基于语义描述的相机拍摄重定向方法研究
2020-04-08张毛磊刘晓平
张毛磊, 李 琳,2, 刘晓平,2
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230601; 2.工业安全与应急技术安徽省重点实验室,安徽 合肥 230601)
近年来,随着海量视频资源的涌现,视频检索技术处在不断快速发展的阶段,其中快速、高效地检索出视频中包含的镜头语言是该领域的一个研究热点。视频影像资料中所包含的镜头语言对摄影爱好者具有很好的指导和借鉴意义,但尚无有效方法能以量化的方式准确分析出视频中的镜头语言,因此,分析已有视频资料中包含的镜头语言得到量化描述,从而指导非专业领域的用户拍摄出与原视频相同镜头语言的视频具有切实的意义。
本文提出了一种快速获取视频中镜头语言的方法,可以根据视频中相机的姿态信息得出其中包含的镜头语言,并将其重定向到目标场景中用于动画生成。其中相机姿态信息获取已有大量成熟方法,如文献[1-2]在原相机自标定方法上进行改进后提出的方法已经可以高效、精确地获得相机姿态信息。
国内外已有大量针对视频影像中镜头提取方法的研究。文献[3]利用“草地区域比例”对足球视频进行了语义分析,将比赛画面分为比赛、暂停2类;文献[4]借助隐马尔可夫模型(hidden Markov model,HMM)对足球视频的语义结构进行了分析,且在准确性和分割正确性方面都有良好的表现,但该方法在对视频进行语义分析时没有将重要的相机运动等信息考虑其中;文献[5]综合了“草地区域比例”“运动员球衣的尺寸”“特效标志的出现”等各类颜色、面积和暗示性信息,将足球视频的镜头分为播放、特写、回放、暂停4类;文献[6]在镜头颜色特征分析的基础上对足球视频的镜头进行语义分割,通过定义多个语义颜色,利用支持向量机(support