智能家居移动机器人的人脸识别方法
2020-04-08李林鹏南恺恺王晓华
李 珣,李林鹏,南恺恺,王晓华,张 蕾
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
随着人工智能技术的不断发展,更多机器人服务场景的应用落地,人机交互将成为新时代的常态[1]。在未来的智能家居中,人机交互往往需要对人的身份进行快速响应,从而执行后续的一系列权限操作,同时对陌生人的身份进行判别,在追求准确率的同时也要防止产生延迟的滞后感,因此实时性的身份识别尤为重要[2]。而人脸识别相比其他的生物特征识别具有非接触性、不易仿冒、方便采集等特点而被大量应用于人物身份识别[3]。
对于人脸识别,文献[4-5]提出了一种局部二值法来描述图片的纹理特征,具有灰度尺度不变和光照不变的优点,但是对于表情和姿态表征不够明显。之后许多研究人员在LBP算法原有的理论基础上进行了改进[5-7]。文献[8]提出使用稀疏系数来描述人脸图像,使用最小残差来判别是否属于同一张人脸,该算法在应用上具有有效性和鲁棒性,但是存在训练时间过长的问题。文献[9]提出使用PCA+SRC算法来改善光照因素的影响,文献[10]使用深度学习的方法在国际权威人脸识别数据库(labeled faces in the wild,LFW)中识别准确率达到了97.25%。但是在实际应用场景中,基于二维的静态数据集识别受到光线等因素的影响会造成识别率降低。近年来推出的RGB-D相机可以有效捕捉物体的三维特征[11],Kinect等相机的出现推动了三维人脸识别的发展[12-14]。文献[15]使用改进的RISE算法来计算RGB图像和深度图像的显著性,但是并没有充分的利用人脸的深度信息。文献[16]使用无监督方法从数据集中提取紧密二值描述子,在正脸和面部变化较小的情况下达到较好地识别效果,但是对于局部遮挡的情况下,信息损失比较严重。当前,基于二维和三维的人脸识别技术都停留在算法和已有的静态数据集上,仅是作为一个孤立的任务,将人脸检测、人脸识别、人脸跟踪与机器人视觉同步为一个系统可以提高机器人感知世界的能力[17]。在实际应用场合,一个完整的系统还需要考虑许多其他的因素。诸如整个系统的稳健性、视频采集的时效性、机器人检测运动目标的同步性以及人脸识别算法的完成效率等。
