基于BTM的物联网服务发现方法
2020-04-09王舒漫李爱萍段利国陈永乐
王舒漫,李爱萍,段利国,付 佳,陈永乐
(太原理工大学信息与计算机学院,太原030024)
0 引言
物联网(Internet of Things,IoT)作为我国战略性新兴产业的一个重要组成部分,正进入深化应用的新阶段[1]。随着5G 技术的推广和物联网设备的平价化,预计到2020 年会有500 亿设备接入物联网[1],同时,也导致用户从数量巨大的物联网设备中精确地定位满足其特定业务需求的设备变得越来越困难和耗时,如何快速高效地辅助用户发现满足需求的设备成为了目前急需解决的问题。
基于面向服务架构(Service-Oriented Architecture,SOA)的物联网使物联网的功能服务化[2],服务聚类是支持服务快速发现的有效辅助方法,聚类算法根据某一相似特性快速聚合相关服务,将数据划分成不同的集合,能提高服务发现的效率。在物联网服务发现中,Liu 等[3]通过提取物联网服务的主题签名,利用主题建模方法进行聚类来确定相似服务集。Jiang等[4]使用自然语言处理技术提取服务描述文本中的目标特征,计算两个服务目标特征之间的语义相似度,并采用K-means算法对服务进行聚类。
上述研究为物联网服务的发现提供了有益的方法参考。然而,物联网服务描述文档属于短文本,特征稀疏,信息量少,采用已有的服务发现方法进行聚类时会出现“类型无法识别、类型丢失”等现象,达不到理想效果。针对物联网服务的上述特点,本文提出了一种基于词对主题模型BTM(Biterm Topic Model)的物联网服务发现方法,根据服务的隐含主题进行聚类。
1 相关工作
物联网的概念最早可追溯到20世纪90年代,国际电信联盟在2005 年的ITU 互联网报告中正式给出“物联网”的概念:按照既定的协议,通过互联网实现物与物之间信息交换和通信,进而实现智能化识别、定位、跟踪、监控和管理的一种网络。
1.1 物联网场景中的“物”的标识
物联网场景中的“物”主要指的是现实环境中存在的感知识别、信息交互和智能控制的任何设备和资源。物联网是开放式的、动态变化式的、高分布式的,允许设备随时在不同地点以多种方式接入物联网中;然而对设备信息没有统一格式的描述,从而导致接入物联网的设备呈现多种形式的信息表达,设备间信息的交互和共享受限[5]。对物联网设备信息进行统一的资源描述,是面向物联网设备服务发现的基础。近年来,一些研究人员通过以下方法来解决目前物联网领域设备的统一描述问题。王书龙等[6]提出了基于本体的物联网设备资源描述模型,根据设备特点将其划分为5 个类资源进行综合描述,包括属性、控制、状态、历史信息和隐私。