vector machine,SVM)对镜头进行分类,将镜头属性分为正常比赛镜头和回放镜头,正常镜头分为特写镜头、中景镜头、中场区远景镜头、球门区远景镜头4类,但随着语义颜色增加到一定数量,分类精度有明显降低;文献[7]定义了足球的5种场景视图,即特写、中景、中场区、前场区以及球门区视图,并综合使用“草地区域比例”“运动员的尺寸”和典型轮廓线等颜色、面积、场地标示信息对场景分类;文献[8]引入本体领域知识,结合MPEG-7标准提出了一个视频语义内容分析框架,该框架将体育视频领域中的镜头分为正常比赛、近镜头、场外镜头、回放类型;文献[9]将视频看做是有内在联系的语义资源集合,提出了一个语义网络框架,提取视频中文本、面部、音频、颜色、形状、纹理特征对视频进行分割,但该框架的测试视频较少,其适用性有待验证。以上研究大多面向某一特定类型视频资源展开,在其他领域视频的适用性仍有待验证。文献[10]采用音频分类和时域梯度相结合的方法,提取视频中人物、城市场景、景观等语义信息,但在处理模糊图像序列时仍有较大误差;文献[11]提出了一种基于语义的场景分割算法对视频进行镜头分割,该方法首先将视频分割为镜头,并提取镜头中的关键帧,利用关键帧中的低层特征对其进行分类,得到关键帧语义并构造语义概念矢量,最后根据语义概念矢量对镜头关键帧进行聚类,对场景进行分割,但该方法存在语义概念提取错误的问题;文献[12]提出了一种基于SVM的多模态主动学习算法来提取视频中的语义特征,将主动学习引入语义提取当中,在人工干预尽量少的情况下,提取视频中多模态特征,包括颜色特征、纹理特征、镜头运动等,但该方法的检索效率较低。
