基于深度学习的电影推荐算法
2020-04-08阮文俊胡小龙李丽华
阮文俊,胡小龙,李丽华
(中南大学计算机学院,湖南 长沙 410075)
0 引言
随着互联网的发展,大数据时代已经到来,信息过载的现象越来越突出.如何从大量复杂的数据中挖掘出有价值的信息,并对其进行分析,从而提高人们的生活水平显得格外重要.从海量数据中挖掘用户需要的数据主要有两种方法:一是通过搜索引擎,这需要用户精准地描述自己需要什么;二是通过推荐系统,推荐系统的任务是根据用户的偏好或历史行为,呈现给用户可能想要的信息,从而帮助用户节省宝贵时间[1].
推荐系统的发展可以追溯到1979年,它从认知科学开始,逐渐在生活中起到越来越重要的地位.目前,越来越多的电子商务网站开始接入推荐系统,例如淘宝、亚马逊等,推荐系统帮助他们推荐感兴趣的商品给用户,节省用户的浏览时间.除此之外还有网易云音乐推荐系统、微博社交推荐系统、Netflix电影推荐系统等.推荐系统帮助用户节省时间,同时帮助企业带来收益,因此推荐系统受到广泛研究.文献[2]提出一种基于Logistic函数和用户聚类的协同过滤算法来解决协同过滤中评分稀疏性问题.文献[3]将协同过滤和深度学习结合,提出了两种集成模型来针对完全冷启动项目和不完全冷启动项目.文献[4]为了利用用户的多种行为数据,开发了一个神经网络模型来捕捉多类型的用户行为,通过学习多种用户行为的语义来进行推荐.
目前,主流的推荐算法主要分为协同过滤推荐算法、基于模型的推荐算法和混合推荐算法.其中协同过滤算法在进行推荐的时候主要考虑用户的历史行为,通过用户的历史评分矩阵计算用户或物品之间的相似性,然后向用户进行推荐[5].而基于模型的推荐算法通过分析物品本身的属性,向用户推荐与用户感兴趣的物品相似的其他物品[6].混合推荐算法则是结合了协同过滤算法和基于内容的推荐算法,力求得到更好的推荐效果[7].
以上传统的推荐算法目前都面临一些问题.协同过滤算法非常依赖用户评分矩阵,因此会面临稀疏性问题,即由于对物品进行打分的用户占少数,用户评分矩阵会非常稀疏,找到相似用户非常困难.这通常在物品数量比用户数量高的系统中尤为突出。同时还面临冷启动问题,一个物品除非有用户对其进行打分,否则它将不会被推荐给用户.而基于模型的推荐算法虽然可以改善了稀疏性问题,但是会导致推荐准确率降低[8].本研究针对目前推荐算法中常遇到的问题,提出一种基于深度学习的推荐算法,利用深度学习算法充分挖掘用户和物品的特征,构建模型,并且MovieLens-1m数据集上进行验证.
1 模型结构
1.1 CNN文本网络结构卷集神经网络(convolutional neural network,CNN)是多层感知机(MLP)的变种,通过在神经网络中添加卷集层和池化层使得能够提取出样本的局部特征,同时将提取的特征通过网络正向传播,随着网络层数的增加,样本的特征也不断地被挖掘出来[9,10].如图1所示,通过利用卷积层对像素矩阵进行学习,其中每一个计算单元对输入数据的一小部分作出响应,可以识别图像中的颜色、轮廓、形状从而训练出分类模型.在过去的10年中,CNN已经成为解决计算机视觉问题最受欢迎的技术之一,大量的计算机视觉应用都采用CNN构建,如图像分类、物体检测、面部识别等[11-16].
