云/边缘协同的轴承故障诊断方法
2020-04-08张文龙胡天亮王艳洁魏永利
张文龙,胡天亮,4+,王艳洁,魏永利
(1.山东大学 机械工程学院,山东 济南 250061;2.高效洁净机械制造教育部重点实验室,山东 济南 250061;3.机械工程国家级实验教学示范中心,山东 济南 250061;4.山东大学 苏州研究院,江苏 苏州 215123;5.衢州职业技术学院 信息工程学院, 浙江 衢州 324002)
0 引言
近年来,伴随着产品质量、生产效率和产品复杂程度的不断提高,对机电装备的可靠性和稳定性提出了更高的要求。与此同时,由于机电装备构成环节和影响因素的增加,对故障和功能失效的预防难度也越来越大。轴承是机电装备中必不可少的部件,它的性能往往会从完好逐渐经历一系列不同的退化状态直至完全失效[1]。然而,当这些机电装备在高温、高污染以及过载等不利的条件下运行时,轴承等易损件在运行过程中发生故障的概率非常大。若不能及时预测或进行故障处理,往往会引发更严重的设备损伤,导致高额的维护成本和严重的经济损失,甚至出现安全问题。
传统以傅里叶变换为基础的故障诊断方法可以在边缘端采集数据进行实时分析,但是由于轴承的振动信号具有非线性与非平稳的特点,难以取得较好的分析效果[2]。主成分分析是目前实际工程故障诊断与预测中最为常见的特征提取方法[3-4]。但是采用人工提取特征的方式不但需要大量具有专业知识的人员参与,而且往往不具有代表性,在不同的应用之间存在着偏差。
针对这个问题,一些国内外的学者提出使用卷积神经网络(Convolutional Neural Networks,CNN)代替人工来进行特征提取[5-6],这样可以在训练阶段将特征抽取和分类融合并同时优化为一个单一的学习块,当训练样本数据量足够大时,能达到很高的诊断准确率。CNN模型需要利用大量带有标签的训练数据进行充分训练之后才能完成准确的故障识别[7],而对于带标签样本的收集以及模型的准确训练皆需大量的计算时间和计算资源。因此,现阶段类似的深度学习任务大都是在拥有丰富计算、存储资源的云端进行。然而,若单纯通过云端进行训练,需考虑对不同个性化诊断案例的适应能力,需对不同的应用场景分别进行训练,得到相适应的模型参数。该方法将导致训练参数大幅增加,训练任务繁重,与故障诊断的响应时限要求存在着矛盾。