针对上述方法存在的适用场景、计算效率等问题,本文提出了一种镜头语言提取方法,仅需要利用视频中相机的运动信息即可提取其包含的镜头语言,并能重定向到其他场景用于动画生成。
1 总体设计
本文基于语义描述的镜头语言提取方法可以将提取的镜头进行定性描述,生成镜头语言描述文件,用于指导非专业领域用户进行拍摄以及目标场景的动画生成。该方法的流程如图1所示。

图1 方法流程
图1中,数据输入为一段视频,步骤如下:① 对该视频进行相机标架与轨迹的提取;② 根据所得相机轨迹信息对其进行直线、曲线分段;③ 利用本文定义的11种基本运动方式,对镜头语言进行分类、识别,获得镜头语言所包含的运动方式序列,并生成对镜头语言定性描述的文件;④ 根据步骤③的结果,将原视频中的镜头语言重定向到目标场景中,生成场景动画。
2 相机运动的语义描述
相机镜头全局运动的类型一般由推、拉、摇、移、升、甩、悬等组成,其中基本的运动类型有推、拉、摇、移4种。根据视频中的相机轨迹可以将运动方式划分为直线运动、曲线运动、相机位置不变3种。其中,直线运动可以细分为直线拉l1、直线推l2、直线垂直平移l3、直线移l4、直线聚焦某一物体运动l5;曲线运动可以细分为曲线推q1、曲线拉q2、曲线移q3、曲线聚焦某一物体运动q4。此外,可以依据相机标架是否发生变化将相机位置不变分为相机静止s1、相机摇s2运动;相机镜头朝向与相机轨迹之间的关系可以清晰地描述相机运动方式,因此,仅需要考虑相机镜头朝向与相机运动轨迹之间的关系。
