同的文本特点来设计文本特征,这些特征包括文本的单词级别的n 元语言模型(word n-gram)和字符级别的n 元语言模型(character n-gram)、文本的主题分布、文本的语法和语义特征等[1]。根据不同的文本特征,可以设计使用不同的方法。支持向量机(Support Vector Machine,SVM)、随机森林(Random Forests,RF)和隐式狄利克雷(Latent Dirichlet allocation,LDA)主题模型等都是解决作者身份识别问题常用的方法[2-3]。近年来,深度学习技术在文本表示方面取得了很好的效果,因此卷积神经网络(Convolutional Neural Network,CNN)和长短期记忆(Long Short-Term Memory,LSTM)神经网络也被用来解决作者身份识别问题[4-7]。
但是,在实际问题中,作者身份识别问题通常被限定在某一范围内。比如,法官想要通过一篇文档来确定犯罪嫌疑人,而且证据表明犯罪嫌疑人是一个年龄在40 和50 岁之间的女性。如果利用现有的方法,即仅利用文档进行作者身份识别,判断的结果可能是一个年龄在20和30岁之间的男性,显然这个结论是错误的。原因在于现有的方法没有利用作者依赖的信息,即在开放域上利用文档预测作者,忽略了依赖信息的重要性。
通常来讲,作者身份的限定条件可能是某种离散的属性,比如性别、年龄和婚姻状况等,但由于上述信息包含用户隐私,获取成本比较高,因此本文使用易于获得的亚马逊商品评论作为实验数据集。在商品评论数据集中,用户选择购买某种商品与其年龄、性别、收入情况和兴趣爱好等方面息息相关,可以在某种程度上反映用户的属性信息。因此,选择使用商品ID 作为限定条件,提出了一种目标依赖的作者身份识别算法,可以避免复杂的文本特征设计,同时有效利用依赖信息进行作者身份预测。本文的主要工作如下:1)提出了一种使用目标依赖信息解决作者身份识别问题的算法,探索了两种不同的信息融合方式,并在亚马逊电影评论和CD评论数据集上证明了这两种融合方式可以用于解决限定条件下的作者身份识别问题。2)提出了一种使用BERT(Bidirectional Encoder Representation from Transformer)提取文本特征的方法,避免了针对不同类型的数据集设计不同文本特征的复杂性,并用实验验证了这种方法优于目前已有的文本特征提取方法。
1 相关研究
1.1 文本建模与作者身份识别问题
针对文本建模,许多工作研究了不同的文本特征提取方法,大致可以分为以下几种特征:1)词汇级别的特征,包括单词长度、文档长度、文档中词汇的丰富程度和错误词汇数量等;2)字符级别的特征,包括字符的类别(字母或者数字)和字符n 元模型等;3)语法特征,包括词性和句子结构等;4)语义特征,包括语义依赖分析和功能分析等。考虑到评论数据的生成受到用户和商品的同时影响,Zhang 等[8-9]利用主题模型和矩阵分解模型同时对用户评论和商品进行建模。
之前的研究中,作者身份识别大致分为两种思路[9]。第一种思路是基于相似度的方法。这种方法的做法是将作者的所有文本信息拼接为单个文档,将单个文档的特征作为该作者的特征。对于一条新的文本,通过比较该文本与已知文本的相似度,将相似度最高的已知文本的作者作为未知文本的预测结果。基于这个思路,Seroussi等[10]将一个作者发布的所有文本组成一条文本,然后使用主题模型的方法从文本中提取出文本的主题分布作为作者的特征,对于一条新的文本,计算其主题分布与作者特征之间的Hellinger 距离,距离最小的作者作为预测结果。另一个思路是基于分类的思想,大多数的研究都基于此方法。Schwartz 等[1]使用单词级别n 元模型和字符级别的n 元模型作为文本的特征,这样可以将一段文本信息映射为二值的特征向量,然后使用支持向量机(SVM)进行分类。Zhang 等[11]除了使用n 元模型,还加入了语义特征,具体操作是:对文本进行语法分析得到文本的语法树,并对树中的每一个节点进行编码,将这些节点的编码作为文本的语义特征;接下来,将文本的语义信息和内容信息作为两个不同的通道使用CNN进行分类。
以上方法与本文提出的方法最大不同之处有两点:一是需要复杂的特征设计与处理;二是忽视了在实际问题中作者身份存在限定条件这一特征,仅利用文档信息进行作者身份判定。这些方法可能得出与限定条件相悖的结论。
1.2 预训练语言模型
在自然语言处理领域,词向量被广泛应用在多种任务中,比如,文本分类、问答系统以及文本检索等。Word2Vec[12]是目前最常用的词嵌入模型之一,它实际上是一种浅层的神经网络模。常用的模型包括根据上下文出现的词语来预测当前词语生成概率的连续词袋(Continues Bag of Words,CBOW)模型和根据上下文的词语预测当前词语生成概率的跳字(Skipgram)模型。但是由于Word2Vec 输入的上下文有限,使得其无法解决多义词的情况。BERT[13]是一种新的语言表示模型。不同于Word2Vec,BERT 使用文本内容的左、右语境进行预训练得到文本的深度双向表征,因此,BERT 通过添加额外的一层神经网络进行微调,就可以在多种任务上达到最优的效果。本文将通过BERT模型得到的文档向量作为文本特征。
1.3 多模态学习
多模态学习是一种利用多种数据类型进行学习的方式。多模态学习需要利用好各种数据类型的内在关系,使得不同的数据类型可以提供有效且互补的信息。信息融合首要的问题是解决融合发生的位置,一般可以分为三种,分别是特征多模态融合(feature multimodal fusion)、决策多模态融合(decision multimodal fusion)和混合多模态融合(hybrid multimodal fusion)[14]。特征多模态融合是对不同的特征在进入模型之前进行融合;决策多模态融合方式需要在特征输入模型之前保持相互独立,而在各自通过模型之后进行融合;混合多模态融合既在输入之前进行融合又需在通过模型之后进行融合。其次需要解决融合内容这一问题,不同的数据类型有不同的表示方式,如何选择数据的表示类型是解决这一问题的关键。
本文探索了两种信息融合方式在作者身份识别问题中的应用,分别代表了前期融合和后期融合:前期融合和后期融合的区别在于融合发生的位置不同,前期融合在输入模型之前对不同的数据类型进行融合,后期融合是对不同的数据类型在输入模型之后进行融合。
2 目标依赖作者身份识别算法
2.1 问题描述与符号定义
设数据集中包含的用户集合为U={u1,u2,…,un},评论集合为R={r1,r2,…,rm},商品集合为D={d1,d2,…,dq},其中,n、m 和q 分别为用户数量、评论数量和商品数量。目标依赖的作者身份识别算法是根据作者产生的评论和对应评论的商品(ri,di)从候选集U 中找到对应的评论的作者ui。本文使用的符号表述见表1。

