并行查询下查询执行计划的选择
2020-04-09裴泽锋牛保宁张锦文AmjadMuhammad
裴泽锋,牛保宁,张锦文,Amjad Muhammad
(太原理工大学信息与计算机学院,太原030024)
0 引言
查询是数据库系统的主要工作负载,查询效率的高低决定数据库运行性能的好坏。在数据库系统中,一个查询在真正执行前,查询优化器会生成多种查询执行计划(即查询在数据库中的执行方案)。尽管这些计划最终生成完全相同的结果集,但它们的执行效率却存在很大差异[1]。寻找较优的查询执行计划可以以较小的代价、在很大程度上缩短查询的响应时间,提高查询效率,进而提高数据库系统的性能。
目前,主流的数据库管理系统大都是通过查询优化器为查询选择较优执行计划,即查询的多种执行计划中,使查询响应时间较少的执行计划[1-3]。虽然不同数据库查询优化器实现有所差别,但它们都是依据执行代价——成本预算[4],为查询选择执行代价较小的执行计划作为该查询的较优执行计划。PostgreSQL 作为目前成功的开源数据库之一,它的优化算法效率高于其他数据库[1],本文以PostgreSQL 为对象,研究并行查询下查询执行计划的选择。查询执行前,客户端发出查询请求,解析器接收此请求并生成查询树,查询优化器中的规划器接收查询树并生成可能的查询执行计划,优化器依据动态规划或基因算法等计算每个执行计划的执行代价,从中选出执行代价较小的一个执行计划作为较优执行计划,并据此制定一个完整的规划树传递给执行器去执行[1,5]。
在数据库管理系统中,查询优化器在为查询生成不同的执行路径时,会综合考虑数据表的扫描方式、表间连接方式及连接顺序,在选择较优执行路径时,会依据查询的复杂程度选用不同的算法。因此,当数据库中只有一个查询运行时,如果查询不太复杂,查询优化器可以做到避免选择最差执行计划,且在为此类查询选择较优查询计划上可保持一定的准确率。
随着数据量的急剧增长、用户需求的不断变化,查询语句越发复杂。由于查询优化器优化算法本身的局限性,它只能依据数据库配置参数静态地为查询选择一个较优的执行计划,如果查询语句过于复杂,在统计信息不准确的情况下,成本估算的误差会成倍放大[6],因此会造成所选择的较优执行计划存在较大偏差。
特别地,在实际的数据库系统中,单一查询运行的情况比较罕见,大部分情况是不同查询在一起并行,因此,一个查询的运行会受到其他查询的影响,我们将其称为查询交互[7]。由于查询交互现象的存在,相比其单独运行,查询的响应时间会有显著变化,大部分查询的响应时间会变长。而且,查询并行数(MPL)越大,这种变化越发明显。
但是,目前的查询优化器并没有特别地考虑查询交互这一关键因素的存在,仅通过数据库参数配置很难准确反映查询交互。如果数据库配置参数固定,查询一旦确定,查询的较优执行计划随之确定。我们认为,在不同的查询组合(两个及两个以上查询并行运行时的查询集合)下,查询的较优执行计划可能也不同。假设当查询Q 单独运行时,查询优化器为该查询选择的较优查询计划为A。测试实验证明,多数情况下,当查询Q 与其他查询并行执行时,较优的执行计划不是A,如果按执行计划A 执行查询Q,会大幅度延长其执行时间,并严重影响其他查询的执行。因此,当多个不同查询并行时,目前的查询优化器并不能为查询选择当前查询组合下的较优执行计划。
为此,本文提出一种度量查询受查询交互影响程度大小的标准QIs(Query Interactions),为选择查询执行计划时定量考虑查询交互因素打下基础。针对并行查询下较优执行计划的选择,本文提出一种为查询动态选择当前查询组合下较优执行计划的方法TRating(Time Rating),该方法通过比较按照不同执行计划执行的查询在查询组合中受查询交互影响程度的大小,选择受查询交互影响较小的查询所对应的执行计划作为该查询的较优执行计划。
1 相关工作