随着物联网技术的飞速发展,数据越来越多地产生在网络边缘,将部分数据在网络边缘进行处理会更有效率。现如今边缘计算[8]、雾计算[9]等概念逐渐成为研究的热点。然而,若单纯通过边缘端由个性化的应用数据进行训练,则训练过程受限于边缘端的计算能力和存储能力,导致训练时间增长。除此之外,能够满足模型充分训练的大量数据的收集工作也较难开展。
借鉴在深度学习领域将具备高性能计算、存储的云端资源和个性化适应能力强、时限要求控制好的边缘端设备结合的思想[10],本文提出一种云/边缘端协同的轴承故障实时诊断方法,旨在充分发挥云端与边缘端的优势,通过对计算资源和计算实时性要求的协调,实现轴承故障的实时诊断。
1 整体框架设计
整体方案采用云/边缘端协同的思想进行构建。
云端的优势主要体现在以下两点:①丰富的计算资源,可快速进行大量复杂运算;②充足的存储资源,可以存储用于训练的海量样本。但同时由于云端时间敏感性差,任务定制能力差,往往不能满足实时性要求。而边缘端由于其与应用对象紧密耦合,因此具有两个优点:①实时响应性好;②服务对象单一,可进行个性化的服务定制。但其计算资源往往成为限制大规模数据驱动计算的瓶颈。为解决轴承故障实时诊断问题,本文基于上述对于云/边缘端优缺点分析,充分发挥云/边缘端的各自优势,设计整体框架如图1所示。
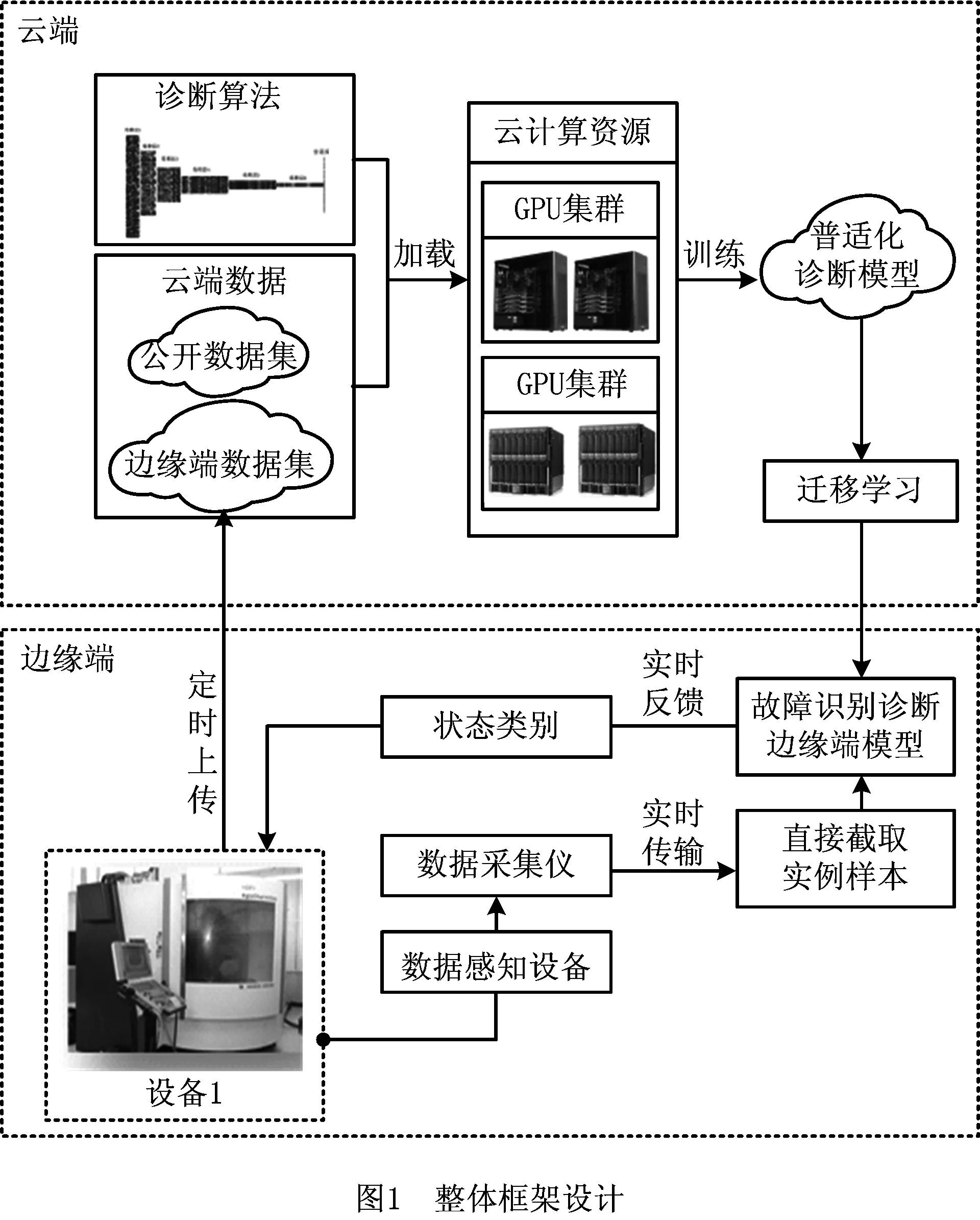
图1中,云端主要进行训练样本数据的存储和普适化模型的训练。其中,训练样本数据由两部分构成:一部分为轴承故障诊断公开数据集,另一部分为边缘端采集的轴承个性化诊断样本数据集。随后,基于云端丰富的训练样本资源和计算资源,通过对轴承的故障诊断普适模型进行持续训练更新,以得到普适化的训练结果,该训练结果可作为中间结果服务于不同的诊断场景。
边缘端通过数据感知装置采集个性化工况下轴承的实时状态数据,将其传递给云端存储。同时在边缘端形成个性化工况的训练样本,对云端迁移至边缘端的普适化诊断模型进行个性化修正,从而提升对具体诊断任务的适用性,由此形成个性化模型以进行轴承故障的实时诊断。
从图1可以看出,轴承故障诊断任务中云端和边缘端的数据交互主要包含两种方式:①边缘端会定时将存储在本地的个性化样本上传到云端存储,丰富云端的训练集和验证集;②随着云端存储的数据集的更新,定时通过训练完成普适诊断模型参数的优化,并将优化后的模型参数迁移到边缘端来进行模型修正。