Santos等[7]提出了一种针对嵌入式资源的描述语言,该描述语言从功能、需求和限制三方面来描述设备资源。结合以上研究,本文根据异构物联网设备的共有特征,结合物联网服务发现的需求,选取功能、接口、工作状态、工作环境四部分来构建物联网服务描述模型,如图1 所示。其中,功能用于描述用户对服务功能的要求;接口用于描述用户对于相关的设备服务接入方式的要求,包括接口信息、通信方式等;工作状态用于描述用户对于服务相关联的设备的当前运行状态的要求;工作环境用于描述用户对于服务相关联的设备的正常工作环境的要求,包括工作温度、湿度、地理位置等。
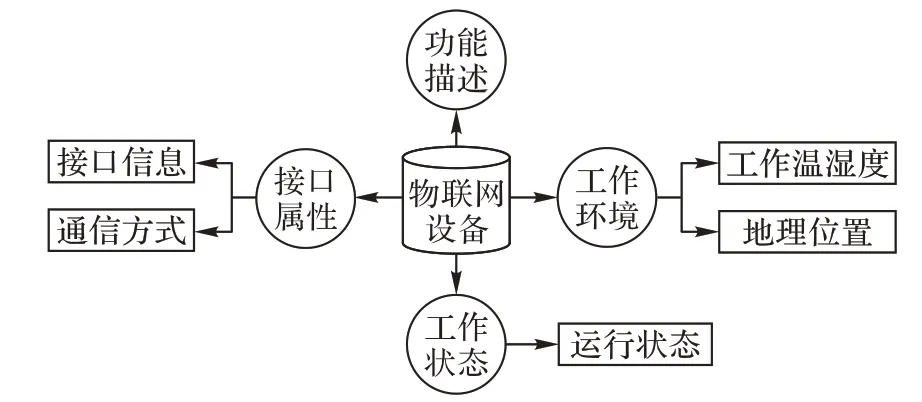
图1 物联网服务描述文本Fig.1 Service description text for IoT
1.2 现有的物联网服务发现方法
随着技术发展,物联网服务数量还在逐步呈不断上升的趋势,高效快速地发现最佳的服务成为亟待解决的问题。
通过挖掘服务的潜在语义信息对服务进行聚类,尤其是借助于主题模型进行服务发现,能有效地提高服务聚类的精度和速度,减少资源消耗。在主题模型中,认为一个服务描述文本包含多个隐含主题。Teixeira 等[8]提出采用概率发现的方法来进行服务发现,提高了服务发现的速度,并降低了服务资源的消耗。Casser 等[9]提出了一种混合语义的服务匹配方法,采用概率主题模型来学习服务的隐含主题,并通过主题相似度进行服务聚类。同时,由于物联网设备故障或损坏、设备的移动性等因素,使得物联网服务经常出现消失或重现等动态变化特点,使用主题模型对物联网服务进行主题建模成为解决服务动态变化的有效方法之一。
然而,物联网服务描述文档属于短文本,信息量少,缺乏足够的词频共现,直接使用传统的主题模型或其扩展模型对短文本进行建模,会导致严重的数据稀疏问题。因此,对语义信息稀少的短文本进行合理的建模,是实现高质量服务发现的关键。
近年来,现有的研究中有部分尝试将短文本进行扩充来进行主题模型的训练。魏强等[10]利用英文Wikipedia 对短文本的服务描述进行语义扩充,将短文本转换为长文本进行建模来构建高质量的主题模型。肖巧翔等[11]通过使用word2vec扩充服务描述语义,然后基于隐狄利克雷分配(Latent Dirichlet Allocation,LDA)模型对服务进行聚类。还有一些研究考虑利用外部知识库对短文本进行特征扩充,这也是一种较常见的方法,但恰当的外部数据集不容易找到,而且使用一个外部知识库会使建模精确度下降,同时,这些方法没有普遍性。2013 年,Yan 等[12]在LDA 和一元混合模型的基础上提出了基于词对信息的词对主题模型BTM,在不进行文本扩充的情况下能有效地克服短文本数据稀疏问题,同时考虑了词之间的语义联系。因此,本文使用BTM 对物联网服务的隐含主题进行挖掘,再通过主题进行服务聚类。