综上, 本文针对智能家居场景中动态人脸识别技术有待提高的问题, 提出了一种结合深度图像的人脸实时识别跟踪方案。 不同于传统人脸识别技术, 利用深度图像不同目标像素点的梯度值, 快速分离头部背景。使用 Hungarian 算法与 HMM 算法相结合进行人脸跟踪。 根据所提出的方案在 Turtlebot 机器人的基础上进行物理平台改装,使用局域网连接机器人端与远程 PC 端进行训练数据实时传输。 最后, 在工作室等现实环境中进行数据采样训练以及人脸识别测试, 实验结果表明: 本文提出的方法在实时视频中保持良好的精度, 是一种提高智能家居场景中移动机器人人脸识别准确率的有效方法。
1 运动目标检测与识别
机器人对室内移动目标进行检测识别, 必须兼顾时效性和准确性。因此, 本文在实时运动目标检测时引入 Viola-Jones 方法[18], 通过积分图的形式取代传统的滑动窗口来计算 Haar 特征,加速计算过程;进而结合 Fisherface 算法将高维数据映射到低维空间, 根据提取的特征向量投影到面部空间进行人脸识别; 最后采用 Hungarian 算法获得最优匹配[19],结合隐马尔可夫模型 (hidden markov model,HMM) 过滤掉相邻采样之间的虚假目标, 获得最终检测与识别结果, 算法流程如图1所示。
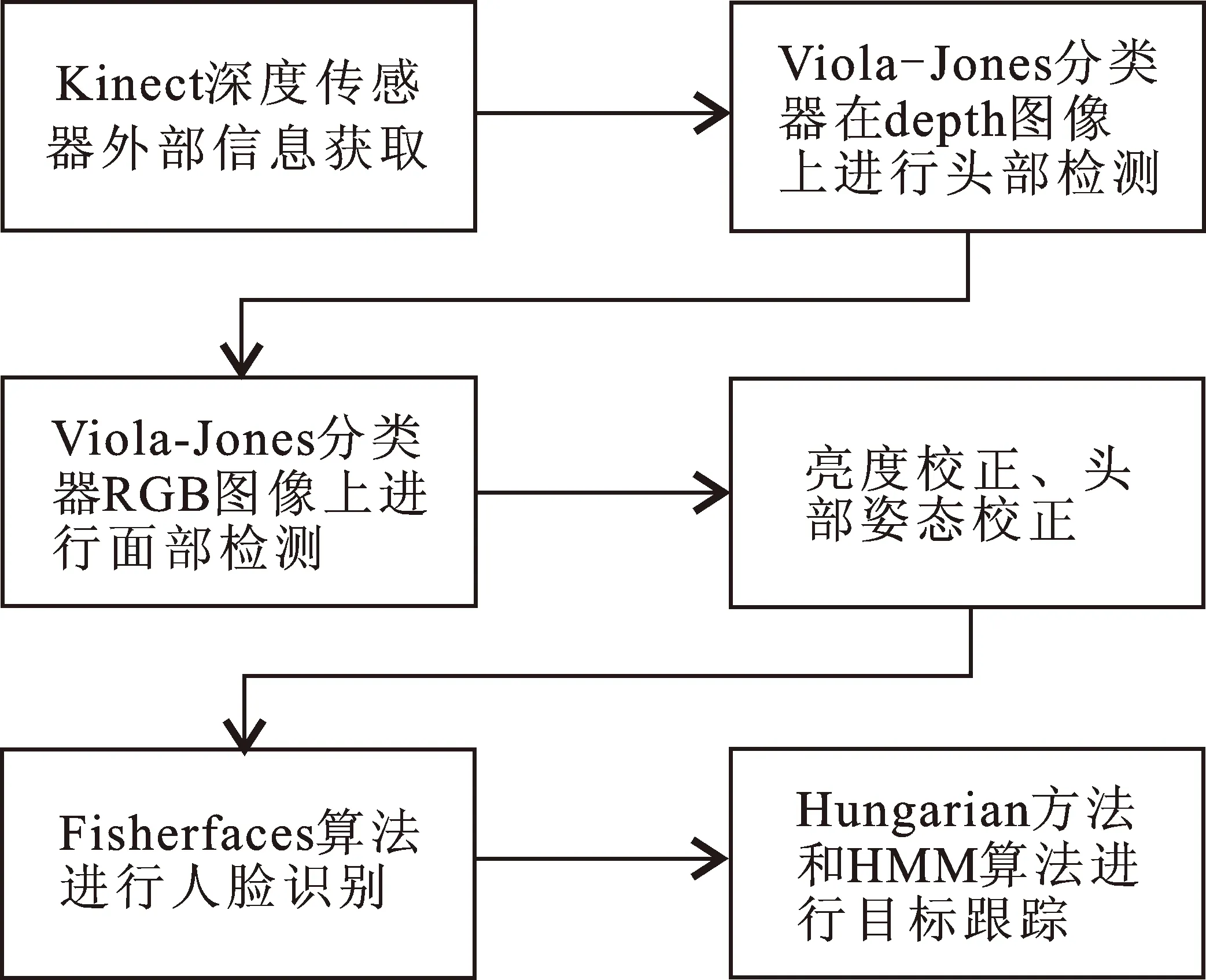
图 1 算法流程Fig.1 Algorithmic flow
1.1 目标检测
在动态场景中,二维的人脸检测存在噪声及光线等干扰因素。使用RGB-D图像中的深度信息可以较好地弥补这个缺陷。因此,借助实验室Kinect可以获得受光照影响较小深度信息,快速将头部从背景中分离出来。深度图像中的头部检测步骤优先于RGB图像中的面部检测,且在光线较差的情况下依旧可以快速检测出头部区域,检测过程如图2所示。
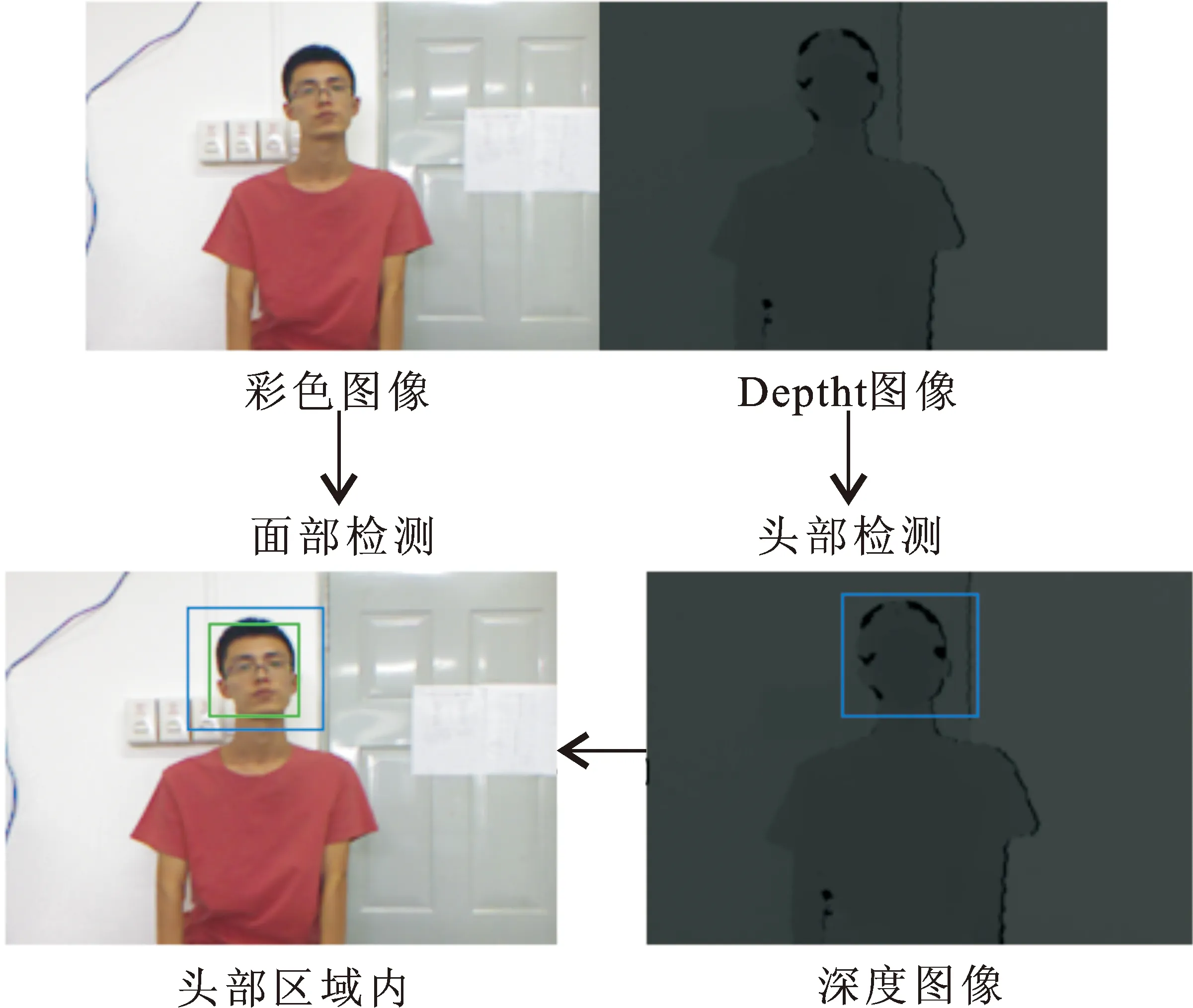
图 2 人脸检测流程Fig.2 Face detection process
由于获得头部图像的非统一性,需对图像进行头部姿态校正预处理,同时为提高识别的准确率,保证面部光照均匀需对其进行直方图均衡化,使图像中的灰度值均匀分布,增强图像的有效特征。在光照不足的条件下,可使用对数变换来改变灰度值,令
g(x*,y*)=ln(f(x*,y*)+1)
(1)
式中:f(x*,y*)表示原始图像;g(x*,y*)表示对数图像。