2 故障诊断算法的设计与实施
2.1 轴承诊断算法的设计准则
由于轴承的振动信号较易采集且能很好地反映轴承状态,本文提出的故障诊断算法以采集的轴承振动信号作为故障诊断模型的输入,以轴承故障类型作为故障诊断模型的输出。在云端基于样本数据进行普适化诊断模型的训练后,通过迁移学习的方式在边缘端形成面向个性化工况的轴承故障诊断模型,基于实时采集的轴承振动数据对轴承故障进行实时的诊断。其中迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程[11]。
上述任务场景中的诊断算法需要对振动信号进行全面的特征提取,且云端的诊断模型要服务于个性化的边缘端故障诊断任务,同时边缘端需具备接受云端训练模型迁移的能力。因此,本文提出的神经网络识别算法的构建需要满足以下准则:
(1)既需要有足够大的卷积核来获取周期性变换的特性,又需要小的卷积核来获取局部特征;
(2)神经网络的深度要相对较深,以更容易获取优质的特征表示;
(3)神经网络构建的过程中应充分考虑过拟合的问题;
(4)神经网络整体参数不能太多,方便在资源不足的边缘端进行使用;
(5)边缘端与云端模型框架应相同,以满足云端训练结果向边缘端迁移的要求。
2.2 云端算法的构建与训练
近年来在轴承故障诊断领域也不乏一些优秀的深度学习算法涌现出来[12-14],其中第一层宽卷积核深度卷积神经网络(Deep CNN with Wide First-layer Kernel, WDCNN)算法与上述的设计准则较为符合。其网络结构中卷积层的结构特点是第一层为64×1的大卷积核,之后卷积层全部为3×1的小卷积核[15]。该算法中卷积核的设计和上述设计准则中的卷积核的尺寸要求十分相符,即在第一层使用了中等大小的卷积核,其不仅可以使网络拥有足够大的感受野并且保证不忽略过多的局部特征,除此之外该网络结构训练参数较少。但该算法进行故障诊断的准确率仍有待提高,并且对于过拟合的考虑有所欠缺。
基于此在WDCNN算法基础上进行以下两点改进:
(1)使用丢弃法抑制神经网络的过拟合现象,提高模型准确性。
(2)提升其神经网络的深度,从5层卷积层加深到6层卷积层,在保证训练参数总数增加较少的前提下,避免过拟合现象,提升故障诊断的准确性。