2 BTM
传统的主题模型模拟文本的生成过程,再通过参数估计得到隐含主题。与传统的主题模型相比,BTM 通过将文档转换为词对,直接对整个语料库的词对biterm(即共现的无序词对模式)进行建模来学习短文本中的主题。BTM 的图模型表示如图2所示。其中:φz表示主题z下的词对概率分布,θ表示语料库中全局主题概率分布,多项式分布的参数φz和θ 分别用于生成主题和词对;T 代表主题个数;|B|代表语料库biterm集合B中词对的总数;wi、wj和z分别代表词对b的两个词及其主题;α和β是Dirichlet先验分布的参数。
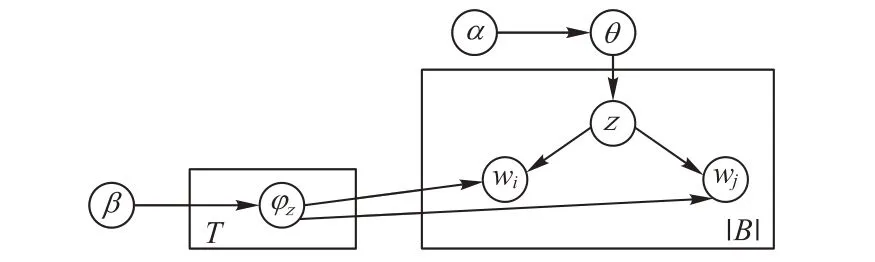
图2 BTM的图模型表示Fig.2 Graphical model representation of BTM
2.1 生成过程
在BTM中,语料库由多个主题组成,每个biterm独立地从特定主题中抽取,具体生成过程如下:
1)生成各个主题z下的主题-词分布φw|z~Dir(β)。
2)生成整个语料库的全局的主题分布θz~Dir(α)。
3)生成biterm集合B中的每个词对b=(wi,wj):
a)从全局的θ中抽取一个主题z~Mulit(θ);
b)从主题z中抽取两个词:wi,wj~Mulit(φw|z)。
按照以上的生成过程,词对b=(wi,wj)的联合概率可以表示为:

因此,产生BTM语料库的概率为:

2.2 参数估计
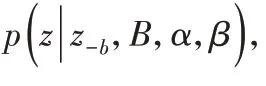
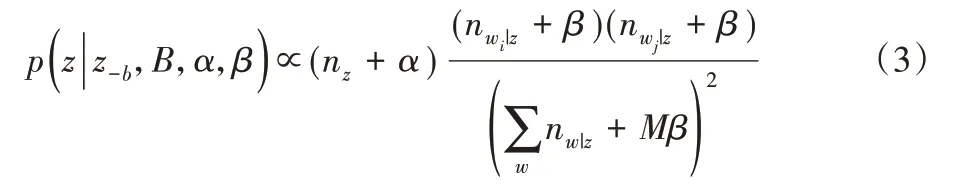
其中:z-b表示除了词对b 之外的所有biterm 的主题分配,nz表示biterm 分配给主题z的次数,nw|z表示词w 分配给主题z的次数,M 表示语料库中不同词的次数。一个词对b 被分配给主题z,词对b中的两个词wi、wj也会被分配到主题z上。
根据词对的主题分配的次数和词共现,全局主题分布θz和主题-词分布φw|z可以进行估计:
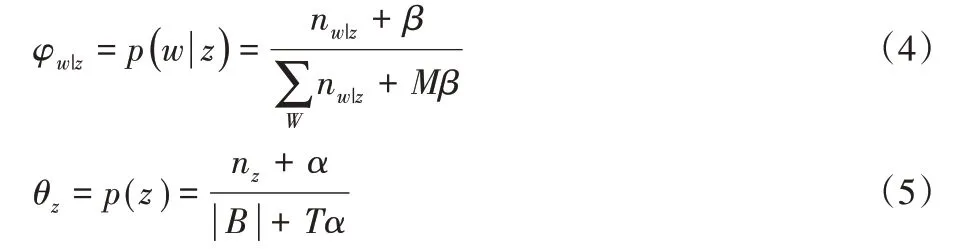
其中:φw|z表示主题z 中词w 的概率,θz表示主题z 的概率,|B|表示词对总数,T表示主题个数。
3 基于BTM的物联网服务发现