目前,数据库管理系统通过查询优化器为查询选择较优执行计划。对于一个特定的查询,在查询执行前,查询优化器中的规划器负责为查询生成所有可能的执行计划,优化器依据成本预算从中选择执行代价最小的计划。针对复杂度不同的查询,查询优化器采用不同的算法进行处理。对于比较简单的查询,优化器采用动态规划算法,该算法搜索范围小且效率高;对于比较复杂的算法,则采用基因算法。基因算法是一种自适应的算法,可以在较短的时间内给出一个较优的解[1]。因此,对于数据库中单一运行的查询,查询优化器在为不太复杂的查询选择一个不坏的执行计划时可保持一定的准确率。但是,如果查询语句过于复杂,由于查询优化器成本估算算法的局限性,在统计信息估计不准确时,成本估算的误差会成倍放大,无法为查询选择较优的执行计划[7]。
特别地,在实际的数据库系统中,单一查询运行的情况比较少见,多数情况下是不同查询在一起并行,并行查询间存在查询交互,这种交互会导致某一查询的运行受到其他查询的影响[8]。由于查询优化器通过数据库配置参数静态地为查询选择查询执行计划,这种选择较优执行计划的方式尽管一定程度上反映了查询交互[9],但是其并没有特别地考虑查询交互这一关键因素的存在,无法准确地反映这种查询交互现象。在并行查询情景下,一个不坏的执行计划在另一查询组合中可能会变得不好,甚至更差[9]。在这种情况下,如果仍用原有执行计划去执行该查询,会严重影响该查询和其他查询的性能。因此,通过查询优化器已无法为查询准确地选择当前查询组合下较优的执行计划[10-11]。
目前,有关考虑查询交互的并行查询下较优执行计划的选择还没有专门的研究,大部分研究都是通过度量查询交互进而预测并行查询下查询的开销及响应时间[12-13],进而为查询调度提供一定的依据。目前对响应时间的预测方法主要集中于建立分析模型和统计模型。分析模型指把查询计划分段,估计每一段的工作量、系统的执行速率,然后求得该段的执行时间,最后把所有分段的执行时间加起来即可。统计模型指事先选取并运行一定量的样本,依据样本运行结果,给定输入和输出,根据训练集利用统计的方法训练模型,然后通过测试集来评判模型的性能,最后依据模型给出预测结果。利用统计模型预测并行查询的响应时间性能要优于分析模型。但是无论是分析模型还是统计模型,预测响应时间只能用于合理地调度一批查询的执行顺序。如果数据库中到达一批查询,按照先到先服务原则,先到查询需要首先被处理。在这种情况下,如果可以为该查询选择当前组合下较优的执行计划,这对提高查询效率,进而提高数据库运行性能尤为重要。
在多查询并行时,查询交互这一关键因素会影响查询的响应时间,进而影响查询效率。Duggan 等[14]利用BAL(Buffer Access Latency)即查询平均页读取时间来度量查询交互。查询Q单独运行时的BAL值等于该查询读取页花费的总时间除以此查询读取页的总数。多查询并行时,一个查询的BAL 值越大,则表示其受其他查询的影响程度越大,但这种度量只适用于中等大小查询。之后,张锦文等[15-16]提出QueryRating 来度量两个查询并行时查询交互的大小,由于其直接采用查询响应时间的比值大小来衡量查询交互的大小,宏观直接且使用范围广;但QueryRating 只适用于度量两个查询并行时,其中一个查询受另一个查询影响程度的大小。
基于以上查询交互度量使用范围的限制、查询优化器为查询选择当前查询组合下较优执行计划存在较大偏差的问题,本文提出了一种度量查询在多查询(MPL >2)并行下受查询交互影响程度大小的标准QIs,并基于查询交互提出了一种动态地为查询选择当前查询组合下较优执行计划的方法TRating。当用户提交的查询到达时,依据先到先服务原则,为先到查询选择当前查询组合下的较优执行计划提供了依据,具有一定的实际意义。
2 并行查询下较优执行计划的选择
2.1 QIs度量标准
Zhang 等[15]提出的QueryRating 的表达式如式(1),它直接计算响应时间的比值,建模复杂度低且准确率高。