改进后的算法结构如图2所示,各层参数如表1所示。云端搭建好的诊断算法的训练与更新过程如图3所示。
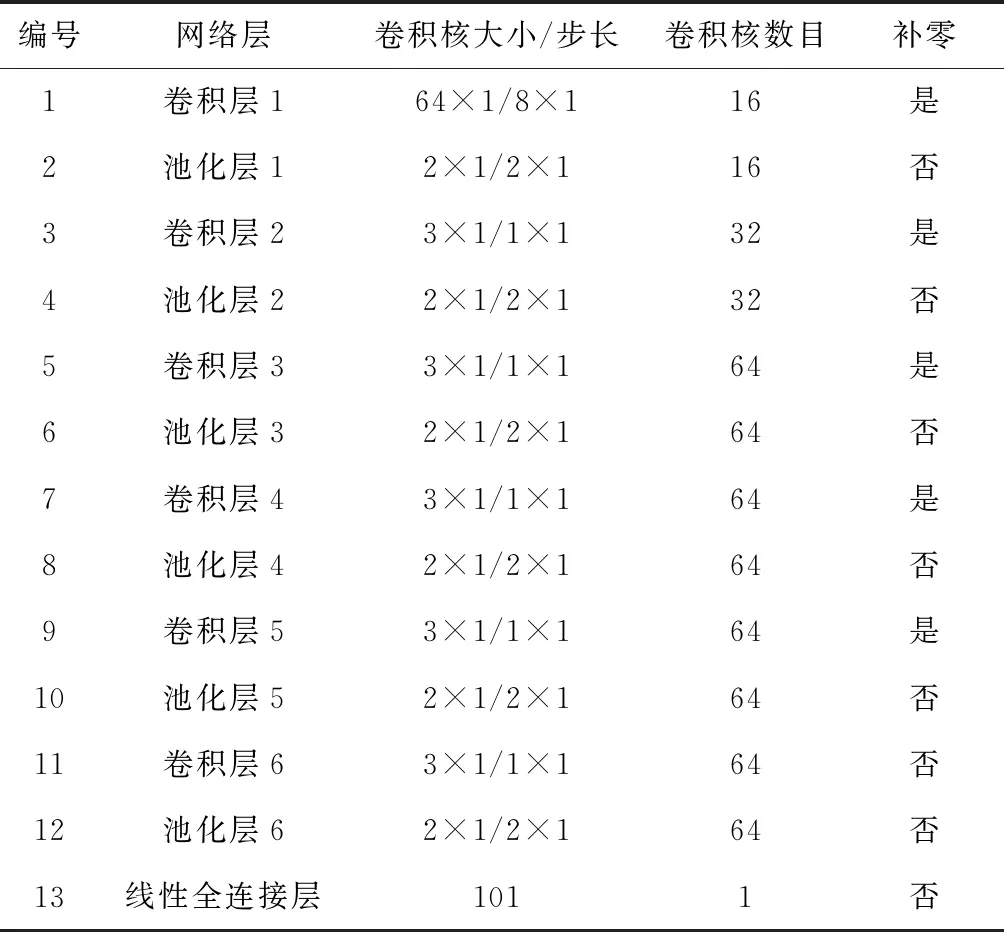
表1 改进后的CNN诊断模型的参数

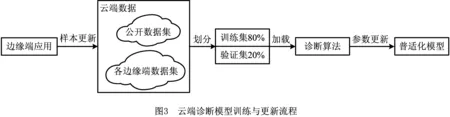
图3中,在任务初期主要是使用公开的轴承数据集来进行普适化模型训练,随着任务的进行会有边缘端应用所生成的个性化样本加入到数据库中进行持续更新训练。在训练时将训练样本按比例划分为训练集与验证集,每进行一次训练均反向传播更新模型参数,以运用云端丰富的计算资源,在诊断服务全过程中,针对不同任务场景提供持续快速的普适化模型参数更新服务。
2.3 边缘端算法的设计与实施
边缘端的任务主要是对轴承进行故障的实时诊断,其算法沿袭云端算法的基本框架,这样就可以将云端的普适化模型参数经过迁移学习迁移到边缘端。但与此同时需要根据不同的边缘端的特性进行调整。主要调整策略如下:
(1)根据边缘端不同的振动信号采样频率调整输入的数据长度;
(2)根据边缘端的计算资源和本地样本,选择匹配的神经网络配置。
边缘端算法的更新与应用如图4所示。

图4中,从云端经过参数迁移得到边缘端初始化的诊断模型。在边缘控制器上使用本地样本对该诊断模型进行个性化训练,最终生成可应用于边缘端的个性化诊断模型。此时将实时的振动信号采集加载在个性化诊断模型上就可以实时生成诊断结果,并可以根据诊断结果做出相应的响应。
3 实验与结论
本章根据上一章的内容分别设计实验来探究以下的内容:
(1)云端构建的诊断算法相较WDCNN改进的效果是否明显;
(2)在轴承故障诊断任务中通过迁移学习是否可以提高故障诊断的准确率并有效节约训练时间和资源。
3.1 实验平台
本文设计的实验平台由云端和边缘端两部分组成。在云端的硬件系统主要由4块GTX1080 GPU和CPU以及扩展的1 T硬盘组成。软件方面操作系统选用的是Ubuntu16,深度学习框架选用的是Pytorch,使用Python来完成整个云端的普适化模型训练的程序。边缘控制器选用的是NVIDIA JETSON TX2,在其上中搭载Ubuntu16系统,深度学习框架选用的是Pytorch,使用Python来搭建对实时振动信号进行实时故障诊断与识别的程序。