针对物联网服务的特性,本文提出了一种基于BTM 的物联网服务发现方法:首先通过预处理物联网服务文档,得到有效的服务特征数据集;接着利用BTM 提取服务的隐含主题,并通过全局主题分布θz和主题-词分布φw|z计算推理得到服务文档-主题概率分布p(z|d);然后利用基于最大距离的Kmeans 算法对服务进行聚类;最后,通过计算服务请求与候选服务集中服务的相似度,返回最佳匹配结果。基于BTM 的物联网服务发现框架如图3所示。
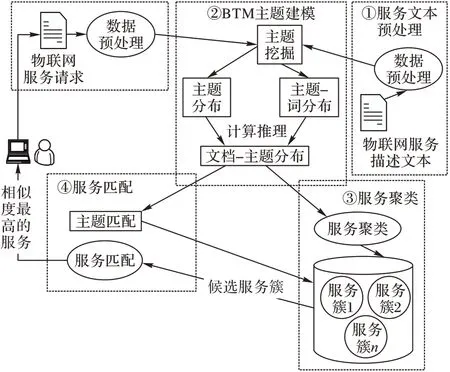
图3 基于BTM的物联网服务发现框架Fig.3 Service discovery framework for IoT based on BTM
3.1 数据预处理
通过特征提取、分词、去停用词、词干还原等方法,对物联网服务描述文档进行预处理。
1)对物联网服务描述文本中的“service name”“functional description”“interface type”等关键特征进行提取。
2)对提取的文本中的复合词进行拆分,如“Carbon-Dioxide”等。
3)利用正则表达式去除一些无关词汇和符号,如“and”“of”“&”等,避免对建模造成影响。
4)具有相同词干的单词具有相同的含义,如“recommended”和“recommending”具 有 相 同 的 词 干“recommend”,为了便于词语匹配,需利用Python 库NLTK 的Porter Stemmer进行词干还原。
3.2 BTM建模
在BTM 中,物联网服务描述文本文档可以被看作是包含隐含主题的文档。将预处理后的数据集作为BTM 的输入进行建模,学习其隐含主题,并通过Gibbs 抽样估计出全局主题分布θz和主题-词分布φw|z。由于BTM 不对文档生成过程进行建模,而是直接对语料库的词对进行建模,我们无法直接得到服务文档-主题概率分布,因此需要推理计算服务文档-主题分布p(z|d),将每个物联网服务描述文本表示为隐含主题分布向量。该分布相当于文档中词对的分布和词对-主题分布的乘积,计算公式为:

其中,以词对b 作为中间量,可以计算出文档d 中词对的条件概率分布p(b|d),计算公式如式(7)所示,nd(b)表示词对b 在文档d中出现的次数。

根据参数估计的结果,可计算得到词对-主题分布p(z|b)为:
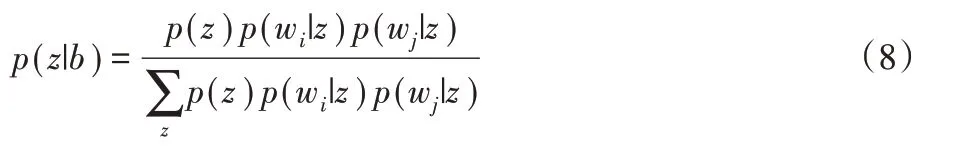
因此,在上述基础上,通过全局主题分布θz和主题-词分布φw|z计算推理得到服务文档-主题概率分布p(z|d),下面给出具体的主题挖掘过程的算法。
输入 主题数T,数据集services,参数α,参数β,迭代次数N;