QueryRating 可以度量两两查询并行时由于查询交互某一查询受到另一查询影响程度的大小。那么,如果多查询并行(MPL >2)时,由于查询交互,某一查询会受到其余任何一个查询的影响,如何度量多查询并行时特定查询所受查询交互影响程度的大小是为该查询选择当前查询组合下较优执行计划的基础。受Duggan 等[14]提出的B2L&BAL 模型预测查询性能的启发,本文通过考虑其他剩余每个查询对要研究查询的查询交互大小,提出了一种度量多查询并行时查询所受查询交互影响程度大小的标准QIs,表达式如下:

其中:

式(2)中:QIsqi表示多查询并行时,查询qi受其他剩余查询查询交互影响的大小;tqi表示查询qi单独运行时的响应时间;Durqi(Duration)可以看作查询qi所受其他查询查询交互影响的持续时长。
本文对式(2)、(3)作如下解释:多查询并行时,由于查询交互,对于某个查询,其余查询都会阻碍或促进该查询的执行。在考虑该查询受查询交互影响大小时,要分别考虑其余每个查询对该查询的影响即,因此,本文将不同的进行求和表示其余查询对该查询的影响大小。特别地,本文认为,该查询单独运行时间的长短会影响其受查询交互影响程度的持续时长,该查询单独运行时响应时间越长,则当其加入查询组合后,它受查询交互影响的持续时长也越长。因此,本文通过Durqi表示查询qi所受其他查询查询交互影响的持续时长。Durqi越大,表示其响应时间所占比例越大,则当该查询加入查询组合时,它所受其他查询查询交互影响的持续时长也越大。
由式(2)、(3)可以看出,QIsqi值越大,表示多查询并行时,由于查询交互,查询qi受其他查询的影响程度越大。
2.2 TRating方法的具体实现
在实际的数据库系统运行中,对于用户提交的查询,依据先到先服务原则,按照用户提交查询的先后顺序执行查询。那么,当某个查询到来时,为查询选择当前查询组合下较优的执行计划对提高查询效率十分必要。当按照特定执行计划执行的某查询在加入查询组合时,相比其他执行计划,按特定执行计划执行的某查询单独运行时的响应时间较短,且它所受查询交互影响程度越小,则其在查询组合中的响应时间越短。也就是说,按特定执行计划执行的某查询单独运行时的响应时间的长短和该查询所受查询交互影响程度的大小均会影响该查询在查询组合中最终的响应时间。响应时间越短的查询对应的执行计划即为该查询在当前查询组合中较优的执行计划。
为能准确地描述该方法,本文定义该方法中用到的符号见表1。

表1 相关符号定义Tab.1 Definition of related symbols
相比其他执行计划,如果按特定执行计划执行的某查询单独运行时的响应时间较长,即使该查询在查询组合中受其余查询的查询交互影响较小,它最终的响应时间也可能较长;同样地,如果按另一执行计划执行的该查询单独运行时的响应时间较短,即使该查询在查询组合中受其余查询的查询交互影响较大,它最终的响应时间也可能较短。考虑到这种现象的存在,将Facqw_k值作为每个查询计划的基准值。建立的表达式如下:

其中,Facqw_k表示按qw_k执行计划执行的查询单独运行时的响应时间所占该查询所有执行计划单独运行时响应时间之和的比值,以此作为每个查询执行计划的基准值。

该方法具体流程如下:
1)构建两张索引表IT1、IT2和两张数据表T1、T2,并将索引表IT1和数据表T1关联,索引表IT2和数据表T2关联。
索引表IT1存储A 中查询的查询编号i、每个查询对应的所有执行计划编号j,并将其分别设置为一级索引和二级索引。表结构见表2。

表2 索引表IT1Tab.2 Index table IT1
索引表IT2存储C 中查询组合编号f、每个查询组合中查询qi和查询qn所对应的QueryRating 值和的编号和,并将查询组合编号设置为一级索引。表结构见表3。

表3 索引表IT2Tab.3 Index table IT2
数据表T1、T2分别对应索引表IT1、IT2中数据实际值,另数据表T1需要存储每个qi_j单独运行时的响应时间。
由索引表IT1、数据表T1获取按特定执行计划执行的查询单独运行时的响应时间,由索引表IT2、数据表T2获取该查询所受其他查询的QueryRating。
2)给定MPL=w,当某查询qw到达数据库时,该查询与目前正在执行的(w-1)个查询构成一个查询组合。
由索引IT1表、数据表T1得到该查询的所有执行计划qw_k及其对应单独运行时的响应时间tqw_j,计算出Facqw_k值。
3)比较所有执行计划对应的TRatingqw_k,较小的TRatingqw_k值所对应的执行计划即为该查询在当前查询组合下较优的查询执行计划。
3 实验结果与分析
3.1 实验环境与设计
本实验选用的测试基准为TPC-H[17],查询模板为2,3,4,8,10,12,14,22。这些模板涵盖了分组、排序、聚集、连接、子查询等多表查询操作,其默认执行计划包含了各种基本表的扫描方式、表间连接方式及连接顺序。本实验分别给每个查询指定三个不同的执行计划,把按不同执行计划执行的同一查询看作不同查询。实验环境配置如表4。