直线运动方式的5种基本类型如图2所示。其中,蓝色箭头表示相机镜头朝向;黑色箭头表示相机运动方向。图2a为直线拉l1;图2b为直线推l2;图2c为直线垂直平移l3;图2d为直线移l4;图2e为直线聚焦某一物体l5。
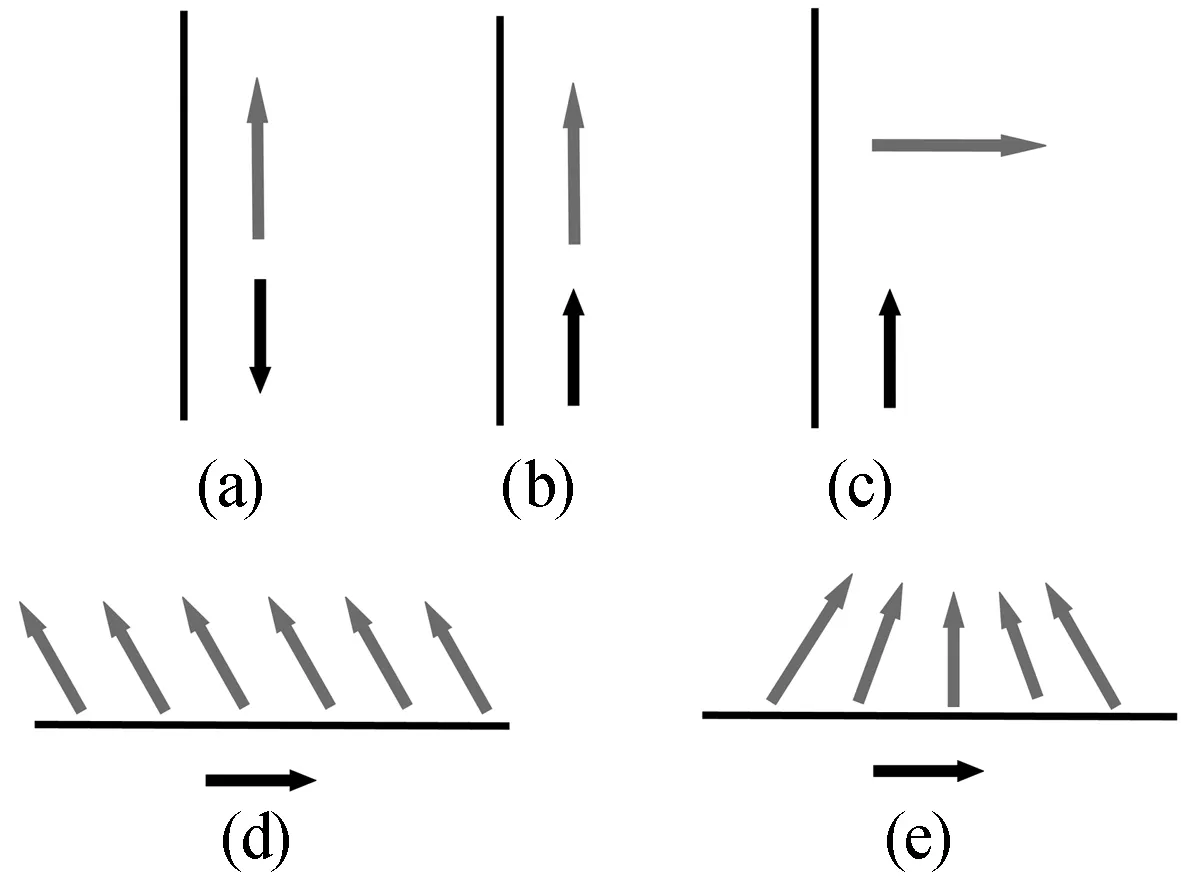
图2 直线运动方式基本类型
曲线运动方式包含的4种基本运动类型如图3所示。其中,图3a所示为曲线推q1;图3b所示为曲线拉式q2;图3c所示为曲线移q3;图3d所示为曲线聚焦某一物体q4。
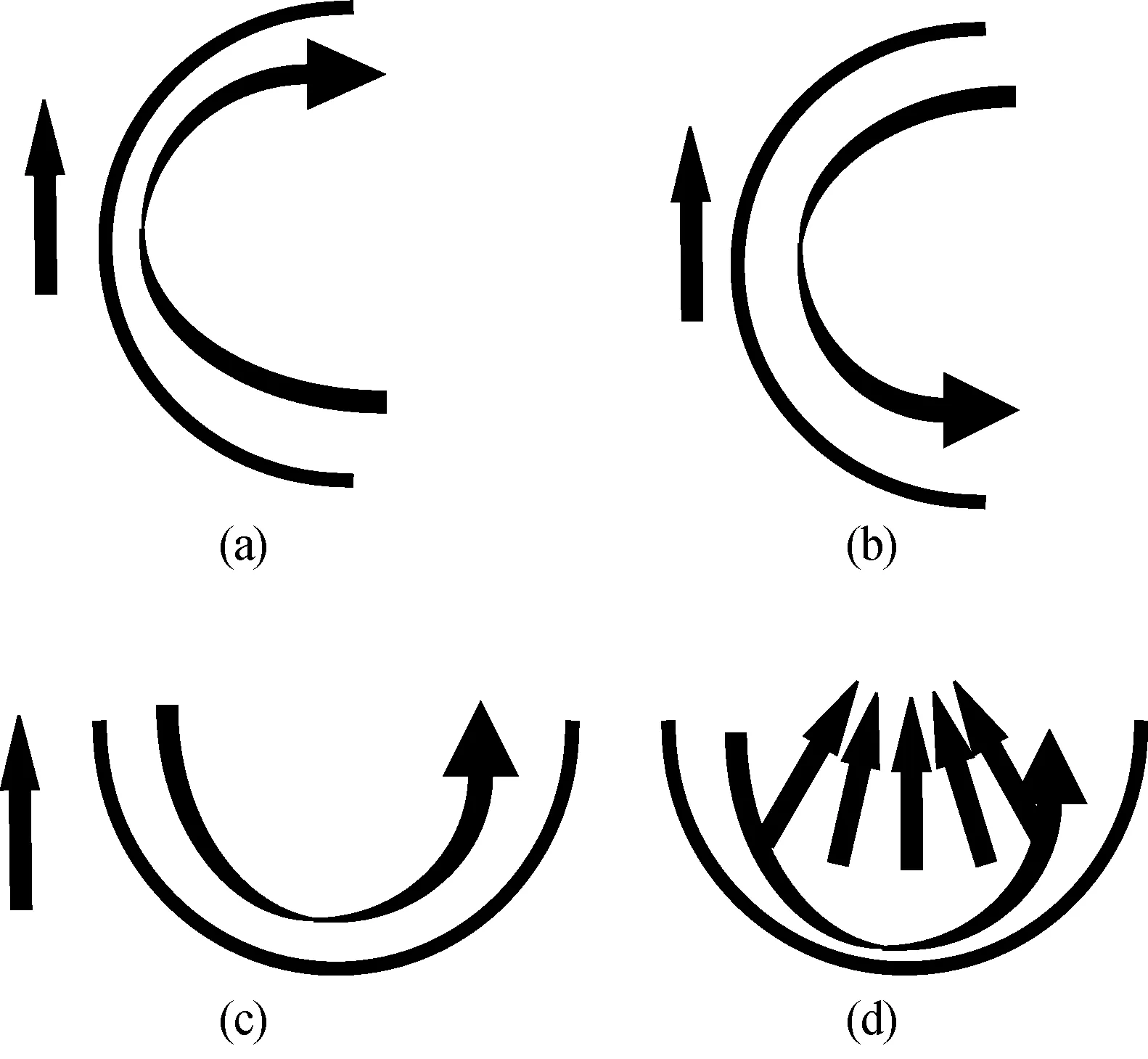
图3 曲线运动方式基本类型
对于相机位置无变化的运动方式,本文根据相机标架是否变化,将其分为相机静止s1、相机摇s22种基本类型。对于任意复杂的镜头语言,都可以由以上描述的11种类型相机运动方式组合表达。
3 视频中镜头语言的提取
利用上述11种相机运动方式对一段视频中所包含的镜头语言进行分析,获取镜头语言所包含基本运动方式序列的过程称为镜头语言的提取。具体提取方法框架如图4所示。
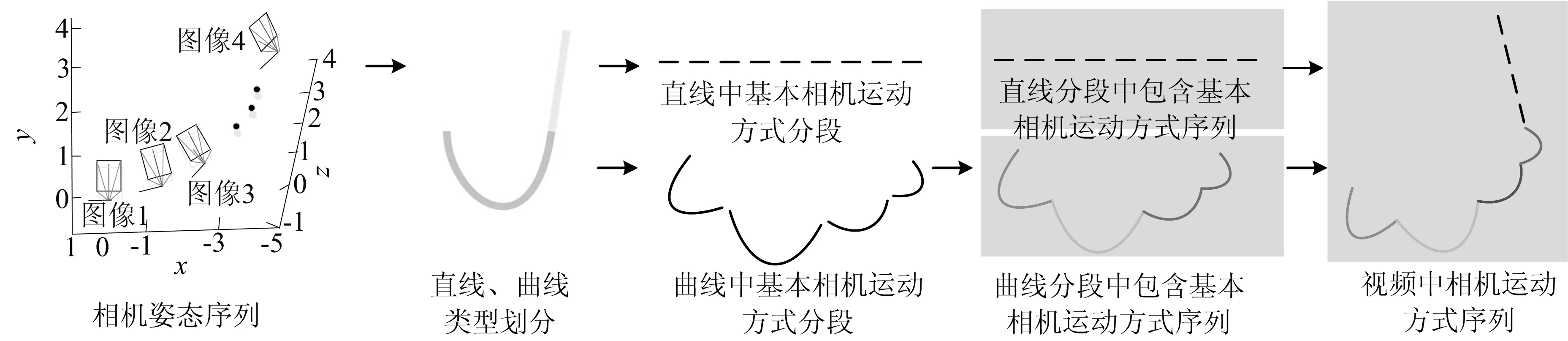
图4 镜头提取方法框架
视频中镜头语言提取的主要步骤分为相机标架和轨迹的获取、相机直线曲线轨迹分段、镜头语言的分类与识别。本文利用VisualSFM获取相机的标架与轨迹信息,该工具可以精确地获取相机标架与轨迹信息,为后续精确提取相机运动方式提供了保证。根据文献[13]中有序离散点的曲率近似法求解每个相机位置点的曲率,利用曲率对相机轨迹进行分段。下面将详细介绍镜头语言中相机运动方式的分类以及镜头语言的识别。