输出 参数p(z|d)。

3.3 服务聚类
服务聚类是根据服务某一特征快速将服务划分成不同的集合。根据上述分析,得到服务文档使用主题表征的向量后,本文根据主题之间的相似度,采用K-means 算法对服务进行聚类。
为了避免K-means 算法在聚类时出现局部最优解问题,本文利用余弦相似度计算T 个主题向量两两之间的距离,并将距离最远的两个作为初始簇中心,在剩余的(T-2)个主题中,选取前面两个初始簇中心各自距离乘积最大值的那个样本点作为第三个初始簇中心,依此类推,可以找到K 个初始簇中心,进而在初始聚类中心的基础上进一步聚类。
具体的聚类算法过程如下:
步骤1 计算T 个服务主题两两间的相似度dis(n,1),选取dis(d1,d2)≥dis(di,dj)(i,j=1,2,…,T)作为两个初始服务簇中心。
步骤2 在剩余的T-2 个主题中,选取dis(d1,d3)×dis(d2,d3)≥dis(d1,di)×dis(d2,di)(i=1,2,…,K)作为第三个初始簇中心,以此类推得到K个服务簇中心。
步骤3 对于剩余的T-K 个主题,计算每个主题与K 个服务簇中心的距离,并将该主题聚集到距离最近的服务簇中。
步骤4 重新计算K个服务簇中心。
步骤5 重复步骤3、4,直到服务簇中心不再改变,或者达到其他终止条件。
图4是服务聚类的具体流程。
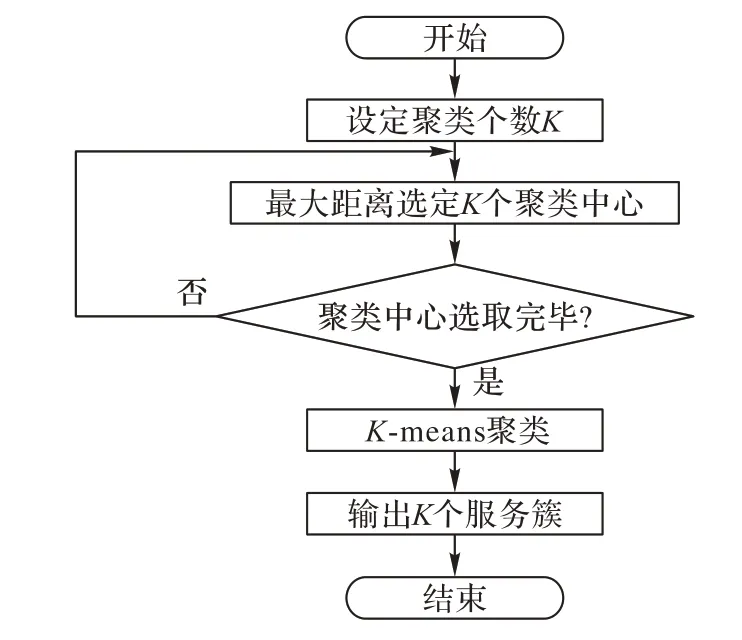
图4 服务聚类流程Fig.4 Flowchart of service clustering
3.4 服务匹配
服务匹配是指根据用户的服务请求,快速准确地匹配到与服务请求相似度最高的服务并返回。具体匹配过程如下:
1)对于用户的服务请求,通过BTM 获取服务请求的隐含主题,计算其隐含主题与各服务簇中心的距离,将相似度最高的服务簇作为候选服务簇返回;
2)对于候选服务簇中的每一个服务,利用余弦相似度计算其隐含主题与服务请求的隐含主题的相似度,并将相似度最高的服务作为匹配结果返回给用户。
4 实验分析
4.1 数据集及实验环境
本文使用采集的物联网设备服务数据集进行实验。其中,物联网工业现场设备服务数据集包含1 038 个服务,涉及不同型号的射频识别(Radio Frequency IDentification,RFID)标签、温度传感器、压力传感器、红外气体传感器、辐射传感器、电流变送器等多种物联网设备。表1 列出了传感器的部分参数信息。
所涉及算法通过Java、Python 编程语言实现,实验环境为Intel Core i5-3210M CPU@2.50 GHz,内存4.00 GB,32 位Windows 7操作系统,Eclipse及PyCharm开发平台。