训练图像和测试图像像素位置的偏差会导致识别性能的下降。为了建立面部方位之间的对应关系,本文进一步使用Viola-Jones分类器[18],利用积分图来计算特征值,定位眼睛、鼻子等面部标志物。积分图的表达特征为
s(x*,y*)=s(x*,y*-1)+i(x*,y*)
(2)
t(x*,y*)=t(x*-1,y*)+s(x*,y*)
(3)
式中:s(x*,y*)为(x*,y*)方向上原始像素之和;t(x*,y*)为积分图。
1.2 目标识别
目标被定位后,将提取到的特征投影到面部空间,利用Fisherface算法对目标进行识别,计算属于各个标签的概率分布,得到正确的标签,如图3所示。
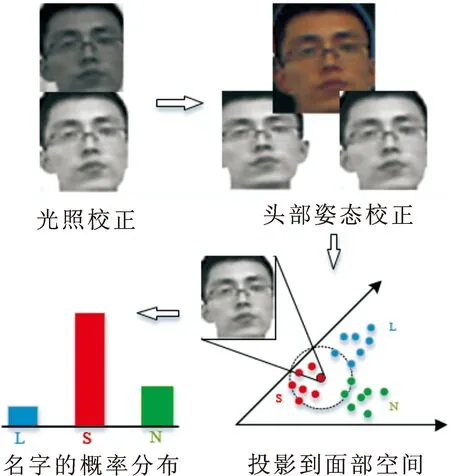
图 3 人脸目标识别基本过程示意图Fig.3 Sketch of basic process of face target recognition
使用LDA线性判别理论对原始数据进行降维分析,期望得到的各类别数据投影点更为集中。通过在空间中寻找最佳的投影向量,使得类内散射矩阵SW最小,类间散射矩阵SB最大。类别为C的类内散射矩阵和类间散射矩阵为
(4)
(5)
式中:μi(i=1,2,…,c)为第i类样本的均值向量;μ为所有样本的均值向量;Ni为第i类样本的个数;xi为第i类样本的集合;x为n维向量。
假设投影的空间维度为d,基向量(w1,w2,…,wd)构成的矩阵Wn×d,最终求得的准则函数为
(6)
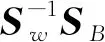
1.3 目标人脸跟踪方法
移动机器人技术结合人脸识别技术的优势在于:利用Kinect提高检测精度,同时规避Kinect的距离限制,脱离了场地限制,并对需求目标进行基于图像跟踪的物理跟踪。所以找到快速有效的人脸跟踪解决方案是本文重点研究内容之一。
本文使用Hungarian算法构建二分图之间的最大匹配,匈牙利算法的核心思想就是通过不断的寻找增广路进行完全匹配[19]。在相邻的采样图像中寻找人脸特征求出最大匹配值。在找到全局最适合的任务后,用HMM来模拟一段时间内的人脸识别过程,HMM是从马尔可夫链中衍生出来的。通过对潜在的隐含状态进行分析,根据人体移动速度的设定,自动过滤掉目标场景中虚假的人脸模型,将标签概率视为权重,为检测到的人脸分配唯一正确的标签。
利用Kinect提供的RGB-D视频流进行数据采集的优势在于可以进行多帧交叉检测,而不是单独的去分析每张图像,为将相邻两次检测的图像进行匹配需要定义一个阈值。之前的检测i和现在的检测j之间的匹配程度定义为