本文根据相机的姿态信息对相机的运动方式进行分类。姿态信息是指相机的标架R与轨迹信息T。其中,T为轨迹上每个点的曲率,轨迹切向方向单位矢量为t;表示标架R的3个单位矢量为f、u、l,f方向为相机镜头朝向,u方向为相机上方向,l方向为相机左方向。本文后续中提及标架与轨迹之间的夹角F变化是指f与轨迹之间的夹角变化。相机基本运动方式分类算法流程示意图如图5所示。

图5 相机运动方式分类算法流程示意图
(1) 在识别视频镜头语言过程中,本文先根据相机运动轨迹曲率的变化,对相机轨迹进行直线、曲线、位置无变化运动方式的划分。选取曲率均值kavg作为临界值k,根据相机位置是否发生变化、T是否小于阈值k将相机运动方式分为3类:① 如图5中1-1所示,根据相机位置是否发生变化,将相机运动方式分为直线曲线以及位置无变化2种类型;② 如图5中1-2所示,根据T是否小于阈值k将相机直线曲线运动类型细分为直线运动类型与曲线运动类型;③ 将相机运动方式分为直线、曲线、位置无变化3种基本运动类型。对于由k的选取而造成的划分区间误差,可以通过后续的结果调整k的选取,以保证区间划分精度。
(2) 上述对相机轨迹进行分段的结果,尚未具体到本文所总结的基本运动类型。如一段直线运动轨迹可以由5种基本直线运动类型的一种或几种有序组合组成;一段直线轨迹所包含的基本运动类型序列如图6所示,其有序组合为{l2,l1,l3,l5,l4}。
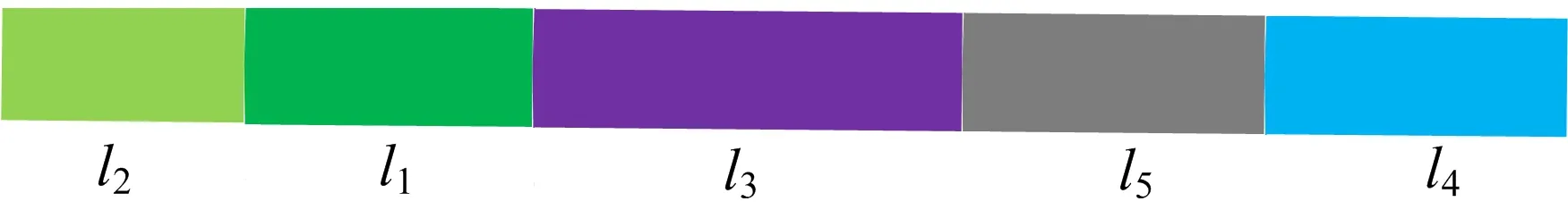
图6 直线运动方式有序组合
曲线运动轨迹也是如此。一段曲线运动轨迹中所包含的基本运动类型序列如图7所示,其有序组合为{q3,q1,q2,q4,q1}。
