NetLinX开放网络下异常权限配置挖掘算法
2020-04-08李力恒王晓磊
李力恒,王晓磊
(黑龙江中医药大学 医学信息工程学院,黑龙江 哈尔滨 150040)
0 引 言
计算机与互联网的持续发展使得用户数据信息不断增加,开发网络下的信息可被随时访问,网络信息安全问题也越来越受关注,开放网络的权限访问问题更加重要[1]。为避免用户隐私数据被非法用户访问,要对数据信息的访问权限进行一定的权限控制,在确保对资源浏览获取有效访问权限的同时防止非法用户进行权限访问,避免部分隐私信息的非授权传播[2]。因此,数据挖掘和入侵检测技术也不断提高。
传统的实用性挖掘方法仅将所统计获取的数据信息进行已有系统攻击状况的比较,如文献[3]中的基于谱聚类的访问控制异常权限配置挖掘方法,此种情况与信息安全准则相悖,且此种方法的匹配效率较低,同时对于某些未知信息或现有入侵方式的变更无法进行精确地挖掘检测与分析。文献[4]提出一种基于SOM聚类的多模态医学图像大数据挖掘算法,医学图像数据自身冗余度不再无限攀升,帧率重叠行为得到有效控制。文献[5]提出了一种复杂高维数据中异常点挖掘算法,从算法精度、ROC曲线面积及运行时间3个角度分析了8个典型数据集,挖掘其中的高维数据异常点。文献[6]提出了一种Android系统中的权限异常检测方法,该方法通过FP-growth算法挖掘所配置的各个权限之间的关联性,根据关联性构建FP-tree检测模型,对权限进行恶意性判决。然而上述几种方法忽略了权限配置过程中包含的错误权限,使对异常权限的挖掘时间大大增加。文献[7]设计了一种挖掘加权最大频繁序列的算法,该算法利用频繁项出现的频率赋予不同频繁序列不同的权重,通过引入频繁加权序列的定义筛选出最大频繁序列,使挖掘结果具有反单调性,提高了挖掘准确性。文献[8]提出了一种基于函数调用关系的应用权限泄露漏洞挖掘方法,该方法分析了常见的权限泄露漏洞的形成原理,在分析可疑路径的基础上,对其中的动态暴露组进行侦查。然而上述2种方法在挖掘过程中具有很大的盲目性,导致挖掘效率较低。文献[9]设计了一种大规模高维数据集中局部异常数据挖掘算法,该算法将FFD技术应用于异常信息挖掘中,利用FFD的强控制能力实现数据传输与挖掘进程的数据互通,结合FIFO挖掘思想实现数据的本地化与异常数据挖掘。文献[10]提出了一种基于改进Eclat算法的资源池节点异常模式挖掘方法,利用Eclat算法通过转换资源池节点数据格式、建立非频繁项集减少序列的连接次数,构建信息存储体,再利用关联规则算法挖掘其中各信息之间的关联,筛选出其中的异常模式。虽然上述2种方法在挖掘效率方面优势较为明显,但由于均是先将数据进行处理或建立储存体,导致挖掘结果的准确率较低。