Hij=L2‖Xi-Xj‖+ω‖Pi-Pj‖a2
i=1,2,…,Ml,j=1,2,…,Mr
(7)
式中:Xi,Xj分别代表相邻两次之间被检测人脸的三维坐标;Pi,Pj分别表示每个检测在所有可能标签上的概率分布;ω是2个距离之间的加权因子;a为所定义的时间间隔。根据人体移动速度的假设,如果2个检测在可能的标签范围内具有相似的预测,则此成本函数是有效的。本文用二分图来描述相邻两次检测结果的匹配问题,在加权二分图中寻找最小成本匹配,用Ml表示先前检测点的集合,Mr表示当前检测的集合。对Mr,Ml进行2个子集之间的所有边数完全匹配。连续的识别跟踪可以保存每个被检测人员的识别结果,使识别更加稳定,并消除出现的误检、漏检。
2 实验与结果分析
根据所设计的人脸识别方法,搭建了物理实验平台并提出了实时信息处理的方案,整个系统如图4所示。该系统采用机器人控制端与远程工作站端相结合的信息处理模式,局域网无线传输数据来连接机器人控制端与远程工作站端,该结构可以保障系统移动端运动连续性和续航能力。机器人运动控制端由Kobuki底盘、Kinect深度传感器以及小型化智能终端等[20]组成,远程端使用一台PC工作站来提高机器人的可控性。

图 4 远程在线人脸识别跟踪系统实物图Fig.4 Physical map of remote online face recognition and tracking system
2.1 数据初始化
为了确保本文提出的方案与平台在真实环境中的实用价值,本文的所有实验都是在实际环境直接进行,实验场地为背景复杂的工作室和光照不均匀的楼道。Kinect提供的视频为30 f/s,根据机器人的运动特性以及移动过程中的角度变化,设置每隔10 f/s提取一张图片,同时远程PC端对提取的图片进行训练。样本组人员切换不同的方位和角度,保证在训练过程中提取到更加丰富的特征。利用人脸检测节点对视频中的人脸进行检测时,若未检测到,返回继续采集检测,将捕捉到的人脸图像标准化尺寸为92×112的图片用于训练。
2.2 结果及分析
为验证本文方法在真实场景中的有效性,切换不同的背景、角度和距离对模型进行测试,单目标识别结果如图5所示。蓝色框和绿色框分别代表头部与面部,同时在远程工作站可视化输出目标的识别效果,在检测识别框的下方实时显示被测试人员姓名。

图 5 单目标识别结果Fig.5 Single target recognition results