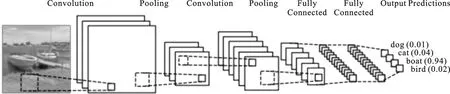
图1 图片卷积神经网络模型
研究人员发现CNN应用于文本问题也能得到较好的效果[10].Rie Johnson将CNN应用于文本的一维结构中,让卷积层中每个单元都响应文档的一小部分区域,从而学习文档特征,实现文档的分类[17].Yuyun Gong将标签推荐任务建模为分类问题,提出一种基于CNN的注意力神经网络推荐模型,通过添加注意力层为单词添加权重,然后将微博标签转换为固定长度的向量,最后实现对微博的推荐[18].CNN应用于文本与图像是不一样的.在文本中网络的输入是词向量,对于一个100维嵌入的10个单词的句子,我们将有一个10×100的矩阵作为输入.过滤层的宽度为100,通常与输入矩阵的宽度相同,高度通常为2~5,即一次滑动窗口为2~5个字.图2所示为分别有高度为2和3的文本滑动窗口.
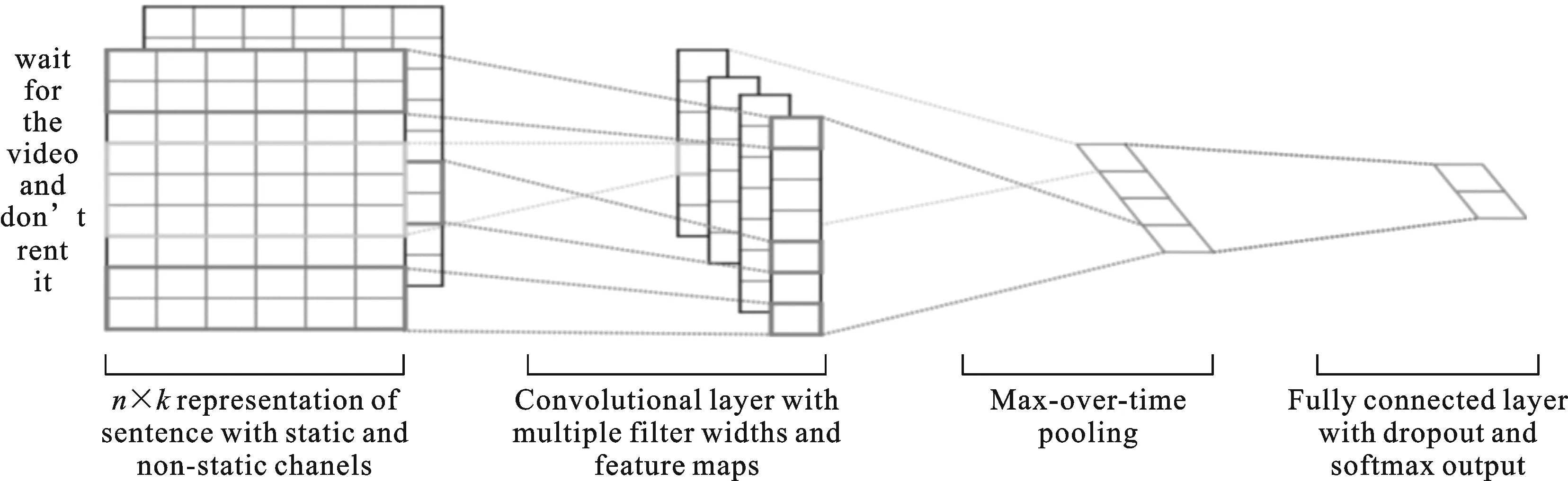
图2 文本卷积神经网络模型
1.2 基于深度学习的推荐算法模型为解决传统推荐算法产生的评分矩阵稀疏性问题,本文中基于CNN文本神经网络提出一种深度学习的推荐算法模型,利用神经网络深层次的挖掘出用户、电影特征之间的关系,从而训练模型,实现电影推荐.算法模型图如图3所示.