表1 符号定义Tab.1 Symbol definition
2.2 预训练文档特征提取
为了避免复杂的特征设计,本文采用BERT 提取预训练的词向量,如图1 所示。具体地,对于用户的评论文本,首先将其分词后得到Tok1,Tok2,…,Tokn,通过BERT 预训练模型,可以得到词向量表B。查询词向量表B 后得到Vec1,Vec2,…,Vecn分别对应Tok1,Tok2,…,Tokn的向量表示。文档向量表示是将Vec1,Vec2,…,Vecn拼接。如图1所示。
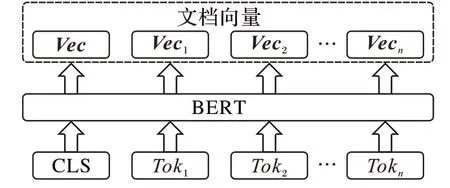
图1 预训练的文档特征提取Fig.1 Pre-trained document feature extraction
2.3 基于文档向量的卷积神经网络
卷积神经网络的输入为用户评论文本。首先将用户评论文本通过BERT 得到对应的文档向量。设定文本的最大长度为L,对于不足最大长度的作填充处理,超过最大长度的作截断处理。因此,输入即为文档向量E。
在得到输入文档向量后,需要对文档向量进行二维卷积操作。首先是一个卷积核H ∈ℝd×w作用于输入的文档向量,其中w 为卷积核的宽度。由此产生的特征矩阵O,经过激活函数σ 后加上偏置项b 可以得到文档向量经过卷积处理的特征:
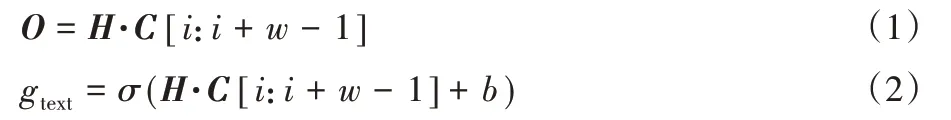
式(1)和式(2)定义为Conv2D。
最大池化作用于g:
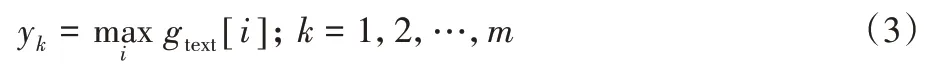
其中,m 是特征层的个数。最大池化保证了yk中含有每个特征层中最重要的信息。将所有的yk拼接起来即可得到文本特征:

在得到文本特征之后,需要使用Softmax 层进行分类。Softmax 层的输入为上述文本特征,为了得到模型对每个用户的预测分数,需要将ftext与权重矩阵W ∈ℝn×m相乘:

经过Softmax 函数归一化后可得该文档属于第i个作者的概率:

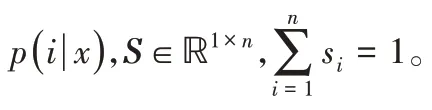
2.4 加入目标依赖信息的卷积神经网络
本文选择的依赖信息为作者评论对应的商品ID。商品ID 对于预测评论的作者的作用是可解释的:一个用户更倾向于购买自己喜欢的商品,这包括商品的类别、价格和美观程度等。商品ID是一个离散的数据,本文的目的是将此ID转化成为一个稠密的向量,使得这个向量可以从某种意义上表示该商品的各种特征。
接下来,对前期融合和后期模态两种融合方式进行详细的介绍。
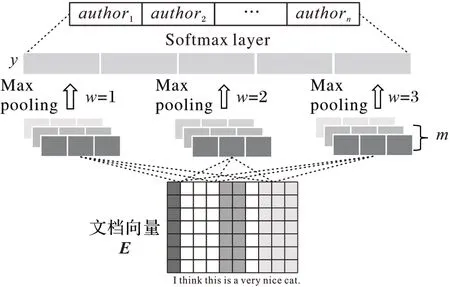
图2 基于文档向量的卷积神经网络Fig.2 CNN based on document vector
2.4.1 前期融合
前期融合将商品ID 向量与文档向量在输入到卷积神经网络之前进行融合。具体地,将商品ID通过查商品ID向量表P 得到对应的向量表示p。然后将该向量与文档向量进行拼接,将拼接后的向量输入到卷积神经网络中:

最大池化作用于g:
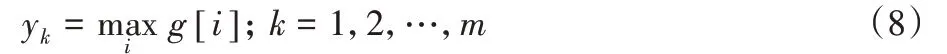
拼接yk:

最后使用Softmax层进行分类:

模型的结构如图3所示。

图3 前期融合模型Fig.3 Earlier-stage fusion model
2.4.2 后期融合
后期融合将商品ID 向量与经过卷积操作之后的文档向量进行拼接。具体地,将文档向量经过卷积操作后与商品ID向量进行拼接,商品ID 向量并没有参与卷积与最大池化操作:

最大池化作用于g:
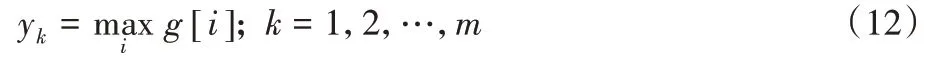
拼接yk:

使用Softmax函数分类:

模型结构如图4所示。
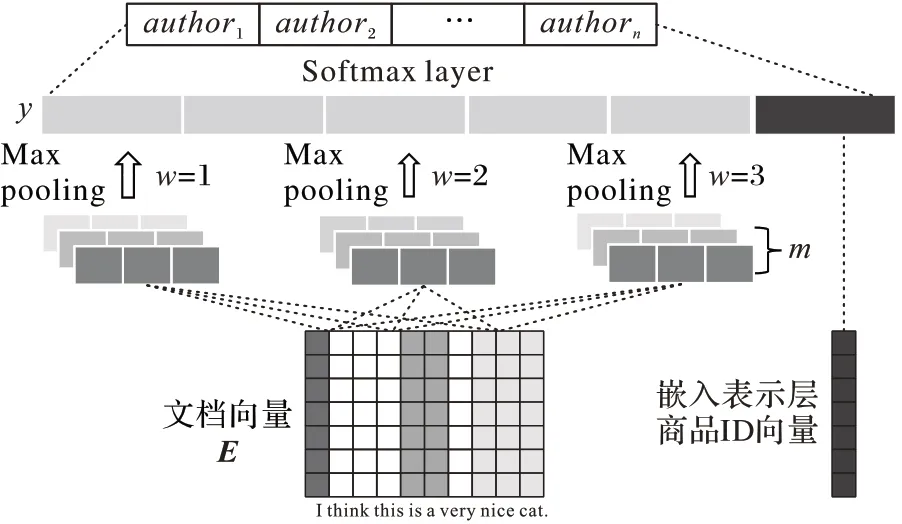
图4 后期融合模型Fig.4 Later-stage fusion model
3 实验结果及分析
3.1 指标定义与实验数据集