针对现有异常权限配置挖掘算法存在的挖掘时间长、效率低、精度差的问题,本文提出一种NetLinX开放网络下异常权限配置挖掘算法。首先对挖掘数据进行数据预处理,数据净化、会话与用户识别及路径补充处理,降低数据挖掘的冗杂程度,经过识别排除其他干扰数据影响,再进一步进行异常权限配置的检测,提高了挖掘系统的效率,最后将检测后的数据信息进行挖掘,综合利用 lncLOF与OPTICS 方式进行数据挖掘,减少挖掘信息数据量,缩减挖掘时长, 进而提升整体异常权限配置挖掘效果。
1 权限配置数据预处理
权限配置数据预处理的主要目的是将NetLinX开放网络下的数据信息转化为较为准确可靠、便于挖掘的数据。这一过程以缩短挖掘时间,提高挖掘效率,该过程包括数据净化、会话和用户识别、路径补充3个部分。
1.1 数据净化
在数据净化过程中,需进行关联规则与系统访问的初始化设计,并检测其有效性是否能够较为精准的显示出用户对于网络信息的访问流程[11]。首先,利用运行系统下载文件,在下载过程中相应增加记录数量。一般情况下,用户下载的HTML页面会产生多条记录,由于页面中存在其他数据信息的使用,图文下载过程中会出现增加记录的下载,此时需要进行用户页面请求,与代表意图相匹配,并同时应用于用户网络信息的访问与数据统计。在访问后,确保所挖掘的数据具备任务所需的挖掘意义,同时对于无关数据与冗余信息进行系统消除,并相应的进行记录的特级删减[12]。在确立请求之后,对其数据信息进行保留分析处理,同时定义剪切规则编制,预先设定专门的相应网站进行数据分类,并建立对应规则信息库,根据所需挖掘检测的网站分类进行规则信息库的数据清理,也可根据自身需求进行信息删减,完成整体数据净化过程。
1.2 会话与用户识别
利用用户多次访问记录进行单个会话的划分,根据数据超时原则检测2个页面请求之间的时差是否超出规定界限,如超过,则开始新的会话。此外,识别过程需利用不断变化的本地存储与系统服务器,基于站点进行启发规则的技术识别,并验证用户地址是否相同。如果用户的访问记录或规则系统发生改变,则每个系统服务器代表不同的访问用户,接着将访问系统与设置站点结构拓扑相结合,构建中心系统服务器访问浏览途径。若请求页用户与所访问页面无超链接联系,则存在另一个拥有同样用户地址的用户。在请求页面相同的情况下,采取识别过滤方法,滤除用户同时使用2种网络进行访问或不经过站点直接进行输入连接的情况[13],用户识别结构如图1所示。