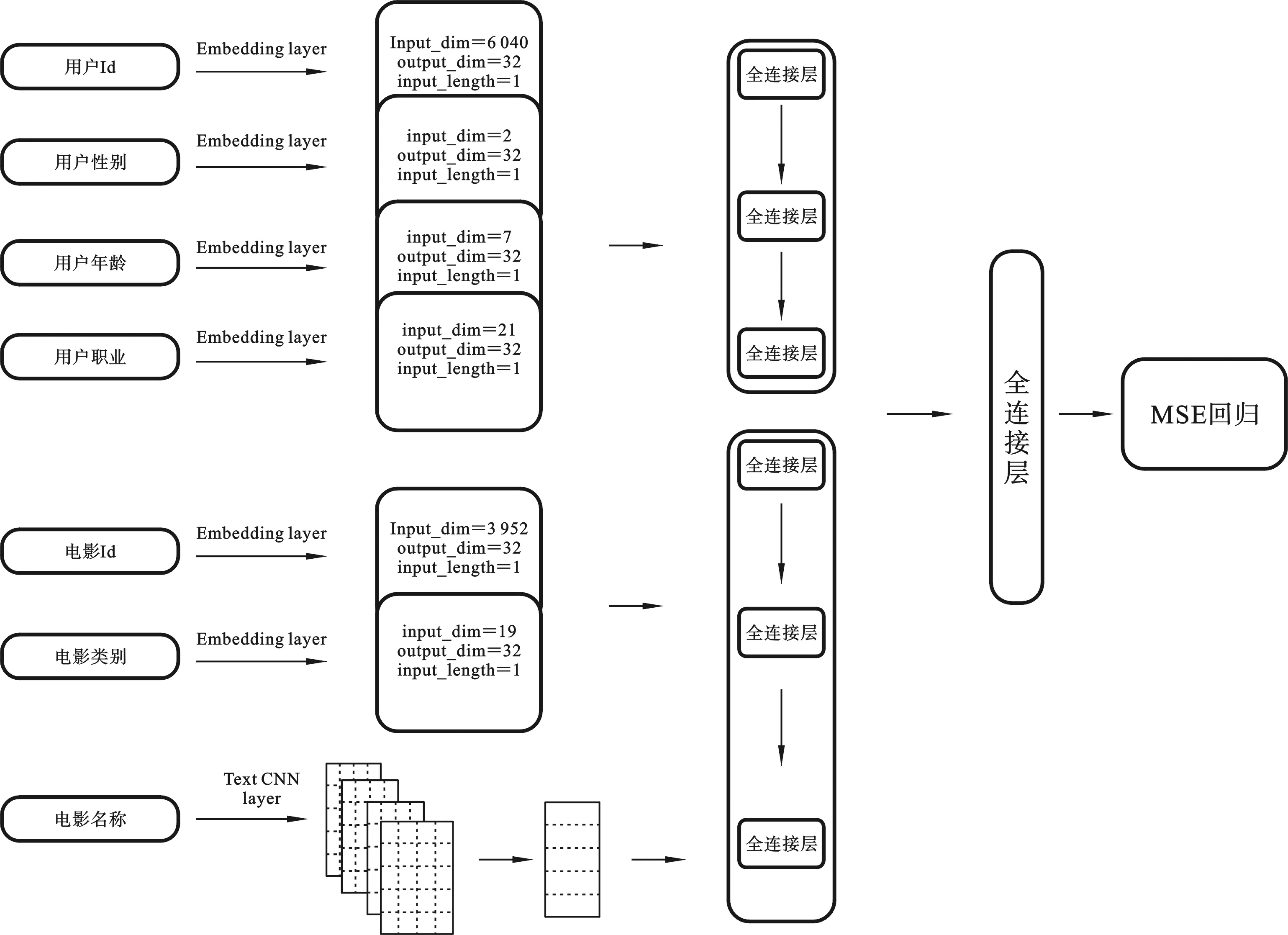
图3 基于深度学习的推荐算法模型
首先对数据进行预处理,提取出用户和电影的基本属性,将基本属性转换为对应的数字向量表示.通常会将基本属性转换为one-hot形式,但是由于转换成one-hot之后会导致特征维度很大,所以对于某些基本属性可以直接用数字索引代替.例如,用户的性别可以用一位0、1表示,而不需要用一个二维向量[0,1]表示.电影的类别可以用数字1,2,…,17表示,因为一部电影可能对应很多个类别,因此将电影类别矩阵维度设为17,不存在的类别用18代替.将用户的基本属性向量、电影的基本属性向量和电影的文本描述向量分别用矩阵u、v、d表示.
d:[d1,d2,…,di,…,dm]
将用户和电影基本属性向量提取出来之后,分别输入嵌入层,嵌入层的一个作用就是可以降低训练所需的数据量.