表1 传感器的部分参数信息Tab.1 Some parameters information of sensors
4.2 评价指标
本文采用类内类间距离比值作为服务聚类质量的评价指标,对于服务聚类而言,同一类内部距离越小,不同类之间距离越大,表示该聚类效果明显,计算如下:

其中:R(K)表示类内类间距离比值,R(K)越小,聚类质量越好。
within(K)表示类内距离,即同一类中各服务之间的平均距离,本文使用所有类内距离的最大值作为整个数据集的类内距离,计算如下:
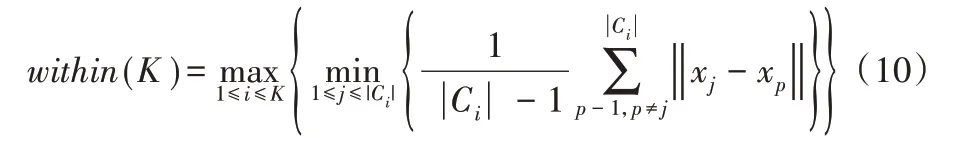
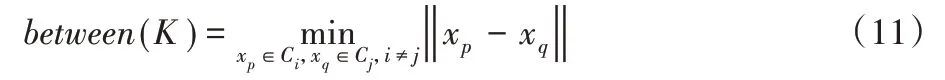
其中:i,j=1,2,…,K;xp和xq分别是属于Ci类和Cj的服务。
本文采用准确率Precision 和归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG)作为服务发现结果的综合评价指标。
Precision 是指检索得到的服务中正确服务的占比,如式
其中:|Ci|表示属于Ci类的服务的个数,xj和xp是属于Ci类的服务。
between(K)表示类间距离,即不同类最近的两个服务之间的距离,本文使用任意两个类之间距离的最小值作为整个数据集的类间距离,计算如下:(12)所示,其中,Ci表示第i 个聚类簇,A 表示检索得到的服务数中正确匹配的服务数,B表示检索得到的服务数。

NDCG 用来衡量和评价检索结果算法,与服务请求相似度最高的检索结果排位越靠前,NDCG的值越大,计算如下:
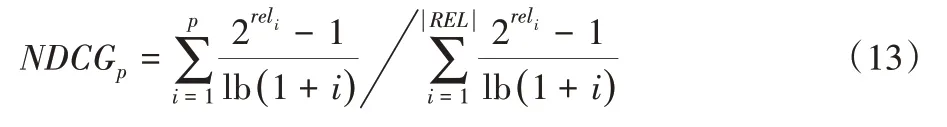
其中:reli表示在检索结果p 个文档中第i 个文档的相关等级,|REL|表示这p个文档按照相关性从大到小的顺序排序。
4.3 实验结果与分析
对物联网服务描述文本进行特征提取、分词、词干还原等操作,生成预处理文本作为BTM 建模的输入,BTM 中的主题数T 是一个经验值,根据数据集人为设定。参数α 一般取值,参数β一般取值0.01。经过主题挖掘,可以得到服务文档-主题分布矩阵,部分数据如表2 所示(结果取小数点后8位,加粗数据表示该文档中主题相关性最高的主题的概率)。

表2 服务文档-主题分布矩阵Tab.2 Service document-topic distribution matrix
4.3.1 BTM不同主题个数下服务聚类的比较