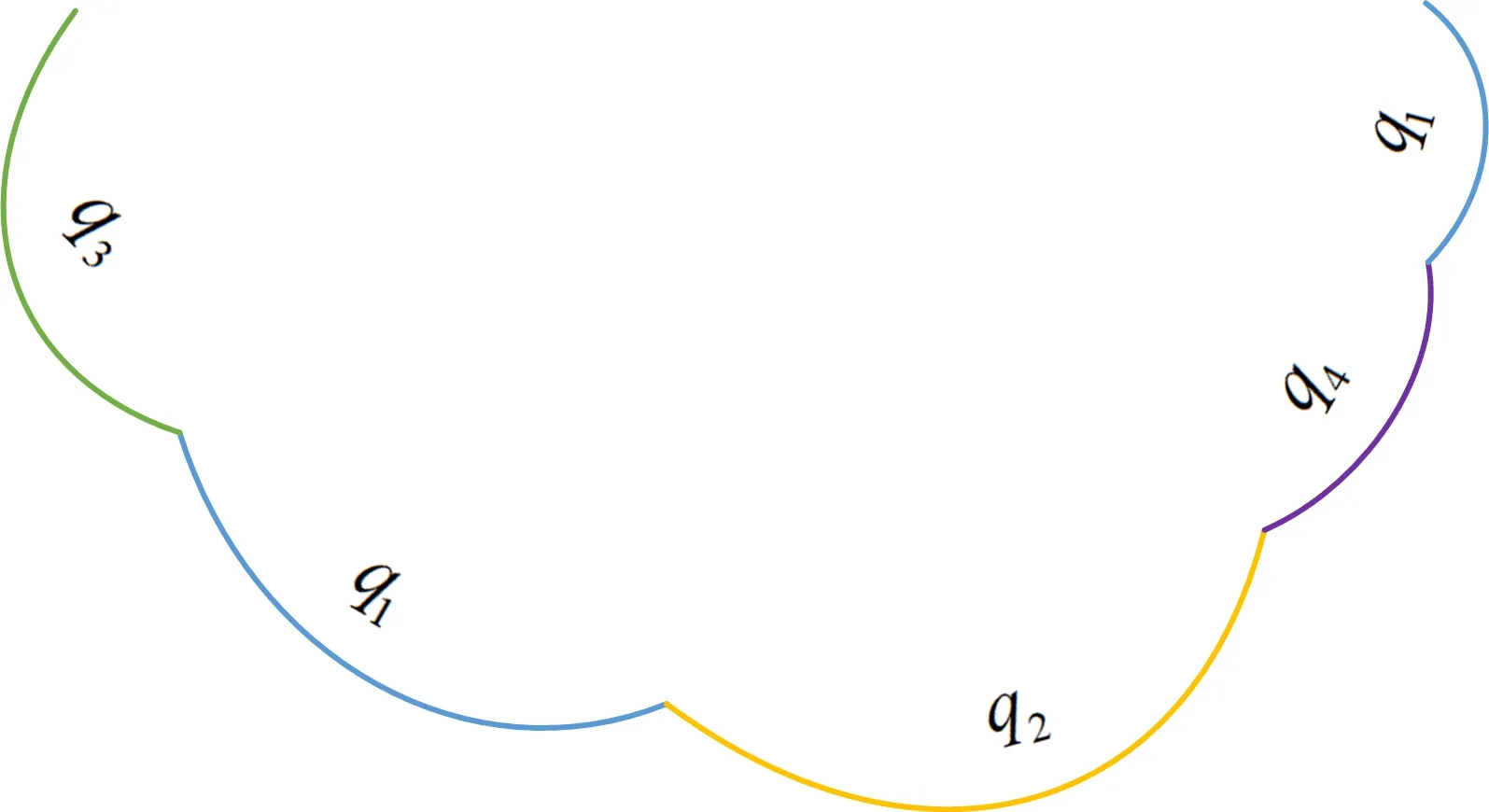
图7 曲线运动方式有序组合
为了确定直线运动与曲线运动中所包含的基本运动类型序列,需要根据相机的标架R与轨迹信息T的变化以及两者之间的关系对相机运动方式进行分段、识别。如图5中2-1直线类型,根据相机标架R是否变化,将直线类型分为直线聚焦于某一物体与其他4种基本直线运动类型;如图5中2-2,对于曲线类型,根据相机标架R是否变化,将曲线类型分为曲线聚焦某一物体与其他3种基本曲线运动类型。对于相机标架R变化较为明显的,可以确定其为l5或q4;对于相机标架R无明显变化的,可以初步判断其运动方式为直线运动类型l1、l2、l3、l4中的一种或曲线运动类型q1、q2、q3中的一种,为处理此类情况,可计算标架与轨迹之间夹角值F,由F值最终确定某一基本运动类型,即
Fj=P(fj,tj),j=1,2,3,…,n
(1)
其中,fj与tj之间的夹角值由函数P求得。F取值与某一运动类型的对应关系如图8所示。图8a所示为F取值与基本运动类型的对应关系,横坐标表示基本运动类型,纵坐标为夹角F取值;图8b所示为一段视频中F值的连续变化过程,根据图8a中F与基本运动类型的对应关系,可以得到该段视频所包含的基本运动类型序列为{q2,q1,l3;l5,l4;q4,q1;l2,l1}。
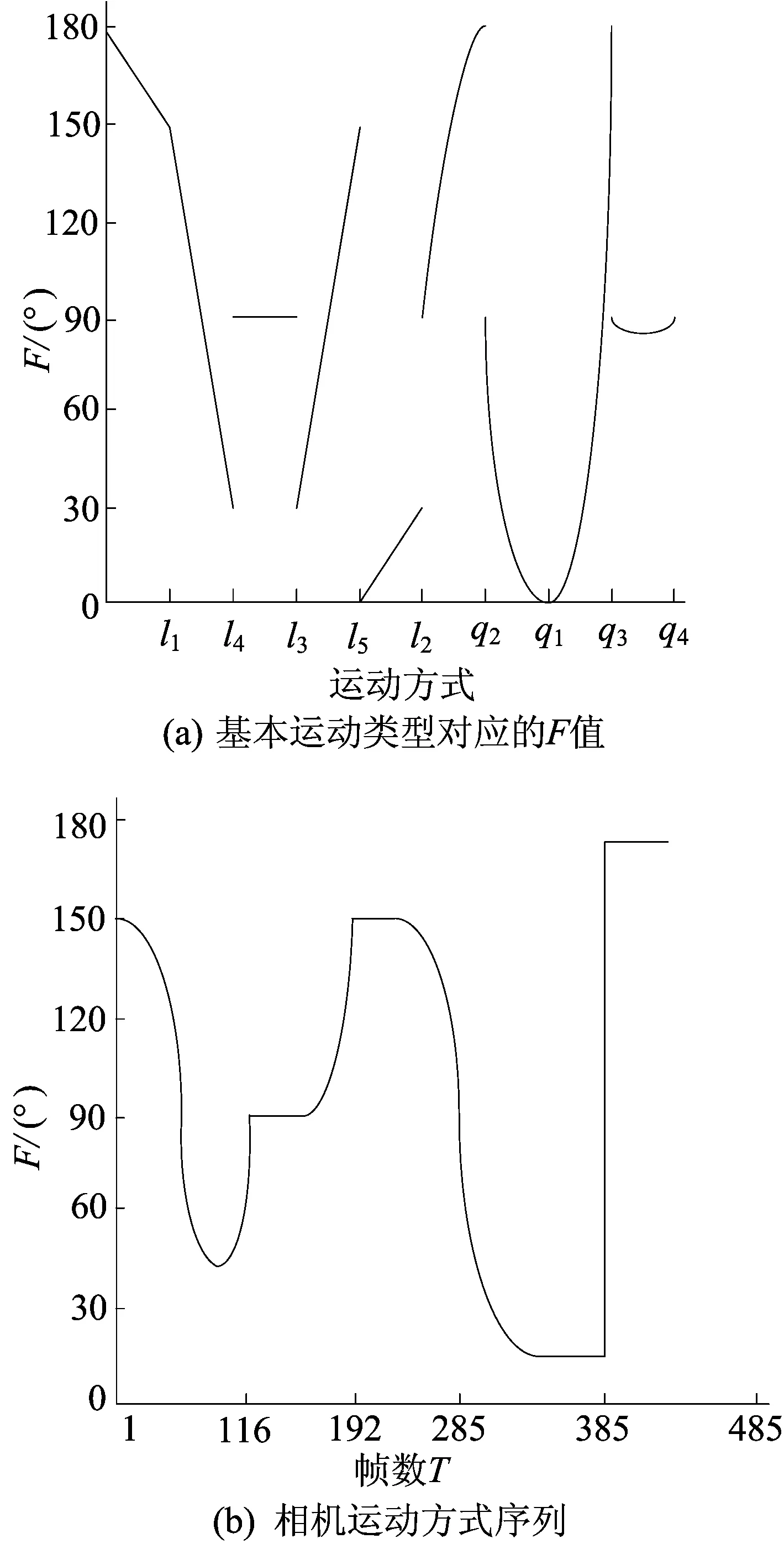
图8 相机旋转矩阵与平移向量夹角变化关系
对于相机位置没有发生变化时对应的相机静止s1、相机摇s22种类型,可以根据相机的标架是否变化进行判断。