(1)
(2)
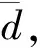
(3)
(4)
将输出值与真实样本评分对比,用MSE优化损失.
(5)
2 实验与分析
2.1 实验环境与数据本文实验硬件配置为2.6 GHz Intel Core i5处理器,16 GB RAM, 操作系统为macOS.采用TensorFlow框架编写代码进行实验,采用MovieLens-1m真实数据集作为实验数据.TensorFlow是谷歌开发的机器学习平台,拥有各种工具,可以进行机器学习、深度学习的实验.Movie Lens-1m是美国明尼苏达大学的Group Lens研究小组提供的数据集,该数据集广泛用于推荐算法的研究.该数据集包含了6 040个用户对3 652部电影的1 000 209个评分,其中还包含了用户年龄、职业,电影名、电影类别等额外信息.对所有评分采用4∶1的方式分割,分为训练集和测试集,将训练集用于模型的训练,测试集用于测试.
2.2 模型训练与评估将用户向量和电影向量输入模型,采用2,3,4,5的卷积核高度进行卷积学习,最后再加上一层全连接层作为输出层,将输出值回归到真实评分,采用MSE函数优化损失.调整学习率和模型参数,不断学习之后通过观察Loss发现模型很快能够达到收敛,如图4所示,模型稳定,可以用于电影的推荐.