对具有不同主题数目的BTM 在用于物联网服务聚类时的情况进行了可视化对比。在该实验中,分别设定主题数为10、15、20、30 进行训练,得到的模型分别标记为BTM_10、BTM_15、BTM_20、BTM_30,部分实验结果如图5 所示,图中“十字”符为各聚类中心。从实验结果图对比分析发现,随着BTM 主题个数的细化,物联网服务的聚类效果发生明显的变化。计算不同主题数下各聚类数对应的类内类间距离比值,如表3所示。在K=7 时,不同主题数下类内类间距离比值较小;T=15,K=7 时,类内类间距离比值最小,整体聚类效果较好(迭代次数N取值为2 000)。
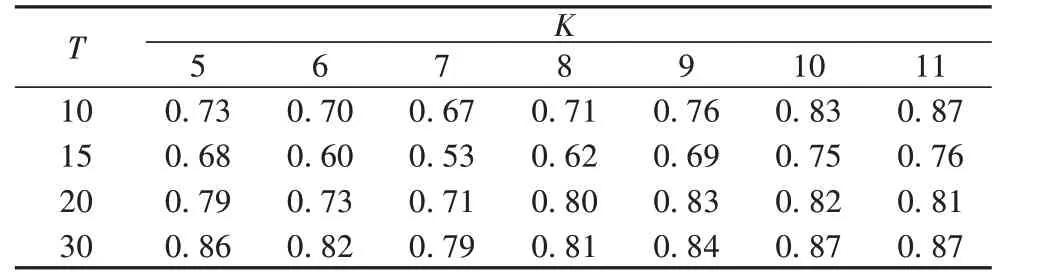
表3 不同主题数下各聚类数K对应的类内类间距离比值Tab.3 Distance ratio within and between classes under different number of topics with different K
4.3.2 不同方法下服务发现的比较
为了验证本文提出的基于BTM的物联网服务发现方法的有效性,采用4种现有服务发现研究中的常用方法TF-IDF[14]、LDA[15]、HDP[10]和LDA-K[16]作为基准与本文方法进行对比。
1)TF-IDF[14]:该方法用TF-IDF 算法计算服务之间的相似度,利用服务相似度使用K-means 方法进行服务聚类,是一种基于关键词的服务分类办法。
2)LDA[15]:该方法建立了三层贝叶斯模型,即文档-主题-词,基于LDA 模型的服务发现,通过LDA 建模提取服务的隐含主题信息,并根据不同主题对服务进行分类。LDA 对长文本进行主题挖掘有较好的效果,但处理短文本效果不明显。
3)HDP[10]:一种非参数贝叶斯主题模型,可以根据数据集自动确定主题数量。与LDA 模型相比,该方法更适合对具有实时性的数据集进行主题建模。
4)LDA-K[16]:使用LDA 将服务从词项空间转换到主题空间,通过建模学习得到服务的隐含主题,并使用K-means 算法对服务进行分类,该方法注重主题分布整体的相似度。
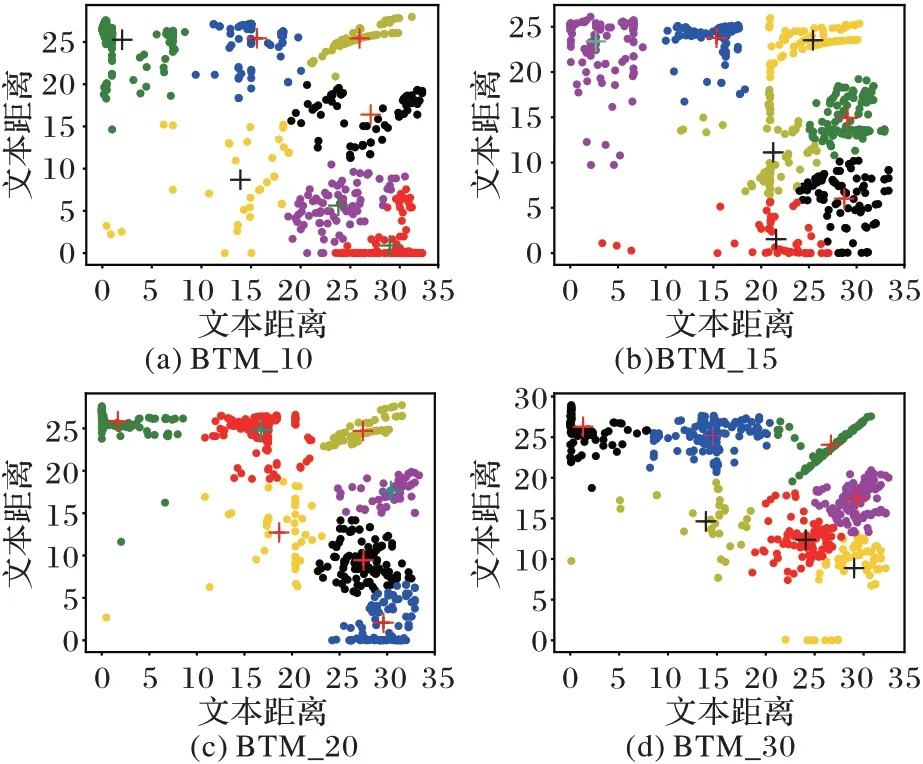
图5 不同主题个数下服务聚类效果Fig.5 Service clustering under different number of topics