3.2 云端诊断算法的实现与性能探究
本次实验中所使用的公开数据集为美国凯斯西储大学的轴承数据集[12],选取其中的101种轴承状态的样本,标签与其故障状态的对应情况如表2所示。表中轴承数据分为健康和故障两大类,其中故障类别中又分为风扇端和驱动端数据。载荷代表的是实验中的电机载荷,单位为马力。轴承故障分为3个等级:故障等级一对应的是直径为0.177 8 mm的损伤;故障等级二对应的是直径为0.355 6 mm的损伤;故障等级三对应的是直径为0.533 4 mm的损伤。由于外圈损伤的位置是相对固定的,使用@3、@6以及@12分别代表损伤位置在3点钟、6点钟、12点钟位置。

表2 凯斯西储大学轴承故障数据集的故障类别与标签对照表

续表2
首先使用上述数据集对原始的WDCNN算法进行训练,经过100次的训练之后其准确率稳定在83.41%左右。为了增强其抽象特征的提取能力,提升模型的准确性,在这里增加了一层卷积层,经过100次的训练之后其准确率稳定在88.50%左右,由此得出,在本次任务中加深神经网络的层数可以有效提高模型预测的准确性。基于此在诊断算法的不同位置添加丢弃层。为了保证算法预测准确率的稳定性,每个实验均重复进行10次,最后结果取10次实验结果的平均值。实验结果如图5所示。
在图5中,通过对比发现在模型的最后3层添加丢弃层,且丢弃率为0.3的时候诊断效果最优,其模型预测准确率可以达到94.41%。
3.3 云/边缘端协同的迁移学习对比实验
本次实验中通过在云端搭载的GPU服务器上基于改进的WDCNN算法对凯斯西储大学轴承故障公开数据集进行充分训练,得到轴承故障诊断的普适化模型。
在边缘端则使用德国帕德博恩大学的轴承数据集[16]中与迁移学习源域数据集的故障种类相似的部分故障数据,来模拟边缘端采集到的个性化轴承数据。在本次实验中主要选取经电火花加工制造的轴承内圈损伤和轴承外圈损伤以及两类运行时间不同的健康轴承数据。每一大类数据中又根据工况的不同分为4小类,其故障类别与标签对照表如表3所示。用上述故障数据集来模拟边缘端采集到的轴承故障信息。

通过云端的普适化模型参数的迁移和边缘端的个性化调整以及训练,使得在边缘端的模型可以完成对于轴承故障的诊断与识别。由于边缘端使用的数据采集频率较高,这里截取4096×1数据作为输入到模型中来进行轴承故障的诊断,经过边缘端模型的识别可以快速反馈轴承的状态。