本文算法可以完成多目标联合检测,采用相同的设置对多目标进行检测识别实验验证,可视化结果如图6示例所示。当相机检测新的目标的进入视界范围内,系统能够快速对新进入目标进行锁定,并将识别结果可视化输出到PC端。

图 6 多目标识别结果Fig.6 Multi-target recognition results
为了验证本文算法在物理平台的识别效率,并统计检测、识别算法的实用性,本文以30名人员作为训练样本集,随机选取6名成员进行150次验证测试统计机器人在移动过程中的人脸识别时间及识别准确率,统计结果分别如表1和表2所示。
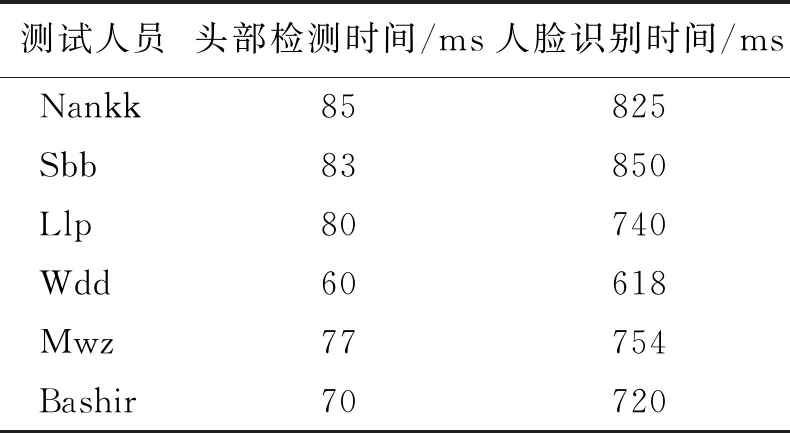
表 1 人脸识别时间测试表Table 1 Face recognition timetable
训练完成后,需要对机器人平台进行人脸识别测试来得到头部定位的时间。首先遮挡摄像头,测试人员完全进入视野范围后移开挡板,从表1可知,平均定位时间为76 ms,识别时间平均维持在751.17 ms。在新的目标进入相机视野,头部进入检测范围有一个动态的过程,受到距离以及不同环境的影响检测时间会发生波动,面部进入视频后识别时间维持在1 s左右,基本满足实用需求。
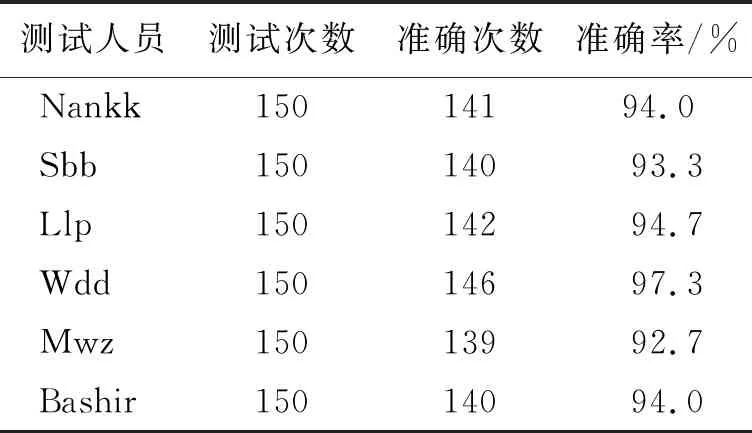
表 2 人脸识别率统计表Table 2 Statistical table of face recognition rate
测试结果显示出不同目标的识别结果存在波动现象。分析其原因,本文选取的实验环境是在背景复杂的工作室和光照差异较大的楼道,实验结果会受到环境因素以及测试人员面部表情和距离Kinect相机的远近等因素影响,从表2可知,平均识别率达到了94.3%,可以满足移动机器人在室内环境中的需求。
3 结 语
为了满足智能家居机器人实时人脸识别需要,提出了一种基于移动机器人平台的动态人脸识别跟踪方法。算法部分利用深度图像的光照不变性快速定位头部位置,保证动态视频中面部识别匹配的鲁棒性,提出Hungarian和HMM算法相结合的目标跟踪模式。将算法移植到Turtlebot移动机器人搭建物理平台,远程PC端加速数据处理过程。最后在现实环境中采集视频进行实验,动态环境中平均识别率达到了94.3%。在接下来的工作中,将研究深度信息和彩色信息的融合方案,在保持系统时效性的同时进一步提高识别准确率。