表4 实验环境配置Tab.4 Experimental environment configuration
为查询选择当前查询组合下较优的执行计划,必须首先获取查询的多个执行计划。本文首先获取查询的多个执行计划,紧接着通过实验验证同一查询在不同查询组合下所选择的较优执行计划不同这一现象的大量存在。最后,给定MPL,依据先到先服务原则,根据实际用户提交查询的先后,对比当前查询优化器,通过实验验证本文所提出的为查询选择当前查询组合下较优执行计划方法的准确性。
3.2 执行计划生成及其响应时间
由于执行计划的生成会综合考虑基本表的访问顺序、表间的连接方式和连接顺序,因此本文在生成查询执行计划时,对于单表查询着重考虑基本表的访问顺序,对于多表查询,着重考虑表间连接方式和连接顺序,以此生成代表性执行计划。
使用explain 命令,PostgreSQL 查询优化器直接生成查询默认的执行计划。依据上述原则,通过关闭或打开执行计划开关,使得优化器允许或禁止使用一些扫描或连接方法,进而生成一定数量的执行计划,且其执行的查询响应时间少于或多于默认执行计划响应时间,且相差不宜过大。最后通过pg_hint_plan 插件绑定查询计划,使查询按指定的执行计划去执行。下面通过图1、图2说明。