其中:N 为样本数量,I(⋅)为指示函数,y(n)为样本的真实标记,y'(n)为预测结果。
类别c的召回率定义为:


其中:TPc表示真正例数(True Positive,TP),FNc表示假负例数(False Negative,FN),FPc表示假正例数(False Positive,FP),TNC表示真负例数(True Negative,TN)。
宏召回率定义为:
类别c的精确率定义为:

宏精确率定义为:

宏F1定义为:
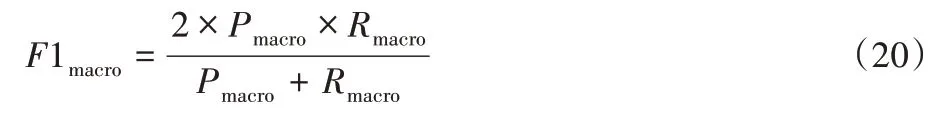
实验将原数据集划分为训练集∶验证集∶测试集=6∶2∶2,其中验证集用于调整参数,测试集用作最终测试。为了验证模型在不同领域的有效性,实验采用亚马逊电影评论(Amazon Movie_and_TV)和CD 评论(CDs_and_Vinyl_5)两个数据集。由于上述两个原始数据集比较稀疏,而本文的实验数据既要求同一作者包含一定数量的评论信息,同时也要求同一商品包含一定数量的评论信息。因此,需要从原始的数据集中检索出一些满足上述要求的用户和商品。两个数据集的统计信息如表2所示。
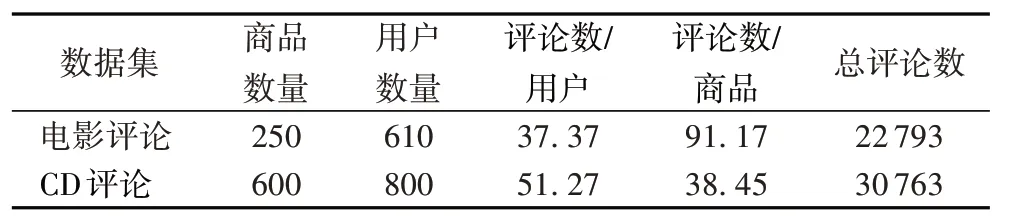
表2 数据集统计信息Tab.2 Dataset statistics
3.2 实验方法
表3 中包含了神经网络的具体结构及参数。为了减轻过拟合,在每个卷积层之后加入50%Dropout,使用ReLU 作为激活函数,使用Adam[16]作为优化器,学习率为10-4来训练网络。