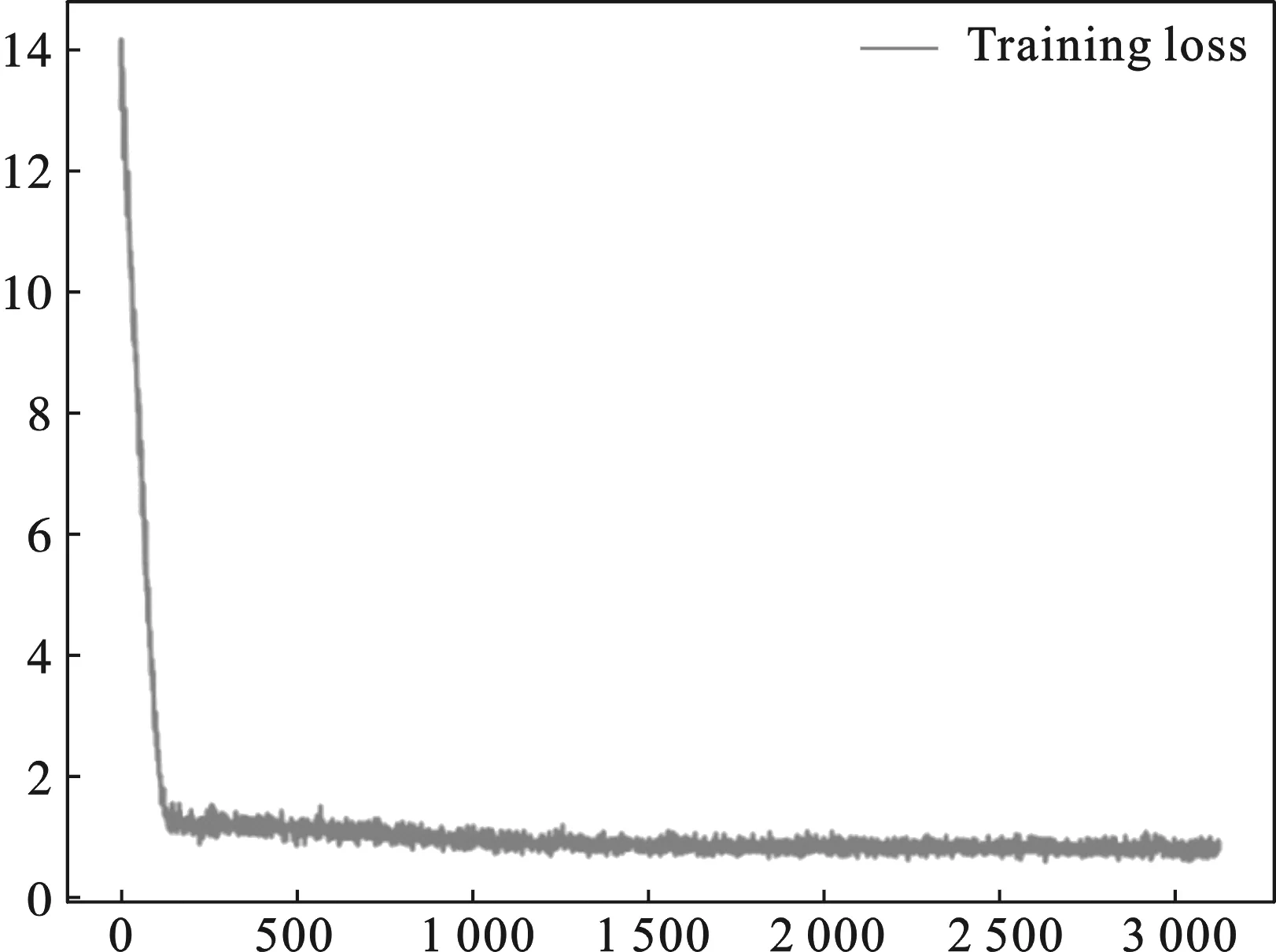
图4 Loss曲线图
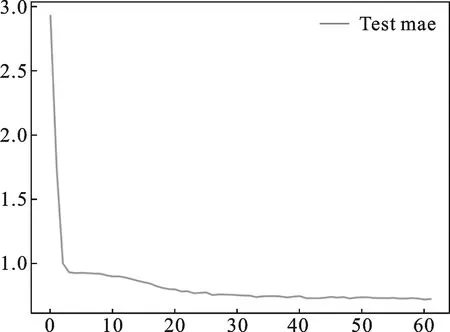
图5 MAE曲线图
将模型应用于测试数据集上,采用MAE对推荐模型进行评估,MAE是指平均绝对误差,通常用来表示推荐偏离准确度的程度.计算方式如下:
(6)
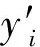
将训练好的模型基于相同数据集与其他推荐算法进行比较如图6所示,本文中提出的基于深度学习的推荐算法相较于文献[11]的推荐算法和文献[12]的推荐算法在MAE上明显偏低,说明本文中提出的推荐算法准确性上有显著提升,同时由于使用深度学习的方法挖掘用户和电影的特征,而不是基于用户评分矩阵挖掘关联关系,所以有效地缓解了稀疏性问题.
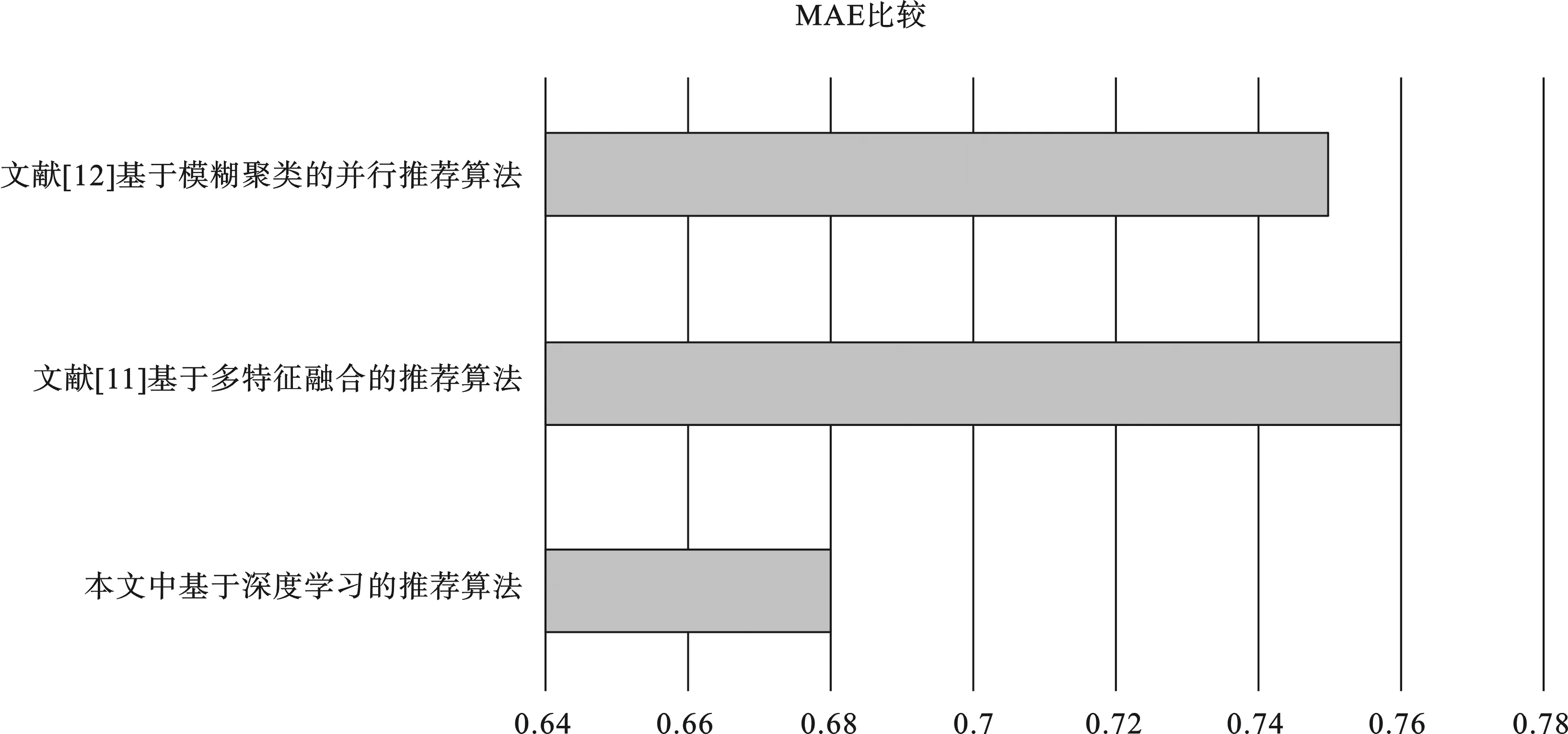
图6 与其他算法MAE比较
测试基于top-k进行推荐,选择召回率(PRecall)、准确率(PPrecision)和F1值(F)作为推荐的性能评估指标[15].
其中召回率指用户喜欢的商品被推荐的概率,公式表示如式(7)
(7)