图1 默认执行计划Fig.1 Default execution plan
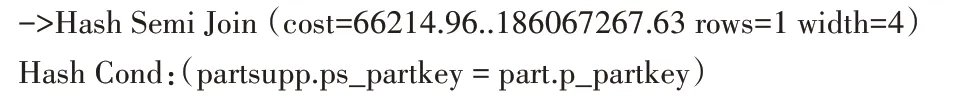
图2 关闭MergeJoin后的执行计划Fig.2 Excution plan after closing MergeJoin
实验中,服务器只开启PostgreSQL 数据库进程,分别单独运行每个查询、并行执行每两个查询组成的查询组合,利用PostgreSQL 的pg_stat_statement 模块获取查询的响应时间,通过多次运行求平均值的方法减少其他因素干扰,准确获取响应时间,从而求得响应时间的比值。
3.3 查询组合不同时的较优执行计划验证
本文分别对并行度MPL=2,4,6,8 时的同一查询加入不同查询组合所选择的较优执行计划进行实验。实验结果表明,同一查询在不同查询组合下所选择的较优查询计划不同,而且这种现象普遍存在,平均约占71%。由于篇幅受限,图3仅对部分样例实验结果进行展示,并加以说明。
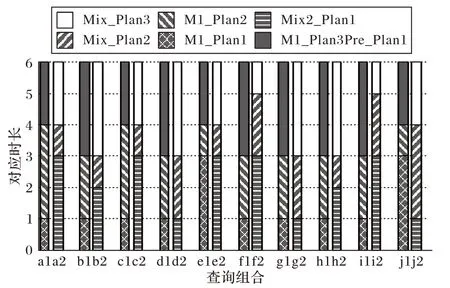
图3 关闭nestloop后MPL=4时,同一查询加入不同的查询组合时的较优执行计划抽样Fig.3 Sampling of better execution plan of one query adding to different query combinations with nestloop closed and MPL=4
图3 中:每组由两个柱状图构成,它们分别表示同一查询加入不同的查询组合中构成新的查询组合,每个柱状图分成三段,每一段表示按不同的执行计划执行的此查询加入查询组合,自底向上分别表示执行计划1、2、3,执行计划1 为PostgreSQL 查询优化器给出的执行计划,每段长度分别对应按特定执行计划执行的此查询加入查询组合后的响应时间的长短。
由图3 可知,多数情况下,每组的两个柱状图的三段长度均不相同,这说明当同一查询加入不同的查询组合时,所选择的较优执行计划并不相同。比如,当查询加入a1、a2 查询组合时,对应与a1 构成新的查询组合,该查询的较优执行计划为PostgreSQL 查询优化器给出的执行计划即执行计划1;但对应与a2 构成的新的查询组合,该查询的较优执行计划为执行计划2,不同于执行计划1。
本文对此种现象作如下解释:对于单一运行的查询,由于查询优化器搜索算法的限制,目前其仅能做到避免选择最差执行计划,当查询比较复杂时,为查询选择较优执行计划会存在较大偏差;对于并行运行的查询,优化器并没有特别地考虑查询交互这一主要因素,因为查询在不同查询组合下选择较优执行计划的偏差更大,因此,此种现象的大量存在十分正常。
3.4 TRating和查询优化器对比
模拟用户提交查询的实际场景,依据先到先服务原则,分别在MPL=2,4,6,8 时计算TRating 方法和查询优化器为查询选择较优执行计划的准确率,结果如表5所示。
由表5 可知,在不同并行度下,与目前查询优化器相比,本文所提方法选择较优执行计划准确率平均提高了25 个百分点。本文方法之所以准确率提高,是因为它在为查询选择当前查询组合下的较优执行计划时,特别地考虑了多查询并行时查询交互这一关键因素,并合理地度量了特定查询在查询组合中所受的查询交互影响的大小。尽管这样,随着并行度的增加、查询间交互的复杂化,预测准确率会稍有下降,属正常现象。
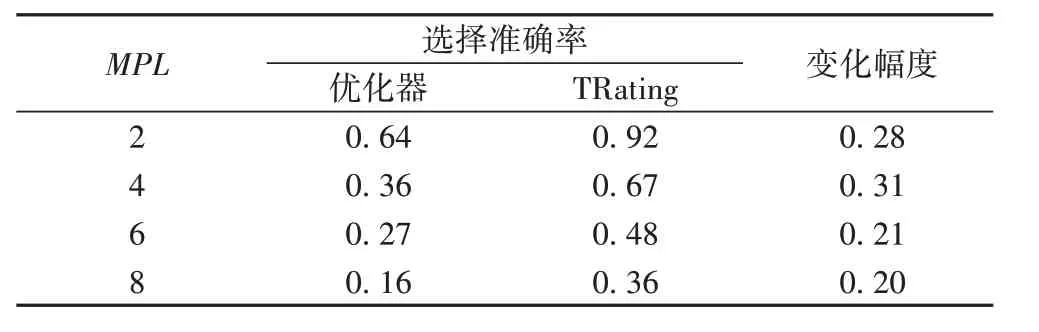
表5 TRating和查询优化器准确率对比Tab.5 Accuracy comparison between TRating and query optimizer
更可观的是,当前查询优化器是基于成本估算为查询选择较优执行计划,它需要计算每个执行计划所涉及各种操作的成本,计算量大。相对于查询优化器,本文TRating 方法在为查询选择较优执行计划时,由于模型选择的合理性,所涉及的计算量较小。因此,实验发现,在相同的计算环境下,本文方法TRating耗时远小于当前查询优化器。除此之外,不难发现,在不同MPL 值下,通过本文方法TRating 选择较优执行计划的准确率均高于当前查询优化器,这是因为本文方法特别地考虑了并行查询下查询交互这一关键因素。因此,随着MPL 即查询并行数的增加和查询交互的复杂化,虽然本文方法TRating准确率会有所下降,但仍优于当前查询优化器。
实验发现,在少数情况下,当本文方法不能为查询选择较优执行计划时,其所选择执行计划仍然为次优执行计划(即除去较优执行计划,使查询响应时间较少的执行计划),同样避免了最坏执行计划,也具有相当的实际意义。表6 是MPL=2,4,6,8 时,本文TRating 方法为查询选择次优执行计划的准确率。由表6 可知,在不同并行度下,本文TRating 方法为查询选择次优执行计划(包括较优执行计划)平均预测准确率高达69%,由此可知本文所提方法具有相当高的可靠性。

表6 TRating选择次优执行计划准确率Tab.6 TRating accuracy for suboptimal execution plan selection
4 结语
查询是数据库的主要负载,查询效率直接决定数据库系统的性能。多查询并行时,由于现有查询优化器只能依据参数配置静态地为查询选择一个不坏的执行计划,并没有特别地考虑查询交互这一关键因素,导致其在为查询选择当前查询组合下的较优执行计划时存在较大偏差。基于此,本文合理地度量了特定查询在多查询并行时受查询交互影响程度的大小,在此基础上,创新性地提出了动态地为查询选择当前查询组合下较优执行计划的方法TRating,并通过实验验证了其合理性。当用户提交的查询到达时,依据先到先服务原则,为先到查询选择当前查询组合下的较优执行计划提供了依据,具有一定的实际意义。随着查询并行度的增加、查询交互的复杂化,如何更准确地建立方法,或通过训练深度学习模型,保持其预测准确率不变是后续研究的重点。