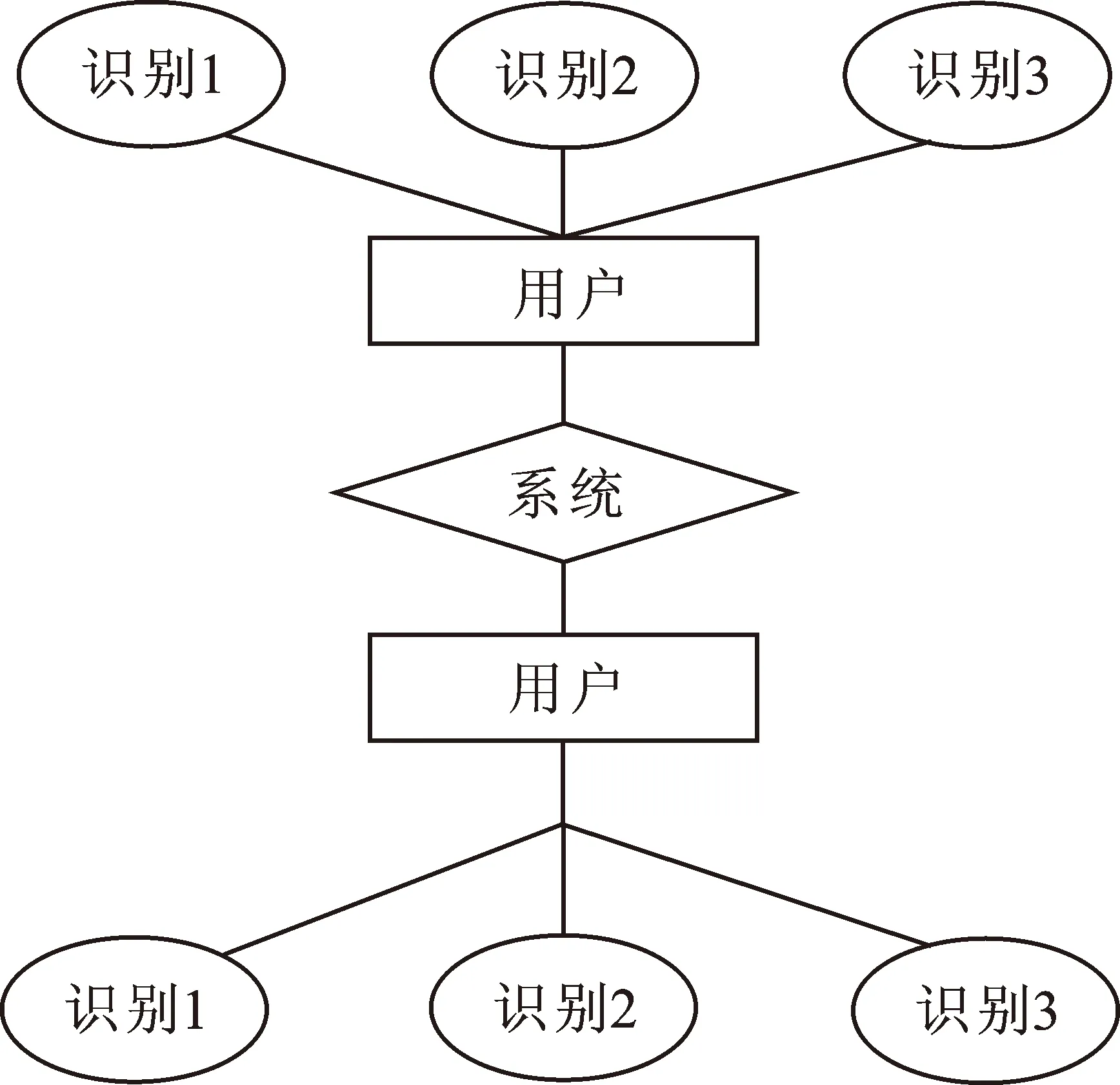
图 1 用户识别结构图Fig.1 User identification structure
1.3 路径补充
在访问过程中会出现访问是否重要的请求确定记录申请,在此情形下,需要将网络记录中不存在却同时显示用户行为的信息补充,以此来完成对数据的预处理。若当前所接收的请求与上一次的用户页面之间无超链接关系,则用户存在使用按钮调节缓存至页面的情况,此时应采用检索引擎进行请求确定页数的指引,若在用户访问多条页面中都存在包含当前页的连接请求,则将设定站点结构进行页面代替,并通过此种方式将所遗漏的页面请求补充至用户会话页面[14]。
2 异常权限配置检测
在对数据预处理后,对权限配置过程的异常情况进行检测,对异常权限配置进行规则匹配,再利用UPA繁复对权限信息进行用户相似度的聚类,由此获得相似用户访问的集合。但在规则匹配和异常权限配置过程前,需对权限配置信息进行预处理。这一预处理过程的对象为权限配置信息,将其划分为不同的类簇并判断异常权限信息的位置。这一过程能够避免挖掘过程的盲目性,排除了其他数据的干扰,有效提高挖掘效率和精度。
2.1 聚类结果信息预处理
在将异常权限配置进行检测之前,需对其进行信息预处理,设定独立的类簇种族,并构造指数模式向量,利用指数模式向量中的不同参数判定异常权限的所在区域。若相对应的位置模式向量的参数都为1,则指数模式向量中此参数存在位置也为1,剩余选取位置皆为0[15]。
2.2 异常权限配置的规则匹配
将预先设置的异常权限配置信息进行数据规则筛选,并将筛选结果进行集合组排列。若某个权限被其中一个特定用户所访问,则赋予此匹配权限用户的存在比值小于指定阈值距离a,并将此位置设定为正确位置[16]。若某个权限被多个应用用户所使用,则当前存在的用户占取全部用户的配备比值小于指定阈值。除此以外,当剩余包括该权限特征的指定模式向量的交集存在2种情况:
1) 指定为该模式向量的子集,并设定权限配置为正常权限配置,不加以配置处理。
2) 若无指定为该模式向量的子集,并设定权限配置为异常权限配置,将此权限配置列入异常权限配置候选组中,并在各个权限配置方形阵中设置相应位置为0。若在未被授权的用户中出现比值小于指定阈值的情况,则将此类数据同时归入异常权限配置数据集中,并在各个权限配置方形阵中设置相应位置为1。