准确率指正确推荐的项目数量占所有推荐项目数量的比例,用来衡量用户对推荐项目感兴趣的程度,公式表示如式(8)
(8)
其中,R(u)表示模型为用户u生成的推荐列表,T(u)表示测试样本中用户u评分的项目集合,R(u)∩T(u)表示两个集合的交集.

图7 推荐项目个数取不同值时准确率、召回率、F1值比较
F1指标被广泛用于分类问题中,它是召回率和准确率的调和平均数,公式表示如式(9)
(9)
对推荐项目取不同值,并且分别在召回率、准确率、F1值3个指标上与传统的基于用户的推荐算法(UBCF)进行比较,实验结果如图7所示.随着推荐数目的不断增加,召回率与F1值在两种算法中都单调增加,并且本文中提出的算法始终高于UBCF推荐算法.准确率随推荐项目增加,先上升后下降,因为随着推荐项目个数的增加,分母变大,准确率是有可能下降,本文中提出的算法在准确率上也始终高于UBCF算法.这表明本文中提出的推荐算法在推荐效果上优于UBCF算法.
3 结论
本文中提出一种基于深度学习的推荐算法模型.该推荐算法利用神经网络和文本卷集神经网络充分挖掘用户和电影的特征,从而进一步学习特征之间的关系,最后计算用户对电影的评分,产生推荐列表,解决传统推荐算法中存在的评分矩阵稀疏性和冷启动问题.最后在真实数据集上进行实验,结果表明,本文中提出的推荐算法模型具有较好的准确性,可以提升推荐效果.