表3 神经网络结构及超参数Tab.3 Neural network architecture and hyperparameters
3.3 不同实验方法对比
将所提出的模型与以下模型进行对比:
1)CNN-2:Shrestha 等[15]使用Character n-gram 作为输入,使用一个Embedding 层将输入映射为稠密的矩阵,然后依次通过卷积层和全连接层后使用Softmax 函数得到输出。实验发现,当选择2-gram 时,在验证集上的效果最好,将此模型记为CNN-2。
2)LSTM-1:LSTM 已经被成功用于文本分类的任务中[4-5]。使用Character n-gram 作为输入特征,将所有单向LSTM 单元的输出进行求和作为文本特征,最后用Softmax 函数进行分类。
3)SVM:Schwartz等[1]选择word n-gram和character n-gram作为输入,使用SVM 进行分类。实验证明,使用word n-gram和character n-gram 作为输入与仅仅使用character n-gram 作为输入的结果基本相同,在实验中将不考虑word n-gram。实验中使用character n-gram 长度为4 作为特征,线性核SVM 作为分类器。
4)RF:RF 是机器学习中经典的多分类方法,它包含多个决策树,在分类问题中往往具有很好的效果。实验采用character 3-gram 作为输入,使用sklearn 实现的随机森林分类器在验证集上调参,效果最好的分类器用于测试。
5)Syntax-CNN:Zhang 等[11]除了使用n 元模型,还加入了语义特征,这样可以将文本的语义信息和风格信息融合起来得到比较好的效果,但同时增加了模型复杂度。
6)LDA-S:Seroussi等[10]将作者的所有文本拼接后将单词频率作为LDA 的输入,得到每个作者的主题分布,使用Hellinger 距离度量新文本的主题分布与作者主题分布的距离,距离最近的为预测结果。
7)CNN-product:CNN-product 是一种仅利用商品ID 向量预测用户的方法。首先将商品ID 通过嵌入层将其表示为向量,然后通过一层卷积神经网络和最大池化得到卷积特征,最后使用Softmax函数进行分类。
不同方法的实验结果如表4所示。从表4中可以看出,后期融合在两个数据集上都取得了相比其他方法最好的结果,在以后的实验中,将后期融合记为TDAA(Target-Dependent method for Authorship Attribution)。TDAA 的效果优于前期融合,其原因可能是:前期融合将商品向量与文本向量视为相同的输入,忽视了两者所含的不同信息,使得模型无法学得互补的信息。
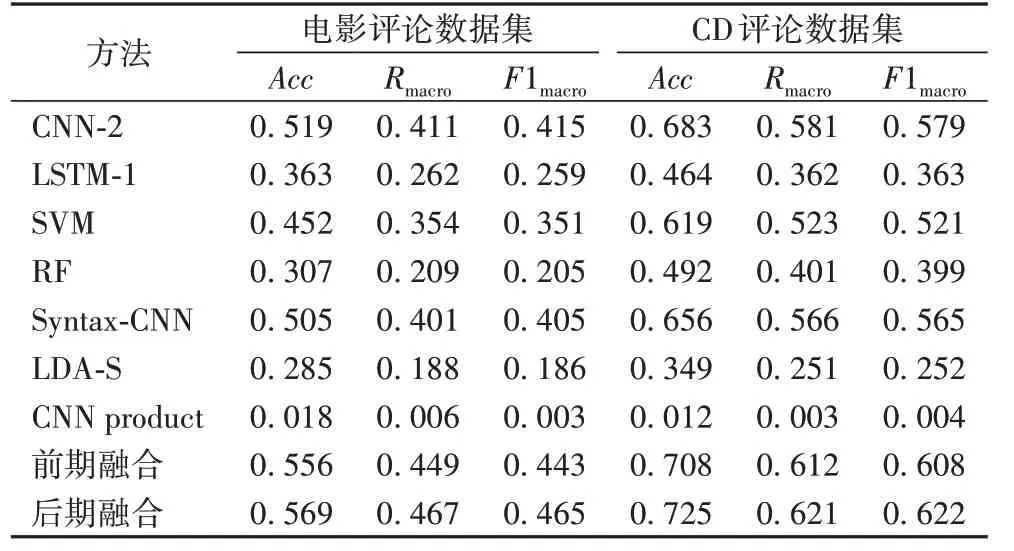
表4 两个数据集上不同方法的评价指标结果对比Tab.4 Comparison of evaluation results of different methods on two datasets
与仅利用商品信息的对比:仅利用商品信息的方法在两个数据集上的准确率均不足0.1,本文方法远高过它。
与仅利用文本信息对比:在对比方法中,本文方法比其他方法中最优的结果仍高出4%~5%。在传统的机器学习分类方法中,效果最好的是SVM,它也是被广泛应用在作者身份识别问题中的一种方法;LDA-S 效果不如其他机器学习方法的原因可能是商品评论数据集的主题分布比较集中,作者之间的主题分布差异不大,造成分类的难度增加;LSTM-1 捕获的信息可能更多是语义上的,与作者的写作风格无关,因此与其他深度学习方法差异较大。