表3 实验选用的帕德伯恩大学轴承故障数据集的故障类别与标签对照表
3.3.1 迁移学习策略的选择与对应效果的探究
一般来说,进行迁移学习有两种策略:①Finetuning,它包括在基本数据集上使用预训练的网络并训练目标数据集中的所有层;②Freeze and train,它包括保持除最后一层(或几层)之外的所有层冻结(不更新权重)并训练最后一层。在本次迁移学习实验中分别应用两种方式去进行迁移学习,通过比较模型预测的准确性来选取适合的迁移学习方式。实验中目标域的训练集样本数量梯度设计如表4所示。在每次实验中,每类故障均选取未经训练的140组带标签的数据作为验证集进行故障诊断准确率的验证。
在本次实验中首先构建好上文提到的轴承故障诊断算法,然后在训练过程中依次使用表4中的训练集1~6对构建好的神经网络进行训练,其实验结果如表5与图6所示。
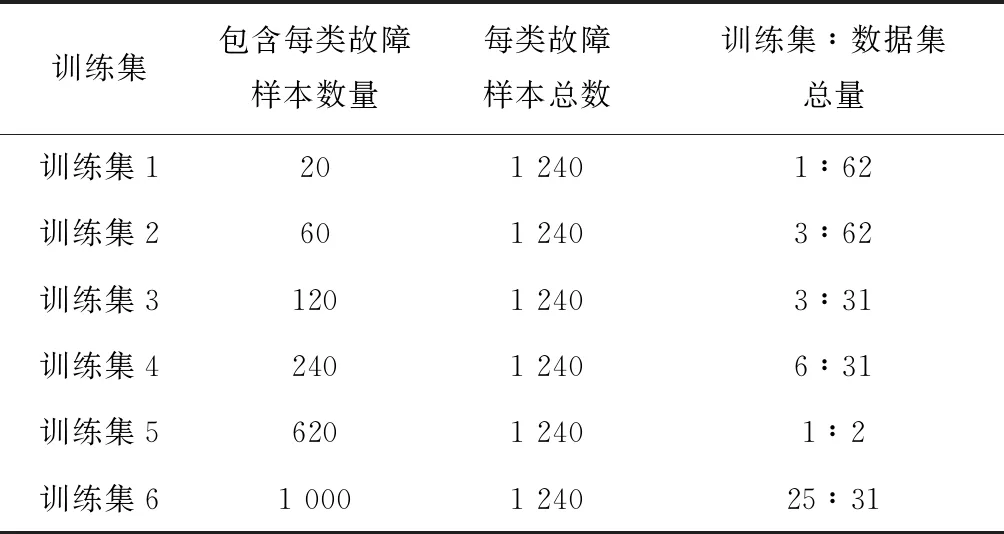
表4 实验中目标域各训练集样本量设置

表5 未进行迁移学习的实验结果

使用迁移学习方式时首先在云端使用源域样本对上一节得出的最优改进算法进行充分的训练,最终得到一个故障预测正确率达到接近95%的模型。将该模型中的所有参数传输到边缘控制器端。
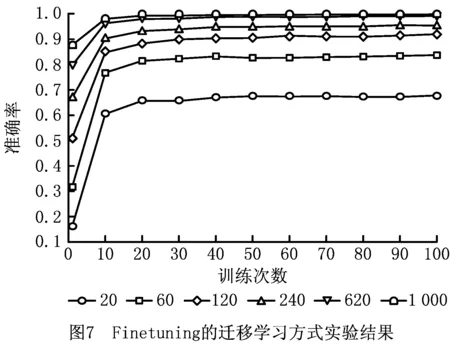
首先,采用Finetuning的方式来进行迁移学习,即在边缘端直接加载由云端传输过来的模型参数,使用表4设置的训练样本梯度分别对边缘端初始模型进行训练,并在训练中更新所有层的参数,在这里每次实验均重复进行10次,最后结果取10次实验结果的平均值,其结果如表6与图7所示。
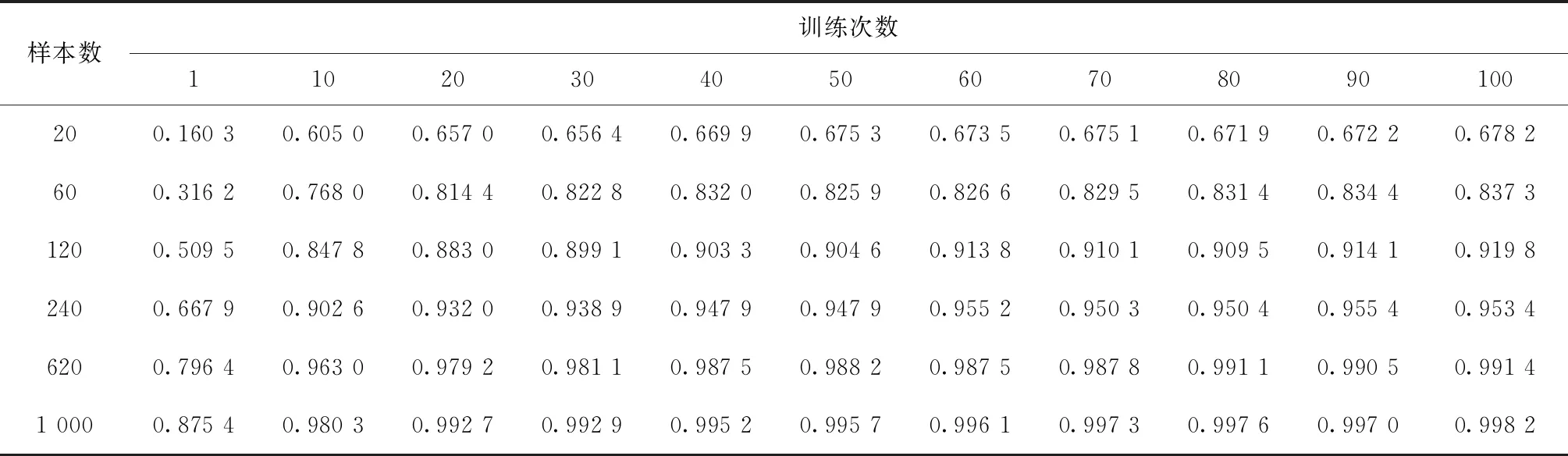
表6 Finetuning的迁移学习方式实验结果
然后,采用Freeze and train的迁移学习方式来进行训练,即在边缘端直接加载由云端传输过来的模型参数,使用表4设置的训练样本梯度来对模型进行训练,并在训练中仅更新全连接层的参数。在本次实验中分别使用一层全连接层和两层全连接层两种方式来实现最后的分类。在这里每次实验均重复进行10次,最后结果取10次实验结果的平均值,其实验结果如表7、图8以及表8、图9所示。分别截取上述4个实验中拥有少量训练样本时的实验结果,并将其汇总在一起进行对比分析,其汇总结果如表9所示。