4 镜头语言拍摄重定向
为了得到适用于不同类型场景的相机标架与轨迹信息,需要根据重定向目标场景中的拍摄目标和距离,使用参数化的方法重新生成每种镜头语言的相机标架与轨迹。考虑到重定向目标场景中的拍摄目标与距离各异,该方法具有一定的普适性,可以适用于多种类型场景,对于场景动画的生成有较大帮助。
4.1 镜头语言的参数化
每种镜头语言所包含的基本运动方式序列不同,对每种镜头语言进行参数化,使其成为关于运动方式序列的函数,即
(2)

4.2 相机拍摄的重定向
在不同类型的场景中,由于拍摄目标的不同以及相机距目标的距离各异,重定向生成的镜头语言中相机标架与轨迹也自然不同。利用已知拍摄目标的物理参数以及相机与拍摄目标之间的距离生成适用于该场景的相机标架与运动轨迹是重定向的关键。
对于每种镜头语言中所包含的相机运动方式序列,为了将其重定向到其他场景中,首先需初始化相机起始位置,求出相机距拍摄目标的距离d,利用d与拍摄目标场景区域高度h调整镜头语言中相机的标架与轨迹。
(3)
其中,maxX、minX和maxZ、minZ为求解基本运动方式相机轨迹中分量X、分量Z的最大值与最小值;i=1,2,3,…,11。
5 实验结果及分析
5.1 正确性实验
实验时,在网络上获取3种类型各异的真实场景中拍摄的视频和在Unity 3D中渲染的3种视频作为测试数据。

(4)
其中,Sum()为镜头语言中包含基本运动方式的数量;Fm函数用于求解2个序列中包含的相同运动方式匹配度;σtl∈[0,1],σtl值越小说明2种相机运动方式序列越接近。3种真实场景中拍摄视频的相似误差结果见表1所列。


表1 实拍视频的误差结果