2.3 数据的交叉类聚处理
依据用户与权限方形阵采取聚类方式进行异常权限信息配置,不断转换方形阵中的配置规则,并得到数据转置阵,利用类聚模式进行交叉类聚匹配,获取类聚结果后根据所选取的规则制造所需的异常权限配置数据集[17]。
在对全部结果进行综合收集处理后,获取新的用户权限方形阵,并将该阵作为异常权限配置的输入框数据源实行综合执行,最终达到异常权限配置检测后的交集数据为空时停止配置。
3 异常权限配置挖掘
将以上检测出的异常权限配置进行挖掘,在某个数据集中,利用异常数据集定义,将少数数据进行综合数据算法挖掘处理,可进一步降低挖掘时间,进而提高整体挖掘效率。
在算法的起始进行OPTICS方法处理,将原始集合中的大量密集数据进行聚类处理,并将松散数据集转换为异常种簇,并持续分析处理,在异常种簇的数据中进行内部离群因子的计算[18]。接着对新加入的数据进行OPTICS方法计算,记录新加入数据与中心种簇之间的距离关系,记下哪个种簇离中心的距离最小。若此距离小于预定的数值参数Q,则可将该数据直接添加至该种簇中。若这些新添入的数据无法满足正常种簇的条件,则将组合成新的种簇[19]。最后,比较以上计算出的离群因子,并选择出异常数据的代表参数。具体过程如下:
1) 进行算法数据输入,设置总体数据集,其中需要进行输出的异常数据的整体数量为k。
2) 调节OPTICS与IncLOF方法,将输入的数据集进行类聚处理,并将横坐标设定为结果数据中的序列,纵坐标设定为可达距离。
3) 按照可达距离设置的特定参数阈值r在纵坐标中沿着平行于横坐标的位置进行直线设置,在直线组合成的点集中划分陡峰与密集数据综合位置,陡增的峰尖为边缘点,并沿不同的陡峰中心进行纵向切割,2个相近峰间形成常种簇[20]。
4) 当出现大量数据时,分别计算每个种簇的中心对象与系统中心对象的距离,并记录下最小距离,若最小距离小于预先设定的阈值距离a,则将组合成一个新式异常种簇,并持续进行以上步骤的操作,直至全部新增数据都被放置至种簇中[21]。
5) 最终进行离群因子的LOF计算,根据其大小进行数据排序运算并输出,输出结果则为所需异常权限配置数据。其输出公式为z=ak+Q。
4 结果与分析
为检测NetLinX开放网络下异常权限配置挖掘算法的实际应用效果,将该算法与传统算法进行对比,从挖掘精确度和挖掘效率2个角度分析不同挖掘算法的有效性。设定实验参数如表1所示。
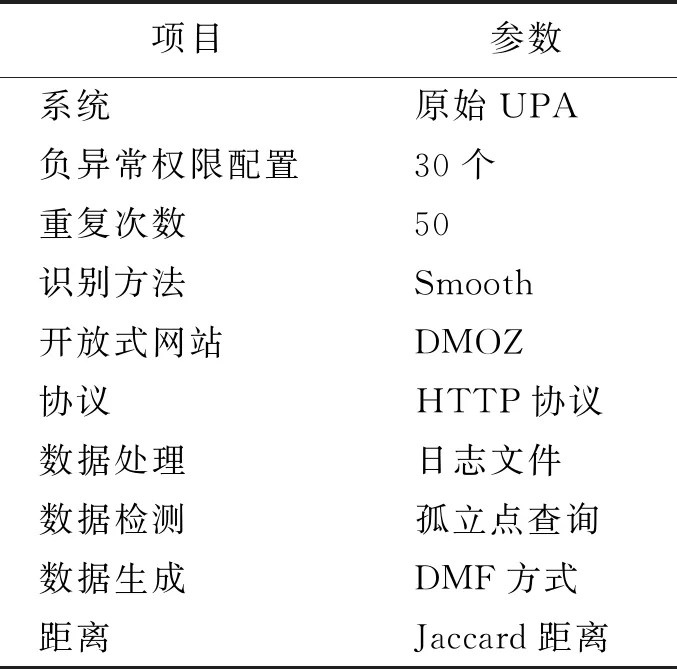