在相同的实验环境下使用相同的数据集,对以上方法提出相同的服务请求进行查询。图6 和图7 分别给出了在不同数量的服务查询下5 种方法的Precision 和NDCG 指标的评估结果。图6是5种方法的物联网服务查询准确率的对比,可以看出,随着服务查询数量的增长,所有方法查准率都呈下降趋势,查询数量为35 时趋于稳定,本文方法整体上要优于其他方法。通过计算可知,基于BTM 的服务查询平均准确率相比TF-IDF、LDA、HDP 和LDA-K 方法分别提高了5.91%、4.01%、2.92%、2.46%。
图7 是5 种方法在不同查询数量下的NDCG 值对比,NDCG 值越大说明与服务请求相似度最高的检索结果排位越靠前。从图7 中可以看出,5 种方法的NDCG 值随着服务查询数量的增加均有所下降,相比其他4 种常用方法,本文方法的查询结果相似度更高。针对短文本的物联网服务,本文方法可以直接建模学习,无需进行文本扩充,有效解决了数据稀疏性问题,服务匹配返回最佳服务的效果得到了提升。
综合分析图6 和图7 的结果可以看出:TF-IDF 侧重通过计算文本中单词的词频和逆文档频率进行服务聚类;LDA、HDP 和LDA-K 主要针对于较长文本进行文档级建模;而BTM主题模型则是对词共现进行建模来增强主题挖掘,利用整个语料库的聚合模式来学习文本的隐含主题,有效地解决了短文档级的数据稀疏问题。因此,基于Precision 和NDCG 的综合分析,对文本较短、语义性差的物联网服务进行聚类,BTM有效地提高了服务发现的效果。
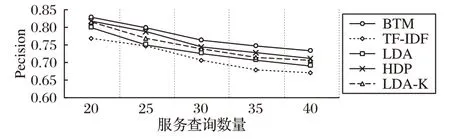
图6 5种方法的物联网服务查询准确率对比Fig.6 Precision comparison of IoT service query by five methods
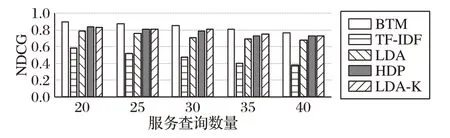
图7 5种方法在不同查询数量下的NDCG值对比Fig.7 NDCG comparison of five methods under different service queries
5 结语
如何快速有效地找到最佳服务以满足不断增长的服务需求是当前物联网应用中需要解决的关键问题之一,由于物联网服务文本短、语义性差等特性,应用现有的服务发现方法不能很好地匹配到最佳服务。针对这一问题,本文提出了一种基于BTM 的物联网服务发现方法,该方法利用BTM 挖掘物联网服务的隐含主题,对服务进行聚类并返回服务请求的最佳匹配结果。实验结果分析表明,该方法在Precision 和NDCG方面比常用的其他方法均有更好的效果。
本文的研究主要集中于物联网服务属于短文本、语义性差这一特性上,今后,我们将会在本文的基础上进一步考虑为物联网服务添加语义标记、服务的实时变化性等特性对物联网服务发现的影响。