表2 已知镜头视频的误差结果
5.2 重定向实验
对使用本文方法分析得出的针对不同拍摄视频的运动方式序列,通过重定向方法应用到某个虚拟场景后进行对比,原视频与重定向并应用到虚拟场景后得到的视频画面对比如图9所示。

图9 原视频镜头与虚拟场景视频中的镜头
图9中,每段镜头中的第1行为原视频中镜头所包含的图像序列;第2行为重定向到虚拟场景中生成的场景动画的图像序列。实验结果表明,本文方法可以将镜头语言中相机的标架与轨迹很好地重定向到虚拟场景中生成场景动画。
本文邀请25名测试者对重定向场景动画的镜头相似度、视频流畅性、画面展示度3个方面进行评测,结果表明,重定向生成的场景动画效果好,评价结果如图10所示。

评测问题图10 重定向评测结果
以上2种类型的实验结果表明,本文基于语义描述的相机拍摄重定向方法具有适用性广、提取镜头语言的正确性高以及重定向效果好的优点。
6 结 论
本文提出了一种基于语义描述的拍摄重定向方法,目的是将一段视频中镜头语言重定向到虚拟场景中,用于场景动画的生成以及指导非专业领域的用户拍摄相同镜头语言的视频。该方法主要特点是利用相机标架与轨迹之间夹角的变化关系定义了11种基本相机运动方式;通过分类、识别镜头语言所包含的相机运动方式确定镜头语言所包含的相机运动方式序列;根据重定向场景的拍摄目标和距离生成适用于重定向场景的相机标架与轨迹,产生场景动画。2种类型实验的结果表明,本文方法在正确性、适应性以及重定向方面都可以达到用户的要求。
然而,本文方法针对存在大量镜头切换的视频还无法进行镜头提取以及并没有将相机运动速度考虑到重定向中。未来,将针对以上问题进行更深入的研究。