表7 使用一层全连接层时实验结果
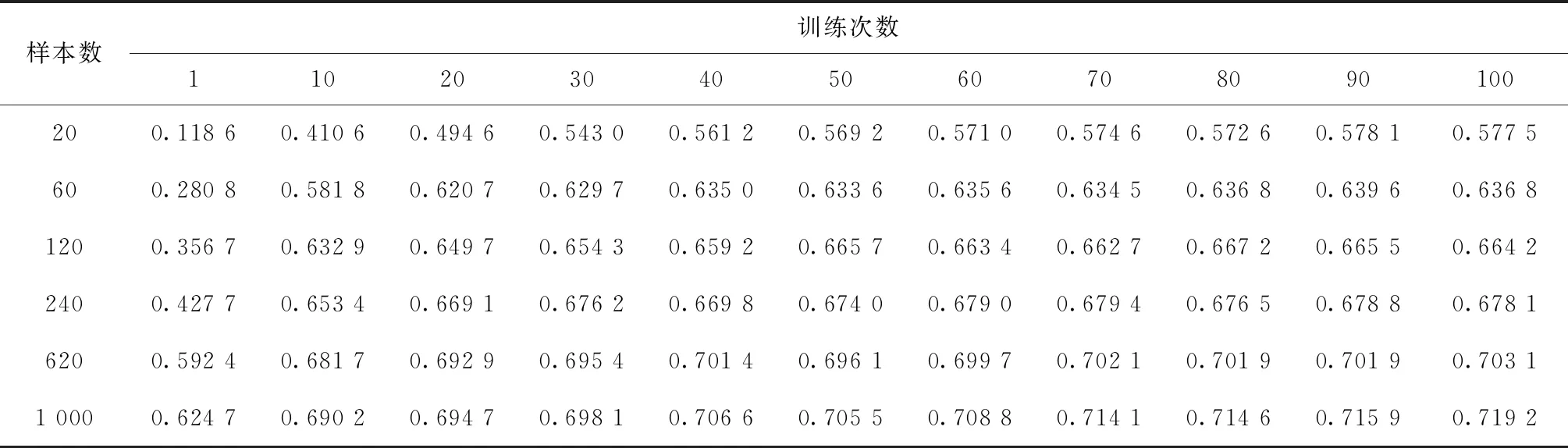
表8 使用两层全连接层时实验结果
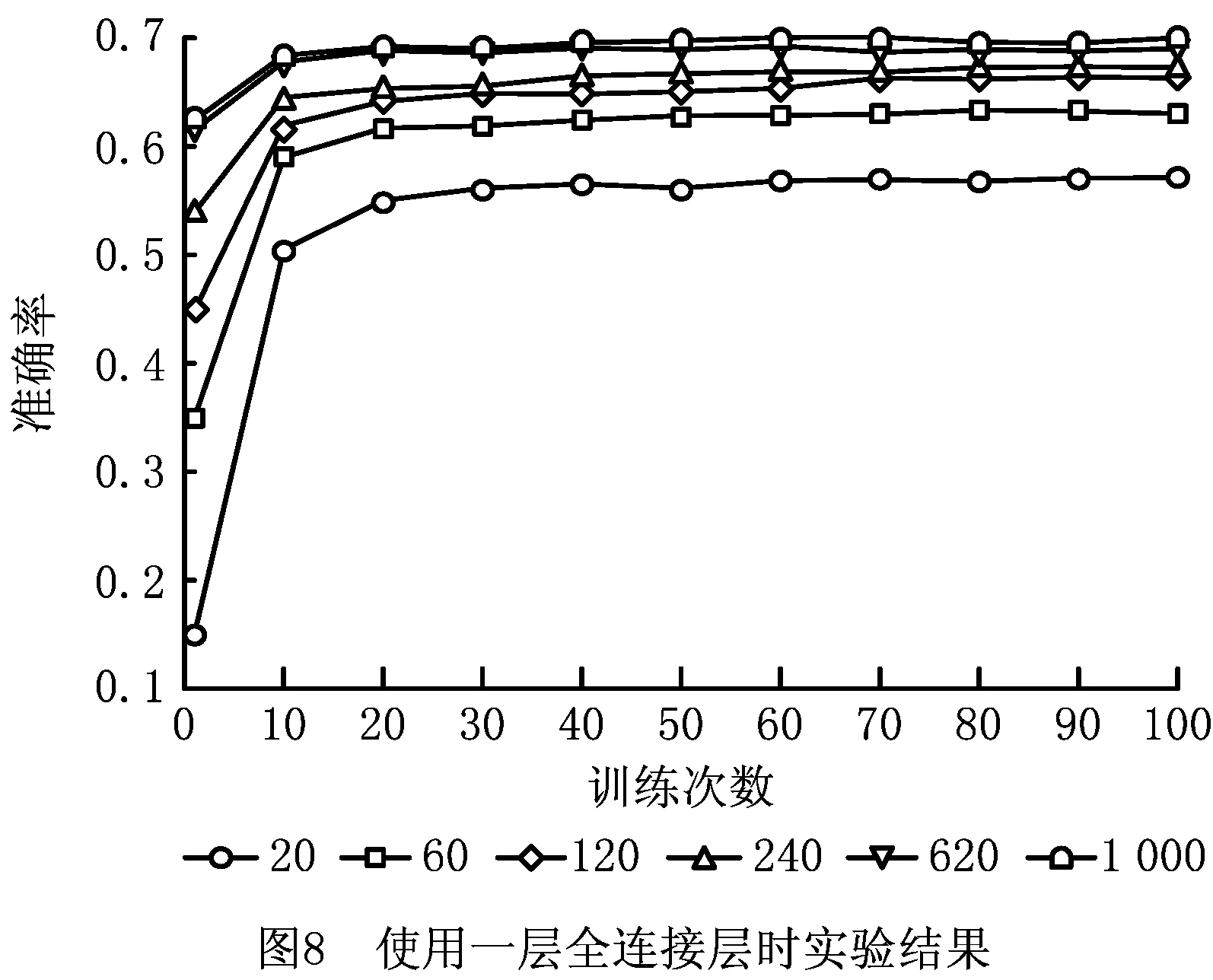


表9 少样本各迁移学习策略的效果对比表
由本次实验得出以下结论:
(1)在拥有少量训练样本时使用迁移学习的诊断准确率提高效果显著
在每类训练样本少于120条的时候,使用迁移学习可以大幅提高模型的预测准确率,如在每类个性化样本的数量仅有20条和60条时对诊断模型进行训练,使用迁移学习的方式分别可以得到67%和83%的预测准确率。而不进行迁移学习在相同情况下仅能达到50%和74%的预测准确率。
(2)在拥有少量训练样本时使用迁移学习的训练时间缩短效果显著
从实验中可以看出,在每类训练样本不超过240条的时候,使用迁移学习可以大幅缩短模型的训练次数。在本次实验中当边缘端每类样本数量为20、60、120、240条时,平均每次训练所需时间分别为1.265 s、2.075 s、3.285 s、5.724 s。当然由于训练时间在不同的硬件平台上会有不同的表现,但训练次数则在不同硬件平台上的表现基本相同,且训练次数和训练时间基本线性相关。因此,为了消除不同情况下的表现差异,统一使用训练次数来衡量训练时间的缩减程度。在每类样本的数量仅有20条时,使用迁移学习的情况下模型预测准确率达到最优解的90%仅需要不到10次训练,而未使用迁移学习的情况下则至少需要40次训练,迁移学习节约训练时间约75%以上。在每类样本的数量仅有60条时,使用迁移学习的情况下模型预测准确率达到最优解的90%仅需要不到10次训练,而未使用迁移学习的情况下则至少需要30次训练,迁移学习节约训练时间约66%以上。在样本数量为120条和240条时达到最优解的90%所需要的的训练时间亦大幅缩短。
(3)本次任务中Fineturn的迁移学习方式要比Freezing and train准确率更高