3.4 目标依赖信息对作者身份识别效果的影响
为了比较在相同文本特征下加入目标信息与不加目标信息的结果,设计了如下实验:采用character n-gram 作为文本特征,使用CNN-2作为实验方法,融合方式采用后期融合与前期融合,对比有无依赖信息对效果的影响。在电影评论数据集上加入商品ID与不加商品ID的对比结果如表5所示。
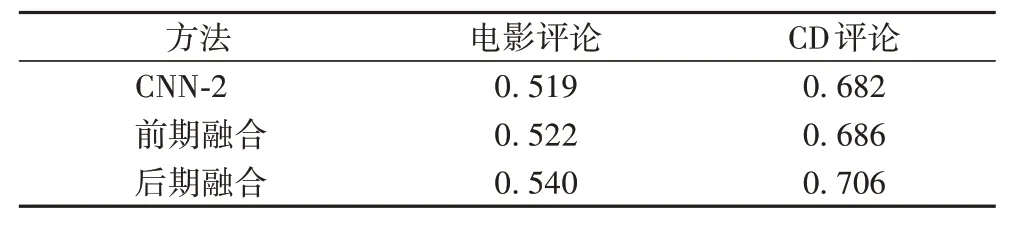
表5 n-gram特征下目标依赖信息对Acc的影响Tab.5 Impact of target-dependence information on Acc based on n-gram feature
采用BERT 提取的文本特征,使用CNN 作为实验方法,融合方式采用后期融合,对比有无依赖信息对实验结果的影响,实验结果如表6所示。
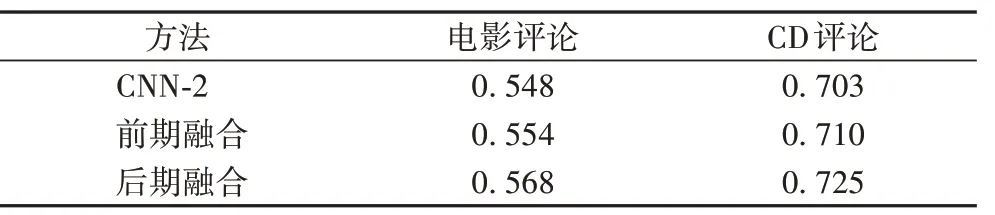
表6 预训练特征下目标依赖信息对Acc的影响Tab.6 Impact of target-dependence information on Acc based on pre-trained feature
对比表5和表6,可以得出如下结论:
1)使用相同的分类模型,通过BERT 提取的文本向量可以比使用character n-gram 作为文本特征的分类精确率高出2%~3%,说明使用BERT 提取文本特征的方法是一种普适且有效的方法。
2)后期融合是一种有效的融合方式。在使用相同文本特征的条件下,对目标依赖信息的后期融合可以比不加依赖信息的方法分类精确率高出2%左右。
3.5 不同长度n-gram对于实验结果的影响
为了探究不同长度的character n-gram 对于实验结果的影响,设计了n-gram 长度分别为1、2、3、4 的实验,所采用的方法为CNN、SVM、RF与LSTM,实验结果如图5所示。
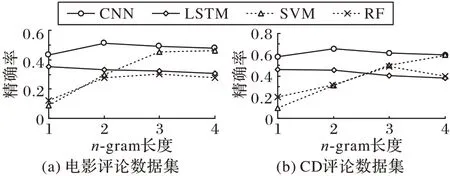
图5 两个数据集上n-gram长度对Acc的影响Fig.5 Impact of different n-gram length on Acc on two datasets
从图5 可以看出,不同长度的n-gram 对不同的方法影响不同。n-gram 长度的增加会造成LSTM 效果下降;而对于SVM,长度增加会使其效果变好;对于CNN 和RF 而言,存在一个最合适的长度使其性能最佳。因此,对于不同的方法首先要通过实验找出最佳的n-gram 长度。TDAA 由于没有使用n-gram特征,因此效果不受影响。
4 结语
本文提出了一种目标依赖的作者身份识别算法,解决了在限定条件下的作者身份识别问题。本文方法免去了复杂的特征设计,利用BERT 提取文本信息,使得该方法更加具有普适性。利用商品ID 作为对作者身份的限制条件,这种方法可以很好地推广到其他对作者身份有限制条件的应用场景中。
提高作者身份识别问题的效果的另一个思路是提高文本分类的效果。目前许多先进的模型被用于文本分类,如Li等[17]提出了一种对抗学习网络(Adversarial Network)来提高文本分类的效果;胶囊网络[18]最初被用在图像分类任务上,其动态路由机制实现了输出对输入的某种聚类;Zhao 等[19]首先尝试了使用胶囊网络实现文本分类,并取得了很好的效果。这些方法都可以被用来解决作者身份识别问题。