表 1 实验参数表Tab.1 Experimental parameter table
将NetLinX开放网络下异常权限配置挖掘算法的挖掘结果与文献[3]中的基于谱聚类的访问控制异常权限配置挖掘算法及文献[5]中的Android系统中权限异常检测算法的挖掘效果进行比较,得到的挖掘精确度对比与挖掘算法效率对比。挖掘精确度对比如图2所示。
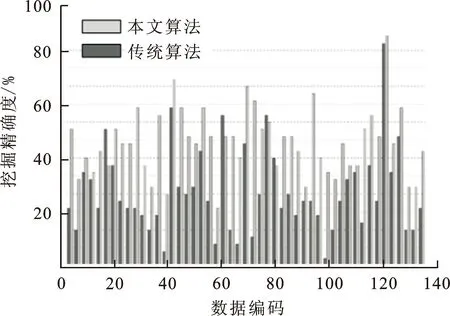
图 2 挖掘精确度对比图Fig.2 Mining accuracy comparison chart
从图2可知,在相同参数条件下,由于本文算法采取独立模型形式,在挖掘过程中减少了其他因素的阻碍,并选用Jaccard距离测试降低了环境因素影响,进一步提高了整体算法的挖掘力度,进而促使本文算法挖掘精度高于传统算法。而文献[3]算法受其他因素影响较大,无法确保系统正常运行,导致挖掘精确度较低。挖掘算法效率对比如图3所示。

图 3 挖掘算法效率对比图Fig.3 Mining algorithm efficiency comparison chart
从图3可知,当挖掘时间为20 s时,本文挖掘算法效率为52%,而文献[5]算法的挖掘效率仅为15%。此种差异形成的原因为本文算法利用Smooth识别方法,对初始数据进行识别,一定程度上降低了挖掘系统的识别压力,减少了挖掘时间,提高整体挖掘效率。
在此后的挖掘中, 随挖掘时间的增加, 本文挖掘算法的挖掘效率持续高于传统算法的挖掘效率, 造成此种差异的原因在于本文挖掘算法相较传统挖掘算法, 采用孤立点查询, 排除非测试点的干扰, 能够更有效的完成挖掘任务。 而文献[5]算法的挖掘数据较为繁杂, 对于挖掘数据的分类整理效果较差。
经过以上的对比分析可知,本文挖掘算法的挖掘精确度与挖掘效率高于传统算法,在较大程度上阻止了非测试因素与其他干扰因素的影响,降低了数据冗杂度,提高了挖掘的整体效率,具备更加广阔的使用空间。
5 结 语
相较于传统算法,本文算法在较大程度上排除了其他数据的干扰,降低了数据存在的数量度,进而提高了挖掘的效率,能够较为清晰地提供数据来源,减少挖掘时间,为使用者提供便利的挖掘,具备更加优越的发展空间与使用市场。然而,现有挖掘算法在权限配置过程包含的错误权限的问题暂时并未得到解决,定向挖掘结果还未达到理想状态。因此,在今后的研究中,将进一步提高本方法的定位挖掘处理能力,扩大该方法的应用范围。