本次故障识别任务中在每类故障有20条及以上的带标签的训练数据时,Fineturn的方式总是能在预测准确率上高出Freezing and train 10%以上。
3.3.2 迁移学习样本对迁移学习的影响探究
在上述实验中迁移学习的源域选取的是凯斯西储大学的101类故障数据集。其中包含健康的轴承状态、轴承外圈损伤的状态、轴承内圈损伤的状态、保持架损伤状态以及滚动体损伤的状态样本。但本次任务要迁移到的目标域中仅有健康的轴承状态、轴承外圈损伤状态和轴承内圈的损伤状态样本这3大类,而没有轴承保持架和滚动体的损伤状态样本。在本实验中要探究迁移学习的源域样本类别对迁移学习的影响。分别以源域中去掉滚动体与保持架损伤样本(表10)、源域中去掉滚动体与保持架损伤样本并进行相似类合并(表11)以及完整的源域样本3类来进行完全的训练。为了保证模型预测准确率的可信性,每次实验均重复进行10次,最后结果取10次实验结果的平均值,其实验结果如图10所示。

表10 去掉保持架与滚动体损伤样本的源域样本对照表

表11 去掉保持架与滚动体损伤样本并进行合并的源域样本对照表

由本次实验得出结论:为了达到好的迁移学习效果,在选取迁移学习样本时要力求做到源域有尽量多的不同故障表现的样本,并且最好对样本做出精细完善的分类。因此,在本次任务中云端存储的不同工况的轴承数据集可以增强迁移学习的效果。
4 结束语
本文提出一种基于一维卷积神经网络的云/边缘协同的轴承故障诊断方法实现轴承故障的实时诊断。运用云端存储的大量样本数据对诊断模型进行持续训练,生成可以适用于同类别的轴承故障诊断任务的普适诊断模型。然后通过迁移学习的方式将训练好的普适化模型迁移到边缘端,在边缘端只需要运用少量本地样本进行微调即得到边缘端的个性化轴承故障诊断模型,用该模型可以进行轴承故障的实时诊断。与此同时边缘端的个性化样本会定期上传到云端,作为训练数据用于更新普适诊断模型。通过实验验证对比分析,使用该轴承故障诊断方法可以将诊断模型的训练在云端实现,而边缘端只需要进行少量的个性化调整训练,可节约大量的训练时间。与此同时在训练样本不足的制约下,可以显著提高故障诊断准确率。由于此方法在实时性、准确性、样本局限性方面体现出的良好效果,后续研究中将进一步探究此方法在齿轮箱、机床电主轴、导轨等关键零部件故障预测和诊断中的应用策略,为制造装备关键零部件故障诊断和预测性维护提供高可行性的实现方案。
